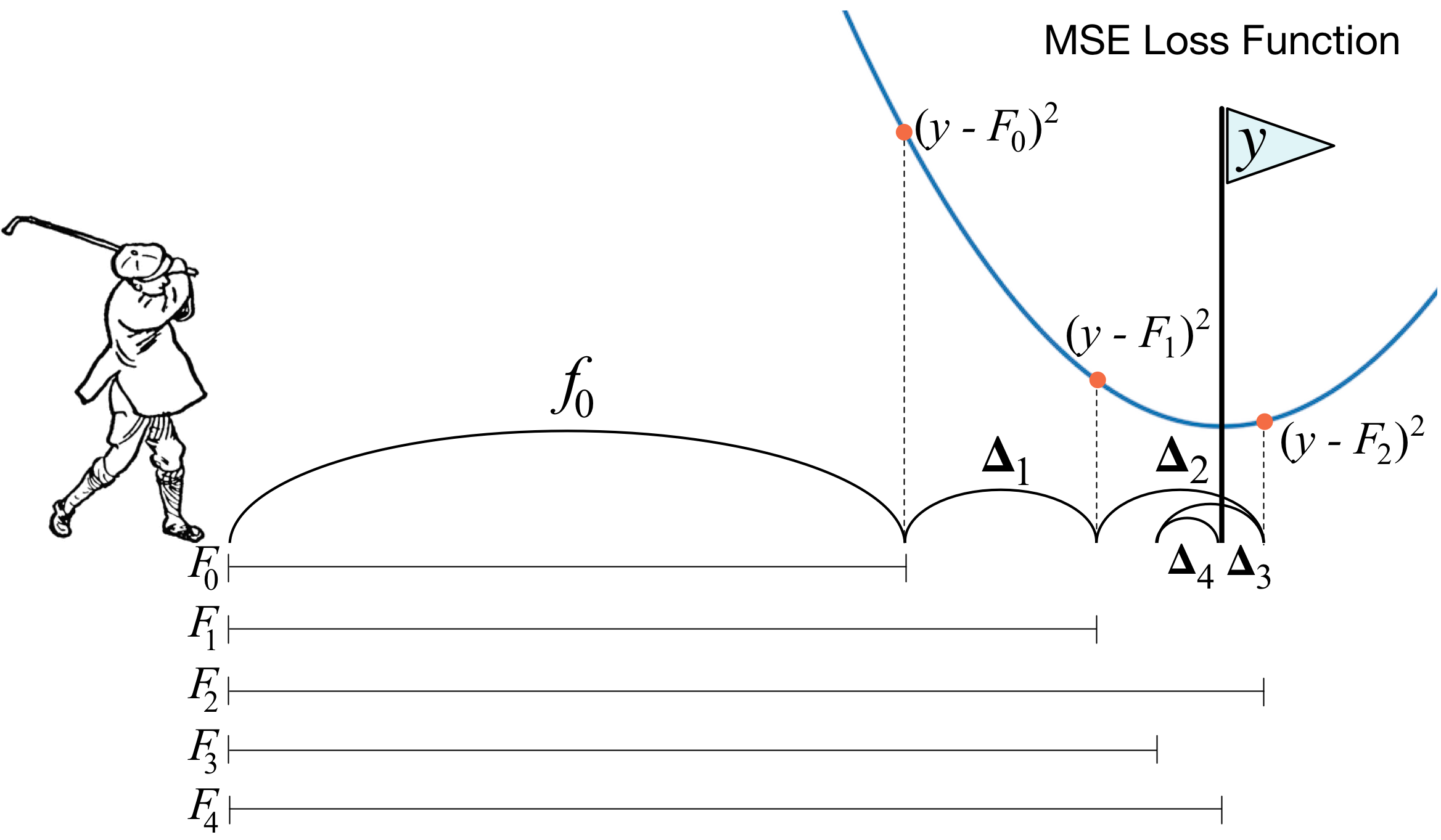
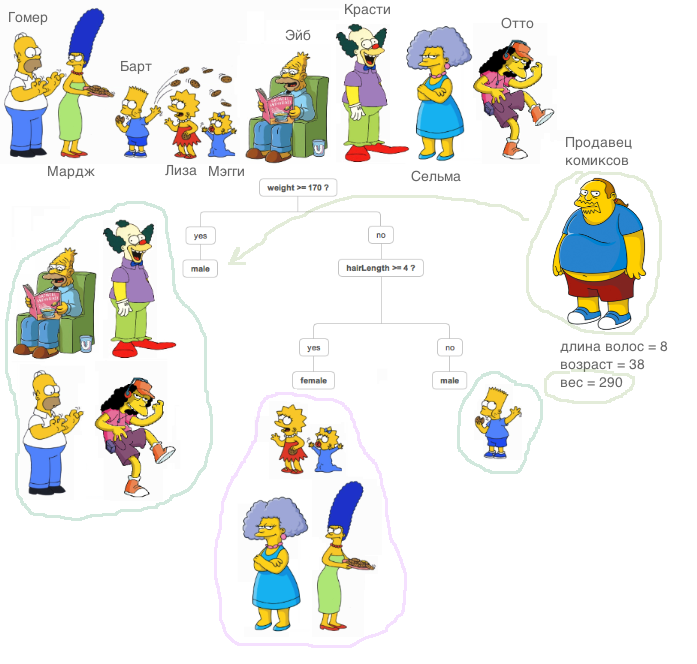
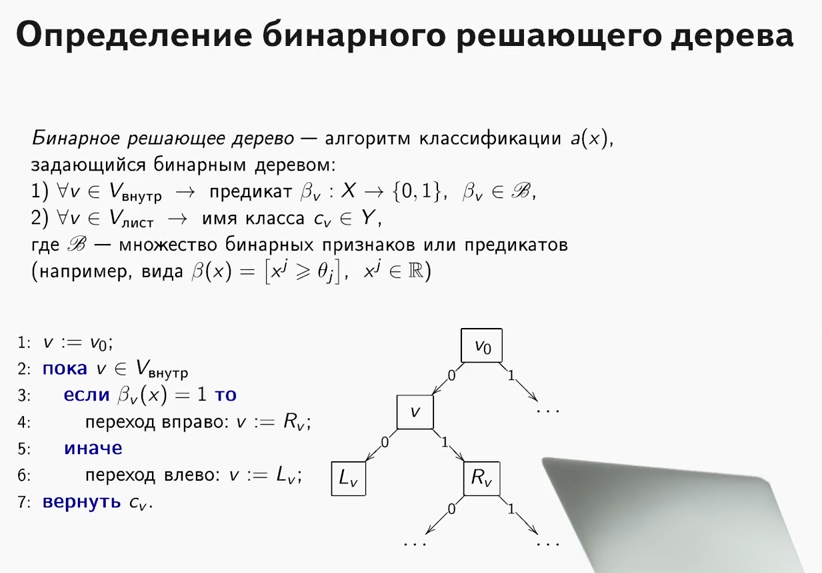
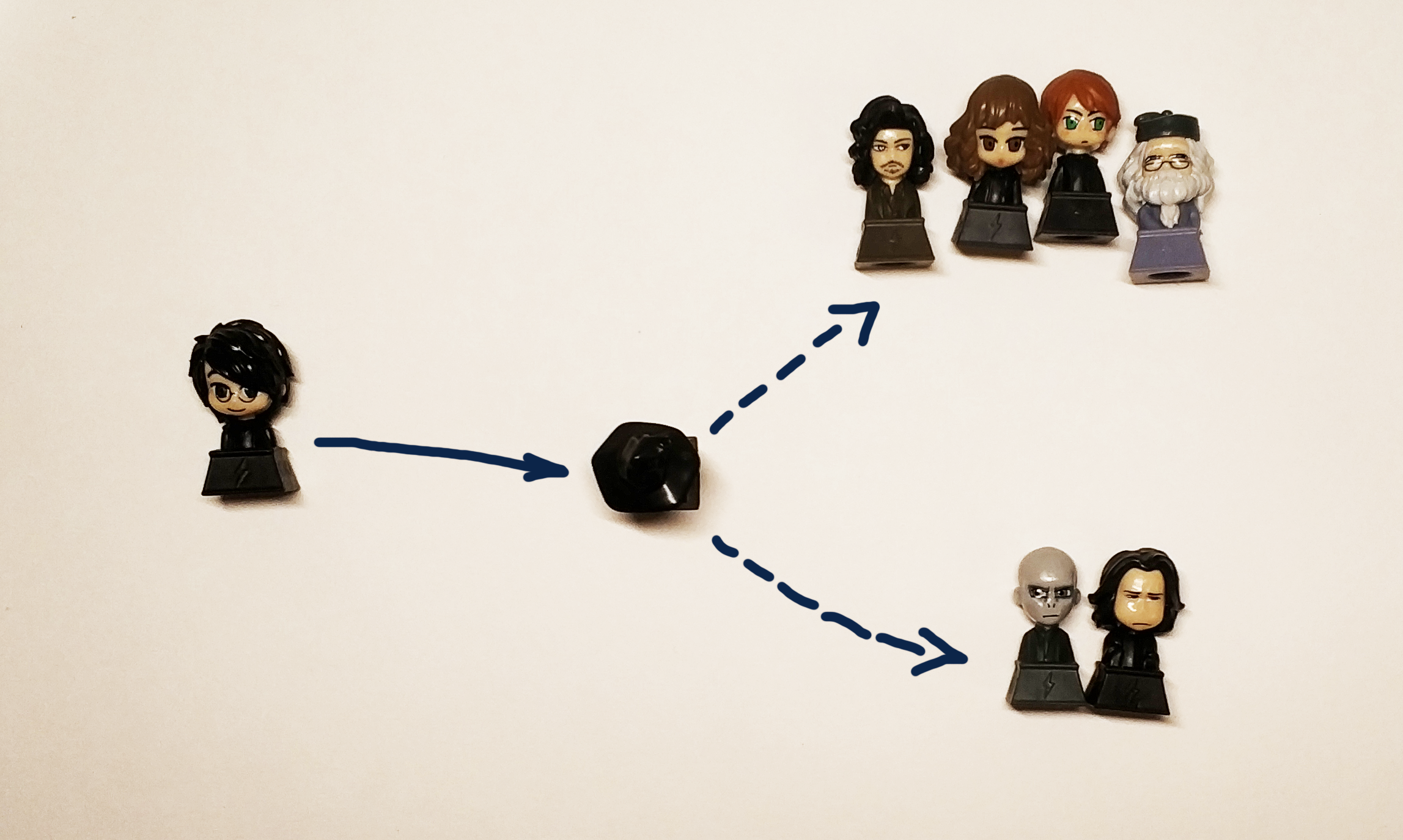
Друзья, в конце марта мы запускаем новый поток по курсу «Data Scientist». И прямо сейчас начинаем делиться с вами полезным материалом по курсу.
Введение
Вспоминая ранний опыт своего увлечения машинным обучением (ML) могу сказать, что много усилий уходило на построение действительно хорошей модели. Я советовался с экспертами в этой области, чтобы понять, как улучшить свою модель, думал о необходимых функциях, пытался убедиться, что все предлагаемые ими советы учтены. Но все же я столкнулся с проблемой.
Как же внедрить модель в реальный проект? Идей на этот счет у меня не было. Вся литература, которую я изучал до этого момента, фокусировалась только на улучшении моделей. Я не видел следующего шага в их развитии.

Именно поэтому я сейчас пишу это руководство. Мне хочется, чтобы вы столкнулись с той проблемой, с которой столкнулся я в свое время, но смогли достаточно быстро ее решить. К концу этой статьи я покажу вам как реализовать модель машинного обучения используя фреймворк Flask на Python.
Введение
Вспоминая ранний опыт своего увлечения машинным обучением (ML) могу сказать, что много усилий уходило на построение действительно хорошей модели. Я советовался с экспертами в этой области, чтобы понять, как улучшить свою модель, думал о необходимых функциях, пытался убедиться, что все предлагаемые ими советы учтены. Но все же я столкнулся с проблемой.
Как же внедрить модель в реальный проект? Идей на этот счет у меня не было. Вся литература, которую я изучал до этого момента, фокусировалась только на улучшении моделей. Я не видел следующего шага в их развитии.
Именно поэтому я сейчас пишу это руководство. Мне хочется, чтобы вы столкнулись с той проблемой, с которой столкнулся я в свое время, но смогли достаточно быстро ее решить. К концу этой статьи я покажу вам как реализовать модель машинного обучения используя фреймворк Flask на Python.