Как мы к этому пришли? Как мы стали вместо решения наших задач, тратить кучи денег на решение проблем, которых у нас нет?

User
Как мы к этому пришли? Как мы стали вместо решения наших задач, тратить кучи денег на решение проблем, которых у нас нет?

Всем привет! Меня зовут Надя, и сейчас я выступаю в роли ментора на программе Mentor in Tech и помогаю людям «войти» в Data Science. А несколькими годами ранее сама столкнулась с задачей перехода в DS из другой сферы, так что обо всех трудностях знаю не понаслышке.
Порог для входа в профессию очень высокий, так как DS стоит на стыке трех направлений: аналитики, математики и программирования. Но освоить специальность — задача выполнимая (хоть и непростая), даже если ты гуманитарий и списывал математику у соседа по парте.
В этой статье я собрала несколько рекомендаций на основе моего личного опыта (как поиска работы, так и найма людей), а также исходя из рассказов знакомых.
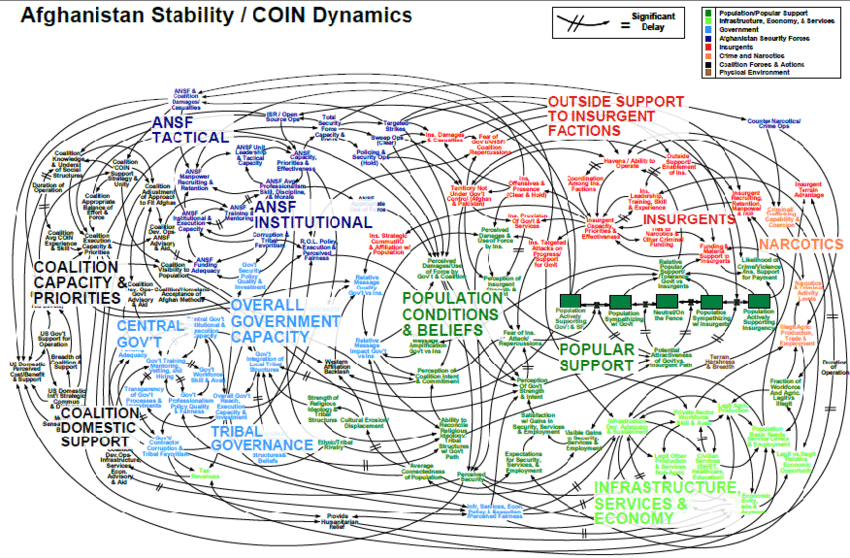
В жизни каждого инженера-фронтендера наступает момент, когда осознаёшь: далее не обойтись без кэширования данных из API. Всё может начаться с самых невинных вещей: сохраняем предыдущую страницу с данными, чтобы кнопка «Назад» срабатывала мгновенно; реализуем простенькую логику отмены действия или обеспечиваем слияние нескольких состояний от различных запросов к API. Но все мы знаем, чем такое кончается. Один за другим возникают запросы на новые фичи, и вскоре мы уже не покладая рук реализуем кэши данных, индексы для работы вручную, оптимистические мутации и рекурсивную инвалидацию кэша.
Эти фичи явственно смахивают на внутренние механизмы баз данных. Действительно, в любом достаточно сложном клиентском приложении программисту непременно придётся реализовывать такое множество фич для управления данными, что эта работа будет напоминать построение предметно-ориентированной базы данных. Такая дополнительная сложность удваивается в каждом проекте, над которым мы работаем, поэтому приходится тратить время на решение бизнес-проблем, а радовать пользователя – уже как успеем.
Поэтому сегодня предлагаю вам составить мне компанию – и мы вместе рассмотрим распространённые паттерны работы с данными приложений, а также разберёмся, как они соотносятся с фичами баз данных. Далее мы рассмотрим решения, которые могли бы стать альтернативами этим паттернам – например, как сделать в клиентской части оптимизированный стек базы данных, который позволил бы нам сосредоточиться на разработке приложения, а не на мелкой возне с данными.
Новое место, новая позиция, новый продукт! Финтех, камунда, ~ 40 (!) микросервисов за которые отвечает наша команда. Первый спринт. Я в роли наблюдателя. В спринте вроде бы обычная задача - нужно вызвать из одного сервиса другой, и обработать результат. Ребята оценивают, начинают работу, и что я вижу в течение следующих дней: один разработчик берёт сервис-сервер, другой сервис-клиент, и каждый начинает реализацию контракта описанного в табличке в confluence. Что-от около десятка полей, если мне не изменяет память. Они уходят на пару дней, возвращаются, начинают тестирование контракта, выясняется что одно или два поля немного различаются в названии, уходят править нейминг, возвращаются, тестируют и только после этого переходят к написанию какой-то логики.
И тут меня понесло. Да, дело не конкретно в этих ребятах или задаче. Или продукте. Или компании. Они просто делают работу как привыкли делать. С точки зрения разработчика - закрыть такую задачу за 3 или 6 дней - нет особой разницы. Над сроками вообще начинаешь заморачиваться только после перехода в роль которая за эти самые сроки хоть как-то отвечает. Но потратить 4 дня силами двух разработчиков только на контрактую обвязку...
Здесь в памяти начали всплывать давние попытки генерации спецификаций по коду. Или документации по коду. Или кода из спецификации. В общем какие-то попытки генерации чего-то связанного с openapi. А дальше мы ушли в углубленное изучение того, как это можно использовать в контексте нашего продукта и большого количества взаимодействий сервисов.

Не секрет, что работа с часовыми поясами — боль, и многие разработчики объяснимо стараются ее избегать. Тем более что в каждом языке программирования / СУБД работа с часовыми поясами реализована по-разному.
Среди тех, кто работает с PostgreSQL, есть очень распространенное заблуждение про типы данных timestamp (который также именуется timestamp without time zone) и timestamptz (или timestamp with time zone). Вкратце его можно сформулировать так:
Мне не нужен тип timestamp with time zone, т.к. у меня все находится в одном часовом поясе — и сервер, и клиенты.
В статье я постараюсь объяснить, почему даже в таком довольно простом сценарии можно запросто напороться на проблемы. А в более сложных (которые на самом деле чаще встречаются на практике, чем может показаться) баги при использовании timestamp практически гарантированы.
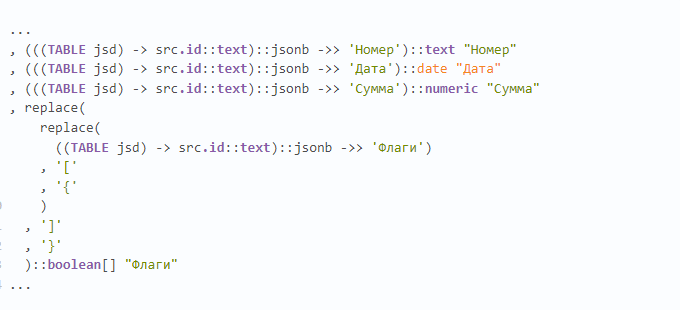
Недавно попался на глаза примерно такой кусок запроса, и тут прекрасно примерно все:
• множество чтений из CTE (хоть и единственной записи, но все же);
• извлечение по каждому ключу текста с раскастовкой в jsonb;
• извлечение каждого отдельного json-ключа в каждое отдельное одноименное поле;
• "ручное" преобразование текстового представления массива в json в текстовое представление PostgreSQL.
А как - правильно?
Рассмотрим вариант добавления трейсов в Spring Boot 3 приложение с использованием Kafka в качестве транспорта и Zipkin в качестве инструмента для трассировки.
Функциональность соберем в автоконфигурацию для подключения к Spring Boot приложениям.

Ранее мы писали статью про реализацию паттерна MVVM на Флаттере. В комментариях к ней просили разобрать связку нашего приложения с базой данных.
Стоит заметить, что локальная БД в данном случае будет использоваться для кеширования данных, получаемых с бэкенда, однако взаимодействие с бэком не будет рассматриваться здесь, так как это тема, достойная отдельной статьи.
Меня зовут Ричард, и я младший разработчик в компании Digital Design.
Здесь будет разобрана конкретная реализация, однако я постараюсь использовать максимально общий язык для описания происходящего.

Эта статья о том как отправлять и обрабатывать HTTP-запросы непосредственно из/в PostgreSQL. Автор расскажет о том, что такое асинхронное уведомление в PostgreSQL, и наглядно продемонстрирует, как с его помощью можно взаимодействовать с внешними системами из самой СУБД.


Гуд ньюз эвриван! Спустя полтора года работы восьми айтишников с суммарным опытом в IT 130 лет достигнут результат в виде учебника по тестированию, которого еще никто и никогда не делал.

Всем привет, на связи Никита Пятаков, Android-разработчик в МТС Диджитал. В этой статье я расскажу вам о том, как в приложении Мой МТС была проведена работа над UI новой карточки услуги. Рассказ мой будет последовательным – сначала про саму задачку, потом про решение, которое разбито на подпункты.

В этой статье мы рассмотрим процесс создания и автоматизации моста Ethernet/Wi-Fi с
использованием Raspberry Pi и обсудим потенциальные угрозы безопасности,
которые могут возникнуть для корпоративных сетей.

В августе 2023 года компания «Открытая мобильная платформа» опубликовала Flutter SDK с начальной поддержкой ОС Аврора. Статья поможет разобраться, как настроить инструменты разработки, а также раскроет секрет написания плагинов для расширения возможностей работы с платформозависимым API.

Серверные компоненты React – это большой кусок работы. Недавно мы переосмыслили нашу документацию и устроили ребрендинг Mux. Пока мы этим занимались, мы перенесли весь материал сайтов mux.com и docs.mux.com на серверные компоненты. Так что, поверьте мне… я знаю. Знаю, что это возможно, не так страшно и, в принципе, что дело того стоит.
Давайте я вам объясню, почему, ответив на следующие вопросы: почему так важны серверные компоненты, а также для чего они хороши? Для чего они не так хороши? Как их использовать, как их постепенно внедрять и какие продвинутые паттерны следует использовать, чтобы всем этим управлять? Дочитав эту статью, вы станете замечательно представлять, следует ли вам использовать серверные компоненты React, а если следует – то как использовать их эффективно.

Всем привет! Меня зовут Борис Вербицкий, и я представитель того редкого типа iOS разработчиков, которые тепло относятся к Kotlin Multiplatform Project и рады появлению Compose Multiplatform. Здесь я решил поделиться своим опытом использования этих технологий, а также кое-какими размышлениями вокруг процессов с такой разработкой. Цель этой статьи - это поднять обсуждение предложенного мной подхода, послушать все за и против в комментариях.
Приятного чтения!

Всем привет, на связи IT-сообщество Газпромбанка, и меня зовут Грошев Павел. Я занимаюсь разработкой на языке программирования Python, и уже больше года, создаю загрузчики внешних данных для нашей DataFactory – внутрибанковской платформы больших данных.
Сегодня я расскажу, об одном интересном механизме, который, как мне кажется, может упростить жизнь разработчиков и/или команд поддержки работы DAGов Airflow и ETL-процессов.

О пет-проектах знают на Хабре многие. У кого-то такой проект крайне сложный, у кого-то попроще. И разрабатываются такие проекты с разной целью — от just for fun до обучения или доказать самому себе — «Я могу». На самом деле, пет-проекты — отличный вариант для практического обучения начинающих программистов. Да и опытные профессионалы, освоив новую технологию, тоже часто делают на базе полученных знаний что-то новое, чтобы закрепить в памяти и получить новый навык. Но максимальный профит от домашних проектов всё же получают новички. Кстати, эта статья — именно для начинающих разработчиков.

Вторая часть — https://habr.com/ru/post/563484/
Вокруг темы синтеза речи сейчас много движения: на рынке есть огромное число тулкитов для синтеза, большое число закрытых коммерческих решений за АПИ (как на современных технологиях, так и на более старых, т.е. "говорилки") от условных GAFA компаний, большое количество американских стартапов, пытающихся сделать очередные аудио дипфейки (voice transfer).
Но мы не видели открытых решений, которые бы удовлетворяли одновременно следующим критериям:
16kHz так и в 8kHz из коробки;Мы попытались учесть все эти пункты и представить комьюнити свое открытое некоммерческое решение, удовлетворяющее этим критериям. По причине его публичности мы не заостряем внимание на архитектуре и не фокусируемся на каких-то cherry picked примерах — вы можете оценить все сами, пройдя по ссылке.