Именно такие претензии я услышал от наших девелоперов. Самое интересное, что это оказалось правдой, дав начало длительному расследованию. Речь пойдет про SQL servers, которые крутятся у нас на VMware.

User
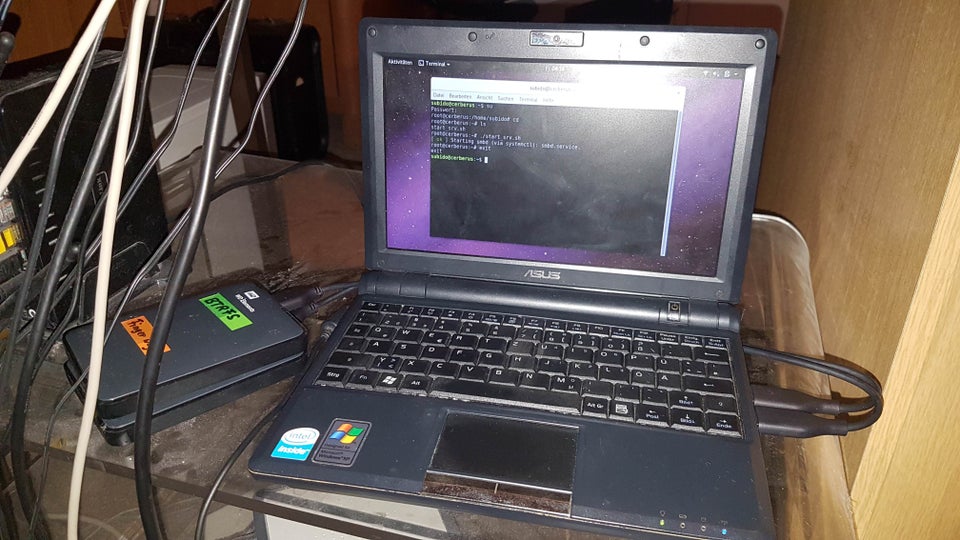
Когда строка изменяется командой UPDATE, фактически выполняются две операции: DELETE и INSERT. В текущей версии строки устанавливается xmax, равный номеру транзакции, выполнившей UPDATE. Затем создается новая версия той же строки; значение xmin у нее совпадает с значением xmax предыдущей версии.Через какое-то время после завершения этой транзакции старая или новая версии, в зависимости от
COMMIT/ROOLBACK, будут признаны «мертвыми» (dead tuples) при проходе VACUUM по таблице и зачищены.

ON UPDATE, переносящий все изменения в какие-нибудь агрегаты. А вам надо все пообновлять (новое поле проинициализировать, например) так аккуратно, чтобы эти агрегаты не затронулись.BEGIN;
ALTER TABLE ... DISABLE TRIGGER ...;
UPDATE ...; -- тут долго-долго
ALTER TABLE ... ENABLE TRIGGER ...;
COMMIT;ALTER TABLE накладывает AccessExclusive-блокировку, под которой никто параллельно выполняющийся, даже простой SELECT, ничего из таблицы прочитать не сможет. То есть пока эта транзакция не закончится, все желающие даже «просто почитать» будут ждать. А мы помним, что UPDATE у нас до-о-олгий…


Довольно типичная схема при разработке системы, когда основная логика обработки сосредоточена в приложении (в нашем случае Erlang), а данные для работы этого приложения (настройки, профили пользователей и т. д.) в базе данных (PostgreSQL). Приложение Erlang кэширует настройки в ETS для ускорения обработки и снижения нагрузки на БД путём отказа от постоянных запросов. При этом изменение этих данных происходит через отдельный (возможно, внешний) сервис.
В таких ситуациях встаёт задача поддержания закэшированных данных в актуальном состоянии. Есть разные подходы для решения этой задачи. Один из них — это логическая репликация PostgreSQL. О нем и пойдёт речь ниже.





Перевод статьи подготовлен для студентов курса «Администратор Linux».
Ранее я рассказал о том, как проверить и включить использование Hugepages в Linux.
Эта статья будет полезна, только если у вас действительно есть, где использовать Hugepages. Я встречал множество людей, которые обманываются перспективой того, что Hugepages волшебным образом повысят производительность. Тем не менее hugepaging является сложной темой, и при неправильном использовании он способен понизить производительность.
На написание данной статьи меня вдохновила статья об анализе Сишного printf. Однако, там был пропущен момент о том, какой путь проходят данные после того, как они попадают в терминальное устройство. В данной статье я хочу исправить этот недочет и проанализировать путь данных в терминале. Также мы разберемся, чем отличается Terminal от Shell, что такое Pseudoterminal, как работают эмуляторы терминалов и многое другое.

git clone https://www.bamsoftware.com/git/zipbomb.gitzipbomb-20190702.zip
git clone https://www.bamsoftware.com/git/zipbomb-paper.git
 Клифф Клик — CTO компании Cratus (IoT сенсоры для улучшения процессов), основатель и сооснователь нескольких стартапов (включая Rocket Realtime School, Neurensic и H2O.ai) с несколькими успешными экзитами. Клифф написал свой первый компилятор в 15 лет (Pascal для TRS Z-80)! Наиболее известен за работу над С2 в Java (the Sea of Nodes IR). Этот компилятор показал миру, что JIT может производить качественный код, что стало одним из факторов становления Java как одной из основных современных программных платформ. Потом Клифф помог компании Azul Systems построить 864-ядерный мейнфрейм с софтом на чистой Java, который поддерживал паузы GC на 500-гигабайтной куче в пределах 10 миллисекунд. Вообще, Клифф успел поработать над всеми аспектами JVM.
Клифф Клик — CTO компании Cratus (IoT сенсоры для улучшения процессов), основатель и сооснователь нескольких стартапов (включая Rocket Realtime School, Neurensic и H2O.ai) с несколькими успешными экзитами. Клифф написал свой первый компилятор в 15 лет (Pascal для TRS Z-80)! Наиболее известен за работу над С2 в Java (the Sea of Nodes IR). Этот компилятор показал миру, что JIT может производить качественный код, что стало одним из факторов становления Java как одной из основных современных программных платформ. Потом Клифф помог компании Azul Systems построить 864-ядерный мейнфрейм с софтом на чистой Java, который поддерживал паузы GC на 500-гигабайтной куче в пределах 10 миллисекунд. Вообще, Клифф успел поработать над всеми аспектами JVM.
Этот хабрапост — большое интервью с Клиффом. Мы поговорим на следующие темы:
Интервью ведут:
Сегодня поговорим об архитектурных подходах в iOS-разработке, про некоторые нюансы и наработки реализации отдельных вещей. Расскажу, каких подходов придерживаемся мы и немного углубимся в детали.