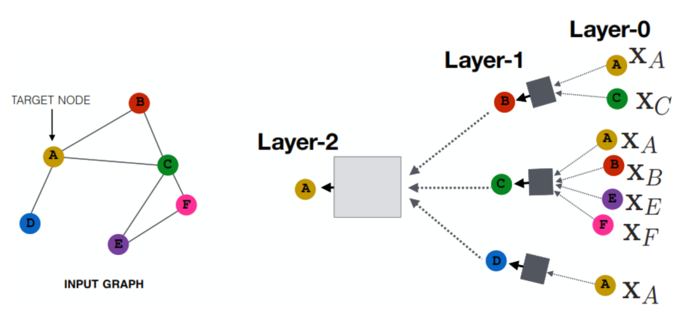
Интеграция DMR858M: Практическое руководство по созданию пользовательских цифровых раций на ESP32

В области разработки встраиваемых систем интеграция радиочастотных (РЧ) функций в продукт часто сопряжена со сложным проектированием аппаратного обеспечения и трудоемкой реализацией стека протоколов. Модуль DMR858M значительно упрощает этот процесс, предоставляя высокоинтегрированную подсистему цифровой мобильной радиосвязи (DMR) с мощностью передачи до 5 Вт.1 Это не просто РЧ-трансивер, а комплексное решение, внутренне объединяющее микроконтроллер (MCU), чип цифровой рации, РЧ-усилитель мощности и аудиоусилитель.1 Такая конструкция позволяет разработчикам управлять полнофункциональным ядром рации — поддерживающим стандарт DMR Tier II, совместимым с традиционными аналоговыми режимами и оснащенным функциями SMS и шифрования голоса — через простой последовательный интерфейс.1