Код зависим от данных и моделей, а значит от абстракций используемых в них, поэтому рефакторинг неминуем сегодня. Почему? Обычно под рефакторингом подразумевают реорганизацию кода из соображений необходимости использовать данные по-новому. Мы поговорим о самом частом и нелюбимом типе рефакторинга - лавинообразный рефакторинг, возникающий при изменениях в моделях данных, структурах таблиц и бизнес логике.
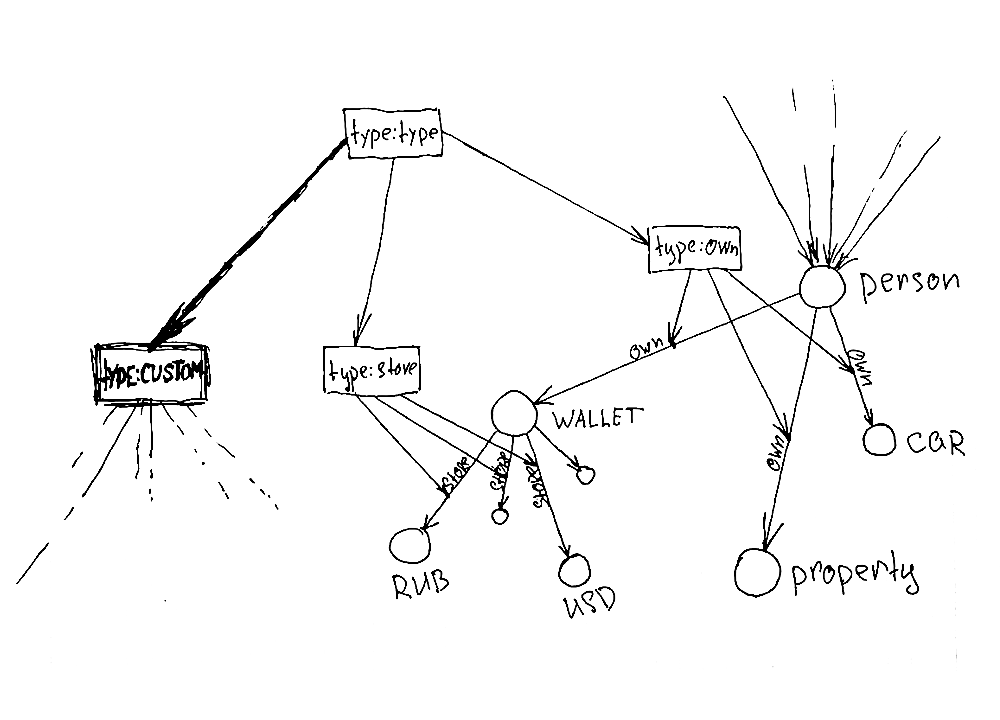
Философия Deep описывает всё концепцией Link. Любой объект это Link, любое отношение это Link. У отношения всегда указаны
fromиto. У самостоятельного объектаfromиtoне указаны. Это также отличает Deep философию от графовых баз данных, там edge не может служить объектом отношений.

Что может меняться в зависимости от моделей данных?
Переименование полей.
Изменение отношений one to one/many
Добавление абстракций
Устаревание абстракций
Всегда можно попробовать залатать проблемы с обратной совместимости добавлением новых адаптеров и слоёв. Но эта борьба с симптомами лишь отложит последствия настоящей проблемы. С каждым изменением бизнес логики эффект луковицы будет только нарастать. И будет становиться больше абстракций которые переплетены друг с другом.

Многие программисты поспорят - это вопрос чистоты кода. Мы не согласны. Чистота кода, это только про его реализацию. Проблема не в том, как мы пишем код, как бы сильно нам не хотелось в это верить. Проблема в том, что он в принципе зависим от абстракций бизнес логики, и пытаясь исправить последствия этой проблемы программисты не уменьшают сложность кода, а лишь помножают её. В то же время программисты окружают себя мнимыми ощущениями комфорта и контроля на ситуацией.
Deep.Case ставит целью победить этого врага. Модели данных могут развиваться вообще не приводя к рефакторингу. Как? Для того что бы объяснить, разберемся в причинах проблем.
Переименование полей
Архитектура может быть разная. Вы можете использовать GraphQL и генераторы схем, или сопоставлять API и абстракции данных через ORM/ODM самостоятельно, пробрасывая правила работы с таблицами кодом. У вас может быть функциональное API и REST API с сервера. Но, вероятно, в любом случае схема работы с этими API будет определена либо на уровне API, либо на уровне имен колонок в таблицах. Таким образом, мы компенсируем вынужденные изменения оплатой разработчиков на то, чтобы обновить базу данных, генераторы, резолверы и API. Проблема здесь - разделение реализации функционала и интеграции его в бизнес логику. Этот один слой абстракции помножается на пересечения условий бизнес логики и обстоятельства связей между колонками, в итоге делая цену каждой волны сильно зависимой от возраста проекта. Точно подсчитать фактор зависимости не удалось, но эта цена всегда оказывается кратно больше стоимости самой модификации полей и конечного изменившегося поведения в бизнес сценарии.

Здесь же приходится учитывать права доступа и любые иные бизнес правила. Это увеличивает цену таких волн рефакторинга кратно правилам бизнес логики. Deep.Case позволяет полностью забыть об этой проблеме!
Изменение отношений one to one/many
Как бы мы не тешили себя иллюзиями, что можем все предугадать, это очевидно не так. Любая, даже самая идеальная модель, будет меняться. То, что мы считали единственной связью, станет множественной. То, что мы считали множественной из одной таблицы, начнет ссылаться из нескольких. Модели, задуманные к применению в одних местах, становятся необходимы во многих прочих. Каждое такое изменение сегодня снова требует участия разработчика.
С Deep.Case данные делятся на:
связи используемые в качестве нодов (точек), отвечающих на вопрос
ЧТО, как например: платеж, объем, потребность, момент, и любые иныесвязи используемые в качестве отношений (связей), отвечающих на вопрос
КАК СВЯЗАНО, как например: X хочет Y, W просмотрел Z, T владеет R, T отвечает на Pкастомные таблицы поставляемые моделями данных, доступные из линка соответствующего типа. Предназначение таких таблиц - обеспечить хранение кастомных, не ссылочных, данных которые удобнее описать в отдельной таблице.

Связи, описывающие отношения, изначально не ограничены системой, как one/many. На уровне модели могут быть описаны, и в дальнейшем изменены правила создания связей каждого типа.
Это значит, что для перехода от oneк many достаточно разрешить создавать несколько связей определенного типа.
Во всех обработчиках и клиентских интерфейсах рекомендуется исходить из итерируемости каждого подмножества. При начальном производстве учитывать это очень дешево. Просто даже если мы думаем что связь такого типа бывает только в одном экземпляре, нужно подразумевать что их может статься множество.
Добавление новых уровней абстракций
Например, когда нужно создать новый способ связи и новые сущности. С Deep.Case больше не нужно проходить полный цикл изменения структуры данных, моделей ORM/ODM, или учитывать как код отражает требуемые абстракции, и его негибкость тормозят изменения бизнес логики. Для такого рода изменений больше не нужен backend developer. Достаточно создать новый тип связей и описать, при каких обстоятельствах в окружающем пространстве эта связь может создаваться и меняться. Она сразу станет доступна через единый GraphQL/REST API, никак не повредив старым абстракциям и связям, а значит зависимому от них коду.
Деприкейт старых уровней абстракций
Так как больше нет самописного слоя резолверов API, деприкейт старых абстракций сводится к рекомендации не использования определенных связей в новом коде. Но, так как на их существование может быть завязано некоторое подмножество интерфейсов и обработчиков, их существование можно просто поддержать на уровне базы. Даже если пакет поставляющий модель данных хочет перейти на другой тип связей, ничто не мешает, создавая новые связи, поддерживать зеркальные структуры, создавая их на основе новых.
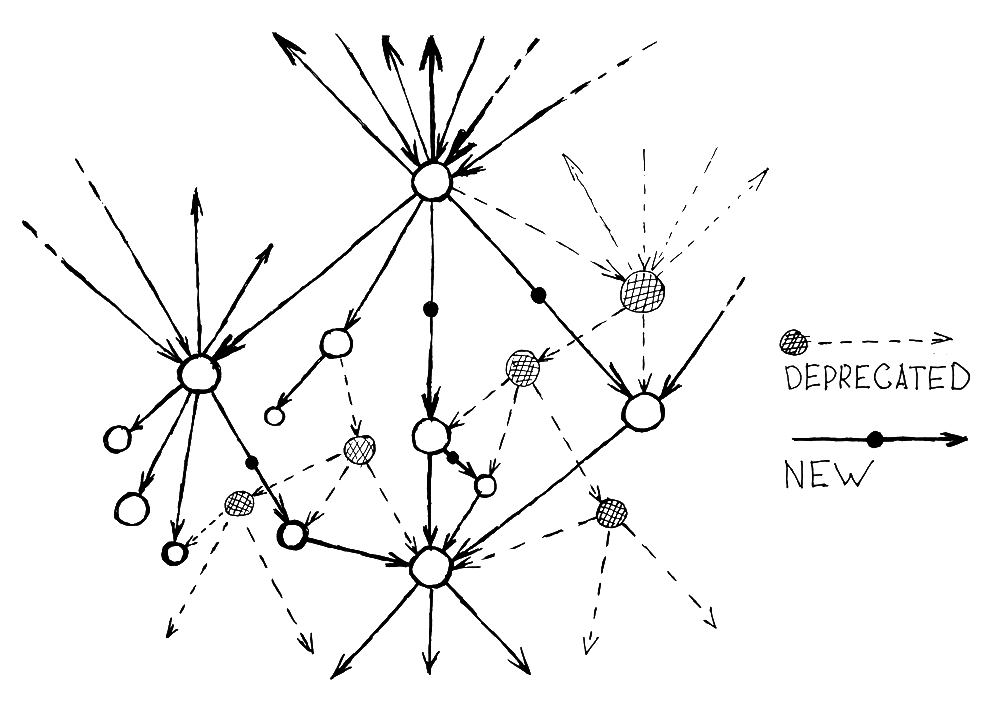
Поддержите ассоциативные технологии
Мы создаем среду разработки (коробочную CE/EE версию и SaaS версию), позволяющую использовать ассоциативный подход для решения ваших бизнес задач, нуждающихся в хранении данных, с возможностью адаптации под любые изменения бизнеса. Мы создадим распределённую сеть серверных кластеров в едином ассоциативном пространстве, в том числе чтобы не думать о региональном законодательстве, создавая проект. Мы создаём культуру публикации повторно используемых моделей данных с их поведением.
Присоединяйтесь к нашему сообществу в Discord. Подпишитесь на ранний доступ в нашем Waitlist или поддержите нас на Patreon.
На нашем сайте можно найти ссылки на черновики будущих статей находящихся в разработке, ссылки на исходники кода, планы по project и product менеджменту и invest презентации.

