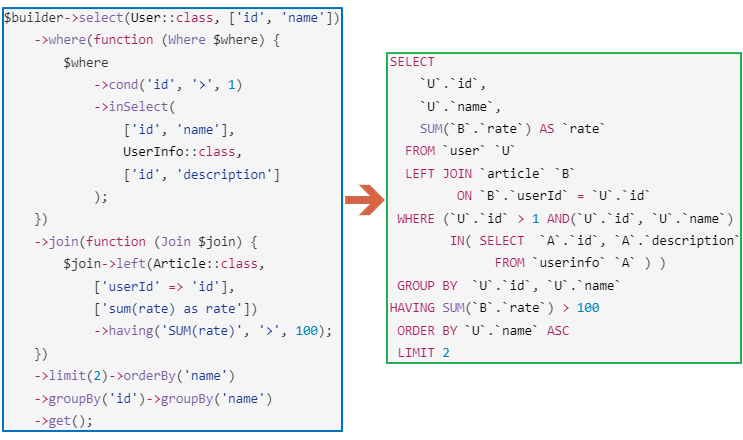
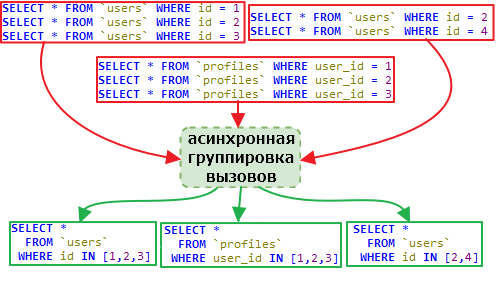
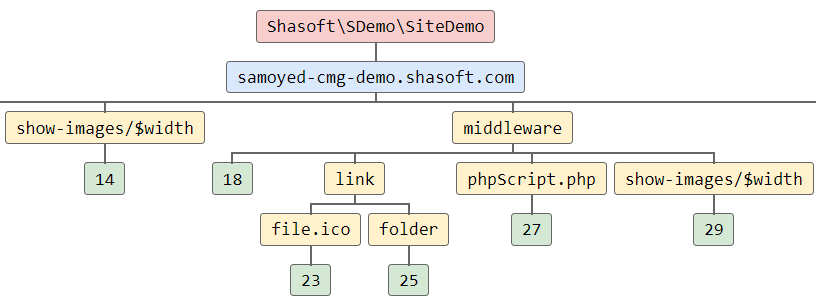
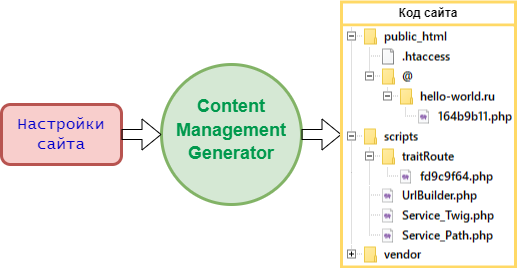
Я писал ранее статью Генерация API сайта на основе заданных пользователем функций, однако информация там была о конечной реализации (к тому же теоретической), и, ожидаемо, никто не понял для чего это вообще нужно. Поэтому попробую расписать это с другой стороны: от задачи к её решению через генерируемое в Samoyed CMG API.
Описание задачи
Пусть у нас есть небольшой сайт со списком статей с пагинацией. Статьи пишут пользователи сайта.
На главной странице выводим список последних 10 статей. В списке заголовок и автор. При нажатии на заголовок выводится страница с выбранной статьёй. На странице статьи выводится заголовок, содержимое + автор.
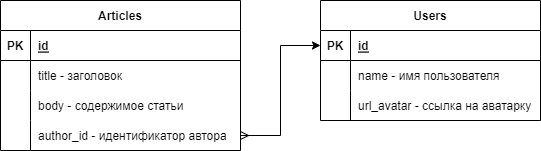
Простейшая схема таблиц базы данных представлена ниже.