Совсем недавно мы искали дата-сайентиста в команду (и нашли — привет,
nik_son и Арсений!). Пока общались с кандидатами, поняли, что многие хотят сменить место работы, потому что делают что-то «в стол».
Например, берутся за сложное прогнозирование, которое предложил начальник, но проект останавливается — потому что в компании нет понимания, что и как включить в продакшен, как получить прибыль, как «отбить» потраченные на новую модель ресурсы.

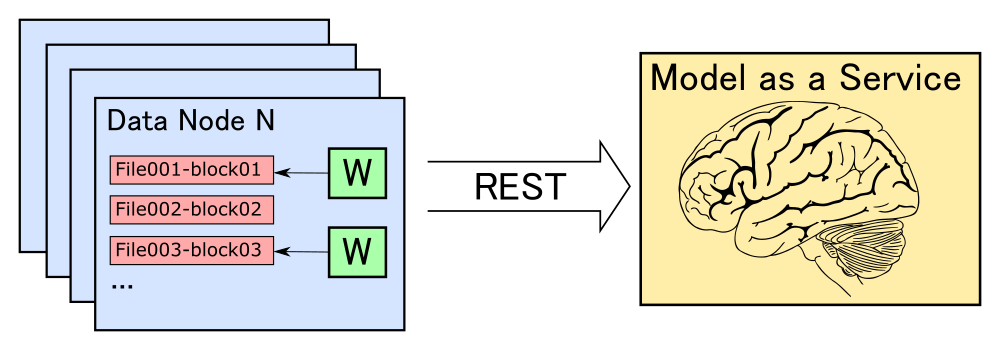
У HeadHunter нет больших вычислительных мощностей, как у «Яндекса» или Google. Мы понимаем, как нелегко катить в продакшен сложный ML. Поэтому многие компании останавливаются на том, что катят в прод простейшие линейные модели.
В процессе очередного внедрения ML в рекомендательную систему и в поиск по вакансиям мы столкнулись с некоторым количеством классических «граблей». Обратите на них внимание, если собираетесь внедрять ML у себя: возможно, этот список поможет по ним не ходить
и найти уже свои, персональные грабли.


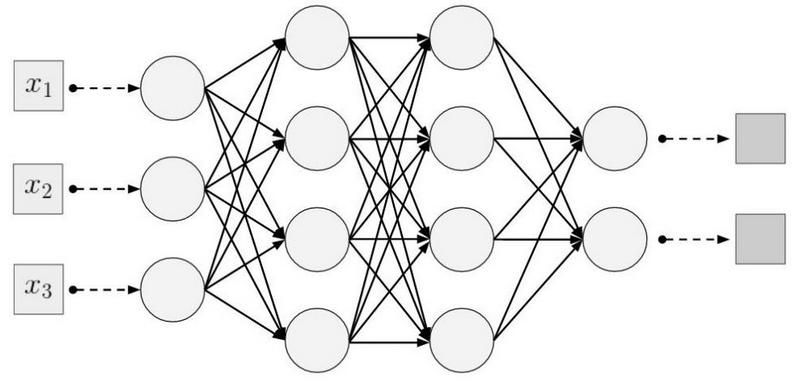






 Этот список появился как личная памятка по темам, которые я обсуждал с коллегами и друзьями и в которых хотел разобраться поглубже…
Этот список появился как личная памятка по темам, которые я обсуждал с коллегами и друзьями и в которых хотел разобраться поглубже…