Прошлый топик, про оценку сложности алгоритмов был весьма положительно оценён хабрасообществом. Из этого я могу сделать вывод, что тема базовых алгоритмов весьма интересна. Сегодня я хочу представить вам часть, посвящённую алгоритмам сортировки. Про базовые алгоритмы писать для Хабра совсем несерьёзно, а вот про сортировки Шелла, пирамидальную и быструю рассказать всё-таки стоит. (Если кому-то интересно почитать про базовые методы, милости прошу сюда)

Костюков Владимир @spiff
Пользователь
Задача RMQ — 1. Static RMQ
4 min
Введение
Задача RMQ весьма часто встречается в спортивном и прикладном программировании. Удивительно, что на Хабре ещё никто не упомянул эту интересную тему. Попробую восполнить пробел.
Аббревиатура RMQ расшифровывается как Range Minimum (Maximum) Query – запрос минимума (максимума) на отрезке в массиве. Для определённости мы будем рассматривать операцию взятия минимума.
Пусть дан массив A[1..n]. Нам необходимо уметь отвечать на запрос вида «найти минимум на отрезке с i-ого элемента по j-ый».
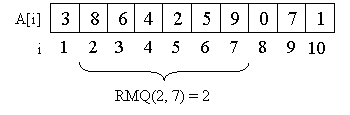
Рассмотрим в качестве примера массив A = {3, 8, 6, 4, 2, 5, 9, 0, 7, 1}.
Например, минимум на отрезке со второго элемента по седьмой равен двум, то есть RMQ(2, 7) = 2.
В голову приходит очевидное решение: ответ на каждый запрос будем находить, просто пробегаясь по всем элементам массива, лежащим на нужном нам отрезке. Такое решение, однако, не является самым эффективным. Ведь в худшем случае нам придётся пробежаться по O(n) элементам, т.е. временная сложность этого алгоритма – O(n) на один запрос. Однако, задачу можно решить эффективнее.
Как работать «в потоке»? Нужны всего 3 ресурса
5 min

Знакомо ли вам такое состояние, когда вы настолько увлечены идеей, что полностью погружаетесь в процесс ее реализации, забывая о времени и окружающем мире? А завершив, испытываете радость и даже счастье? Значит, у вас есть опыт потоковых состояний – особых ресурсных состояний сознания, когда все внимание сфокусировано на цели, и в результате замечательные идеи рождаются сами собой, и время концентрируется, вмещая гораздо больше, чем в обычном состоянии.
Тема эффективности потоковых состояний для работы и творчества уже несколько раз поднималась на Хабре, и в этой статье мы хотим обсудить практическую часть – что необходимо для того, чтобы вызывать это состояние «на заказ»?
Опции JVM. Как это работает
7 min
С каждым днем слово java все больше и больше воспринимается уже не как язык, а как платформа благодаря небезызвестному invokeDynamic. Именно поэтому сегодня я бы хотел поговорить про виртуальную java машину, а именно — об так называемых Performance опциях в Oracle HotSpot JVM версии 1.6 и выше (server). Потому что сегодня почти не встретить людей, которые знают что-то больше чем -Xmx, -Xms и -Xss. В свое время, когда я начал углубляться в тему, то обнаружил огромное количество интересной информации, которой и хочу поделится. Отправной точкой, понятное дело, послужила официальная документация от Oracle. А дальше — гугл, эксперименты и общение:
Начну, пожалуй, с самой интересной опции — DoEscapeAnalysis. Как многие из Вас знают, примитивы и ссылки на объекты создаются не в куче, а выделяются на стеке потока (256КБ по умолчанию для Hotspot). Вполне очевидно, что язык java не позволяет создавать объекты на стеке на прямую. Но это вполне себе может проделывать Ваша JVM 1.6 начиная с 14 апдейта.
Про то, как работает сам алгоритм можно прочитать тут (PDF). Если коротко, то:
Для реализации данного алгоритма строится и используется так называемый — граф связей (connection graph), по которому на этапе анализа (алгоритмов анализа — несколько) осуществляется проход для нахождения пересечений с другими потоками и методами.
Таким образом после прохода графа связей для любого объекта возможно одно из следующих следующих состояний:
После этапа анализа, уже сама JVM проводит возможную оптимизацию: в случае если объект NoEscape, то он может быть создан на стеке; если объект NoEscape или ArgEscape, то операции синхронизации над ним могут быть удалены.
Следует уточнить, что на стеке создается не сам объект а его поля. Так как JVM заменяет цельный объект на совокупность его полей (спасибо Walrus за уточнение).
Вполне очевидно, что благодаря такого рода анализу, производительность отдельных частей программы может возрасти в разы. В синтетических тестах, на подобии этого:
скорость выполнения может увеличится в 8-15 раз. Хотя, на казалось бы, очевидных случаях из практики о которых недавно писалось (тут и тут) EscapeAnalys не работает. Подозреваю, что это связано с размером стека.
Кстати, EscapeAnalysis как раз частично ответственен за известный спор про StringBuilder и StringBuffer. То есть, если Вы вдруг в методе использовали StringBuffer вместо StringBuilder, то EscapeAnalysis (в случае срабатывания) устранит блокировки для StringBuffer'а, после чего StringBuffer вполне превращается в StringBuilder.
-XX:+DoEscapeAnalysis
Начну, пожалуй, с самой интересной опции — DoEscapeAnalysis. Как многие из Вас знают, примитивы и ссылки на объекты создаются не в куче, а выделяются на стеке потока (256КБ по умолчанию для Hotspot). Вполне очевидно, что язык java не позволяет создавать объекты на стеке на прямую. Но это вполне себе может проделывать Ваша JVM 1.6 начиная с 14 апдейта.
Про то, как работает сам алгоритм можно прочитать тут (PDF). Если коротко, то:
- Если область видимости объекта не выходит за область метода, в котором он создается, то такой объект может быть создан на фрейме стека вместо кучи (на самом деле не сам объект, а его поля, на совокупность которых заменяется объект);
- Если объект не покидает область видимости потока, то к такому объекту другие потоки не имеют доступа и следовательно все операции синхронизации над объектом могут быть удалены.
Для реализации данного алгоритма строится и используется так называемый — граф связей (connection graph), по которому на этапе анализа (алгоритмов анализа — несколько) осуществляется проход для нахождения пересечений с другими потоками и методами.
Таким образом после прохода графа связей для любого объекта возможно одно из следующих следующих состояний:
- GlobalEscape — объект доступен из других потоков и из других методов, например статическое поле.
- ArgEscape — объект был передан как аргумент или на него есть ссылка из объекта аргумента, но сам он не выходит из области видимости потока в котором был создан.
- NoEscape — объект не покидает область видимости метода и его создание может быть вынесено на стек.
После этапа анализа, уже сама JVM проводит возможную оптимизацию: в случае если объект NoEscape, то он может быть создан на стеке; если объект NoEscape или ArgEscape, то операции синхронизации над ним могут быть удалены.
Следует уточнить, что на стеке создается не сам объект а его поля. Так как JVM заменяет цельный объект на совокупность его полей (спасибо Walrus за уточнение).
Вполне очевидно, что благодаря такого рода анализу, производительность отдельных частей программы может возрасти в разы. В синтетических тестах, на подобии этого:
for (int i = 0; i < 1000*1000*1000; i++) {
Foo foo = new Foo();
}
скорость выполнения может увеличится в 8-15 раз. Хотя, на казалось бы, очевидных случаях из практики о которых недавно писалось (тут и тут) EscapeAnalys не работает. Подозреваю, что это связано с размером стека.
Кстати, EscapeAnalysis как раз частично ответственен за известный спор про StringBuilder и StringBuffer. То есть, если Вы вдруг в методе использовали StringBuffer вместо StringBuilder, то EscapeAnalysis (в случае срабатывания) устранит блокировки для StringBuffer'а, после чего StringBuffer вполне превращается в StringBuilder.
English Learning Hacks
2 min
Многим понравился первый пост об хаках в изучении английского. Настал момент для второго, финального.
Презумпция виновности программиста или почему компилятор иногда «тупит»
12 min

Этот пост снова посвящается цикловым оптимизациям. Почему вообще речь зашла о цикловых перестановочных оптимизациях? Дело в том, что это одна из самых эффективных частей оптимизирующего компилятора. В число цикловых перестановочных оптимизаций входит как автовекторизация так и автопараллелизация. У этих оптимизаций существует своя специфика, но в целом у всех цикловых оптимизаций общие проблемы и общие методы их решения.
Часто приходится слышать мнение, что компилятор во многих случаях «тупит». Мне хочется здесь побыть адвокатом компилятора, чтобы показать, что жизнь компилятора не так уж легка, возможно вызвать легкую долю сочувствия к его нелегкой доле и показать, какие существуют объективные трудности при обработке программы и почему во многих случаях компилятор совершенно обоснованно не может сделать ту или иную оптимизацию, которая кажется очевидной программисту. Ну и заодно я хочу продемонстрировать некоторые возможности помочь компилятору в его работе. Понятно, что иногда существуют и субъективные факторы, в лице разработчиков, которые по како-либо причине не реализовали ту или иную функциональность внутри компилятора.
Особенности обработки исключений в Windows
4 min
Прочитав недавний топик "Использование try — catch для отладки" решил все таки в качестве дополнения поделиться и своим опытом.
В этой статье предлагаю рассмотреть получение callstack’а места, где было брошено исключение в случае работы со
получение callstack’а места, где было брошено исключение в случае работы со
структурными исключениями (MS Windows). В детали работы исключений вдаваться не будем, т.к. это тянет на отдельный цикл статей (для интересующихся рекомендую Рихтера, MSDN и wasm.ru). Конечно, есть много уже готовых проектов для генерации
Что делать с полученным стеком вызовов — решать вам. Можно смотреть отладчиком, можно записать в файл и смотреть сторонней программой (для этого не забудьте записать список загруженных модулей с их адресами, а так же вам понадобятся отладочные символы).
В этой статье предлагаю рассмотреть
получение callstack’а места, где было брошено исключение в случае работы со структурными исключениями (MS Windows). В детали работы исключений вдаваться не будем, т.к. это тянет на отдельный цикл статей (для интересующихся рекомендую Рихтера, MSDN и wasm.ru). Конечно, есть много уже готовых проектов для генерации
minidump’ов (например CrashRpt или google-breakpad), так что эта статья носит больше образовательный характер.Что делать с полученным стеком вызовов — решать вам. Можно смотреть отладчиком, можно записать в файл и смотреть сторонней программой (для этого не забудьте записать список загруженных модулей с их адресами, а так же вам понадобятся отладочные символы).
Алгоритм поиска пути Jump Point Search
6 min
Этот алгоритм является улучшенным алгоритмом поиска пути A*. JPS ускоряет поиск пути, “перепрыгивая” многие места, которые должны быть просмотрены. В отличие от подобных алгоритмов JPS не требует предварительной обработки и дополнительных затрат памяти. Данный алгоритм представлен в 2011 году, а в 2012 получил высокие отклики. Что из себя представляет данный алгоритм и его реализацию можно прочитать дальше в статье.
Тренды в образовательной среде (памятка для вуза)
6 min
Добрый день!

Ниже небольшая заметка, адресованная тем, кто так или иначе влияет на академическое образование в нашей стране. Потому как после трёх лет упорной работы по развитию пресловутого «образования 2.0» я вынужден сделать вывод, что слишком мало руководителей нашей высшей школы понимают общую стратегию мировой академической среды.
Я постарался собрать в этот пост основную выжимку, чтобы любой мог дать ссылку на него и сказать «вот, посмотри куда всё движется». И может быть это добежит до ректората какого-нибудь хорошего вуза.
Итак, сначала немного пафоса.
Ниже небольшая заметка, адресованная тем, кто так или иначе влияет на академическое образование в нашей стране. Потому как после трёх лет упорной работы по развитию пресловутого «образования 2.0» я вынужден сделать вывод, что слишком мало руководителей нашей высшей школы понимают общую стратегию мировой академической среды.
Я постарался собрать в этот пост основную выжимку, чтобы любой мог дать ссылку на него и сказать «вот, посмотри куда всё движется». И может быть это добежит до ректората какого-нибудь хорошего вуза.
Итак, сначала немного пафоса.
Простое написание тестов — это не TDD!
4 min
Translation
Эта статья представляет собой хороший теоретический материал о TDD для тех, кто об этом ещё ничего не знает.
Карьера программиста, или Cracking Coding Interview
4 min
Для одного из наших первых постов-рецензий мы выбрали замечательную книгу, которую рекомендуем каждому программисту, желающему совершенствоваться и развиваться как профессионалу. Это пятое издание одного из западных бестселлеров среди книг по программированию — Cracking the Coding Interview: 150 Programming Interview Questions and Answers, получившая в русском издании название «Карьера программиста. Как устроиться на работу в Google, Microsoft или другую ведущую IT-компанию».

Для книги IT-тематики эта книга имеет совершенно невероятный рейтинг на сайте Amazon’а (на 6 сентября это #388 в общем рейтинге книг и №1 – для раздела «Computers & Technology»), поэтому я как куратор данного проекта был просто счастлив, когда «Питер» получил эксклюзивные права на издание этого бестселлера в России.
Для книги IT-тематики эта книга имеет совершенно невероятный рейтинг на сайте Amazon’а (на 6 сентября это #388 в общем рейтинге книг и №1 – для раздела «Computers & Technology»), поэтому я как куратор данного проекта был просто счастлив, когда «Питер» получил эксклюзивные права на издание этого бестселлера в России.
Об одном методе распределения памяти
17 min
Tutorial

Не секрет, что иногда выделение памяти требует отдельных решений. Например — когда память выделяется и освобождается стремительным
В результате стандартный консервативный аллокатор выстраивает все запросы в очередь на pthread_mutex / critical section. И наш многоядерный процессор медленно и печально едет на первой передаче.
И что с этим делать? Познакомимся поближе с деталями реализации метода Scalable Lock-Free Dynamic Memory Allocation. Maged M. Michael. IBM Thomas J. Watson Research Center.
Самый простой код что я сумел найти — написан под LGPL камрадами Scott Schneider и Christos Antonopoulos. Его и рассмотрим.
Java собеседование. Коллекции
10 min
С недавнего времени у меня появилась настойчивая мысль, что профессиональное развитие сильно замедлилось и это хочется как-то исправить. Да, читаю книги, слушаю курсы, но в то же время приходит и понимание того, что возможно пришло время сменить работу, здесь вроде как все изучено, плавно уходим в рутину. Данная мысль сподвигла меня на рассылку своего резюме в несколько компаний — лидеров рынка. После прохождения собеседования в 3 из них, я решил, как водится внести свои 5 копеек в освещение обширной темы собеседования, а именно технических вопросов по Java коллекциям, с которыми приходится сталкиваться. Да, знаю, читатель скажет: «коллекции — избитая тема, сколько можно», но часть из приведенных ниже вопросов, я задавал своим знакомым разработчикам, которые занимают именно позиции разработчиков («крепких середнячков», по меркам недалекой от Москвы глубинки, которые уверенно справляются со своей работой на практике, а вот в теории скажем так есть пробелы, потому, что работа не требует решения каких-то нетривиальных задач, да и потому что не всем это интересно — изучать как внутри работает структура данных), вызывало растерянность. Думаю, что рассмотренный материал будет не очень интересен разработчикам выше уровня Junior (я попрошу их комментировать, дополнять и критиковать изложенный здесь материал), а вот Junior`ы уверен, найдут в этой статье интересное для себя.
Однажды вы читали о ключевом слове volatile…
5 min
Tutorial
 В C и C++ есть ключевое слово volatile, которое указывает компилятору, что значение в соответствующей области памяти может быть изменено в произвольный момент и потому нельзя оптимизировать доступ к этой области. Обычно описание ключевого слова сразу приводит пример с данными, которые могут быть в любой момент изменены из другой нити, аппаратным обеспечением или операционной системой. Прочитав описание примера, большинство читателей глубоко зевает, решает, что в этой жизни им такое не понадобится, и переходит к следующему разделу.
В C и C++ есть ключевое слово volatile, которое указывает компилятору, что значение в соответствующей области памяти может быть изменено в произвольный момент и потому нельзя оптимизировать доступ к этой области. Обычно описание ключевого слова сразу приводит пример с данными, которые могут быть в любой момент изменены из другой нити, аппаратным обеспечением или операционной системой. Прочитав описание примера, большинство читателей глубоко зевает, решает, что в этой жизни им такое не понадобится, и переходит к следующему разделу.Сегодня рассмотрим менее экзотический сценарий использования ключевого слова volatile.
Git Rebase: руководство по использованию
8 min
Tutorial
Rebase — один из двух способов объединить изменения, сделанные в одной ветке, с другой веткой. Начинающие и даже опытные пользователи git иногда испытывают нежелание пользоваться ей, так как не видят смысла осваивать еще один способ объединять изменения, когда уже и так прекрасно владеют операцией merge. В этой статье я бы хотел подробно разобрать теорию и практику использования rebase.
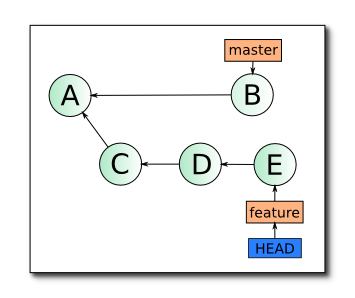
Итак, освежим теоретические знания о том, что же такое rebase. Для начала вкратце — у вас есть две ветки — master и feature, обе локальные, feature была создана от master в состоянии A и содержит в себе коммиты C, D и E. В ветку master после отделения от нее ветки feature был сделан 1 коммит B.
Теория
Итак, освежим теоретические знания о том, что же такое rebase. Для начала вкратце — у вас есть две ветки — master и feature, обе локальные, feature была создана от master в состоянии A и содержит в себе коммиты C, D и E. В ветку master после отделения от нее ветки feature был сделан 1 коммит B.
Scala: Кэширование результатов исполнения методов
4 min
Иногда возникает необходимость кэширования результатов исполнения методов. Одно из возможных решений для java описано здесь. Всё, в принципе, тривиально: EHCache, Spring AOP для перехвата вызовов, немножко кода.
Рассмотрим, как мне кажется, более элегантное решение на scala.
Рассмотрим, как мне кажется, более элегантное решение на scala.
О Scala для тех, кому мало Java, и не только
4 min
Прогресс не стоит на месте, люди ищут новые решения, и на JVM появляется всё больше интересных языков. Но «ядро» JVM сообщества — народ суровый, привыкший к серьёзным стандартам, и с высокими требованиями. Поэтому большинство новых языков так и висят «на периферии».
От других языков на JVM Scala отличается действительно основательным подходом — над языком работает лаборатория мощнейшего европейского института EPFL во главе с профессором Мартином Одерски, который также известен как дизайнер системы generic-ов из Java 1.5. Конечно, это не сравнить по объёму поддержки с серьёзными коммерческими конторами в роде Sun или Microsoft, поэтому язык развивался медленно и «пошёл в дело» совсем недавно:
Что в нём интересного?
От других языков на JVM Scala отличается действительно основательным подходом — над языком работает лаборатория мощнейшего европейского института EPFL во главе с профессором Мартином Одерски, который также известен как дизайнер системы generic-ов из Java 1.5. Конечно, это не сравнить по объёму поддержки с серьёзными коммерческими конторами в роде Sun или Microsoft, поэтому язык развивался медленно и «пошёл в дело» совсем недавно:
Что в нём интересного?
Да, Вирджиния, Scala сложна!
5 min
Translation
Для начала, позвольте уточнить, что я являюсь большим любителем и сторонником Scala вот уже 5 лет. Мною были написаны книги и статьи о Scala. Также я работал со множеством компаний, начавших использование Scala и Lift и проводил code review огромного количества Scala — проектов. Раньше я думал, что Scala — это просто. Она была и продолжает быть лекарством от многих проблем Java. С точки зрения “сложные или вообще невыполнимые вещи в Java довольно просты в Scala”, Scala — довольно простой язык. Работа с коллекциями очень проста. Изоляция бизнес-логики делает программы гораздо более поддерживаемыми и невероятно простыми, чем если бы они писались на Java.
Так почему же Scala сложна? Вот лучшее, что я смог придумать:
Так почему же Scala сложна? Вот лучшее, что я смог придумать:
Закончен предварительный перевод статей по языку Scala от компании Twitter
2 min
С недавнего времени я интересуюсь языком Scala. Пару месяцев назад я набрел на интересную серию статей от компании Twitter. Я сносно читаю на английском, но все же приятнее читать на русском языке, если есть нормальный перевод.
Благодаря труду Мариуса Эриксена (Marius A. Eriksen) и других людей серия статей увидела свет. Всех желающих узнать больше о Scala и помочь в улучшении перевода — приглашаю под кат.
Благодаря труду Мариуса Эриксена (Marius A. Eriksen) и других людей серия статей увидела свет. Всех желающих узнать больше о Scala и помочь в улучшении перевода — приглашаю под кат.
Ликбез по типизации в языках программирования
12 min

Эта статья содержит необходимый минимум тех вещей, которые просто необходимо знать о типизации, чтобы не называть динамическую типизацию злом, Lisp — бестиповым языком, а C — языком со строгой типизацией.
В полной версии находится подробное описание всех видов типизации, приправленное примерами кода, ссылками на популярные языки программирования и показательными картинками.