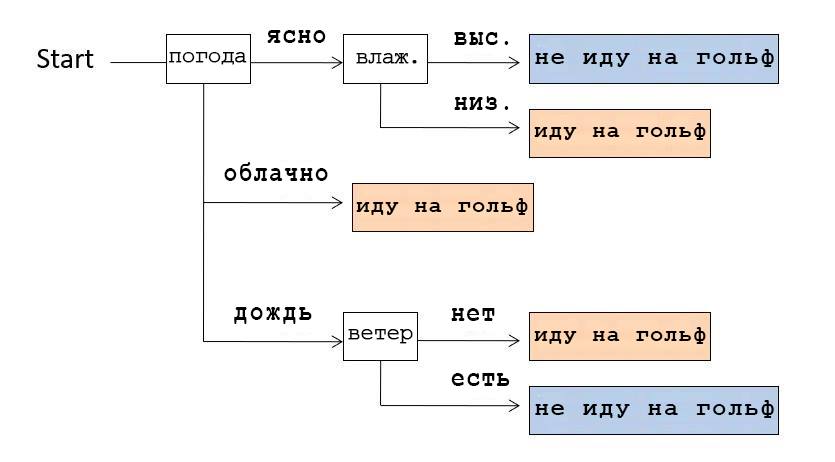
Вы можете спросить: почему эти полумагические модели машинного обучения работают так хорошо? Короткий ответ: эти модели чрезвычайно сложны и обучаются на огромном количестве данных. На самом деле, Lambda Labs недавно подсчитала, что для обучения GPT-3 на одном GPU потребовалось бы 4,6 миллиона долларов — если бы такое было возможно.
Такие платформы, как PyTorch и Tensorflow, могут обучать эти огромные модели, потому что распределяют рабочую нагрузку по сотням (или тысячам) GPU одновременно. К сожалению, этим платформам требуется идентичность графических процессоров (они должны иметь одинаковую память и вычислительную производительность). Но многие организации не имеют тысячи одинаковых GPU. Малые и средние организации покупают разные компьютерные системы, что приводит к неоднородной инфраструктуре, которую нелегко адаптировать для вычисления больших моделей. В этих условиях обучение моделей даже среднего размера может занимать недели или даже месяцы. Если не принять меры, университеты и другие небольшие организации рискуют потерять конкурентоспособность в погоне за разработкой новых, лучших моделей машинного обучения. Но это можно исправить.
В этом посте представлена предыстория и практические шаги по обучению BERT с нуля в университете с использованием пакета HetSeq. Это адаптация популярного пакета PyTorch, которая предоставляет возможность обучать большие модели нейронных сетей на гетерогенной инфраструктуре.
Такие платформы, как PyTorch и Tensorflow, могут обучать эти огромные модели, потому что распределяют рабочую нагрузку по сотням (или тысячам) GPU одновременно. К сожалению, этим платформам требуется идентичность графических процессоров (они должны иметь одинаковую память и вычислительную производительность). Но многие организации не имеют тысячи одинаковых GPU. Малые и средние организации покупают разные компьютерные системы, что приводит к неоднородной инфраструктуре, которую нелегко адаптировать для вычисления больших моделей. В этих условиях обучение моделей даже среднего размера может занимать недели или даже месяцы. Если не принять меры, университеты и другие небольшие организации рискуют потерять конкурентоспособность в погоне за разработкой новых, лучших моделей машинного обучения. Но это можно исправить.
В этом посте представлена предыстория и практические шаги по обучению BERT с нуля в университете с использованием пакета HetSeq. Это адаптация популярного пакета PyTorch, которая предоставляет возможность обучать большие модели нейронных сетей на гетерогенной инфраструктуре.