
Установка Chrome OS на обычный ПК с поддержкой Android Приложений, различия ChromeOS Flex и версии для Chromebook, Сравнение их, подробная установка каждой из них.

Пользователь
Установка Chrome OS на обычный ПК с поддержкой Android Приложений, различия ChromeOS Flex и версии для Chromebook, Сравнение их, подробная установка каждой из них.
Я уже недавно писал на Хабре, что понемногу пилю свой сервис VseGPT с доступом по OpenAI API и чатом к различным нейросетям - ChatGPT, Claude, LLama и пр. (Коротко: потому что вендорлок - зло, разнообразие и опенсорс - добро)
Большая часть работы - это, конечно, роутинг запросов на разные сервера, которые осуществляют обработку нейросетевых моделей; свой у меня скорее общий универсальный интерфейс, который сглаживает разницу между моделями, ну и некоторые прикольные фишечки.
Но я давно задумывался развернуть что-то уникальное, собственное, чего нет у других - в особенности опенсорсную Сайгу.
TLDR: Сайга-Мистраль 7B сравнима с 70B моделью. Доступна на сайте, её можно использовать по API или через интерфейс чата.


Как-то мы лежали в кровати с нашим малышом и жена сказала, что фотографий и видео с ним стало больше и она не хочет использовать платное приложение. Примерно так начинается рассказ создателя Immich – бесплатного open-source решения для хранения фотографий и видео.
Надо сказать, в последние годы я тоже регулярно пытался найти бесплатную self-hosted альтернативу Google Photos и iCloud, однако до сегодняшнего дня функциональных и вместе с тем простых в настройке решений я не встречал. Тот же Nextcloud всегда казался чересчур громоздким. Immich же, напротив, сразу завоевал моё сердце, и вот, после нескольких недель его использования, с радостью делюсь своим рабочим примером.


Всем привет! Это команда Amnezia.
Мы читаем комментарии под нашими постами и знаем, что один из самых частых вопросов – когда будет XRay? Так вот, мы добавили XRay в приложение AmneziaVPN, а точнее протокол Reality от XRay для всех платформ - IOS, Android, Windows, Linux и MacOS. Если у вас еще нет последнего релиза, скорее скачивайте и создавайте VPN на собственном сервере в пару кликов с одним из самых защищенных и быстрых протоколов в мире, ниже мы немного о нем расскажем, а в конце статьи будет пошаговая инструкция как это сделать.
Почему XRay Reality так популярен ?
Все дело в том, что Reality подходит для стран с самым высоким уровнем интернет-цензуры, сейчас его используют в Китае и Иране, он защищен от детектирования методами active probing.
Распознать цензоров REALITY может еще на этапе TLS-хендшейка. Если REALITY видит, что к нему приходит его клиент, то сервер запускает для него VPN туннель, а если приходит любой другой запрос на 443 порт, то TLS-подключение передается на какой-нибудь другой реальный сайт, например, google.com, где цензор получит настоящий TLS-сертификат от google.com и вообще все настоящие данные с этого сайта.
Со стороны систем анализа трафика это выглядит как подключение к настоящему сайту, сервер отдает настоящий TLS-сертификат этого сайта, и вообще все (включая TLS fingerprint сервера) выглядит очень по-настоящему и не вызывает подозрений.
Особенно приятно, что при этом производительность REALITY и скорость подключения у протокола действительно хороши, в сравнении, например, со связкой OpenVPN over Cloak.

Всем привет! На связи команда Amnezia. И если вы давно за нами следите, вы помните как мы были очень маленьким стартапом, который делал первые шаги по созданию более менее современного приложения с open source кодом, чтобы создавать VPN на собственном сервере. Мы понимали что подобное решение нужно, но еще не понимали на сколько нужно и что именно мы будем делать дальше.
AmneziaFree. Начало
Наверное, мы бы и дальше оставались просто разработчиками self-hosted клиента, если бы не массовая блокировка общественно значимых сайтов весной 2022 в России. Особенно болезненно ощущалась блокировка невероятно популярного Instagram*
Тогда при поддержке активистов и различных медиа мы взяли самые очевидные инструменты - арендовали у партнеров серверные мощности, взяли за основу open source приложение WireGuard и создали телеграм-бота раздающего конфигурации для каждого пользователя - и уже буквально через месяц, у нас был готов бесплатный сервис для доступа к заблокированным сайтам AmneziaFree. Он стал неожиданно популярным, практически 250 000 пользователей за короткий промежуток времени получили конфиги с помощью этого бота.
> С 10 апреля 2024, 3 месяца спустя,
> данная статья заблокирована РКН на территории РФ,
> её также удалили с веб-архива archive.org.
> Статья на Хабре осталась доступна с IP других стран.
> Да, теперь, чтобы читать про ВПН, нужен ВПН.
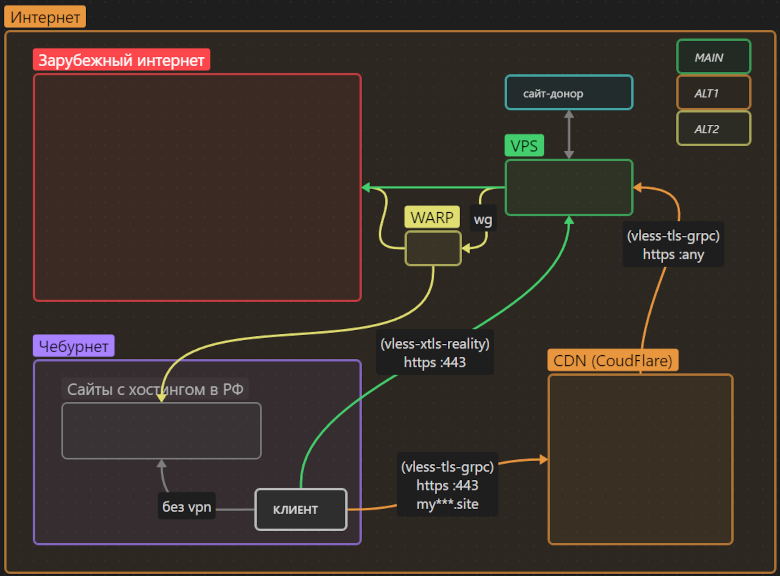
На фоне прошлогоднего обострения цензуры в РФ, статьи автора MiraclePTR стали глотком свободы для многих русскоязычных айтишников. Я же хочу приоткрыть дверь к свободной информации чуть шире и пригласить «не‑технарей» («чайников»), желающих поднять личный прокси‑сервер для обхода цензуры, но дезориентированных обилием информации или остановленных непонятной технической ошибкой.
В этой статье я описал универсальное решение, которое обеспечивает прозрачный доступ к международному интернету в обход цензуры, использует передовые технологии маскировки трафика, не зависит от воли одной корпорации и главное — имеет избыточный «запас прочности» от воздействия цензоров.
Статья рассчитана на «чайников», не знакомых с предметной областью. Однако и люди «в теме» могут найти нечто полезное (например, чуть более простую настройку проксирования через CloudFlare без необходимости поднимать nginx на VPS).
Если у вас ещё нет личного прокси для обхода цензуры — это знак.

О том, как сделать прозрачную синхронизацию заметок Obsidian между устройствами (Desktop, Android, iOS) через GitHub:
1. Без сторонних приложений (вроде iCloud, SyncThing, Termux и пр)
2. Бесплатно
3. Бонусом — резервная копия: как самих заметок, так и истории изменений.
В результате получается полноценная замена Notion: структурированные заметки с автоматической синхронизацией между устройствами.

Сделаем Телеграм бота которому можно кинуть ссылку на YouTube видео и поговорить с ним о содержимом этого видео.

Да, всего 20 строк кода и бот:
1) по качеству ответов будет соизмерим с ChatGPT-4o;
2) будет отвечать очень быстро т.к. подключим мы его через Groq который в среднем в 10 раз быстрее других аналогичных сервисов;
3) будет поддерживать диалог и запоминать последние сообщения.

Мой бизнес основан на двух страницах из советской энциклопедии. Я стал первым производителем конопли в России, разработав свою инженерскую технологию с использованием фена и тазика. А еще боролся с вредителями на производстве и доказывал маркетплейсам, что я не наркоторговец.

Последние пару лет развитие языковых нейросетей как будто бы шло по принципу «больше, длиннее, жирнее»: разработчики пытались раздуть свои модели на как можно большее число параметров и прогнать через них максимальный объем тренировочных данных. 12 сентября OpenAI выпустили новую LLM, которая добавляет в это уравнение еще одно измерение для прокачки: теперь можно масштабировать объем «мыслей», который модель будет тратить в процессе своей работы. В этой статье мы разберемся, чему научилась новая GPT o1, и как это повлияет на дальнейшую эволюцию ИИ.

Прочитал и посмотрел почти все статьи и видео по Obsidian, которые вышли недавно (в среднем не более 1-2 ух месяцев назад). Дал каждому источнику субъективную оценку и написал короткий комментарий.

Эта статья пригодится тем, кто не имеет хоть какой‑то системы по управлению делами, но которому она нужна, так как, например, стало тяжело справляться лишь только за счёт своей памяти или каких‑то мелких чек‑листов на обрывках салфеток. Статья предполагает, что вы будете читать и делать всё в ней написанное. Иначе говоря, статья является практически пошаговой инструкцией, т. е. в ней не будет каких‑то уж совсем незаурядных методов или взглядов.
В статье будет показана базовая реализация системы по управлению делами. В ней будет также кратко объяснено, что делать с привычками, рассказано про планирование работы с источниками. Статья пройдётся по проблеме делегирования дел. Также будет показана важность комментариев к задачам. В конце будет предложен наиболее общий алгоритм работы с системой.
Будет нелишним, если вы прочитаете мою прошлую статью про основные принципы систем, которые помогают достигать поставленных целей.

Эта статья завершает цикл "Управление знаниями в Obsidian". В ней будет предполагаться, что вы способны понять все техники и приемы из прошлой второй части про базовый рабочий процесс, т.к. здесь будут показаны продвинутые способы управления персональной базой знаний. В частности, статья затронет следующие темы:
• Ведение визуальной базы знаний (Excalidraw + Excalibrain)
• Создание системы для интервального повторения (Spaced repetition)
• Создание гибкой иерархии (Breadcrumbs + Excalibrain)
• Использование алгоритмов для поиска новых связей между заметками (Graph Analysis)
• Написание длинных текстов (Longform)

В этой статье будет показано как можно начать организовывать свою базу знаний в Obsidian, отталкиваясь от источников. В статье будет разобрано то, какие стоит использовать папки и теги; как создать свою первую точку входа в систему. Также будет уделено внимание способу ведения журнала (дневника). Статья будет предполагать, что вы не против автоматизации процессов в своей базе знаний, поэтому все источники будут шаблонизированы и впоследствии собраны в свои отдельные библиотеки с помощью Dataview. Завершится статья подробным примером (алгоритмом) рабочего процесса.

Этот текст открывает цикл статей по рассмотрению проблемы управления знаниями в Obsidian. Эта часть почти не будет содержать практических советов о работе с заметками конкретно в Obsidian. Однако в ней будут раскрыты несколько более важные проблемы обработки различных источников информации. Несмотря на последовательное перетекание статьи из одной главы в другую, вы можете попробовать каждый пункт рассматривать как идею, как хак или как возможность внедрить в свою жизнь и рабочий процесс что-то новое.

ChatGPT вышел уже почти два года назад, а датасаентисты до сих пор никак не могут определиться — являются ли нейросети тварями дрожащими, или всё же мыслить умеют? В этой статье мы попробуем разобраться: а как вообще учёные пытаются подойти к этому вопросу, насколько вероятен здесь успех, и что всё это означает для всех нас как для человечества.
Нет времени объяснять! Bytedance тестирует платформу создания АИ ботов, coze.com, в том числе на базе gpt-4/gpt-3.5/Dalle-3 с возможностью интеграции в телеграм/дискорд. На данный момент ограничений практически нет, бесплатный доступ к огромному количеству сервисов, включая платные. Сервис доступен в России и еще в ряде стран.
Есть возможность создавать сложные workflow, добавлять кастомные плагины/апи, да практически что угодно можно сделать. Я покажу на примере нескольких ботов. Простой gpt бот - переводчик, чуть более сложный - для написания кода на питон, с возможностью "гуглить" и очень сложный, для генерации изображений в Dalle, с сложным воркфлоу, кастомными плагинами/вставками кода/условиями и так далее. Поехали!