Курс молодого бойца. Практический курс по Cisco Packet Tracer. Заключение
6 мин
Туториал
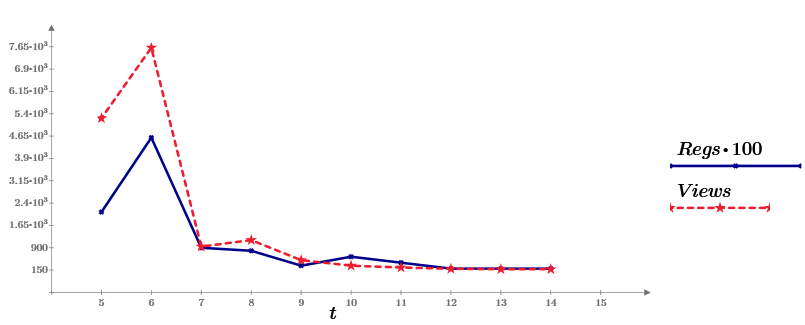
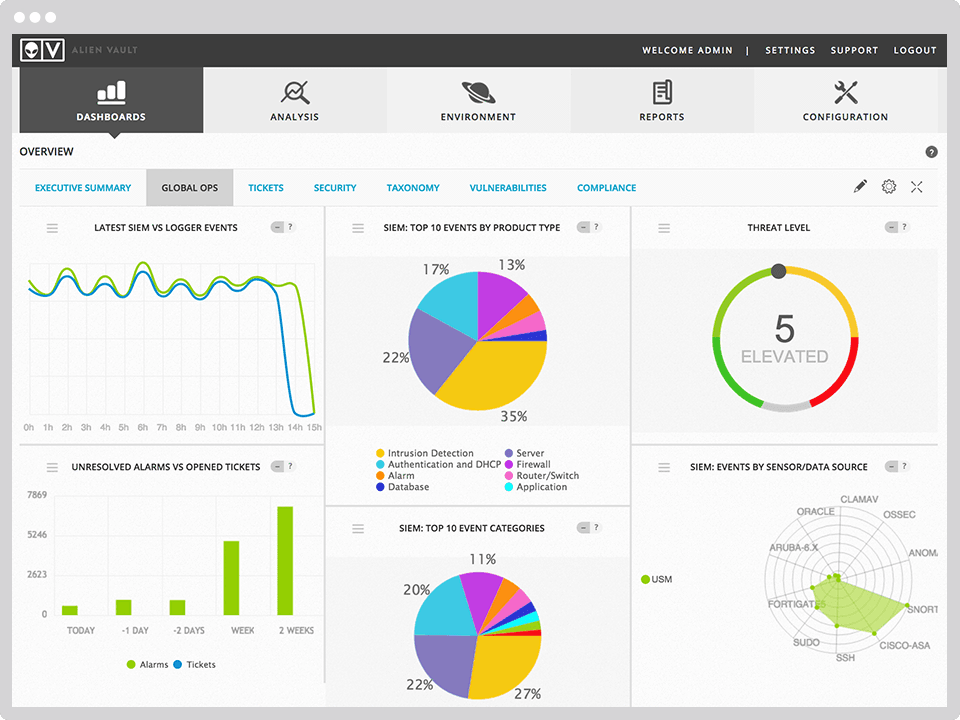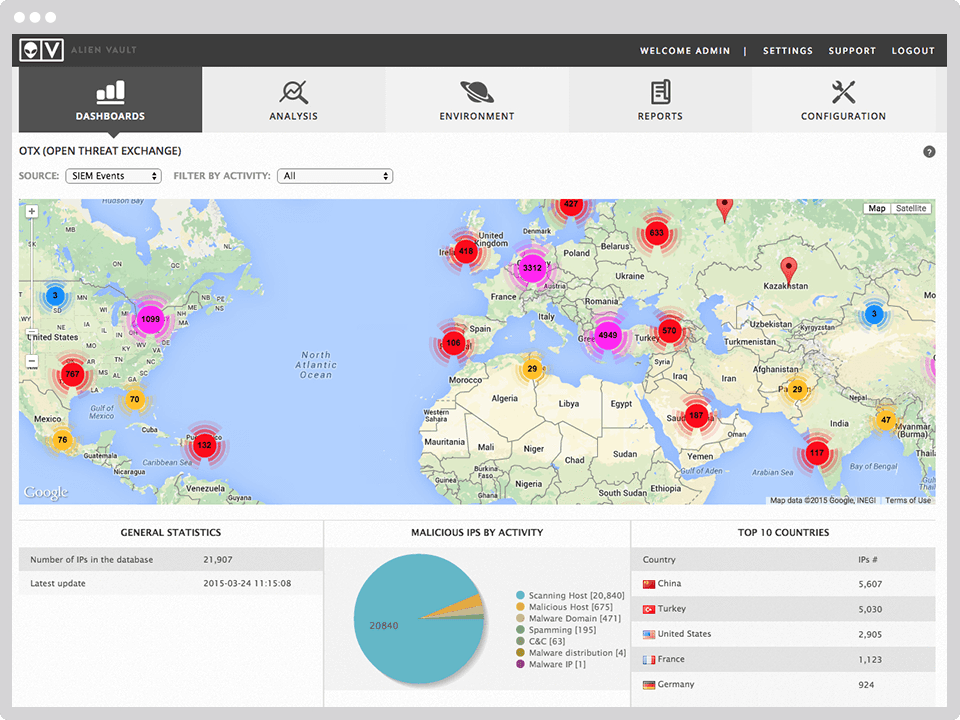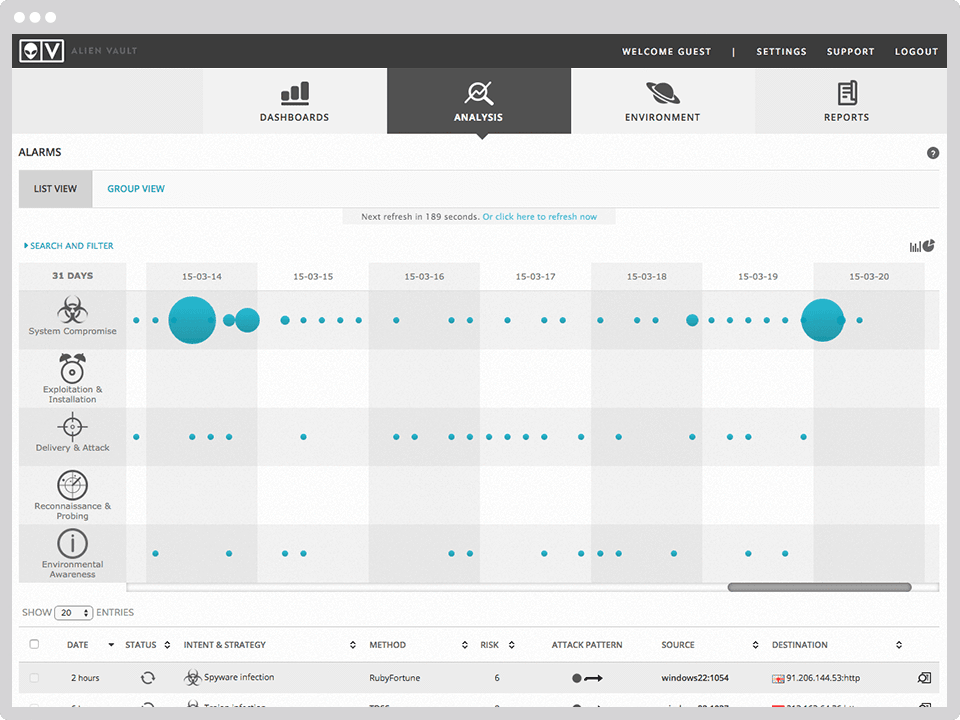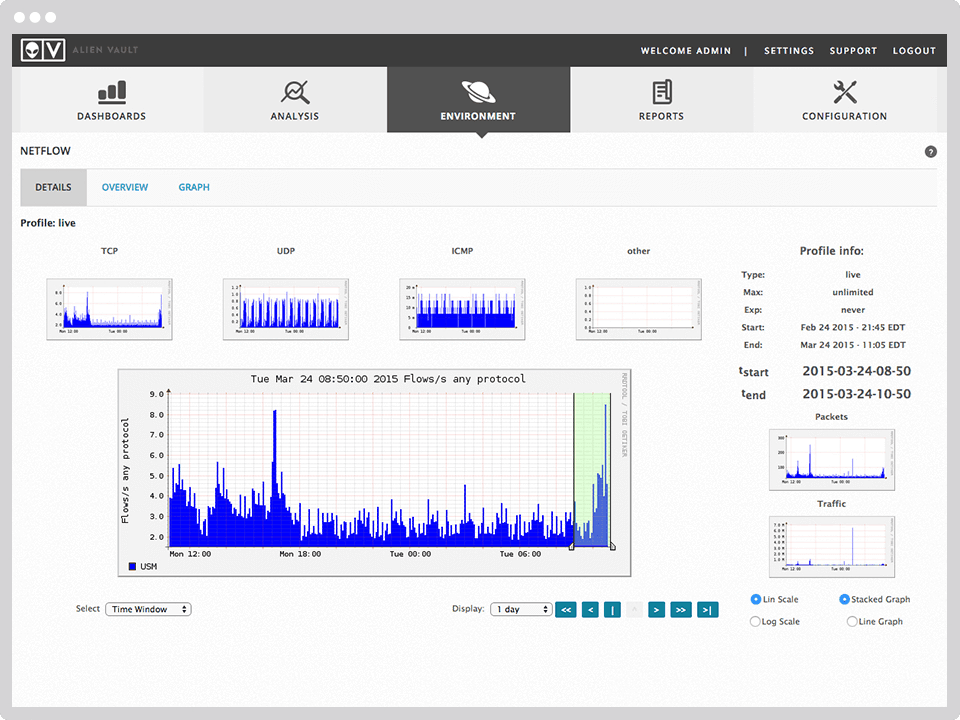
Относительно недавно я опубликовал небольшую статью «Курс молодого бойца. Практический курс по Cisco Packet Tracer». Там я рассказал об опыте создания обучающего курса для внутренних нужд организации. Основная цель курса — быстрая подготовка специалиста к «полевым работам». Уроки параллельно публиковались на YouTube в свободном доступе. Сам проект получил название NetSkills. После публикации на канал YouTube добавилось больше 2-х тысяч подписчиков. Я получил отличный фидбэк (такой, что еле справился) и стимул довести дело до конца.

Несколько дней назад я опубликовал последний видео урок и хотел поделиться некоторыми результатами и мыслями в качестве заключения. Всем, кто заинтересовался, добро пожаловать под кат.
Несколько дней назад я опубликовал последний видео урок и хотел поделиться некоторыми результатами и мыслями в качестве заключения. Всем, кто заинтересовался, добро пожаловать под кат.












 Общая выходная мощность: 12 Вт
Общая выходная мощность: 12 Вт