
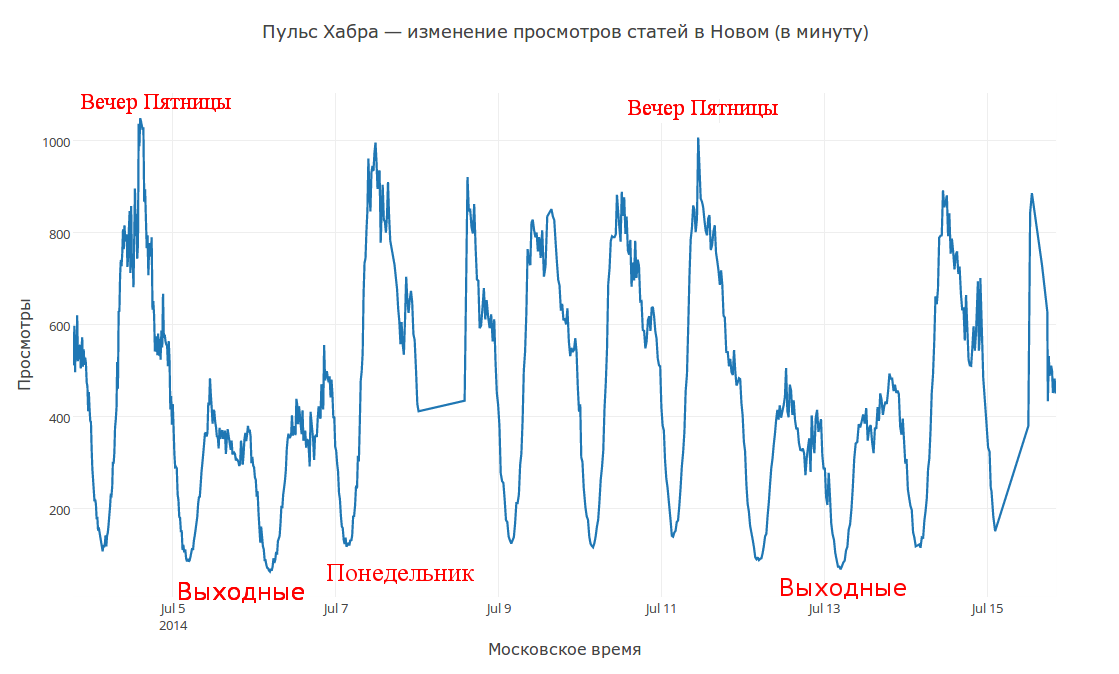
Давным давно у меня родилась гипотеза: «Все айтишники, так же как и я, читают новости и статьи на работе за чашкой чая-кофе в самом начале дня и где-то после обеда».
Чтобы проверить эту гипотезу (ну и не только для этого, конечно) в прошлом году написал и опубликовал монитор Хабра под названием Пульс Хабра. Так как гипотезы необходимо проверять, я занялся сбором данных и анализом закономерностей поведения Хабра-жителей.

Сегодня решил поделиться основными наблюдениями.
Структура статьи:
Чтобы проверить эту гипотезу (ну и не только для этого, конечно) в прошлом году написал и опубликовал монитор Хабра под названием Пульс Хабра. Так как гипотезы необходимо проверять, я занялся сбором данных и анализом закономерностей поведения Хабра-жителей.
Сегодня решил поделиться основными наблюдениями.
Структура статьи:







{kind=link}