

Привет, коллеги!
Если вы когда-нибудь просыпались среди ночи от алертов о том, что «всё упало», но не могли понять почему — эта статья для вас. Поговорим о том, как построить нормальный мониторинг и перестать гадать на кофейной гуще.
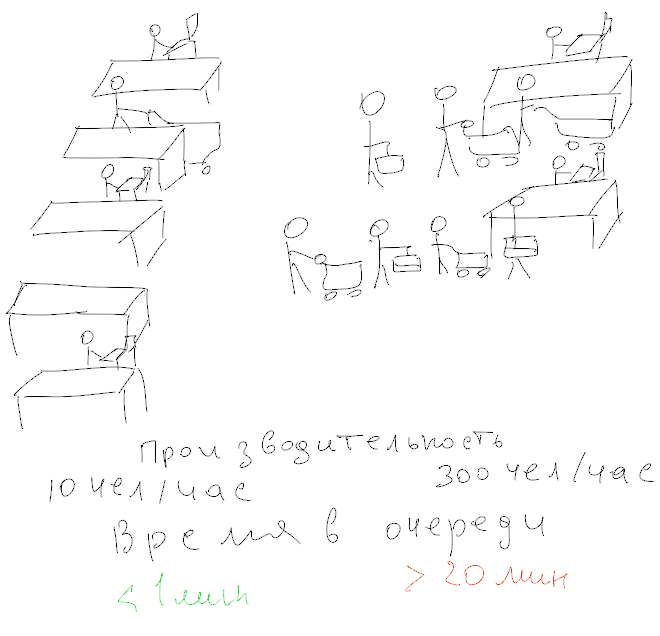
В современном мире, где многие компании переходят на облачные технологии и используют managed-сервисы, важно понимать, какие метрики действительно необходимо мониторить самостоятельно, а какие можно оставить на усмотрение провайдера. Managed-ресурсы предоставляют множество преимуществ, включая автоматическое управление инфраструктурой и встроенные инструменты мониторинга. Однако это не освобождает вас от ответственности за мониторинг критичных для бизнеса метрик.



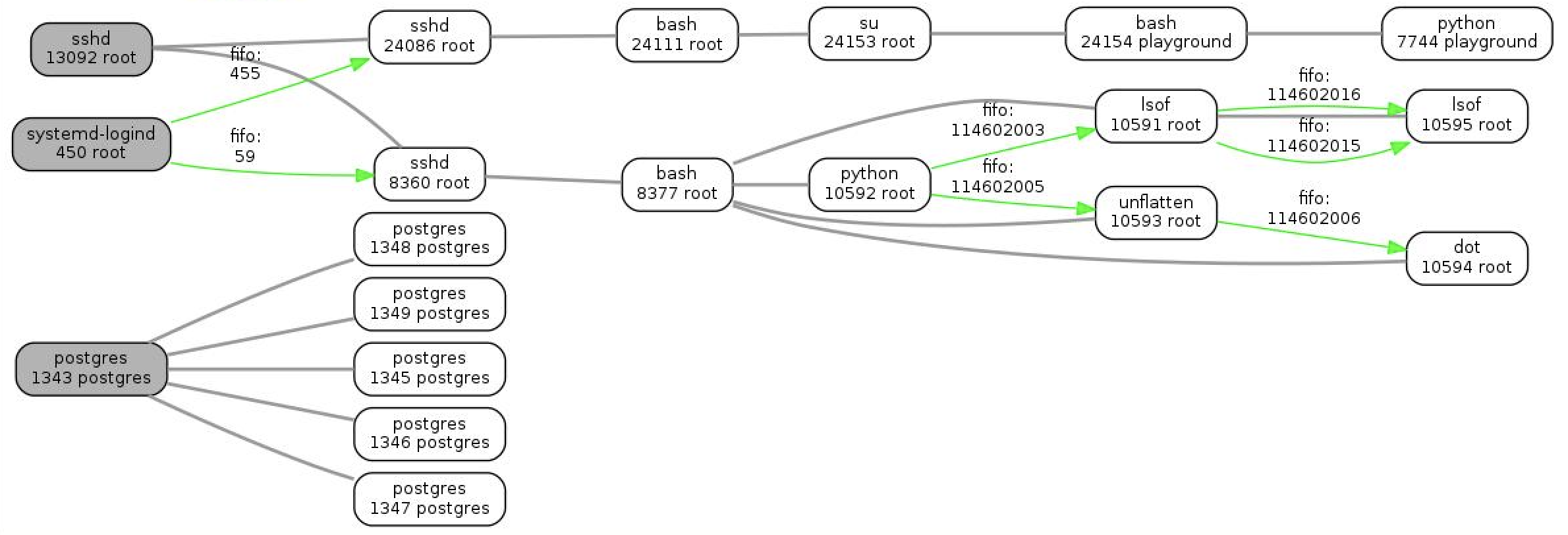





 В процессе эксплуатации систем с SELinux я выделил несколько интересных кейсов, решения которых вряд-ли описаны в Интернете. Сегодня я решил поделиться с вами своими наблюдениями в надежде, что число сторонников SELinux еще немного возрастет :)
В процессе эксплуатации систем с SELinux я выделил несколько интересных кейсов, решения которых вряд-ли описаны в Интернете. Сегодня я решил поделиться с вами своими наблюдениями в надежде, что число сторонников SELinux еще немного возрастет :) [Обновление] Теперь я в каком-то списке спецслужб, потому что написал статью про некий вид «бомбы», так?
[Обновление] Теперь я в каком-то списке спецслужб, потому что написал статью про некий вид «бомбы», так?