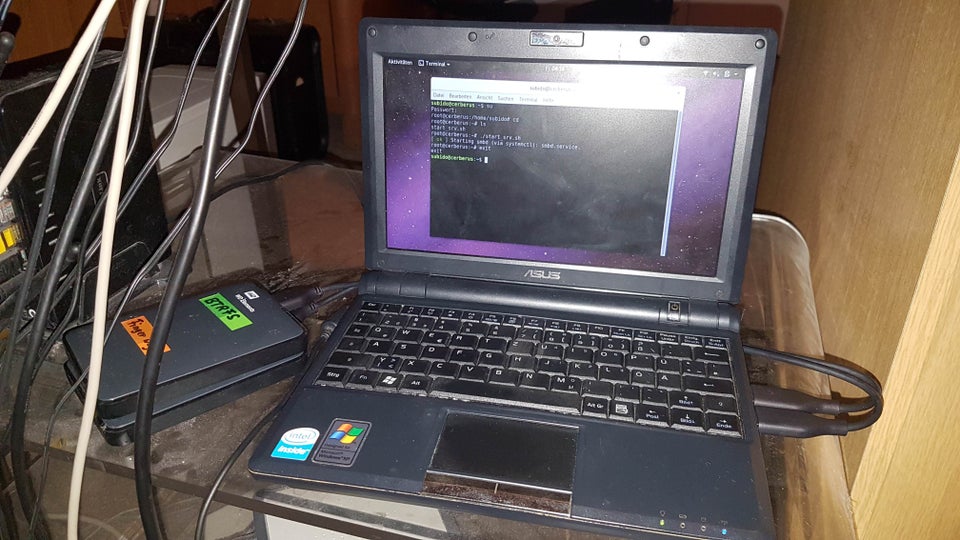
Как и у каждой уважающей себя техподдержки, у инженеров Veeam есть свой список самых популярных поводов позвонить им в любое время дня и ночи. Это и вечно молодое “У вас неправильно работает ретенш”, и никогда не стареющее “У меня место на дисках кончилось, что делать?”, и прорва других.
Однако среди них есть простой, казалось бы, вопрос. Он объясняется за 5 минут, но вот парадокс: его объяснение вылетает из головы в течение следующих тридцати секунд. Звучит этот чудо-вопрос примерно так: “После бекапа Veeam нарисовал мне непонятный график и написал, что у меня загрузка сорса 63%, прокси 48%, сети 99%, а таргета 0! А потом ещё и обозвал этот сорс ботлнеком, а у меня там ого-го какая железяка! И что вообще означают эти проценты?”
Сегодня объясню в текстовом виде, чтобы было куда возвращаться и перечитывать на досуге.
Bottleneck (бутылочное горлышко, если переводить в лоб) - самая медленная часть вашей бекапной инфраструктуры. Узкое место или слабое звено, если хотите. Тот самый нехороший человек, которого семеро ждать не должны, но получается, что ждут. Если переключиться на более технический язык, то эта та часть инфраструктуры, в которой данные в среднем проводят больше всего времени. То есть обрабатываются дольше всего. Получается, что это чистой воды вопрос производительности (перфоманса, как принято говорить). И знание ответа на этот вопрос позволит нам понять, какую часть в цепочке обработки данных надо ускорить, дабы повысить общую скорость процесса.
И тут откровение номер раз: чтобы говорить о перфомансе на серьёзных щщах, надо напрямую измерять интересующие нас метрики и проводить их аналитику. Это статистика загруженности дисков, процессоров, памяти и так далее. Словом, построить внутри одного продукта ещё один продукт, только мониторинговый. Поэтому Veeam ничего напрямую не измеряет, однако в логах можно найти шесть метрик, сделанных путём опосредованных измерений.
Во время старта джобы в интерфейсе Veeam начинает рисоваться график и появляются некие цифры производительности. А если после создания бекапа проанализировать эти цифры, то можно будет сделать довольно точный вывод об узких местах.











 Здравствуйте. Сегодня я расскажу как можно создать единый установочный носитель с множеством разных версий Windows не прибегая к использованию стороннего ПО. Таким образом вы будете полностью понимать какие манипуляции мы выполняем.
Здравствуйте. Сегодня я расскажу как можно создать единый установочный носитель с множеством разных версий Windows не прибегая к использованию стороннего ПО. Таким образом вы будете полностью понимать какие манипуляции мы выполняем.