Я мирно сидел на семинаре, слушал доклад студента о статье с прошлого
CVPR и параллельно гуглил тему.
— К достоинствам статьи можно отнести наличие исходного кода….
Пришлось вмешаться:
— Наличие чего, простите?
— Э-э-э… Исходного кода…
— Вы его смотрели?
— Нет, но в статье указано…
(мать-мать-мать… привычно отозвалось эхо)
ㅡ Вы ходили по ссылке?
В статье, действительно, предельно обнадеживающе написано: “The code and model are publicly available on the project page …/github.io/...”, — однако в коммите двухлетней давности по ссылке значится вдохновляющее «Код и модель скоро выложим»:
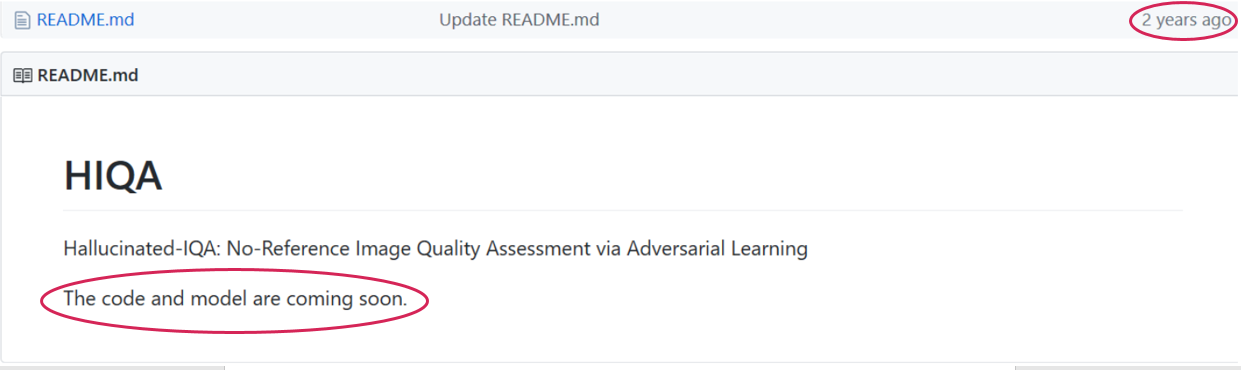
Ищите и обрящете, стучите и откроется… Может быть… А может быть и нет. Я бы, исходя из печального опыта, ставил на второе, поскольку ситуация в последнее время повторяется ну уж о-о-очень часто. Даже на CVPR. И это только часть проблемы! Исходники могут быть доступны, но, к примеру, только модель, без скриптов обучения. А могут быть и скрипты обучения, но за несколько месяцев с письмами к авторам не получается получить такой же результат. Или за год на другом датасете с регулярными скайп-звонками автору в США не удается воспроизвести его результат, полученный в наиболее известной лаборатории в отрасли по этой теме… Трындец какой-то.
И, судя по всему, мы пока видим лишь цветочки. В ближайшее время ситуация кардинально ухудшится.
Кому интересно,
что стало со студентом куда катится научный мир, в том числе по «вине» глубокого обучения, добро пожаловать под кат!