Как много веселых ребят
И все делают велосипед.
А один из них как-нибудь утром
Придумает порох.
Виктор Цой.
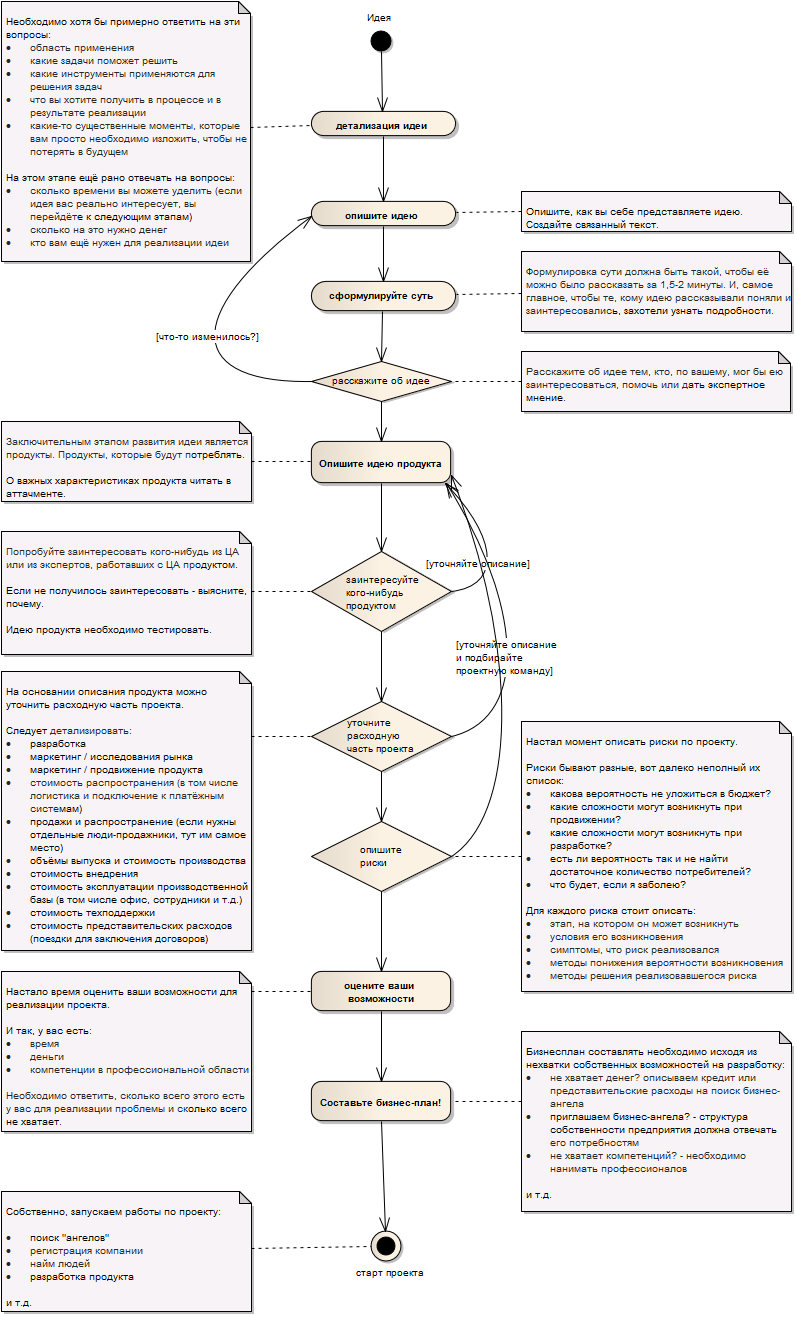
Сначала я хотел написать в раздел «Я пиарюсь» статью о том какой я молодец и какую замечательную штуку сделал но, немного поискав в сети, я без удивления обнаружил, что я совсем не единственный в своем роде. Тогда я решил пойти от обратного: наверное, практически каждый Веб-программист хотя бы раз в своей жизни пытается написать полноценную CMS. При этом, в процессе проектирования (а это процесс, зачастую, наступает уже во время написания кода) у разработчика непременно возникают вопросы. С этими вопросами он обращается к поисковикам и попадает на сайты тех, кто по подобным граблям уже прошествовал.
Итак, я стал смотреть, по каким же запросам попадают ко мне начинающие «разработчики велосипедов», и постарался осветить некоторые вещи, которые для меня самого были неочевидны в начале работ.
И все делают велосипед.
А один из них как-нибудь утром
Придумает порох.
Виктор Цой.
Сначала я хотел написать в раздел «Я пиарюсь» статью о том какой я молодец и какую замечательную штуку сделал но, немного поискав в сети, я без удивления обнаружил, что я совсем не единственный в своем роде. Тогда я решил пойти от обратного: наверное, практически каждый Веб-программист хотя бы раз в своей жизни пытается написать полноценную CMS. При этом, в процессе проектирования (а это процесс, зачастую, наступает уже во время написания кода) у разработчика непременно возникают вопросы. С этими вопросами он обращается к поисковикам и попадает на сайты тех, кто по подобным граблям уже прошествовал.
Итак, я стал смотреть, по каким же запросам попадают ко мне начинающие «разработчики велосипедов», и постарался осветить некоторые вещи, которые для меня самого были неочевидны в начале работ.

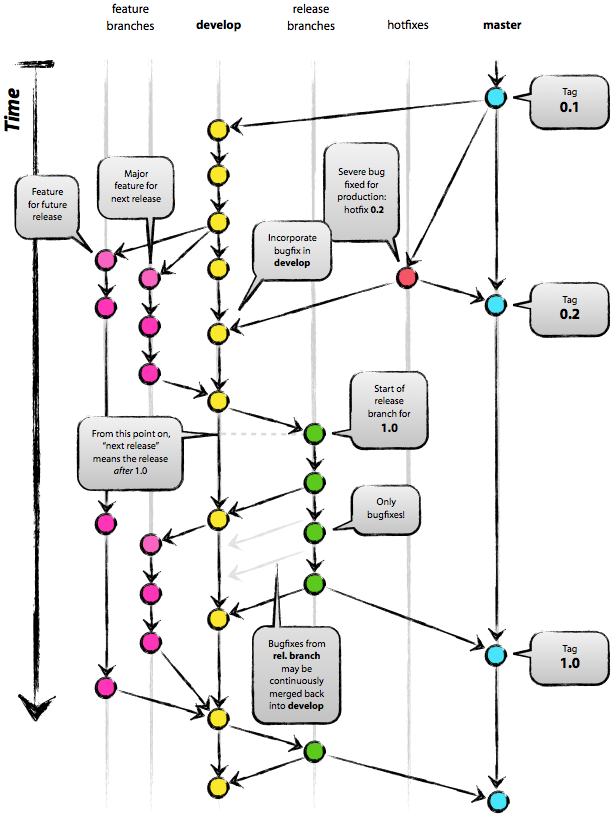
 Mercurial — это современная распределенная система контроля версий с открытым кодом. Эта система — заманчивая замена для более ранних систем вроде Subversion. В этом простом учебном пособии в шести частях Джоэль Спольски (
Mercurial — это современная распределенная система контроля версий с открытым кодом. Эта система — заманчивая замена для более ранних систем вроде Subversion. В этом простом учебном пособии в шести частях Джоэль Спольски ( Для начала, я начал приводить всевозможные тупые причины, по которым нам не надо ничего менять. «Мы должны хранить репозиторий на центральном сервере, так безопаснее», — сказал я. Знаете что? Я был неправ. При работе с Mercurial у каждого разработчика на жестком диске хранится полная копия репозитория. Это, на самом деле, безопаснее. В любом случае, почти в каждой команде, использующей Mercurial, центральный репозиторий тоже существует. И вы можете делать резервное копирование этого репозитория со всей необходимой одержимостью. А еще можете устроить трехступенчатую защиту с
Для начала, я начал приводить всевозможные тупые причины, по которым нам не надо ничего менять. «Мы должны хранить репозиторий на центральном сервере, так безопаснее», — сказал я. Знаете что? Я был неправ. При работе с Mercurial у каждого разработчика на жестком диске хранится полная копия репозитория. Это, на самом деле, безопаснее. В любом случае, почти в каждой команде, использующей Mercurial, центральный репозиторий тоже существует. И вы можете делать резервное копирование этого репозитория со всей необходимой одержимостью. А еще можете устроить трехступенчатую защиту с  Mercurial — это система контроля версий. Разработчики используют ее для администрирования исходного кода. У нее два основных назначения:
Mercurial — это система контроля версий. Разработчики используют ее для администрирования исходного кода. У нее два основных назначения:
")


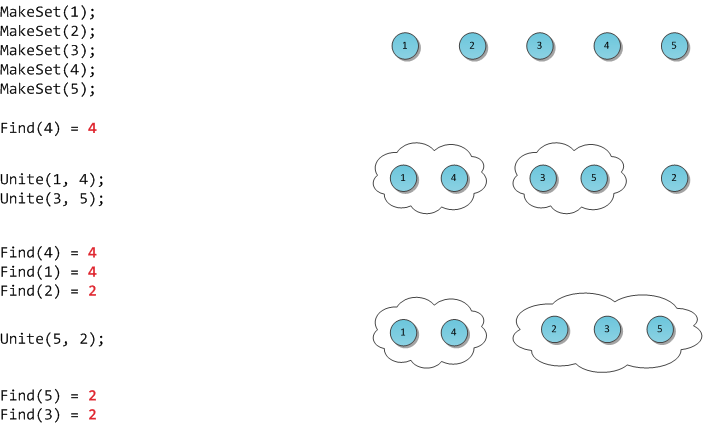
 Алгоритм Флойда — Уоршелла — алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного
Алгоритм Флойда — Уоршелла — алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного