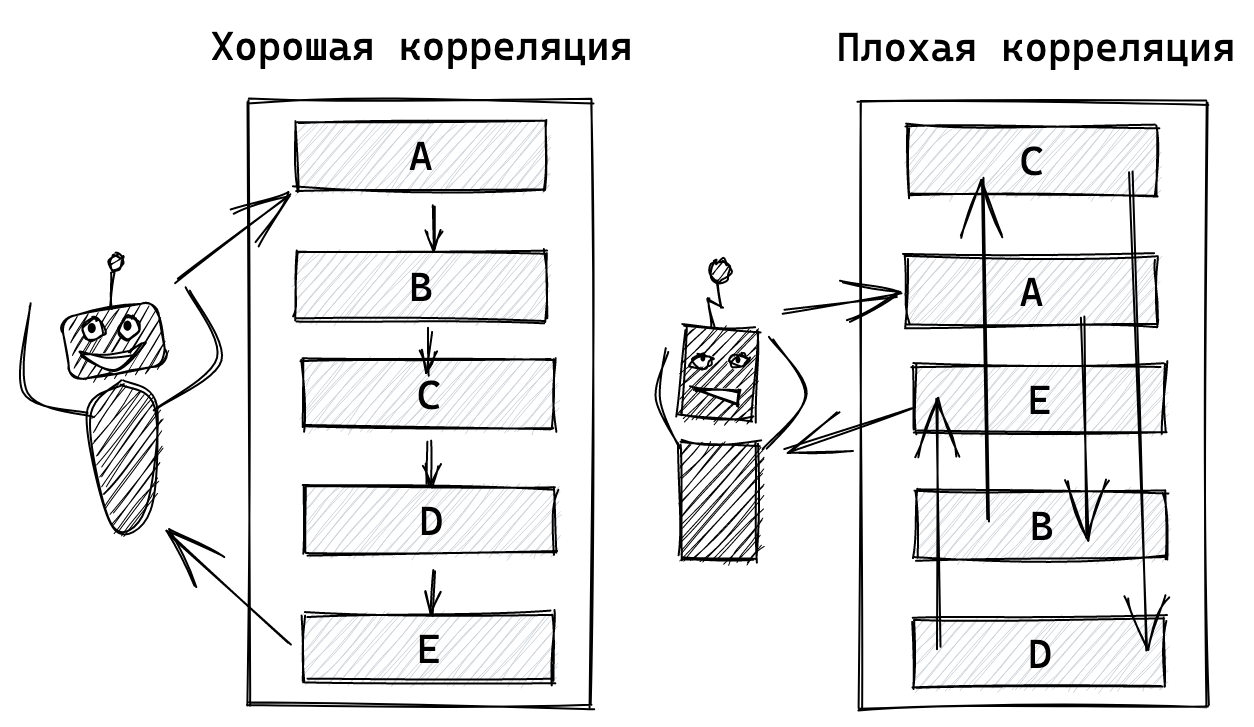
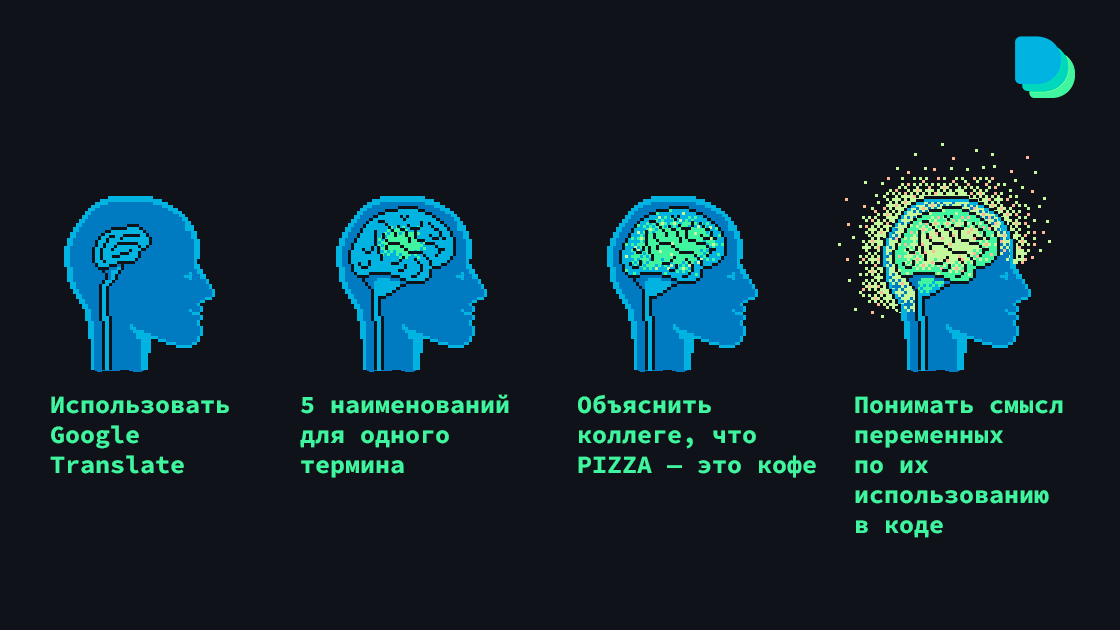
Увидев очередную статью об утомившем всех Chat GPT от Open AI, рука невольно тянется в пистолету минусатору. Ну, в самом деле, сколько можно? Уже, кажется, все успели поиграть с чатом во всевозможных сценариях.
Однако один аспект, почему‑то, почти не затронут как на Хабре, так и в Рунете. Почему же все‑таки Chat GPT говорит по‑русски с весьма специфическим акцентом, который условно можно назвать «нейронным говорком»?
Чтобы понять суть вопроса, обратимся к теории. Чем занимается генеративная нейронная сеть такого типа?
Говоря просто и коротко она получает на вход набор токенов, пропускает их через некий «черный ящик» и выдает другой набор токенов. Вероятность выбора конкретного токена для ответа зависит от набора входящих токенов и конкретных настроек.
Но что же такое «токен»? Интересный факт заключается в том, что для английского языка токеном обычно выступают сочетания символов, зачастую совпадающие с короткими словами или часто встречающимися частями слов.
Возьмем, например, английскую панграмму:
“The quick brown fox jumps over the lazy dog”
Напомню, что панграмма — это предложение из минимального числа слов, содержащая в себе все буквы алфавита.
Официальный токенизатор Open AI.
Показывает, что в этом предложении всего 9 токенов, содержащих 43 символа.