
На собеседованиях на позицию, предполагающую понимание DevOps, я люблю задавать кандидатам такой вопрос (а иногда его еще задают и мне):
Каким, по вашему мнению, должен быть идеальный пайплайн от коммита до продашкена?/Опишите идеальный CI/CD / etc
Сегодня я хочу рассказать про своё видение идеального пайплайна. Материал ориентирован на людей, имеющих опыт в построении CI/CD или стремящихся его получить.
Почему это важно?
Вопрос об идеальном пайплайне хорош тем, что он не содержит точного ответа.
Кандидат начинает рассуждать, а в крутых специалистах ценится именно умение думать.
Когда в вопрос добавляется такое абсолютное прилагательное, как "идеальный", то мы сразу развязываем кандидатам руки в просторе для творчества и фантазий. У соискателей появляется возможность показать, какие улучшения они видят (или не видят) в текущей работе, и что хотели бы добавить сами. Также мы можем узнать, есть ли у нашего предполагаемого будущего коллеги мотивация к улучшениям процессов, ведь концепция "работает — не трогай" не про динамичный мир DevOps.
Организационная проверка. Позволяет узнать, насколько широка картина мира у соискателя. Условно: от создания задачи в Jira до настроек ноды в production. Сюда же можно добавить понимание стратегий gitflow, gitlabFlow, githubFlow.
Итак, прежде чем перейти к построению какого-либо процесса CI, необходимо определиться, а какие шаги нам доступны?
Что можно делать в CI?
сканить код;
билдить код;
тестить код;
деплоить приложение;
тестить приложение;
делать Merge;
просить других людей подтверждать MR через code review.
Рассмотрим подробнее каждый пункт.
Code scanning
На этой стадии основная мысль — никому нельзя верить.
Даже если Вася — Senior/Lead Backend Developer. Несмотря на то, что Вася хороший человек/друг/товарищ и кум. Человеческий фактор, это все еще человеческий фактор.
Необходимо просканировать код на:
соответствие общему гайдлайну;
уязвимости;
качество.


Задачи на этой стадии следует выполнять параллельно.
И триггерить только если меняются исходные файлы, или только если было событие git push.
Пример для gitlab-ci
stages: - code-scanning .code-scanning: only: [pushes] stage: code-scanning
Linters
Линтеры – это прекрасная вещь! Про них уже написано много статей. Подробнее можно почитать в материале "Холиварный рассказ про линтеры".
Самая важная задача линтеров — приводить код к единообразию.
После внедрения этой штучки разработчики начнут вас любить. Потому что они наконец-то начнут понимать друг друга. Или ненавидеть, решив, что вы вставляете им палки в колеса линтеры в CI. Это уже зависит от ваших soft skills, культуры и обмена знаниями.
Инструменты
Инструмент | Особенности |
|---|---|
eslint | JavaScript |
pylint | Python |
golint | Golang |
hadolint | Dockerfile |
kubeval | Kubernetes manifest |
shellcheck | Bash |
gixy | nginx config |
etc |
Code Quality
code quality — этими инструментами могут быть как продвинутые линтеры, так и совмещающие в себе всякие ML-модели на поиск слабых мест в коде: утечек памяти, небезопасных методов, уязвимостей зависимостей и т.д, перетягивая на себя еще code security компетенции.
Инструменты
Code Security
Но существуют также и отдельные инструменты, заточенные только для code security. Они призваны:
Бороться с утечкой паролей/ключей/сертификатов.
Cканировать на известные уязвимости.
Неважно, насколько большая компания, люди в ней работают одинаковые. Если разработчик "ходит" в production через сертификат, то для своего удобства разработчик добавит его в
git. Поэтому придется потратить время, чтобы объяснить, что сертификат должен храниться вvault, а не вgit
Инструменты
Сканер уязвимостей необходимо запускать регулярно, так как новые уязвимости имеют свойство со временем ВНЕЗАПНО обнаруживаться.

Code Coverage
Ну и конечно, после тестирования, нужно узнать code coverage.
Процент исходного кода программы, который был выполнен в процессе тестирования.
Инструменты
Unit test
Модульные тесты имеют тенденцию перетекать в инструменты code quality, которые умеют в юнит тесты.
Инструменты
Build
Этап для сборки artifacts/packages/images и т.д. Здесь уже можно задуматься о том, каким будет стратегия версионирования всего приложения.
За модель версионирования вы можете выбрать:
номер cборки;
datetime, timestamp;
etc
Во времена контейнеризации, в первую очередь интересуют образы для контейнеров и способы их версионирования.
Инструменты для сборки образов
Инструмент | Особенности |
|---|---|
docker build | Почти все знают только это. |
Проект Moby предоставил свою реализацию. Поставляется вместе с докером, включается опцией | |
Инструмент от Google, позволяет собирать в юзерспейсе, то есть без докер-демона. | |
Разработка коллег из Флант'а. Внутри stapel. All-in-one: умеет не только билдить, но и деплоить. | |
Open Container Initiative, Podman. | |
etc |
Итак, сборка прошла успешно – идем дальше.
Scan package
Пакет/образ собрали. Теперь нужно просканировать его на уязвимости. Современные registry уже содержат инструментарий для этого.
Инструменты
Инструмент | Особенности | Цена |
|---|---|---|
Docker Registry, ChartMuseum, Robot-users. | Free | |
Есть все в том числе и Docker. | Free и pro | |
Комбайн, чего в нем только нет. | Free и pro | |
etc |
Deploy
Стадия для развертывания приложения в различных окружениях.

Не все окружения хорошо сочетаются со стратегиями развертывания.
rolling – классика;
recreate – все что угодно, но не production;
blue/green – в 90% процентов случаев этот способ применим только к production окружениям;
canary – в 99% процентов случаев этот способ применим только к production окружениям.
Stateful
Нужно еще помнить, что даже имея одинаковый код в stage и production, production может развалиться именно из-за того, что stateful у них разный. Миграции могут отлично пройти на пустой базе, но появившись на проде, сломать зеленые кружочки/галочки в пайплайне. Поэтому для stage/pre-production следует предоставлять обезличенный бэкап основной базы.
И не забудьте придумать способ откатывания ваших релизов на последний/конкретный релиз.
Инструменты
Инструмент | Особенности |
|---|---|
Docker-compose для helm. Наша разработка. | |
Собираем ямлики в одном месте. | |
"Клуб любителей пощекотать GitOps". | |
Было выше. | |
Для тех, кто любит сам придумывать шаблонизацию. | |
etc |
На правах рекламы скажу что helmwav'у очень не хватает ваших звезд на GitHub. Первая публикация про helmwave.
Integration testing
Приложение задеплоили. Оно где-то живет в отдельном контуре.Наступает этап интеграционного тестирования. Тестирование может быть как ручным, так и автоматизированным. Автоматизированные тесты можно встроить в пайплайн.
Инструменты
Performance testing (load/stress testing)
Данный вид тестирования имеет смысл проводить на stage/pre-production окружениях. С тем условием, что ресурсные мощности на нем такие же, как в production.
Инструменты, чтобы дать нагрузку
Инструмент | Особенности |
|---|---|
wrk | Отличный молоток. Но не пытайтесь прибить им все подряд. |
Cтильно-модно-JavaScript! Используется в AutoDevOps. | |
Artillery.io | Снова JS. Сравнение с k6 |
OldSchool. | |
Перестаньте дудосить конурентов. | |
etc |
Инструменты, чтобы оценить работу сервиса
Инструмент | Особенности |
|---|---|
sitespeed.io | Внутри: coach, browserTime, compare, PageXray. |
Тулза от Google. Красиво, можешь показать это своему менеджеру. Он будет в восторге. Жаль, только собаки не пляшут. | |
etc |
Code Review / Approved
Одним из важнейших этапов являются Merge Request. Именно в них могут производиться отдельные действия в pipeline перед слиянием, а также назначаться группы лиц, требующих одобрения перед cлиянием.
Список команд/ролей:
QA;
Security;
Tech leads;
Release managers;
Maintainers;
DevOps;
etc.
Очевидно, что созывать весь консилиум перед каждым MR не нужно, каждая команда должна появится в свой определённый момент MR:
вызывать безопасников имеет смысл только перед сливанием в production;
QA перед release ветками;
DevOps'ов беспокоить, только если затрагиваются их компетенции: изменения в helm-charts / pipeline / конфигурации сервера / etc.
Developing flow
Чаще всего каждая компания, а то и каждый проект в компании, решает изобрести свой велосипед-флоу. Что после нескольких итераций приходит к чему-то, что может напоминать gitflow, gitlabFlow, githubFlow или все сразу.
Это и не хорошо, и не плохо – это специфика проекта. Есть мнения, что gitflow не торт. GithubFlow для относительно маленьких команд. А про gitlabFlow мне нечего добавить, но есть наблюдение, что его не очень любят продакты - за то, что нельзя отслеживать feature-ветки.
Если вкратце, то:
Gitflow: feature -> develop -> release-vX.X.X -> master (aka main) ->
tag;GitHubFlow: branch -> master (aka main);
GitLabFlow: environmental branches.
TL;DR
Общий концепт
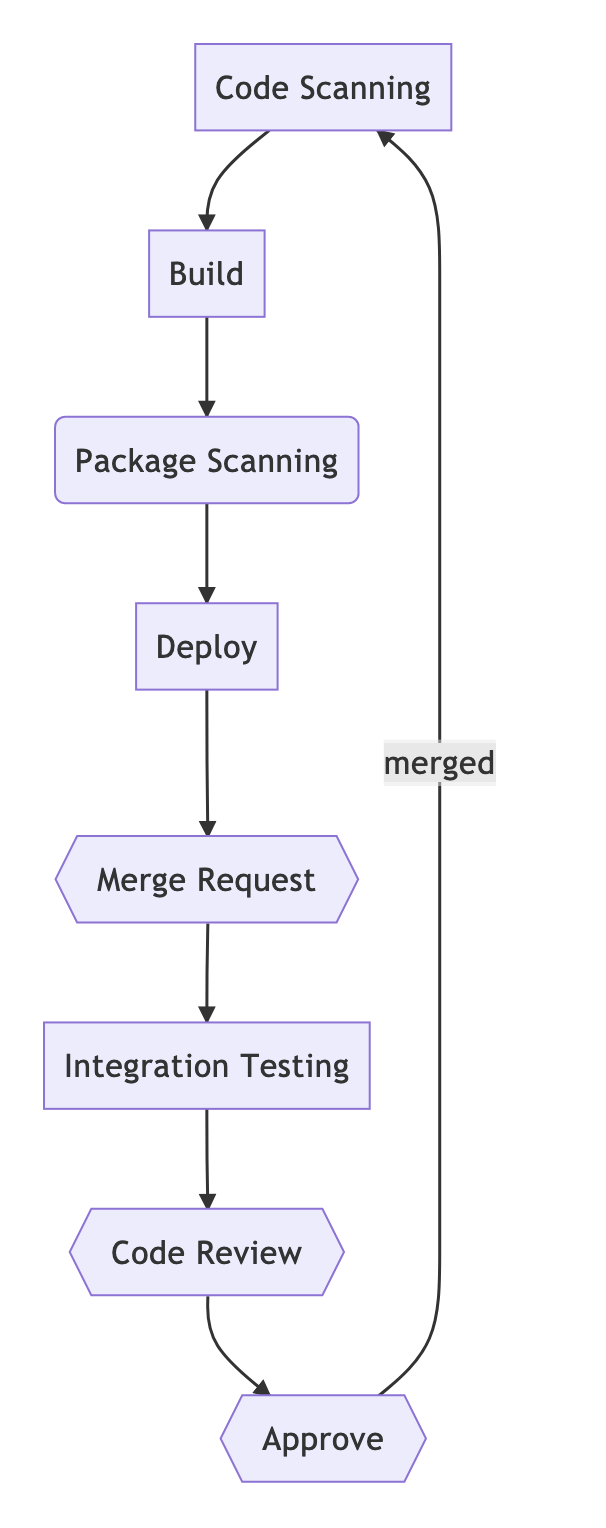
_
Feature-ветка

Pre-Production -> Production

P.S.
Если я где-то опечатался, упустил важную деталь или, по вашему мнению, пайплайн недостаточно идеальный, напишите об этом мне – сделаю update.
Разработчик создал ветку и запушил в нее код. Что дальше?
Оставляйте варианты ваших сценариев в комментариях.

