 Чем качественней налажен процесс разработки, тем реже будут проявляться проблемы с производительностью в релизе. С другой стороны, полностью их не удастся избежать по той банальной причине, что в процессе разработки были сделаны “предположения” относительно условий эксплуатации веб-сервиса, а жизнь постоянно вносит свои коррективы.
Чем качественней налажен процесс разработки, тем реже будут проявляться проблемы с производительностью в релизе. С другой стороны, полностью их не удастся избежать по той банальной причине, что в процессе разработки были сделаны “предположения” относительно условий эксплуатации веб-сервиса, а жизнь постоянно вносит свои коррективы.От того как часто появляются такие проблемы и как быстро они исправляются зависит многое – удовлетворенность пользователя сервисом, репутация разработчика и т.д. Как можно бороться с проблемами производительности?
Один из сценариев – пассивная реакция, т.е. решение проблем по мере их поступления. В этом случае служба поддержки накапливает жалобы до наступления какой-то “критической массы” и затем привлекает разработчиков. Разработчики тратят некоторое время на поиск и устранение проблем, затем веб-сервис снова начинает оперативно обрабатывать задачи.
Главный недостаток такого варианта – пользователи успевают сполна “насладиться” оперативностью работы веб-сервиса, прежде чем им займутся разработчики. А ведь проблему после этого еще только предстоит найти. Еще один недостаток – разработчики должны работать по срокам “на вчера”, что тоже не впечатляет.
Другой вариант, псевдо-активная реализация. Ставятся какие-то утилиты для мониторинга всего и вся, потом главный шаман с бубном время от времени просматривает графики и пытается идентифицировать факт наличия проблемы по ним.
Этот вариант мало отличается от первого, ибо шаман устает смотреть в скучные графики и цифры, и чаще всего все сводится к тому же первому варианту. Но даже если шаман успеет распознать проблему до лавины жалоб, то все равно еще нужно время на поиск и устранение проблемы.
Требуется иной сценарий, который позволил бы с минимальными издержками “держать руку на пульсе” и оперативно локализовывать источник проблем.
Проактивный мониторинг
Проактивный мониторинг означает две вещи:
- Активную нотификацию о проблемах, будь то по телефону, смс, жабберу, icq или мылу;
- Четкий план действий по локализации и устранению проблем.
Нотификацию удобно выстраивать на готовой системе мониторинга, коих в мире не мало. Наколеночные рассматривать не будем, ибо они – удел энтузиастов. А вот из профессиональных хотелось бы отметить cacti, nagios и zabbix. Однако под требования нотификации подходит только горячо и взаимно любимый Zabbix ( или я что-то упустил в cacti? ), а nagios не сильно приспособлен к хранению исторических данных, что весьма полезно для анализа проблем.
Использование оповещений серьезно разгрузит местных шаманов, ибо вместо того чтобы пялиться в сотни графиков сутки на пролет, достаточно носить с собой телефон в кармане. Вопрос лишь в том – что и как мониторить.
Если говорить о производительности, а другие темы мы сейчас не затрагиваем, то достаточно мониторить всего один параметр – среднее время отклика. Если оно превышает указанное в требованиях к веб-сервису значение, то мы имеем проблему и надо с ней разбираться, причем оперативно. Для этого нужно в какой-то момент потратить немного времени и спланировать свою работу по локализации проблем.
Начать план следует с составления схемы обработки запроса. Примером такой схемы может быть:
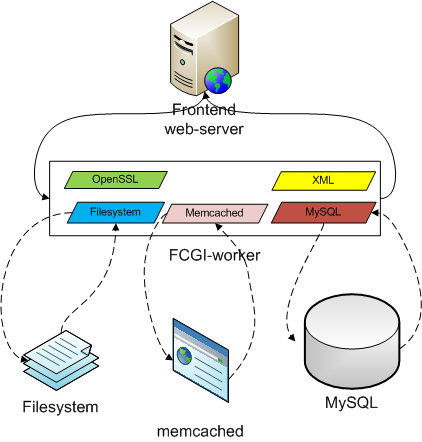
На этой схеме есть два типа компонентов — опциональные и обязательные. Обязательные, такие как веб-сервер и обработчик, всегда присутствуют в обработке запроса и обращение к ним обозначено сплошной линией. А вот компоненты типа файловой системы, мемкеша и мускула могут являться опциональными, потому и выделены прерывистой линией.
Имея такую схему, следует расписать список возможных проблем по каждому компоненту и методику их устранения, дабы разработчиков нужно было привлекать в исключительных случаях. Примером такого списка может быть следующий:
| # | Симптом | Причина | Реакция |
|---|---|---|---|
| 1. | Среднее время ожидания свободного обработчика превысило допустимое значение | Наплыв пользователей | Горизонтальное масштабирование |
| 2. | Среднее время чтения\передачи запроса превысило адекватное значение | Мы превысили ресурсы сети | Смена тарифного плана |
| 3. | Среднее время обработки запроса превысило допустимое значение | Проблемы с кодом\базой\и.т.д. | Пора привлекать разработчиков |
На самом деле третий пункт состоит из множества подпунктов, часть из которых решаются административно и только в редких случаях должны привлекаться разработчики.
Преимущество от наличия такого плана очевидно — большая часть проблем решается если не моментально, то в определенные сроки. Однако нужно изрядно потрудиться как для составления плана, так и для доработки системы, но об этом потом.
Продолжение следует...
