
The future belongs to the companies and people that turn data into products
Человечество никогда не стояло на месте – суровый закон выживания постоянно заставлял его двигаться вперед. В истории развития человечества революции происходили всегда – одно общество сменялось другим, а устаревшие технологии заменялись более прогрессивными. Последняя информационная революция связана с появлением персональных компьютеров в 80-е годы ХХ века. В результате появления новых технологий, позволяющих накапливать информацию в новом виде – цифровом, начало формироваться информационное общество, приходящее на смену индустриальному. Информационное общество – общество, в котором большинство занято производством, хранением, переработкой и реализацией информации. По сравнению с индустриальном обществом, где все силы направлены на производство и потребление товаров, в информационном обществе потребляются интеллект и знания, что приводит к увеличению доли умственного труда. Развитие информационных технологий планомерно меняет структуру общества, а также влияют на метод принятия решений. На первый план в информационном обществе выходят люди, обеспечивающие производство, передачу и обработку информации, т.е. специалисты в информационно-коммуникационных технологиях. Решения в информационном обществе, касающиеся большого количества людей, принимаются большинством, на основе голосования. Время реакции на какое-либо событие составляет считанные минуты, а само событие становится известным практически сразу. Несмотря на это, некоторые правительства, не понимающие эволюционных процессов, происходящих в современном обществе, пытаются ограничить доступ к самому ценному предмету потребления в новом обществе – информации. Люди, выросшие в обществе, где темы для обсуждения искусственно ограничены, а некоторые из них являются запретными, не будут полноценными по сравнению с людьми, выросшими в обществе со свободным доступом к любой информации. Необходимую цензуру будет проводить само общество – и чем выше будет уровень развитие такого общества, тем выше будет уровень самоцензуры. Хорошо, если полный переход на информационную модель общества будет плавным, без потрясений и революций. Совсем плохо, если нам придётся пережить смутные времена. Что ж, у нас будет возможность проследить за развитием событий в дальнейшем. Однако я хотел поговорить не об этом.
Основной ценностью и предметом потребления в информационном обществе становится информация, а точнее знания. В настоящее время, объем накопленных данных в компаниях удваивается каждые 18 месяцев и период удваивания постоянно сокращается. Общий объем цифровых данных в мире на 2012 год составляет около 2.7 зеттабайта – это 27 и 20 нулей. Увеличение по сравнению с 2011 годом практически на 50%, и в двадцать раз больше, чем в 2005 году. К 2015 году прогнозирует общий объем данных в 0.8 йоттабайт – это 1024.

Если посмотреть на кривую роста объема данных, то можно увидеть, что она приобретает экспоненциальную форму. И, хотя, бОльшая часть из этих данных являются по сути цифровой видео, фото и аудио информацией, объем текстовых данных сравнительно высок. Неудивительно, что термин Big Data, зародившийся совсем недавно, можно услышать сейчас всё чаще и чаще. Определить, относится ли тот или иной инструмент или продукт к области Big Data, можно сравнительно просто – используя правило трех V. Это Volume – объем, Velocity – скорость, Variety – многообразие. Если рассматриваемый объект подпадает под определения правила трех V, то он относится к области Big Data. Из большого разнообразия развивающихся информационно-коммуникационных технологий можно выделить три основных тренда на текущий момент – виртуализация, облака и область, относящаяся к хранению и обработке большие объемов данных(Big Data). И до этого данные были объектом изучения и анализа, но в настоящее время это явление приобретает поистине глобальный масштаб. Никто не хочет хранить данные в хранилище данных просто так, позволяя лежать им там мертвым грузом. Если рассмотреть иерархическую информационную модель DIKW поближе, то мы узнаем, что данные сами по себе не представляют никакого интереса. Прежде, чем приобрести какую-либо ценность, они должны пройти через несколько стадий. Если быть точнее, то уровень данных находиться в самом основании, следующая ступень по модели DIKW это информация, добавляющая к данным контекст, дальше идет знание, которое уже можно применить и имеющее некоторую ценность, последней ступенью является мудрость, позволяющая получить из данных факты и на их основе принимать решения. Модель DIKW лежит в основе концепции управления данными. Однако если технологическая база для хранения и обработки данных больших объемов уже существует и активно внедряется во все мире, то теоретическая область отстает от нее. Именно это послужило причиной возникновения так называемой Data Science – науки о данных. Термин Data Science более десяти лет назад ввел в обиход профессор Вильям Кливленд, который написал Data Science: An Action Plan for Expanding the Technical Areas of the Field of Statistics. А в этом году компания EMC провела первый Data Science Summit 2012 в Лас-Вегасе, где рассматривались проблемы, связанные с методами работы с данными, определениями и проблемами, существующими в этой области. Кстати, компания EMC даже открыла вакансию Data Scientist в России, что говорит о заинтересованности EMC в развитии данного направления.
В этой статье мне хотелось бы поближе рассмотреть, что скрывается за термином Data Science и кто такие data scientist.
На самом деле, data science не может считаться полноценной наукой на сегодняшний момент, так как представляет из себя мешанину из совокупности методов и технологий для анализа больших объемов данных. Тем не менее, её рождение происходит на наших с вами глазах и в настоящее время там идет передел за право называть конкретные технологии и методы относящимися к data science, а также идут споры о самом предмете этой науки. В более широком значении, data science – это то, что позволяет извлекать знания из набора данных. От обычной статистики Data science отличается более комплексным подходом – для анализа привлекаются все возможные источники, включающие в себя не только таблицы с сухой статистикой, но также и другие данные.
Это заметно усложняет поиск специалистов в этой области, так как их попросту нет. Специалисты должны сочетать в себе редкий набор качеств: любознательность, знание математической статистики, широкий кругозор в области информационных технологий, способность и желание открывать новое, быть знакомыми с последними достижениями в области Big Data, способность привлекать для решения самые разные данные и методы их обработки. Достаточно хорошо выразил требования к data scientists Майкл Лукидис в своей статье «What is Data Science», опубликованной в журнале O’REILLY RADAR. Также эти требования можно представить на пересечении трех кругов на картинке ниже:
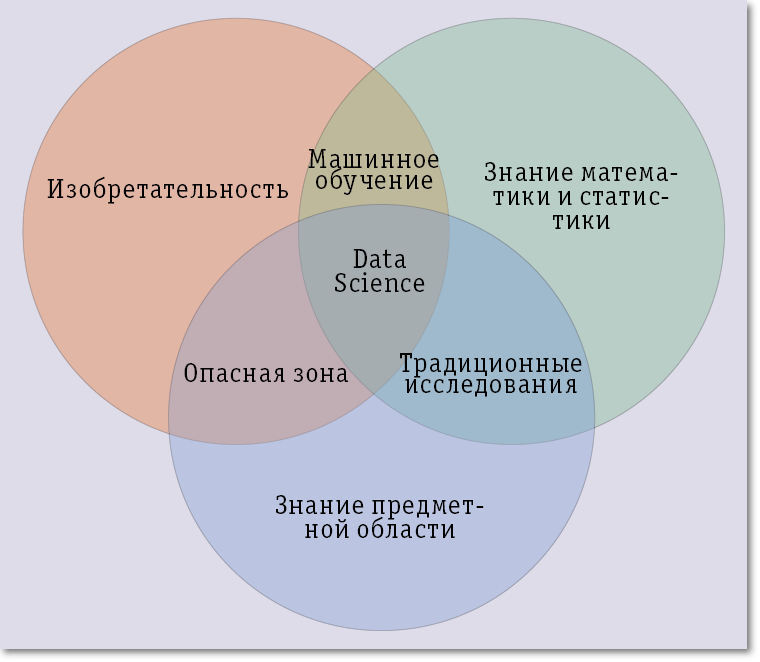
Несмотря на это, не стоит относить data scientist к ученому в белом халате, изобретающему революционные технологии у себя в лаборатории. Вероятнее всего, лучше охарактеризовать data scientist, как человека, знающего методы математической статистики, знакомого с основными инструментами, человека с широким кругозором в области информационных технологий, особенно Big Data, в прошлом занимающегося теоретическими исследованиями в этой области.
Одной из главных тем для обсуждения на прошедшей конференции Data Science Summit 2012 являлась тема, касающаяся поиска таких специалистов в мире, а также их перспективы в будущем. Если мы присмотримся к динамике роста объема данных, а также к стремительному развитию информационно-коммуникационных технологий, то несложно сделать вывод, что в будущем потребность в таких специалистах будет только возрастать, а спрос на них будет постоянно повышаться. Некоторые правительства уже оценили перспективу и предприняли соответствующие шаги — Национальный научный фонд США приравнял тематику Big Data к научной сфере, анонсировав новые области финансирования междисцисплинарных исследований по Большим данным, к чему приурочена целая серия весенних анонсов.
Чтобы иметь более полной представление о том, кто такой data scientist, я предложу список вопросов, которые могут быть заданы претенденту на эту вакансию. Сразу скажу, что список для ознакомления и data scientist, к сожалению, нам не нужны :(
Вопрос 1:
Как вы рассчитаете дисперсию столбцов матрицы на языке R без использования циклов?
Вопрос 2:
Предположим, у вас есть CSV файл с двумя колонками: 1 — имена, 2 — фамилии. Напишите код с использованием скриптового языка для создания CSV файла с фамилиями в 1-ом столбце и именами во 2-ом столбце.
Вопрос 3:
Объясните Map/Reduce, а затем напишите простой пример с его использованием на вашем любимом языке программирования.
Вопрос 4:
Предположим, что вы Google и хотите оценить click through rate(CTR) по объявлениям. У вас есть 1000 запросов, каждый из которых был вызван 1000 раз. Каждый запрос показывает 10 объявлений и все объявления уникальны. Оцените CTR для каждого объявления.
Вопрос 5:
Предположим, вы выполнили регрессию с 10-ю переменными, одна из них является значимой на доверительном интервале в 95%. Вы узнаете, что 10% данных в случайном порядке были упущены, а их значения Y удалены. Как бы вы предсказали значения потерянных Y?
Вопрос 6:
Предположим, у вас есть возможность поехать в одно из двух отделений банка. В первом отделении 10 кассиров, каждый из которых имеет отдельную очередь из 10 клиентов, во втором отделении 10 кассиров, с одной общей очередью в 100 клиентов. Какое отделение вы бы выбрали?
Вопрос 7:
Объясните, чем Random forest отличаются от нормального дерева регрессии?
