Привет всем!
В предыдущем посте было рассказано о трудностях, которые испытывают разработчики при написании SQL-кода (причём актуальны эти проблемы не только для MS SQL Server). Здесь же рассказ о том, как использовать Git для версионного контроля кода SQL Server с помощью SQLFuse. Принцип тот же, что и с обычными файлами, но есть некоторые особенности.

С момента выхода первой публикации на хабре, SQLFuse был переписан для использования в качестве deploy-системы, что предопределило следующие новые качества:
До сих пор не работает:
Хотелось выразить благодарность за отзыв и тестирование SQLFuse вместе с SQL Server 2000. После проведения тестирования выяснилось, что заставить работать SQLFuse с SQL Server 2000 не получится, так в последнем отсутствуют некоторые метатаблицы, и нет должной поддержки XML на уровне языка, которые используются для генерации кода модулей таблиц.
Git не создаёт дополнительных каталогов со своими служебными файлами в каждой директории наблюдаемых структур. Так, например, поступает Subversion. Создание каталогов SQLFuse воспринимает как создание таблицы или схемы, а файлов внутри них — как модулей с текстовым определением, поэтому создание служебных каталогов Subversion не представляется возможным.
Скорее всего, SQLFuse удастся подружить и с Mercurial, — я буду рад багрепортам или почитать рассказ об опыте интеграции.
Пусть имеются два сервера SQL Server — первый рабочий (work), второй тестовый (test); один Deploy-сервер. Публичный репозиторий располагается на ресурсе github.com.
Сандра — коммитер основной ветки, может вносить изменения на рабочий и тестовый сервера. Боб — разработчик, который может вносить изменения только на тестовый сервер. На Deploy-сервере в домашних директориях пользователей Сандры и Боба смонтирована тестовая БД. Только для Сандры дополнительно смонтирована и рабочая БД.
В предыдущей публикации также было рассказано о том, как собрать SQLFuse из исходников и какие зависимости при этом потребуются. Дополнительную информацию об этом и способах установки в систему, можно получить на странице проекта SQLFuse. Как и ранее, базой для демонстрации станет — AdventureWorks2008R2. Предполагается, что уже настроена машина под управлением одним из дистрибутивов ОС Linux, использующий в качестве демона инициализации systemd.
Создание пользователей в системе:
Не забываем сменить пароль пользователей, например, с помощью команды passwd, и задать глобальные переменные, которые необходимы для работы Git.
Пользовательский сервис systemd должен запускаться при входе пользователя в систему и монтировать БД в соответствующие директории. Для этого разместим файлы описания сервисов в директории ~/.config/systemd/user/, и конфигурационных файлов SQLFuse в директории ~/.config/sqlfuse/.
Создание необходимых каталогов:
При такой настройке, после выхода пользователя из системы сервисы будут завершаться автоматически, — эта особенность может быть использована как экстренная отмена сброса кэша в БД.
Благодаря использованию механизма экземпляров systemd, добавление нового сервиса сводится к копированию файла:
Конфигурационный файл SQLFuse, описывающий профили подключения test_advworks и work_advworks, размещается в директории ~/.config/sqlfuse, и в нашем случае будет выглядеть следующим образом:
Для ускорения работы, указывайте максимальное количество подключений больше 1, чтобы выполнять запросы к БД параллельно, при формировании списка и кода объектов таблицы. Однако, если задать значение больше 2, то это особого эффекта этого не принесёт, так как Git не умеет или не хочет распараллеливать свои запросы к файловой системе.
Можно не проделывать одну и ту же последовательность шагов для всех пользователей по подготовке SQLFuse, если разместить необходимые файлы в директории /etc/skel.
Для того, чтобы начать отслеживать изменения, Сандра должна сделать первый коммит для рабочей БД в ветку master и отправить изменения в bare-репозиторий:мне лень настраивать GitLab, поэтому для наглядности будем использовать github.com:
Далее подготовим тестовую БД и ветку testing (изначально, тестовая БД не должна быть смонтирована!):
Все слияния, изменения истории коммитов и прочие операции необходимо проводить на локальных рабочих станциях, но не как на смонтированных БД! Поэтому, чтобы случайно не сломать рабочий или тестовый сервер, можно написать несколько хуков, которые запрещают менять текущие ветки в репозиториях, где смонтированы БД, и выполнять любые команды, кроме git pull для получения изменений из центрального репозитория.
Для Боба настройка рабочей среды почти не отличается. Необходимо клонировать публичный репозиторий, перейти в ветку testing, рекурсивно удалить содержимое каталога advworks и, наконец, произвести монтирование тестовой БД, запустив сервис systemd.
Конечно, было бы очень круто, воссоздать тестовые структуры из рабочей БД путём копирования иерархии директорий и файлов, но, к сожалению, пока представления работают в режиме «только чтение» и не поддерживаются расширенные атрибуты.
Допустим, появилась необходимость задавать дилерскую скидку для каждого продукта. Для этого Боб добавит поле DealerDiscount в таблицу Production.ProductListPriceHistory для хранения процента по скидке. Также Бобу необходимо изменить функцию dbo.ufnGetProductDealerPrice.
Действия Боба для выполнения поставленной задачи будут следующими:
Как могли заметить внимательные читатели, в конце текстовых модулей (процедур, функций, триггеров и т.п.) генерируется очень много пробелов — это связано с тем, что SQL Server не корректно возвращает длину данных из метатаблиц. Реальный размер, можно определить только при выполнении процедуры sp_helptext: он всегда меньше, чем в метатаблице. Если не использовать метатаблицу sys.sql_modules, а сразу процедуру sp_helptext, то значительно снижается скорость получения данных при выполнении команды git status потому, что приходится вызывать процедуру в цикле. Именно поэтому, чтобы предотвратить некорректную работу утилит с файлами, сделан такой костыль. Имейте, пожалуйста, в виду, что при выполнении сброса кэша в БД происходит усечение концевых пробелов в текстовых модулях.
После проверки, Сандра должна произвести слияние нового функционала с веткой master, внеся изменения в рабочую БД, — действия такие же как у Боба, только с веткой master. Если процесс переноса изменений сложен, то слияние может быть выполнено «вручную». После применения SQL-команд, изменения должны быть зафиксированы и отправлены в центральный репозиторий, и синхронизированы ветки тестовые и разработок нового функционала.
Рассмотренная схема разработки очень похожа на утопию, где все изменения могут быть выполнены атомарно и без ошибок, однако, SQLFuse может быть использован только для отслеживания кода модулей, при изменениях, вносимых напрямую в БД SQL-скриптами. Или же для тестовых серверов вносить изменения смешанным методом, а для рабочих использовать скрипт, который будет генерировать разницу между коммитами. Следите за моим аккаунтом на гитхабе, возможно, скоро такой скрипт появится, но, я надеюсь, кто-то меня опередит и напишет его первым, выложив в свободный доступ.
Итак, рассмотренный подход позволяет осуществить:
В следующей публикации будет описано применение системы автоматической генерации документации к модулям SQL Server, а также способ создания/редактирования представлений.
В предыдущем посте было рассказано о трудностях, которые испытывают разработчики при написании SQL-кода (причём актуальны эти проблемы не только для MS SQL Server). Здесь же рассказ о том, как использовать Git для версионного контроля кода SQL Server с помощью SQLFuse. Принцип тот же, что и с обычными файлами, но есть некоторые особенности.
Основные изменения в SQLFuse
С момента выхода первой публикации на хабре, SQLFuse был переписан для использования в качестве deploy-системы, что предопределило следующие новые качества:
- Изменения, сделанные над файлами и директориями накапливаются в кэше, затем по таймеру выполняется сброс SQL-команд в БД, обернув их перед этим в транзакцию. При сбое в одной операции происходит откат всех сделанных изменений и очистка кэша, приводится в соответствие иерархия файлов и директорий с их фактическим состоянием относительно БД. Вместо сброса по таймеру изменений, можно было сделать, например, взаимодействие с D-Bus, но это уже дальнейший этап развития проекта.
- Текст содержимого файлов модулей таблицы (колонки, ограничения и др.) не отображает имя модуля, чтобы не ввести в заблуждение систему версионного контроля: имя файла или директории всегда будет являться именем модуля.
- Оптимизация SQL-команд перед их сбросом в БД. Как оказалось, при накладывания патчей на файлы, происходит их удаление, затем создание вместе с новыми данными, — недопустимо для БД из-за возможности потери данных. Поэтому такие операции преобразуются, по возможности, к одной команде ALTER. Мало того, Git удаляет полностью директории, для которых накладывается патч, а затем создаёт их заново вместе с изменениями патча — эта проблема была также решена.
До сих пор не работает:
- Поддержка создания/редактирования представлений. Учитывайте, пожалуйста, что формат отображения представлений может измениться.
- XML-индексы
- Расширенные атрибуты
- Порядок следования колонок при создании таблиц. То есть при создании таблицы колонки будут созданы в базе данных в том порядке, в котором были созданы на файловой системе, в последующих версиях SQLFuse эта проблема, надеюсь, решится.
Хотелось выразить благодарность за отзыв и тестирование SQLFuse вместе с SQL Server 2000. После проведения тестирования выяснилось, что заставить работать SQLFuse с SQL Server 2000 не получится, так в последнем отсутствуют некоторые метатаблицы, и нет должной поддержки XML на уровне языка, которые используются для генерации кода модулей таблиц.
Почему Git?
Git не создаёт дополнительных каталогов со своими служебными файлами в каждой директории наблюдаемых структур. Так, например, поступает Subversion. Создание каталогов SQLFuse воспринимает как создание таблицы или схемы, а файлов внутри них — как модулей с текстовым определением, поэтому создание служебных каталогов Subversion не представляется возможным.
Скорее всего, SQLFuse удастся подружить и с Mercurial, — я буду рад багрепортам или почитать рассказ об опыте интеграции.
Схема разработки и необходимая инфраструктура
Пусть имеются два сервера SQL Server — первый рабочий (work), второй тестовый (test); один Deploy-сервер. Публичный репозиторий располагается на ресурсе github.com.
Сандра — коммитер основной ветки, может вносить изменения на рабочий и тестовый сервера. Боб — разработчик, который может вносить изменения только на тестовый сервер. На Deploy-сервере в домашних директориях пользователей Сандры и Боба смонтирована тестовая БД. Только для Сандры дополнительно смонтирована и рабочая БД.
Настройка Deploy-сервера
В предыдущей публикации также было рассказано о том, как собрать SQLFuse из исходников и какие зависимости при этом потребуются. Дополнительную информацию об этом и способах установки в систему, можно получить на странице проекта SQLFuse. Как и ранее, базой для демонстрации станет — AdventureWorks2008R2. Предполагается, что уже настроена машина под управлением одним из дистрибутивов ОС Linux, использующий в качестве демона инициализации systemd.
Создание пользователей в системе:
useradd -m -N sandra
useradd -m -N bob
Не забываем сменить пароль пользователей, например, с помощью команды passwd, и задать глобальные переменные, которые необходимы для работы Git.
Пользовательский сервис systemd должен запускаться при входе пользователя в систему и монтировать БД в соответствующие директории. Для этого разместим файлы описания сервисов в директории ~/.config/systemd/user/, и конфигурационных файлов SQLFuse в директории ~/.config/sqlfuse/.
Создание необходимых каталогов:
mkdir -p ~/workspace/work/sqlserv_1/advworks
# директория для тестовой БД будет создана при клонировании репозитория
mkdir -p ~/workspace/test/sqlserv_1
mkdir -p ~/.config/sqlfuse
mkdir -p ~/.config/systemd/user
Файл-сервис test-sqlserv_1-advworks@test_advworks.service
[Unit]
Description=SQLFuse mount profile %i for %u to %h/workspace/%P
[Service]
Type=forking
ExecStart=/usr/bin/sqlfuse -o profilename=%i %h/workspace/%P
ExecStop=/usr/sbin/fusermount -u %h/workspace/%P
TimeoutSec=5min
[Install]
WantedBy=default.target
При такой настройке, после выхода пользователя из системы сервисы будут завершаться автоматически, — эта особенность может быть использована как экстренная отмена сброса кэша в БД.
Благодаря использованию механизма экземпляров systemd, добавление нового сервиса сводится к копированию файла:
cd ~/.config/systemd/user
cp test-sqlserv_1-advworks@test_advworks.service work-sqlserv_1-advworks@work_advworks.service
Конфигурационный файл SQLFuse, описывающий профили подключения test_advworks и work_advworks, размещается в директории ~/.config/sqlfuse, и в нашем случае будет выглядеть следующим образом:
Конфигурационный файл sqlfuse.conf
[global]
# Максимальное количество подключений
maxconn=2
# Наименование приложения, под которым производиться подключение к серверу
appname=SQLFuse
# Использовать ANSI_NPW
ansi_npw=true
# Горячий старт. Пользователь должен иметь права на создание временных таблиц
hot_start=true
# Фильтр по имени - данные объекты не будут искаться в БД
filter=(?i)(\.dav$|\.html$|\.exe$|\.cmd$|\.ini$|\.bat$|\.vbs$|\.vbe$|\.gitignore$|\.git$|\.gitattributes$)
# Не выводить схемы
exclude_schemas=db_accessadmin;db_backupoperator;db_datareader;db_datawriter;db_ddladmin;db_denydatareader;db_denydatawriter;db_owner;db_securityadmin;guest;INFORMATION_SCHEMA;sys
# Время, с момента последней операции записи, по истечению которого сбрасывается кэш
deploy_time=10
##################
# Профиль подключения
[test_advworks]
# Экземпляр или IP-адрес сервера
servername=192.168.6.50
# Наименование БД
dbname=AdvTest
# Профиль авторизации в sqlfuse.auth.conf
auth=advauth
###################
[work_advworks]
# Экземпляр или IP-адрес сервера
servername=192.168.6.50
# Наименование БД
dbname=AdvWork
# Профиль авторизации в sqlfuse.auth.conf
auth=advauth
Для ускорения работы, указывайте максимальное количество подключений больше 1, чтобы выполнять запросы к БД параллельно, при формировании списка и кода объектов таблицы. Однако, если задать значение больше 2, то это особого эффекта этого не принесёт, так как Git не умеет или не хочет распараллеливать свои запросы к файловой системе.
Можно не проделывать одну и ту же последовательность шагов для всех пользователей по подготовке SQLFuse, если разместить необходимые файлы в директории /etc/skel.
Инициализация рабочей среды
Для того, чтобы начать отслеживать изменения, Сандра должна сделать первый коммит для рабочей БД в ветку master и отправить изменения в bare-репозиторий:
# Старт и монтирование рабочей БД
systemctl --user start work-sqlserv_1-advworks@work_advworks.service
# Инициализация и первый коммит для рабочей БД
cd ~/workspace/work/sqlserv_1
git init
git add -v advworks/
git commit -m 'Initial work commit'
# Отправка изменений в публичный репозиторий
git remote add origin https://github.com/alexandrmov/adventureworks.git
git push origin master
Далее подготовим тестовую БД и ветку testing (изначально, тестовая БД не должна быть смонтирована!):
# клонирование общедоступного репозитория из github:
cd ~/workspace/test/sqlserv_1
git clone https://github.com/alexandrmov/adventureworks.git
# сделаем иерархию для тестовой БД похожей на рабочую
mv adventureworks/* ./
rmdir adventureworks
# предпологается, что тестовая и рабочая БД отличаются
git checkout -b testing
rm -rf advworks/*
# монтирование тестовой БД
systemctl --user start test-sqlserv_1-advworks@test_advworks.service
# первый коммит ветки testing и отправка изменений в центральный репозиторий
git add -v advworks/
git commit -m 'Initial testing commit'
git push origin testing
Все слияния, изменения истории коммитов и прочие операции необходимо проводить на локальных рабочих станциях, но не как на смонтированных БД! Поэтому, чтобы случайно не сломать рабочий или тестовый сервер, можно написать несколько хуков, которые запрещают менять текущие ветки в репозиториях, где смонтированы БД, и выполнять любые команды, кроме git pull для получения изменений из центрального репозитория.
Для Боба настройка рабочей среды почти не отличается. Необходимо клонировать публичный репозиторий, перейти в ветку testing, рекурсивно удалить содержимое каталога advworks и, наконец, произвести монтирование тестовой БД, запустив сервис systemd.
Конечно, было бы очень круто, воссоздать тестовые структуры из рабочей БД путём копирования иерархии директорий и файлов, но, к сожалению, пока представления работают в режиме «только чтение» и не поддерживаются расширенные атрибуты.
Псевдореальный пример
Допустим, появилась необходимость задавать дилерскую скидку для каждого продукта. Для этого Боб добавит поле DealerDiscount в таблицу Production.ProductListPriceHistory для хранения процента по скидке. Также Бобу необходимо изменить функцию dbo.ufnGetProductDealerPrice.
Действия Боба для выполнения поставленной задачи будут следующими:
- Синхронизировать ветку master с публичным репозиторием, так как нужно использовать версию кода модулей с рабочего сервера.
- Создать колонку и ограничение, путём создания соответствующих файлов, и изменить функцию:
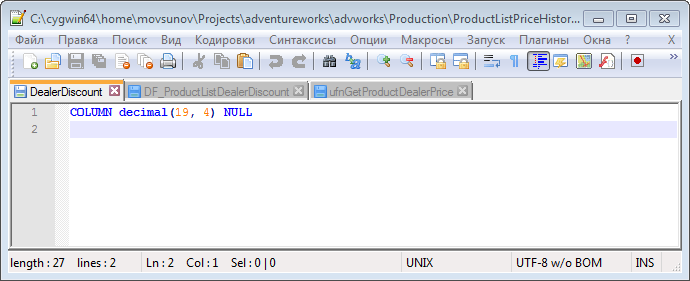
- Зафиксировать изменения в новой ветке dealerdiscount и отправить их в публичный репозиторий:
# Сохранение сделанных изменений в отдельной ветке git checkout -b dealerdiscount git add advworks/dbo/ufnGetProductDealerPrice git add advworks/Production/ProductListPriceHistory/DealerDiscount git add advworks/Production/ProductListPriceHistory/DF_ProductListDealerDiscount git commit -m "Dealer discount" # Отправка локальных изменений в центральный репозиторий git push origin dealerdiscount # Слияние новых изменений в тестовую ветку git checkout testing git rebase testing dealerdiscount # Отправка изменений ветки тестового сервера в центральный репозиторий git push origin testing
- Войти под своим логином на Deploy-сервер и внести изменения в тестовую базу данных для обкатки и тестирования новых изменений:
cd ~/workspace/test/sqlserv_1/ git fetch git pull origin testing
- Создать, что называется Pull Request (здесь можете посмотреть пример), для обсуждения и окончательной проверки коммитером перед слиянием в рабочую БД.
Как могли заметить внимательные читатели, в конце текстовых модулей (процедур, функций, триггеров и т.п.) генерируется очень много пробелов — это связано с тем, что SQL Server не корректно возвращает длину данных из метатаблиц. Реальный размер, можно определить только при выполнении процедуры sp_helptext: он всегда меньше, чем в метатаблице. Если не использовать метатаблицу sys.sql_modules, а сразу процедуру sp_helptext, то значительно снижается скорость получения данных при выполнении команды git status потому, что приходится вызывать процедуру в цикле. Именно поэтому, чтобы предотвратить некорректную работу утилит с файлами, сделан такой костыль. Имейте, пожалуйста, в виду, что при выполнении сброса кэша в БД происходит усечение концевых пробелов в текстовых модулях.
После проверки, Сандра должна произвести слияние нового функционала с веткой master, внеся изменения в рабочую БД, — действия такие же как у Боба, только с веткой master. Если процесс переноса изменений сложен, то слияние может быть выполнено «вручную». После применения SQL-команд, изменения должны быть зафиксированы и отправлены в центральный репозиторий, и синхронизированы ветки тестовые и разработок нового функционала.
Заключение
Рассмотренная схема разработки очень похожа на утопию, где все изменения могут быть выполнены атомарно и без ошибок, однако, SQLFuse может быть использован только для отслеживания кода модулей, при изменениях, вносимых напрямую в БД SQL-скриптами. Или же для тестовых серверов вносить изменения смешанным методом, а для рабочих использовать скрипт, который будет генерировать разницу между коммитами. Следите за моим аккаунтом на гитхабе, возможно, скоро такой скрипт появится, но, я надеюсь, кто-то меня опередит и напишет его первым, выложив в свободный доступ.
Итак, рассмотренный подход позволяет осуществить:
- возможность контролировать оформление кода при коммитах;
- сохранность данных при конкурентных корректировках одних и тех же модулей SQL Server;
- ведение истории правок модулей вносимых пользователями;
- использование ресурсов на подобие GitHub, и веб-приложений таких как GitLab;
- более гибкий поиск по коду и построение графов зависимостей между модулями без подключения к БД.
В следующей публикации будет описано применение системы автоматической генерации документации к модулям SQL Server, а также способ создания/редактирования представлений.
Only registered users can participate in poll. Log in, please.
Каким образом вы осуществляете версионный контроль SQL-кода?
11.93% Проприетарное ПО13
33.03% Сохраняем вручную код в файлы, либо отслеживаем заскриптованную БД целиком/частично36
39.45% Версионный контроль SQL-кода не ведётся43
15.6% Другой метод, ответ в комментариях17
109 users voted. 47 users abstained.
