Большинство компаний сегодня накапливают различные данные, полученные в процессе работы. Часто данные приходят из различных источников — структурированные и не очень, иногда в режиме реального времени, а иногда они доступны в строго определенные периоды. Все это разнообразие нужно структурированно хранить, чтоб потом успешно анализировать, рисовать красивые отчеты и вовремя замечать аномалии. Для этих целей проектируется хранилище данных (Data Warehouse, DWH).
Существует несколько подходов к построению такого универсального хранилища, которые помогают архитектору избежать распространенных проблем, а самое главное обеспечить должный уровень гибкости и расширяемости DWH. Об одном из таких подходов я и хочу рассказать.
Кому будет интересна эта статья?
- Ищете более функциональную альтернативу схеме «звезды» и Третьей Нормальной Форме?
- У Вас уже есть хранилище данных, но его тяжело дорабатывать?
- Нужна хорошая поддержка историчности, а текущая архитектура для этого не подходит?
- Возникают проблемы при сборе данных из нескольких источников?
Если на какой-либо из этих вопросов Вы ответили утвердительно, и при этом не знакомы с Data Vault — прошу заглянуть под кат!
Data Vault — гибридный подход, объединивший достоинства знакомой многим схемы «звезды» и 3-ей нормальной формы. Впервые эта методология была анонсинована в 2000 году Дэном Линстедтом (Dan Linstedt). Подход был придуман в процессе разработки хранилища данных для Министерства Обороны США и хорошо себя зарекомендовал. Позже, в 2013 году, Дэн анонсировал версию 2.0, доработанную с учетом быстро набравших популярность технологий (NoSQL, Hadoop) и новых требований, выставляемых к DWH. Поговорим мы именно о Data Vault 2.0.
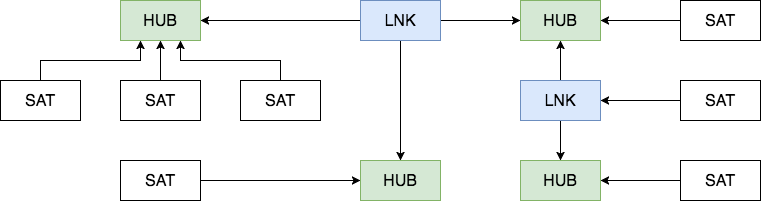
Data Vault состоит из трех основных компонентов — Хаб (Hub), Ссылка (Link) и Сателлит (Satellite).
Хаб
Хаб — основное представление сущности (Клиент, Продукт, Заказ) с позиции бизнеса. Таблица-Хаб содержит одно или несколько полей, отражающих сущность в понятиях бизнеса. В совокупности эти поля называются «бизнес ключ». Идеальный кандидат на звание бизнес-ключа это ИНН организации или VIN номер автомобиля, а сгенерированный системой ID будет наихудшим вариантом. Бизнес ключ всегда должен быть уникальным и неизменным.
Хаб так же содержит мета-поля load timestamp и record source, в которых хранятся время первоначальной загрузки сущности в хранилище и ее источник (название системы, базы или файла, откуда данные были загружены). В качестве первичного ключа Хаба рекомендуется использовать MD5 или SHA-1 хеш от бизнес ключа.
Таблицы-Хабы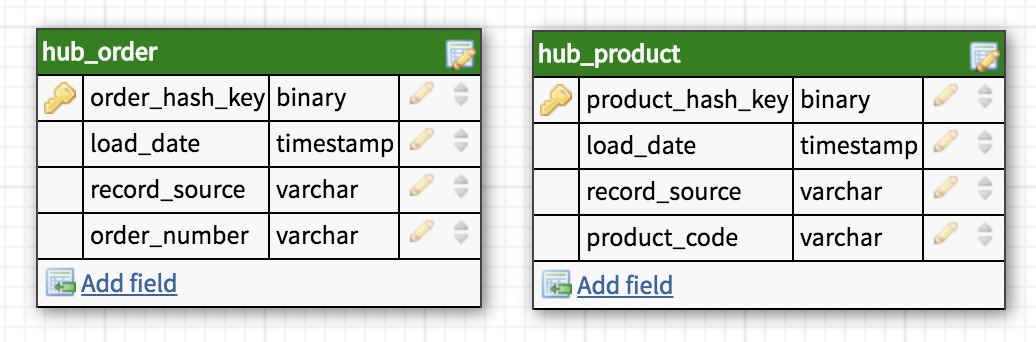
Ссылка
Таблицы-Ссылки связывают несколько хабов связью многие-ко-многим. Она содержит те же метаданные, что и Хаб. Ссылка может быть связана с другой Ссылкой, но такой подход создает проблемы при загрузке, так что лучше выделить одну из Ссылок в отдельный Хаб.
Таблица-Ссылка
Сателлит
Все описательные атрибуты Хаба или Ссылки (контекст) помещаются в таблицы-Сателлиты. Помимо контекста Сателлит содержит стандартный набор метаданных (load timestamp и record source) и один и только один ключ «родителя». В Сателлитах можно без проблем хранить историю изменения контекста, каждый раз добавляя новую запись при обновлении контекста в системе-источнике. Для упрощения процесса обновления большого сателлита в таблицу можно добавить поле hash diff: MD5 или SHA-1 хеш от всех его описательных атрибутов. Для Хаба или Ссылки может быть сколь угодно Сателлитов, обычно контекст разбивается по частоте обновления. Контекст из разных систем-источников принято класть в отдельные Сателлиты.
Таблицы-Сателлиты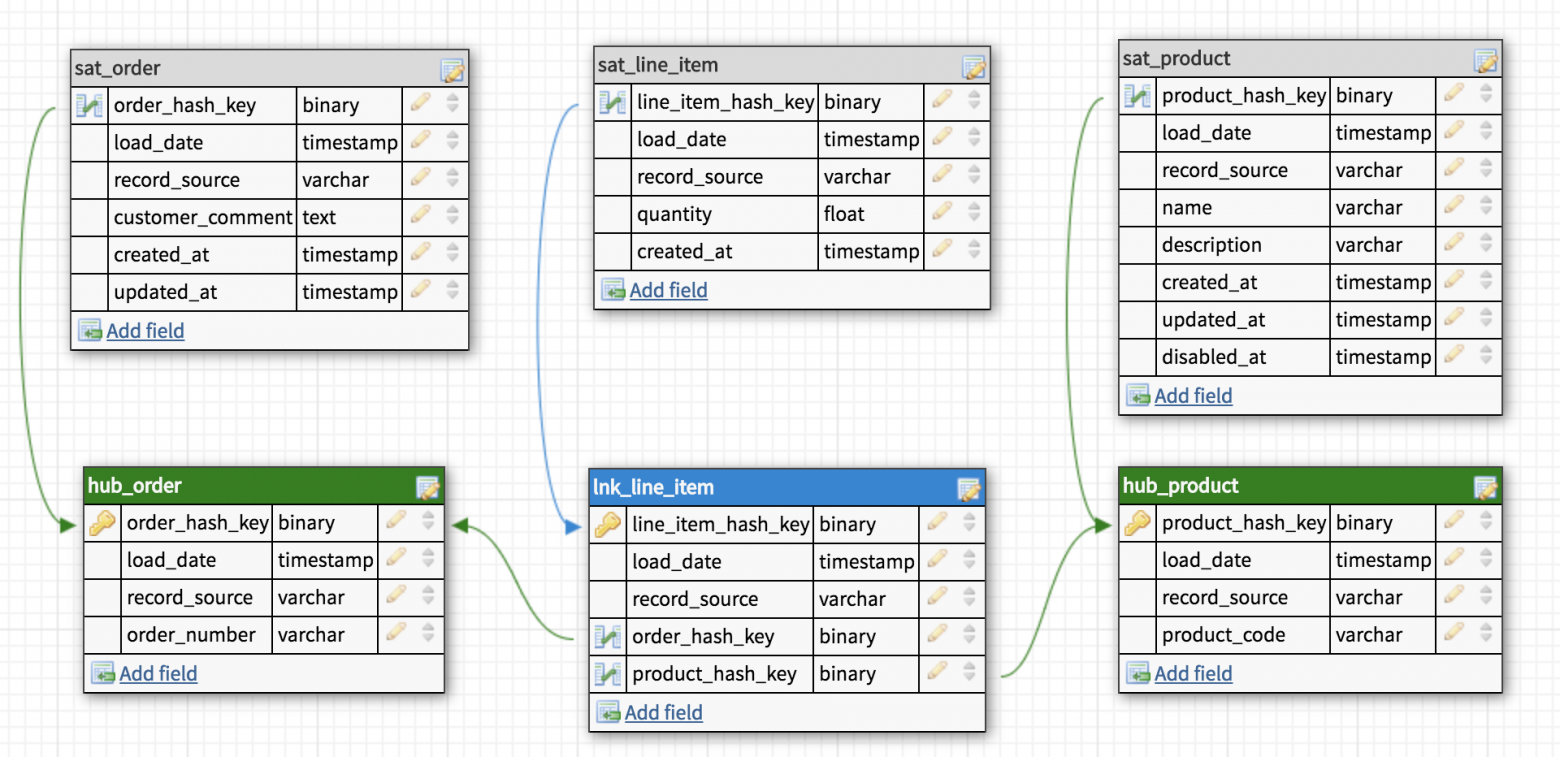
Как с этим работать?
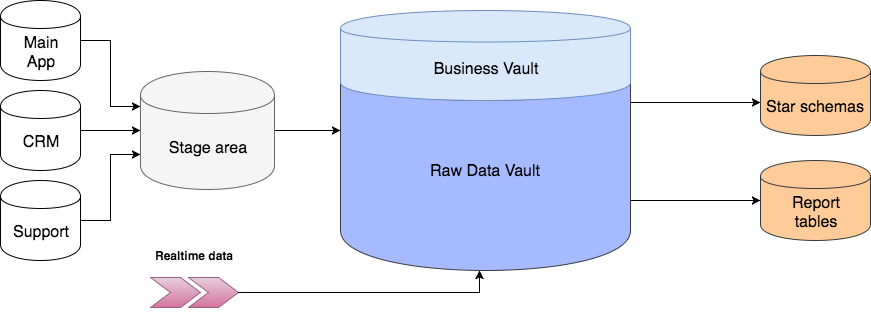
* Картинка основана на иллюстрации из книги Building a Scalable Data Warehouse with Data Vault 2.0
Сначала данные из операционных систем поступают в staging area. Staging area используется как промежуточное звено в процессе загрузки данных. Одна из основных функций Staging зоны это уменьшение нагрузки на операционные базы при выполнении запросов. Таблицы здесь полностью повторяют исходную структуру, но любые ограничения на вставку данных, вроде not null или проверки целостности внешних ключей, должны быть выключены с целью оставить возможность вставить даже поврежденные или неполные данные (особенно это актуально для excel-таблиц и прочих файлов). Дополнительно в stage таблицах содержатся хеши бизнес ключей и информация о времени загрузки и источнике данных.
После этого данные разбиваются на Хабы, Ссылки и Сателлиты и загружаются в Raw Data Vault. В процессе загрузки они никак не агрегируются и не пересчитываются.
Business Vault — опциональная вспомогательная надстройка над Raw Data Vault. Строится по тем же принципам, но содержит переработанные данные: агрегированные результаты, сконвертированные валюты и прочее. Разделение чисто логическое, физически Business Vault находится в одной базе с Raw Data Vault и предназначен в основном для упрощения формирования витрин.
Бизнес-Сателлит
b_sat_order_total_price
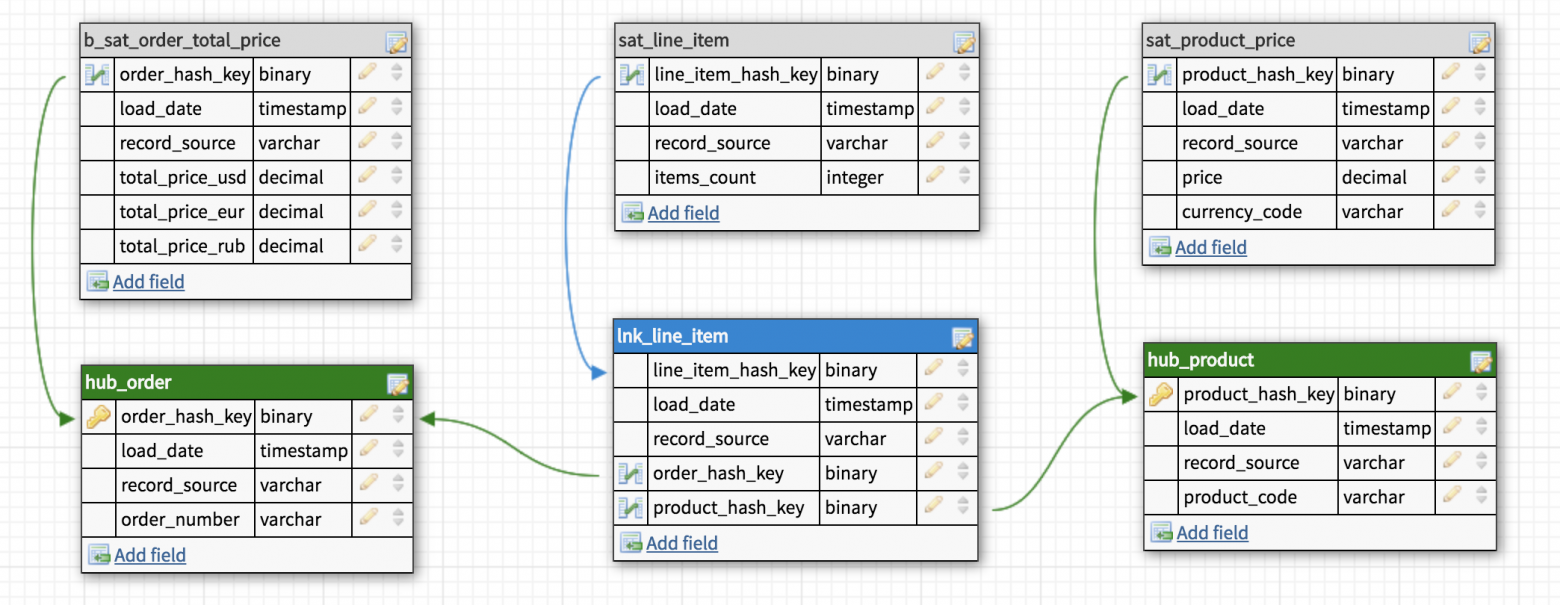
Когда нужные таблицы созданы и заполнены, наступает очередь витрин данных (Data Marts). Каждая витрина это отдельная база данных или схема, предназначенная для решения задач различных пользователей или отделов. В ней может быть специально собранная «звезда» или коллекция денормализованных таблиц. Если возможно, таблицы внутри витрин лучше делать виртуальными, то есть вычисляемыми «на лету». Для этого обычно используются SQL представления (SQL views).
Заполнение Data Vault
Здесь все довольно просто: сначала загружаются Хабы, потом Ссылки и затем Сателлиты. Хабы можно загружать параллельно, так же как и Сателлиты и Ссылки, если конечно не используется связь link-to-link.
Есть вариант и вовсе выключить проверку целостности и загружать все данные одновременно. Как раз такой подход соответствует одному из основных постулатов DV — «Загружать все доступные данные все время (Load all of the data, all of the time)» и именно здесь играют решающую роль бизнес ключи. Суть в том, что возможные проблемы при загрузке данных должны быть минимизированы, а одна из наиболее распространенных проблем это нарушение целостности. Подход, конечно, спорный, но лично я им пользуюсь и нахожу действительно удобным: данные все равно проверяются, но после загрузки. Часто можно столкнуться с проблемой отсутствия записей в нескольких Хабах при загрузке Ссылок и последовательно разбираться, почему тот или иной Хаб не заполнен до конца, перезапуская процесс и изучая новую ошибку. Альтернативный вариант — вывести недостающие данные уже после загрузки и увидеть все проблемы за один раз. Бонусом получаем устойчивость к ошибкам и возможность не следить за порядком загрузки таблиц.
Преимущества и недостатки
[+] Гибкость и расширяемость.
С Data Vault перестает быть проблемой как расширение структуры хранилища, так и добавление и сопоставление данных из новых источников. Максимально полное хранилище «сырых» данных и удобная структура их хранения позволяют нам сформировать витрину под любые требования бизнеса, а существующие решения на рынке СУБД хорошо справляются с огромными объемами информации и быстро выполняют даже очень сложные запросы, что дает возможность виртуализировать большинство витрин.
[+] Agile-подход из коробки.
Моделировать хранилище по методологии Data Vault довольно просто. Новые данные просто «подключаются» к существующей модели, не ломая и не модифицируя существующую структуру. При этом мы будем решать поставленную задачу максимально изолированно, загружая только необходимый минимум, и, вероятно, наша временнáя оценка для такой задачи станет точнее. Планирование спринтов будет проще, а результаты предсказуемы с первой же итерации.
[–] Обилие JOIN'ов
За счет большого количества операций join запросы могут быть медленнее, чем в традиционных хранилищах данных, где таблицы денормализованы.
[–] Сложность.
В описанной выше методологии есть множество важных деталей, разобраться в которых вряд ли получится за пару часов. К этому можно прибавить малое количество информации в интернете и почти полное отсутствие материалов на русском языке (надеюсь это исправить). Как следствие, при внедрении Data Vault возникают проблемы с обучением команды, появляется много вопросов относительно нюансов конкретного бизнеса. К счастью, существуют ресурсы, на которых можно задать эти вопросы. Большой недостаток сложности это обязательное требование к наличию витрин данных, так как сам по себе Data Vault плохо подходит для прямых запросов.
[–] Избыточность.
Довольно спорный недостаток, но я часто вижу вопросы об избыточности, поэтому прокомментирую этот момент со своей точки зрения.
Многим не нравится идея создания прослойки перед витринами данных, особенно если учесть, что таблиц в этой прослойке примерно в 3 раза больше, чем могло бы быть в третьей нормальной форме, а значит в 3 раза больше ETL-процессов. Это так, но и сами ETL процессы будут значительно проще за счет своего однообразия, а все объекты в хранилище достаточно просты для понимания.
Кажущаяся избыточной архитектура построена для решения вполне конкретных задач, и конечно не является серебряной пулей. В любом случае я бы не рекомендовал что-то менять до того момента, пока описанные выше преимущества Data Vault не станут востребованы.
В заключении
В этой статье я упомянул лишь основные компоненты Data Vault — минимум, необходимый для вводной статьи. За кадром остались Point in time и Bridge таблицы, особенности и правила выбора компонентов бизнес ключа и метод отслеживания удаленных записей. О них я планирую рассказать в следующей статье, если тема будет интересна сообществу.
