На переправе оркестратор не меняют.
После того как мне окончательно надоел Docker Swarm из-за своей псевдопростоты и постоянного допиливания, не очень удобной работой с распределенными файловыми системами, немного сыроватым web-интерфейсом и узкой функциональностью, а также отсутствие поддержки «из коробки» GitLab интеграции, было принято решение развернуть свой Kubernetes cluster на собственном железе, а именно, путем развертывания Rancher Management Server 2.0.
Опыт установки, схема отказоустойчивости, работа с haProxy и два dashboard под катом:
Входные данные:
Host Server HP Proliant DL320e Gen8 — 2 шт.
VM Ubuntu Server 16.04, 2Gb RAM, 2vCPU, 20Gb HDD — 1 шт. on each Host (VM-haProxy).
VM Ubuntu Server 16.04, 4Gb RAM, 4vCPU, 40Gb HDD, 20 Gb SSD — 3 шт. on each Host (VM-*-Cluster).
VM Ubuntu Server 16.04, 4Gb RAM, 4vCPU, 100Gb HDD — 1 шт. on anyone Host (VM-NFS).
Схема сети:
Приступаем:
VM-haProxy имеет на борту haProxy, fail2ban, правила iptables. Исполняет роль шлюза для всех машин за ним. У нас два шлюза и все машины в случае потери связи шлюза на своем хосте переключатся на другой.
Главная задача этих узлов (VM-haProxy) распределять доступ к backend, балансировать, пробрасывать порты, собирать статистику.
Мой выбор пал на haProxy, как более узко направленному инструменту относительно балансирования и health checking. При всем этом нравится синтаксис директив конфигураций и работа с белыми и черными списками IP, а также работа с мультидоменным SSL подключением.
Конфигурация haProxy:
Важно: Все машины должны «знать» друг друга по имени хоста.
VM-Master-Cluster — главная машина управления. Отлично от других нод имеет на борту Puppet Master, GlusterFS Server, Rancher Server (container), etcd (container), control manager (container). В случае отключения этого хоста, production сервисы продолжают работать.
VM-Node-Cluster — Ноды, воркеры. Рабочие машины, ресурсы которых будут объединены в одну отказоустойчивую среду. Ничего интересного.
VM-NFS — NFS сервер (nfs-kernel-server). Главная задача — это предоставление буфферного пространства. Хранит конфигурационные файлы и всякое. Не хранит ничего важного. Его падение можно исправлять не спеша, попивая кофе.
Важно: Все машины окружения должны иметь на борту: docker.io, nfs-common, gluster-server.
Монтирование nfs-volume и настройку GlusterFS описывать не буду, так как это щедро описано в большом количестве.
Если вы заметили, в описании спецификации, есть SSD диски, они заготовлены для работы распределенной файловой системы Gluster. Создайте разделы, и хранилища на высокоскоростных дисках.
Примечание. На самом деле, для запуска Rancher не требуется зеркально идентичной среды. Все вышеописанное — это мое видение кластера и описание того, каких практик придерживаюсь я.
Для запуска Rancher достаточно одной машины, с 4CPU, 4Gb RAM, 10Gb HDD.
5 минут до Rancher.
На VM-Master-Cluster выполняем:
Проверьте доступность:
Если вы увидели API — я Вас поздравляю ровно половина пути пройдена.
Взглянув на схему сети снова, мы вспомним что будем работать извне, через haProxy, в конфигурации у нас опубликована ссылка rancher.domain.ru, переходим, устанавливаем свой пароль.
Следующая страница — страница создания кластера Kubernetes.
В меню Cluster Options, выберите Flannel. С другими провайдерами сетей не работал. Советовать не могу.
Стоит обратить внимание на то, что мы установили чекбоксы etcd и Control Plane, чекбокс worker не установлен, в том случае, если вы не планируете использовать менеджер в режиме воркера.
Мы работаем внутри локальной сети, с одним адресом на NIC, поэтому в полях Public и Internal Address указали один и тот же IP.
Скопируйте получившийся код выше, запустите его в консоли.
Спустя некоторое время в web интерфейсе вы увидите сообщение о добавлении ноды. А еще через некоторое время у вас запустится кластер Kubernetes.
Чтобы добавить воркер, перейдите в редактирование кластера в web интерфейсе Rancher, увидите то же меню, которое генерирует команду подключения.
Установите чекбокс только в положение worker, укажите IP будущего воркера, скопируйте команду и выполните ее в консоли нужной вам ноды.
Через некоторое время мощность кластера увеличится, ровно как и количество нод.
Установка Kubernetes Dashboard:
Перейдите в меню Projects/Namespaces.
После установки вы увидите, что namespaces, относящиеся к Kubernetes, будут содержаться вне проектов. Чтобы полноценно работать с этими пространствами имен их необходимо поместить в проект.
Добавьте проект, назовите по своему усмотрению. Переместите namespaces (cattle-system, ingress-nginx, kube-public, kube-system) в созданный вами проект с помощью контекстного меню «Move». Должно получится так:
Щелкните прямо по имени проекта, вы попадете в панель управления workload. Именно здесь далее мы разберем, как создать простой сервис.
Нажмите «Import YAML» в правом верхнем углу. Скопируйте и вставьте содержимое этого файла в текстбокс открывшегося окна, выберите namespace «kube-system», нажмите «Import».
Через некоторое время запустится pod kubernetes-dashboard.
Перейдите в редактирование pod, раскройте меню публикации портов, установите следующие значения:
Проверьте доступ на ноде на которой запущен pod.
Увидели ответ? Публикация завершена, осталось достучаться до административной части.
На главной странице управления кластером в Rancher, есть очень удобные инструменты, такие как, kubectl — консоль управления кластером и Kubeconfig File — файл конфигурации, содержащий адрес API, ca.crt и т.д.
Заходим в kubectl и выполняем:
Мы создали сервис аккаунт с высшими привелегиями, теперь нам нужен токен для доступа в Dashboard.
Найдем секрет созданного аккаунта:
Увидим имя аккаунта с неким хэшем в конце, копируем его и выполняем:
Снова вспомним о том, что у нас все благополучно опубликовано через haProxy.
Переходим по ссылке kubernetes.domain.ru. Вводим полученный токен.
Радуемся:
P.S.
Общим итогом хотелось бы выразить благодарность Rancher за то, что создали интуитивно понятный интерфейс, легко развертываемый инстанс, простую документацию, возможность быстрого переезда и масштабируемость на уровне кластеров. Возможно, я слишком резко высказался в начале поста о том, что Swarm надоел, скорей очевидные тренды развития, своеобразно заставляли засматриваться на сторону и не доводить скучные рутинные дела до конца. Docker создал эпоху развития. И судить этот проект уж точно не мне.
После того как мне окончательно надоел Docker Swarm из-за своей псевдопростоты и постоянного допиливания, не очень удобной работой с распределенными файловыми системами, немного сыроватым web-интерфейсом и узкой функциональностью, а также отсутствие поддержки «из коробки» GitLab интеграции, было принято решение развернуть свой Kubernetes cluster на собственном железе, а именно, путем развертывания Rancher Management Server 2.0.
Опыт установки, схема отказоустойчивости, работа с haProxy и два dashboard под катом:
Входные данные:
Host Server HP Proliant DL320e Gen8 — 2 шт.
VM Ubuntu Server 16.04, 2Gb RAM, 2vCPU, 20Gb HDD — 1 шт. on each Host (VM-haProxy).
VM Ubuntu Server 16.04, 4Gb RAM, 4vCPU, 40Gb HDD, 20 Gb SSD — 3 шт. on each Host (VM-*-Cluster).
VM Ubuntu Server 16.04, 4Gb RAM, 4vCPU, 100Gb HDD — 1 шт. on anyone Host (VM-NFS).
Схема сети:
Рис.1
Приступаем:
VM-haProxy имеет на борту haProxy, fail2ban, правила iptables. Исполняет роль шлюза для всех машин за ним. У нас два шлюза и все машины в случае потери связи шлюза на своем хосте переключатся на другой.
Главная задача этих узлов (VM-haProxy) распределять доступ к backend, балансировать, пробрасывать порты, собирать статистику.
Мой выбор пал на haProxy, как более узко направленному инструменту относительно балансирования и health checking. При всем этом нравится синтаксис директив конфигураций и работа с белыми и черными списками IP, а также работа с мультидоменным SSL подключением.
Конфигурация haProxy:
haproxy.conf с комментариями
########################################################## #Global # ########################################################## global log 127.0.0.1 local0 notice maxconn 2000 user haproxy group haproxy tune.ssl.default-dh-param 2048 defaults log global mode http option httplog option dontlognull retries 3 option redispatch timeout connect 5000 timeout client 10000 timeout server 10000 option forwardfor option http-server-close ########################################################## #TCP # ########################################################## #Здесь мы пробрасываем порт API Сервера Kubernetes listen kube-api-tls bind *:6443 mode tcp option tcplog server VM-Master-Cluster Master:6443 ########################################################## #HTTP/HTTPS - Frontend and backend # ########################################################## #В текущем блоке конфигурации мы разделяем "белки от желтков", frontend от backend. frontend http-in bind *:80 acl network_allowed src -f /path/allowed-ip # Путь к белому списку IP. Применимо в любом блоке директивы. http-request deny if !network_allowed # Правило отклонения подключений в случае отсутствия IP в списке. reqadd X-Forwarded-Proto:\ http mode http option httpclose acl is_haproxy hdr_end(host) -i haproxy.domain.ru acl is_rancher hdr_end(host) -i rancher.domain.ru acl is_kubernetes hdr_end(host) -i kubernetes.domain.ru use_backend kubernetes if is_kubernetes use_backend rancher if is_rancher use_backend haproxy if is_haproxy frontend https-in bind *:443 ssl crt-list /path/crt-list # Путь к списком сертификатов. Отличный инструмент для работы с большим количеством сертификатов. acl network_allowed src -f /path/allowed-ip http-request deny if !network_allowed reqadd X-Forwarded-Proto:\ https acl is_rancher hdr_end(host) -i rancher.etraction.ru acl is_kubernetes hdr_end(host) -i kubernetes.etraction.ru use_backend kubernetes if is_kubernetes { ssl_fc_sni kubernetes.domain.ru } use_backend rancher if is_rancher { ssl_fc_sni rancher.domain.ru } # Backend статистики haProxy. Незаменимый инструмент мониторинга балансировщика. backend haproxy stats enable stats uri /haproxy?stats stats realm Strictly\ Private stats auth login:passwd cookie SERVERID insert nocache indirect # Ну и, собственно, backend для наших dashboard rancher и kubernetes. backend rancher acl network_allowed src -f /path/allowed-ip http-request deny if !network_allowed mode http redirect scheme https if !{ ssl_fc } server master master:443 check ssl verify none backend kubernetes acl network_allowed src -f /path/allowed-ip http-request deny if !network_allowed mode http balance leastconn redirect scheme https if !{ ssl_fc } server master master:9090 check ssl verify none
Важно: Все машины должны «знать» друг друга по имени хоста.
add-host-entry.pp puppet манифест для добавления имени хостов в /etc/hosts
class host_entries { host { 'proxy01': ip => '10.10.10.11', } host { 'proxy02': ip => '10.10.10.12', } host { 'master': ip => '10.10.10.100', } host { 'node01': ip => '10.10.10.101', } host { 'node02': ip => '10.10.10.102', } host { 'node03': ip => '10.10.10.103', } host { 'node04': ip => '10.10.10.104', } host { 'node05': ip => '10.10.10.105', } host { 'nfs': ip => '10.10.10.200', } }
VM-Master-Cluster — главная машина управления. Отлично от других нод имеет на борту Puppet Master, GlusterFS Server, Rancher Server (container), etcd (container), control manager (container). В случае отключения этого хоста, production сервисы продолжают работать.
VM-Node-Cluster — Ноды, воркеры. Рабочие машины, ресурсы которых будут объединены в одну отказоустойчивую среду. Ничего интересного.
VM-NFS — NFS сервер (nfs-kernel-server). Главная задача — это предоставление буфферного пространства. Хранит конфигурационные файлы и всякое. Не хранит ничего важного. Его падение можно исправлять не спеша, попивая кофе.
Важно: Все машины окружения должны иметь на борту: docker.io, nfs-common, gluster-server.
must-have-packages.pp puppet манифест для установки нужного ПО
class musthave { package { 'docker.io': ensure => 'installed', } package { 'nfs-common': ensure => 'installed', } package { 'gluster-server': ensure => 'installed', } }
Монтирование nfs-volume и настройку GlusterFS описывать не буду, так как это щедро описано в большом количестве.
Если вы заметили, в описании спецификации, есть SSD диски, они заготовлены для работы распределенной файловой системы Gluster. Создайте разделы, и хранилища на высокоскоростных дисках.
Примечание. На самом деле, для запуска Rancher не требуется зеркально идентичной среды. Все вышеописанное — это мое видение кластера и описание того, каких практик придерживаюсь я.
Для запуска Rancher достаточно одной машины, с 4CPU, 4Gb RAM, 10Gb HDD.
5 минут до Rancher.
На VM-Master-Cluster выполняем:
sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher
Проверьте доступность:
curl -k https://localhost
Если вы увидели API — я Вас поздравляю ровно половина пути пройдена.
Взглянув на схему сети снова, мы вспомним что будем работать извне, через haProxy, в конфигурации у нас опубликована ссылка rancher.domain.ru, переходим, устанавливаем свой пароль.
Следующая страница — страница создания кластера Kubernetes.
Рис.2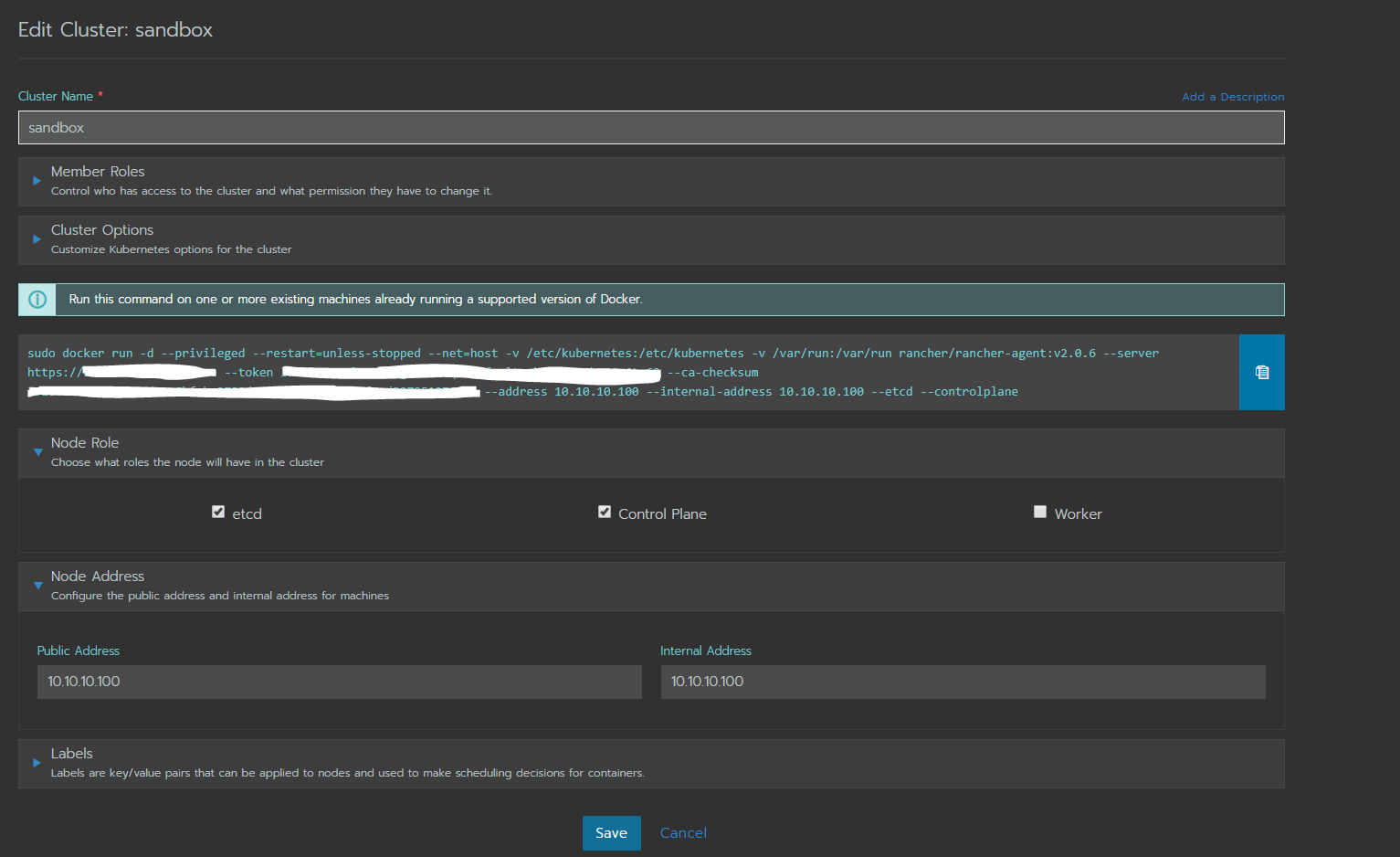
В меню Cluster Options, выберите Flannel. С другими провайдерами сетей не работал. Советовать не могу.
Стоит обратить внимание на то, что мы установили чекбоксы etcd и Control Plane, чекбокс worker не установлен, в том случае, если вы не планируете использовать менеджер в режиме воркера.
Мы работаем внутри локальной сети, с одним адресом на NIC, поэтому в полях Public и Internal Address указали один и тот же IP.
Скопируйте получившийся код выше, запустите его в консоли.
Спустя некоторое время в web интерфейсе вы увидите сообщение о добавлении ноды. А еще через некоторое время у вас запустится кластер Kubernetes.
Рис.3
Чтобы добавить воркер, перейдите в редактирование кластера в web интерфейсе Rancher, увидите то же меню, которое генерирует команду подключения.
Установите чекбокс только в положение worker, укажите IP будущего воркера, скопируйте команду и выполните ее в консоли нужной вам ноды.
Через некоторое время мощность кластера увеличится, ровно как и количество нод.
Установка Kubernetes Dashboard:
Перейдите в меню Projects/Namespaces.
После установки вы увидите, что namespaces, относящиеся к Kubernetes, будут содержаться вне проектов. Чтобы полноценно работать с этими пространствами имен их необходимо поместить в проект.
Добавьте проект, назовите по своему усмотрению. Переместите namespaces (cattle-system, ingress-nginx, kube-public, kube-system) в созданный вами проект с помощью контекстного меню «Move». Должно получится так:
Рис.4
Щелкните прямо по имени проекта, вы попадете в панель управления workload. Именно здесь далее мы разберем, как создать простой сервис.
Рис.5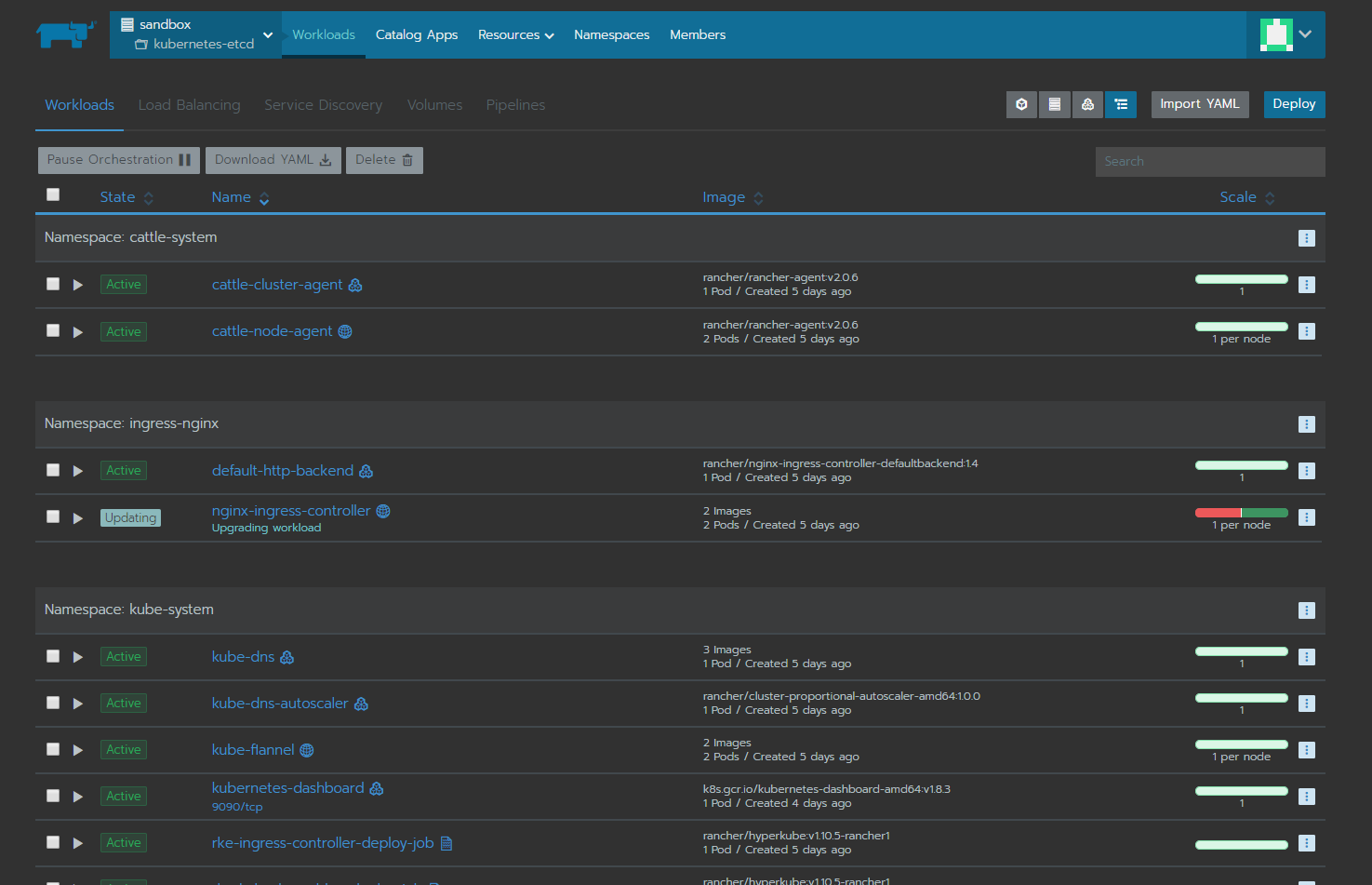
Нажмите «Import YAML» в правом верхнем углу. Скопируйте и вставьте содержимое этого файла в текстбокс открывшегося окна, выберите namespace «kube-system», нажмите «Import».
Через некоторое время запустится pod kubernetes-dashboard.
Перейдите в редактирование pod, раскройте меню публикации портов, установите следующие значения:
Рис.6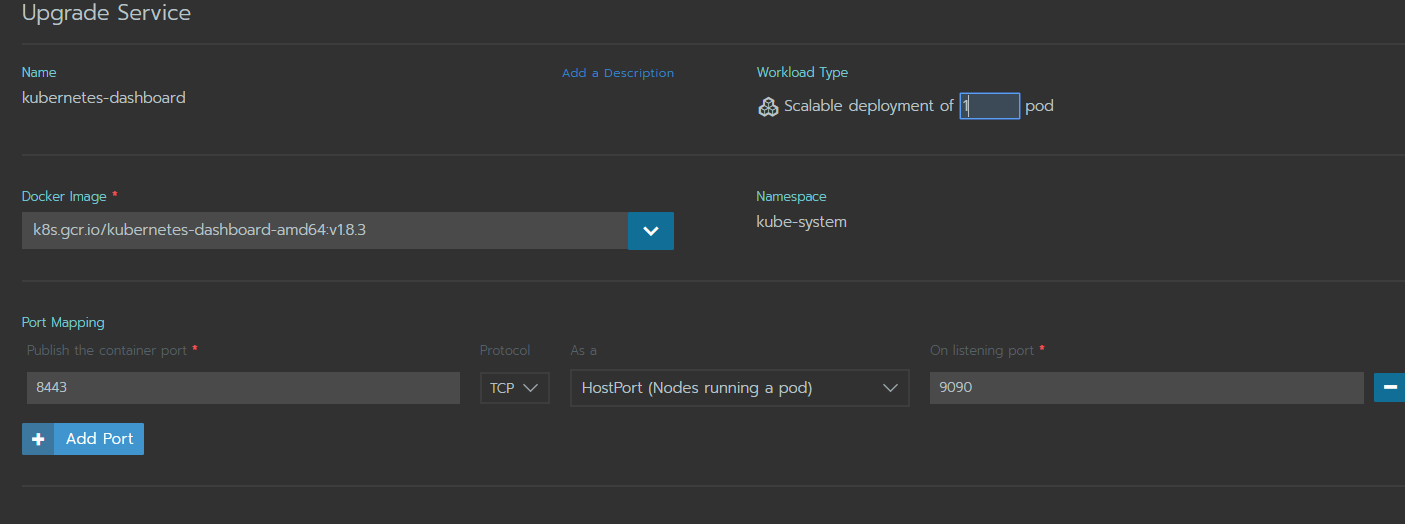
Проверьте доступ на ноде на которой запущен pod.
curl -k https://master:9090
Увидели ответ? Публикация завершена, осталось достучаться до административной части.
На главной странице управления кластером в Rancher, есть очень удобные инструменты, такие как, kubectl — консоль управления кластером и Kubeconfig File — файл конфигурации, содержащий адрес API, ca.crt и т.д.
Заходим в kubectl и выполняем:
kubectl create serviceaccount cluster-admin-dashboard-sa kubectl create clusterrolebinding cluster-admin-dashboard-sa --clusterrole=cluster-admin --serviceaccount=default:cluster-admin-dashboard-sa
Мы создали сервис аккаунт с высшими привелегиями, теперь нам нужен токен для доступа в Dashboard.
Найдем секрет созданного аккаунта:
kubectl get secret | grep cluster-admin-dashboard-sa
Увидим имя аккаунта с неким хэшем в конце, копируем его и выполняем:
kubectl describe secret cluster-admin-dashboard-sa-$(некий хэш)
Снова вспомним о том, что у нас все благополучно опубликовано через haProxy.
Переходим по ссылке kubernetes.domain.ru. Вводим полученный токен.
Радуемся:
Рис.7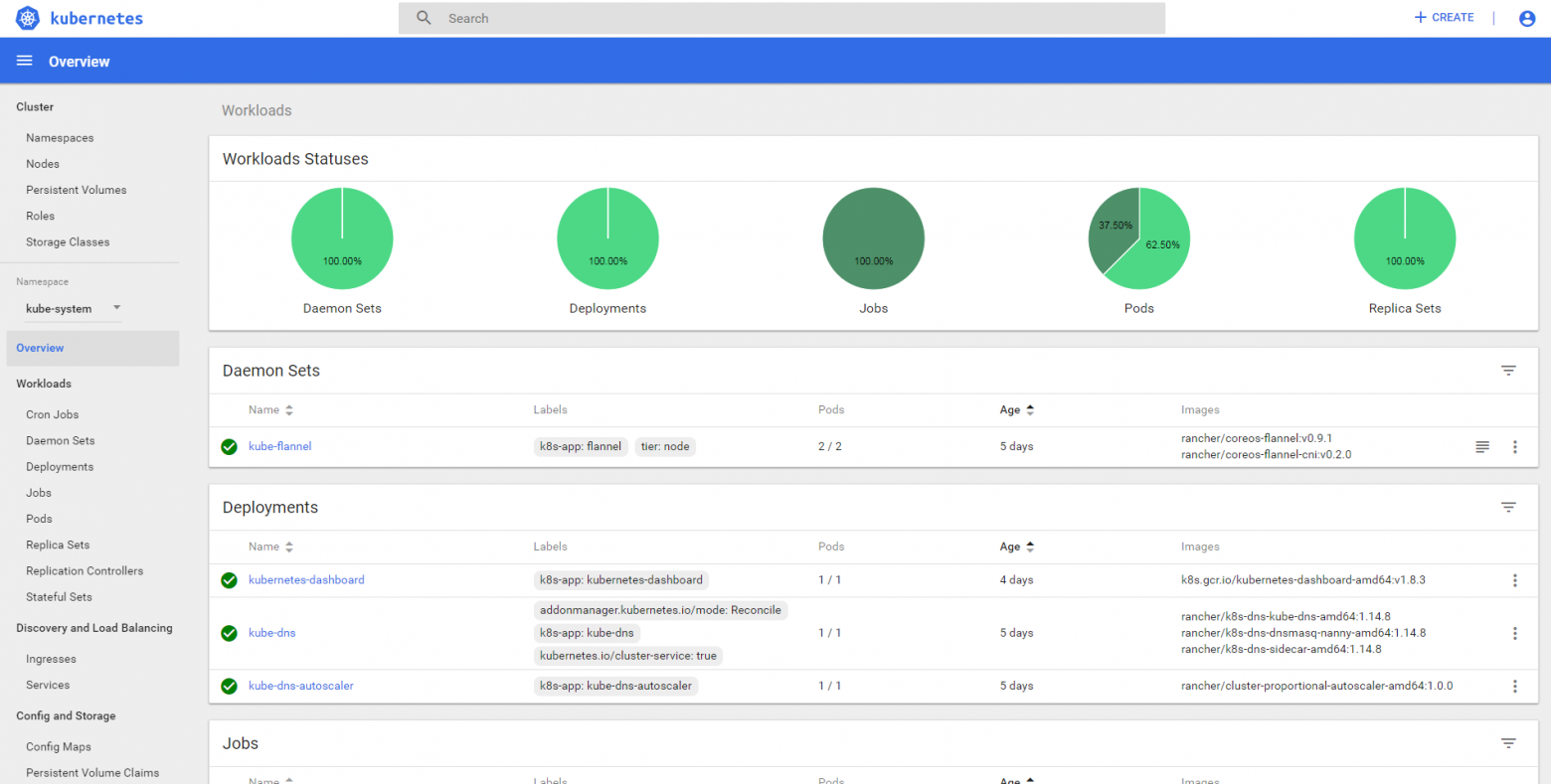
P.S.
Общим итогом хотелось бы выразить благодарность Rancher за то, что создали интуитивно понятный интерфейс, легко развертываемый инстанс, простую документацию, возможность быстрого переезда и масштабируемость на уровне кластеров. Возможно, я слишком резко высказался в начале поста о том, что Swarm надоел, скорей очевидные тренды развития, своеобразно заставляли засматриваться на сторону и не доводить скучные рутинные дела до конца. Docker создал эпоху развития. И судить этот проект уж точно не мне.

