Представляем вашему вниманию технику создания ассемблерных программ с перекрываемыми инструкциями, – для защиты скомпилированного байт-кода от дизассемблирования. Эта техника способна противостоять как статическому, так и динамическому анализу байт-кода. Идея состоит в том, чтобы подобрать такой поток байтов, при дизассимблировании которого начиная с двух разных смещений – получались две разные цепочки инструкций, то есть два разных пути выполнения программы. Мы для этого берём многобайтовые ассемблерные инструкции, и прячем защищаемый код в изменяемых частях байт-кода этих инструкций. С целью обмануть дизассемблер, пустив его по ложному следу (по маскирующей цепочке инструкций), и уберечь от его взора скрытую цепочку инструкций.
Три необходимых условия для создания эффективного «перекрытия»
Для того чтобы обмануть дизассемблер, перекрываемый код должен удовлетворять следующим трём условиям: 1) Инструкции из маскирующей цепочки и скрытой цепочки, – всегда должны пересекаться друг с другом, т.е. не должны быть выровнены друг относительно друга (их первые и последние байты не должны совпадать). В противном случае часть скрытого кода будет видна в маскирующей цепочке. 2) Обе цепочки должны состоять из правдоподобных ассемблерных инструкций. В противном случае маскировка будет обнаружена уже на этапе статического анализа (наткнувшись на непригодный для выполнения код, дизассемблер скорректирует указатель команд и разоблачит маскировку). 3) Все инструкции обеих цепочек должны быть не только правдоподобными, но ещё и корректно выполнимыми (чтобы не случилось так, то при попытке их выполнения программа обрушилась). В противном случае, в ходе динамического анализа сбойные места привлекут к себе пристальное внимание реверсера, и маскировка будет раскрыта.
Описание техники «перекрытия» ассемблерных инструкций
Для того чтобы процесс создания перекрываемого кода был как можно более гибким, необходимо выбирать только такие многобайтовые инструкции, у которых как можно больше байтов могут принимать произвольное значение. Эти многобайтовые инструкции будут составлять маскирующую цепочку инструкций.
Преследуя цель создания перекрываемого кода, который будет удовлетворять трём вышеперечисленным условиям, мы рассматриваем каждую маскирующую инструкцию, как последовательность байтов вида: XX YY ZZ.
Здесь XX – это префикс инструкции (код инструкции и другие статичные байты, – которые не могут быть изменены).
YY – это байты, которые можно менять произвольным образом (как правило, эти байты хранят непосредственное числовое значение, передаваемое в инструкцию; или адрес хранимого в памяти операнда). Байтов YY должно быть как можно больше, – чтобы в них побольше скрытых инструкций влезло.
ZZ – это тоже байты, которые можно менять произвольным образом, с той лишь разницей, что комбинация байтов ZZ со следующими за ними байтами XX (ZZ XX) – должна образовывать действующую инструкцию, которая удовлетворяет трём условиям, сформулированным в начале статьи. В идеале, ZZ должна занимать только один байт, – чтобы на YY (это по сути самая важная часть – здесь наш скрытый код и размещается) оставалось как можно больше байтов. Последняя скрытая инструкция должна заканчиваться на ZZ, – создавая точку схождения для двух цепочек выполнения.
Склеивающие инструкции
Комбинацию ZZ XX – мы будем называть склеивающей инструкцией. Склеивающая инструкция нужна, во-первых, для стыковки скрытых инструкций, которые располагаются в соседних маскирующих инструкциях и, во-вторых, для выполнения первого необходимого условия, озвученного в начале статьи: инструкции обеих цепочек всегда должны пересекаться друг с другом (поэтому склеивающая инструкция всегда находится на пересечении двух маскирующих инструкций).
Склеивающая инструкция выполняется в скрытой цепочке команд, и поэтому должна быть подобрана таким образом, чтобы как можно меньше ограничений на скрытый код накладывать. Допустим, если при её выполнении меняются регистры общего назначения и регистр EFLAGS, то скрытый код не сможет эффективно использовать соответствующие регистры и условные команды (например, если перед склеивающей инструкцией стоит оператор сравнения, а сама склеивающая инструкция меняет значение регистра EFLAGS, то условный переход, который стоит после склеивающей инструкции – будет срабатывать неправильно).
Приведённое описание техники перекрытия проиллюстрировано на следующем рисунке. Если выполнение начинается с начальных байтов (XX), то активируется маскирующая цепочка инструкций. А если с байтов YY – активируется скрытая цепочка инструкций.

Ассемблерные инструкции, подходящие на роль «маскирующих инструкций»
Самая длинная из инструкций, которая на первый взгляд подходит нам лучше всего, это 10-байтовый вариант MOV’а, где в качестве первого операнда передаётся смещение, заданное регистром и 32-битным адресом, а в качестве второго операнда – 32-битное число. В этой инструкции больше всего байтов, которые можно менять произвольным образом (целых 8 штук).

Однако, хотя эта инструкция выглядит правдоподобно (теоретически, она может быть выполнена корректно), она всё же нам не подходит, потому что первый её операнд, как правило, будет указывать на недоступный адрес, и поэтому при попытке выполнения такого MOV’а, программа обрушится. Т.о. этот 10-байтовый MOV не удовлетворяет третьему необходимому условию: все инструкции обеих цепочек должны быть корректно выполнимы.
Поэтому мы будем выбирать на роль маскирующих инструкций только таких претендентов, которые не создают риска обрушения программы. Данное условие существенно сужает круг инструкций, пригодных для создания перекрываемого кода, однако подходящие всё же имеются. Ниже представлены четыре из них. В каждой из четырёх этих инструкций есть по пять байтов, которые можно менять произвольным образом, без риска обрушения программы.
- LEA. Эта инструкция вычисляет адрес памяти, заданный выражением во втором операнде, и сохраняет результат в первом операнде. Поскольку мы можем ссылаться на память без фактического к ней доступа (и соответственно без риска обрушения программы), – последние пять байтов этой инструкции могут принимать произвольные значения.

- CMOVcc. Эта инструкция осуществляет операцию MOV, если выполнено условие «сс». Чтобы эта инструкция удовлетворяла третьему требованию, условие должно быть подобрано таким образом, чтобы при любых обстоятельствах оно имело значение FALSE. В противном случае эта инструкция может попытаться обратиться к недоступному адресу памяти, и т.о. обрушить программу.

- SETcc. Действует по тому же принципу, что и CMOVcc: устанавливает байт в единицу, если выполнено условие «cc». У этой инструкции та же проблема, что и у CMOVcc: обращение к недопустимому адресу приведёт к обрушению программы. Поэтому к выбору условия «cc» необходимо подходить очень осмотрительно.

- NOP. NOP’ы могут быть разной длины (от 2 до 15 байт), в зависимости от того, какие операнды в них указываются. При этом риска обрушить программу (из-за обращения к недопустимому адресу памяти) не будет. Потому что единственное, что делают NOP’ы – это увеличение счётчика команд, (над операндами они никаких операций не производят). Поэтому байты NOP’а, в которых задаются операнды, могут принимать произвольное значение. Для наших целей лучше всего подходит 9-байтовый NOP.

Для справки, вот несколько других вариантов NOP’а.
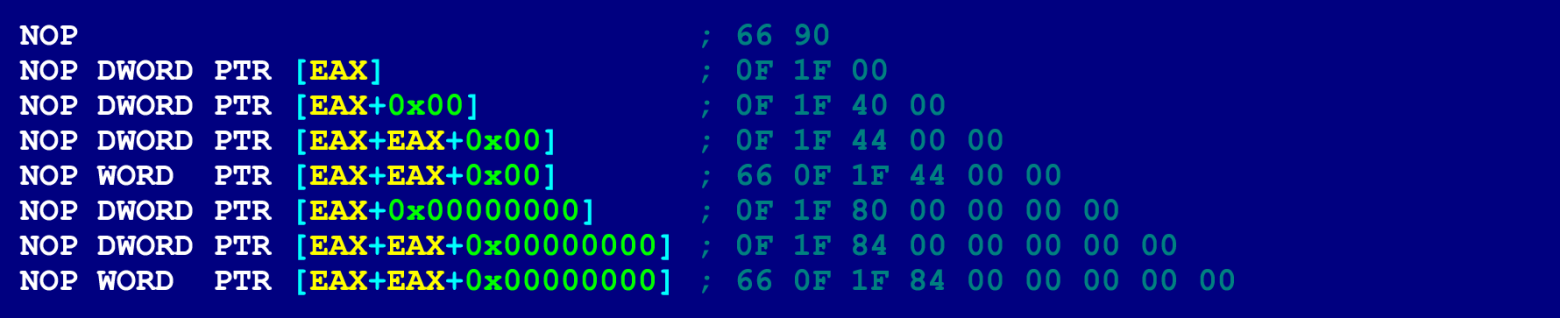
Ассемблерные инструкции, подходящие на роль «склеивающих инструкций»
Список инструкций, подходящих на роль склеивающей инструкции, уникален для каждой конкретной маскирующей инструкции. Ниже представлен список (сгенерированный по алгоритму, представленному на нижеследующем рисунке) на примере 9-байтового NOP’а.

Формируя этот список, мы учитывали только те варианты, при которых ZZ занимает 1 байт (иначе на скрытый код мало места останется). Вот список подходящих склеивающих инструкций, для 9-байтового NOP’а.
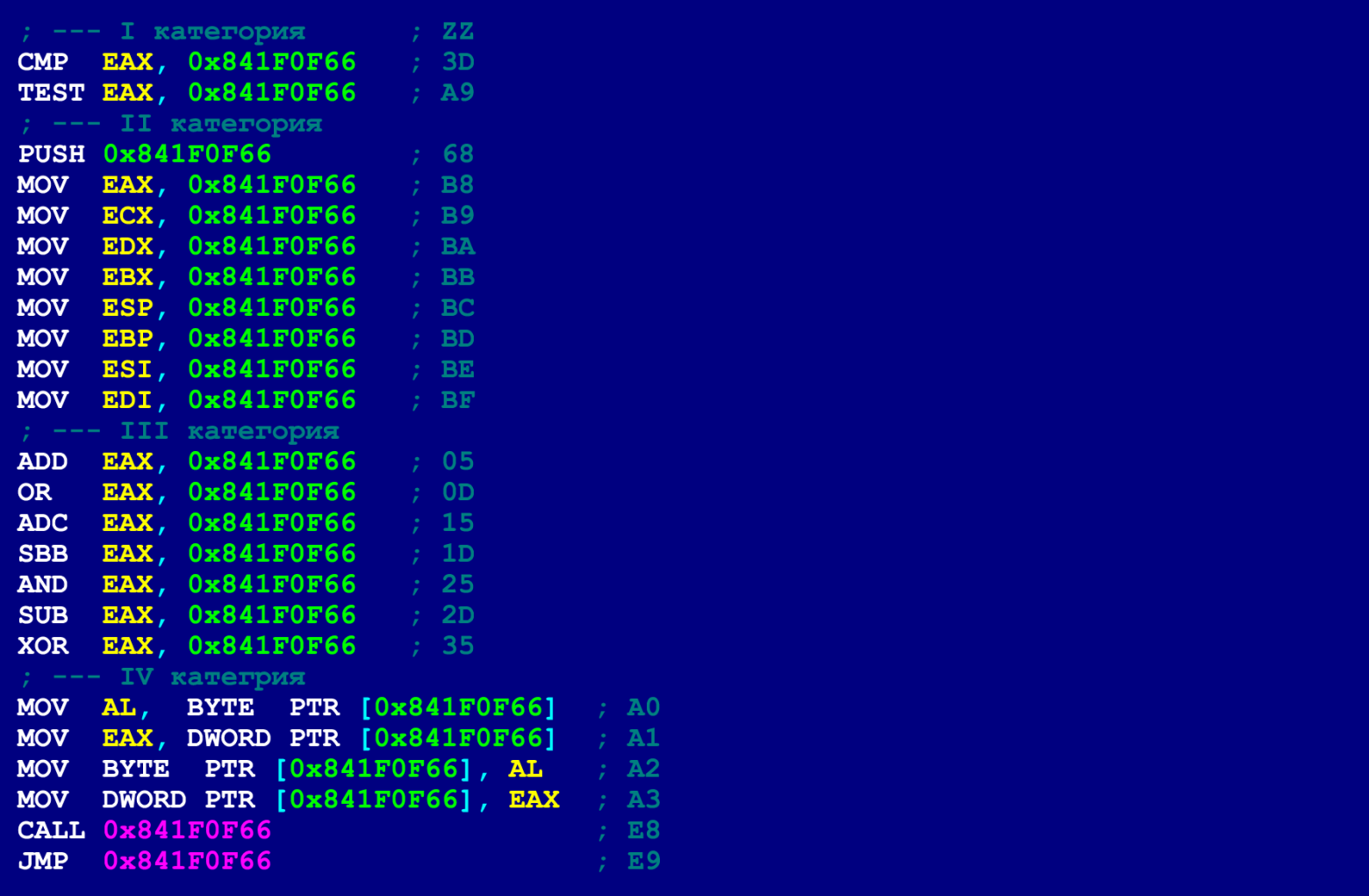
Среди этого списка инструкций нет ни одной, которая была бы свободна от побочных действий. Каждая из них меняет либо EFLAGS, либо регистры общего назначения, либо и то и другое сразу. Этот список разделён на 4 категории, – в соответствии с тем, какое побочное действие оказывает инструкция.
В первую категорию включены инструкции, которые изменяют регистр EFLAGS, но при этом не меняют регистры общего назначения. Инструкциями из этой категории можно пользоваться, когда в цепочке скрытых инструкций нет условных переходов и каких-либо инструкций, действие которых основано на оценке информации из регистра EFLAGS. К этой категории в данном случае (для 9-байтового NOP’а) относятся только две инструкции: TEST и CMP.

Ниже представлен простой пример скрытого кода, который в качестве инструкции склеивания использует TEST. Этот пример осуществляет системный вызов exit, который для любых версий ОС Linux возвращает значение 1. Чтобы для наших нужд правильно сформировать инструкцию TEST, мы должны будем установить последнему байту первого NOP’а – значение 0xA9. Этот байт, при сцепке с первыми четырьмя байтами следующего NOP’а (66 0F 1F 84), превратится в инструкцию TEST EAX, 0x841F0F66. На следующих двух рисунках представлен соответствующий ассемблерный код (для маскирующей цепочки и скрытой цепочки). Скрытая цепочка активируется, когда управление передаётся на 4-й байт первого NOP’а.


Во вторую категорию входят инструкции, которые меняют значения регистров общего назначения или доступную память (стек, например), но при этом не изменяют регистр EFLAGS. При выполнении инструкции PUSH или любого варианта MOV, где в качестве второго операнда задано непосредственное значение, – регистр EFLAGS остаётся неизменным. Т.о. склеивающие инструкции второй категории можно помещать даже между инструкцией сравнения (TEST, например) и инструкцией, оценивающей регистр EFLAGS. Однако инструкции этой категории ограничивают возможности пользования регистром, который фигурирует в соответствующей склеивающей инструкции. Например, если в качестве склеивающей инструкции используется MOV EBP, 0x841F0F66, – то возможности пользования регистром EBP (из остальной части скрытого кода) значительно ограничиваются.
В третью категорию входят инструкции, которые и регистр EFLAGS изменяют, и регистры общено назначения (либо память) изменяют. У этих инструкций нет явных преимуществ, по сравнению с инструкциями из первых двух категорий. Однако их тоже можно использовать, – поскольку они не входят в противоречие с тремя условиями, сформулированными в начале статьи. В четвёртую категорию входят инструкции, при выполнении которых нет гарантии, что программа не обрушится, – есть риск неправомерного обращения к памяти. Ими пользоваться крайне нежелательно, т.к. они не удовлетворяют третьему условию.
Ассемблерные инструкции, которые можно использовать в скрытой цепочке
В нашем случае (когда в качестве маскирующих инструкций используются 9-байтовые NOP’ы), длина каждой инструкции из скрытой цепочки, – не должна превышать четырёх байтов (это ограничение не относится к склеивающим инструкциям, которые занимают 5 байтов). Однако это не очень критичное ограничение, потому что большинство инструкций, у которых длина больше четырёх байт, – могут быть разложены на несколько более коротких инструкций. Ниже приведён пример 5-байтового MOV’а, который слишком велик для помещения в скрытую цепочку.
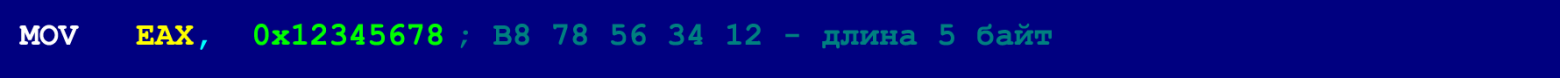
Однако, этот пятибайтовый MOV может быть разложен на три инструкции, длина которых не превышает четырёх байтов.

Усиление маскировки путём рассеивания маскирующих NOP’ов по всей программе
Большое количество подряд идущих NOP’ов выглядит, с точки зрения реверсера, весьма подозрительно. Заострив свой интерес на этих подозрительных NOP’ах, опытный реверсер может докопаться до скрытого в них кода. Чтобы избежать такого разоблачения, можно рассеять маскирующие NOP’ы – по всей программе.
Корректная цепочка выполнения скрытого кода в таком случае может поддерживаться посредством двухбайтовых инструкций безусловного перехода. В этом случае два последних байта каждого NOP’а будет занимать 2-байтовый JMP.
Такой трюк позволяет разбить одну длинную последовательность NOP’ов на несколько коротких (или вообще по одному NOP’у использовать). В последнем NOP’е такой короткой последовательности можно размещать только 3 байта полезной нагрузи (4-й байт заберёт инструкция безусловного перехода). Т.о. здесь возникает дополнительное ограничение на размер допустимых инструкций. Однако, как уже упоминалось выше, длинные инструкции можно раскладывать на цепочку более коротких инструкций. Ниже представлен пример всё того же 5-байтового MOV’а, который мы уже раскладывали, чтобы уложиться в лимит 4 байта. Однако теперь мы этот MOV разложим так, чтобы уложиться в лимит 3 байта.
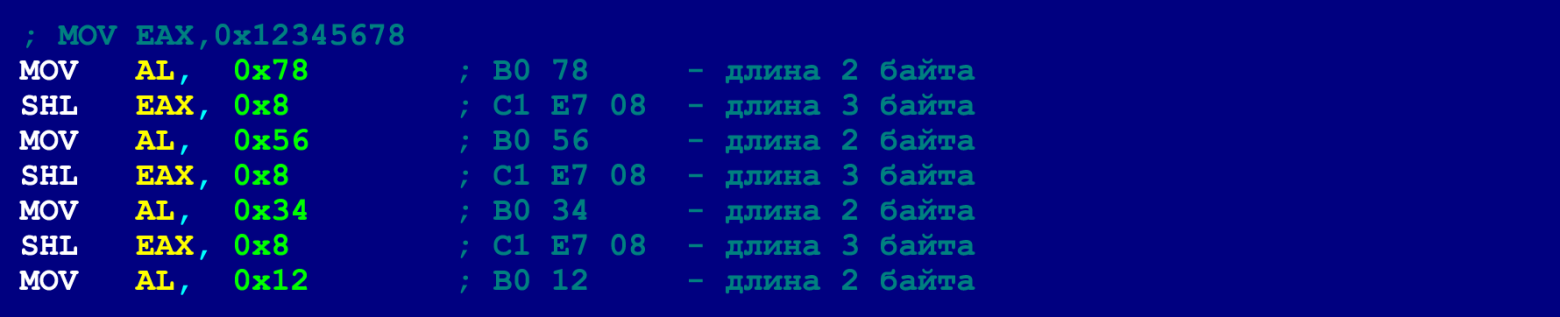
Разложив по такому же принципу все длинные инструкции на более короткие, мы можем, в целях большей маскировки, – вообще только одиночными NOP’ами, разбросанными по всей программе, пользоваться. Двухбайтовые инструкции JMP могут прыгать вперёд и назад на 127 байтов, что означает, что два последовательно идущих NOP’а (последовательных, с точки зрения цепочки скрытых инструкций), должны находиться в пределах 127 байтов.
У такого трюка, есть ещё одно значительное преимущество (помимо усиленной маскировки): с его помощью можно размещать скрытый код в уже существующих NOP’ах скомпилированного бинарного файла (т.е. вставлять в бинарник полезную нагрузку уже после его компиляции). При этом, не обязательно, чтобы эти бесхозные NOP’ы были 9-байтовыми. Например, если в бинарнике идут несколько однобайтовых NOP’ов подряд, то их можно преобразовать в многобайтовые NOP’ы, без нарушения функциональности программы. Ниже представлен пример техники рассеивания NOP’ов (этот код функционально эквивалентен примеру, рассмотренному чуть выше).
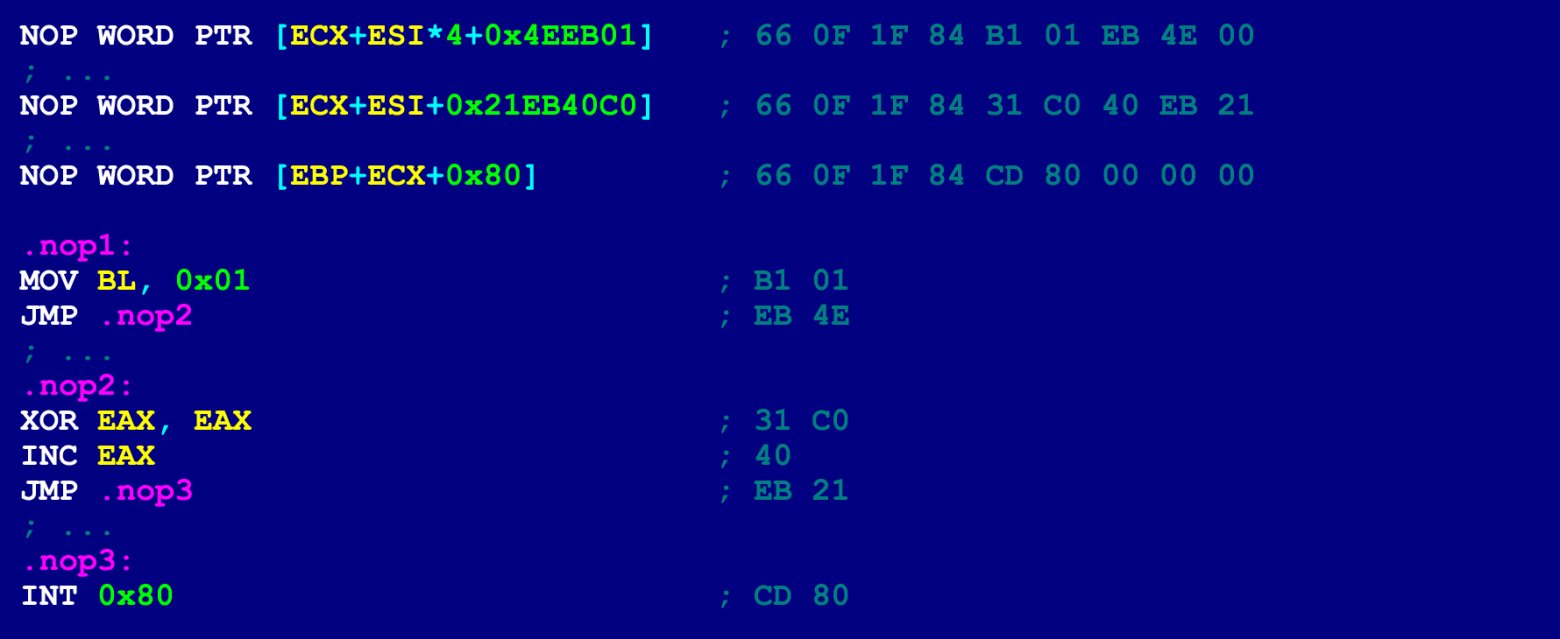
Такой скрытый код, спрятанный в разбросанных по всей программе NOP’ах, обнаружить уже гораздо сложнее.
Внимательный читатель наверняка заметил, что у первого NOP’а последний байт не востребован. Однако в этом нет ничего страшного. Потому что этому невостребованному байту предшествует безусловный переход. Т.о. управление на него никогда не будет передано. Так что всё в порядке.
Вот такая техника создания перекрываемого кода. Пользуйтесь на здоровье. Прячьте свой драгоценный код от посторонних глаз. Но только берите на вооружение какую-нибудь другую инструкцию, а не 9-байтовый NOP. Потому что реверсеры эту статью наверняка тоже прочитают.

