M. Bacchiani, F. Beaufays, J. Schalkwyk, M. Schuster, B. Strope
АННОТАЦИЯ
Мы описываем наш первый опыт разработки и оптимизации GOOG-411, полностью автоматизированного бизнес-поиска при помощи голоса. Мы показываем, каким образом принятие итеративного подхода к разработке системы позволяет оптимизировать различные компоненты системы, таким образом постепенно улучшая показатели, с которыми взаимодействуют пользователи. Мы показываем, вклад различных источников данных в точность распознавания. Для языковой модели, построенной на списке бизнес-объектов, мы видим почти линейное увеличение производительности с суммарным логарифмом тренировочных данных. На сегодняшний день, мы повысили показатель правильного распознавания на 25% и увеличили показатель успешных соединений на 35%.
1. ВВЕДЕНИЕ
GOOG-411 [1] является сервисом по поиску бизнес-объектов при помощи голоса. Пользователям предлагается назвать город и штат, а затем название конкретного бизнес-объекта или бизнес-категории (например, «компьютерные магазины»). Система распознавания речи преобразует голосовой пользовательский запрос в запрос, который подается в интернет-систему по поиску бизнес-объектов, Google Maps [2]. Google Maps возвращает отсортированный список предприятий. В зависимости от того, насколько точно это соответствует запросу пользователя, выдается от одного до восьми результатов запроса с помощью синтез речи (TTS). Пользователи могут выбрать определенный результат, соединиться по телефону с бизнесом-объектом или запросить SMS с информацией и картой. GOOG-411 в настоящее время работает только с английским языком и охватывает десятки тысяч городов по всей территории Соединенных Штатов.
Концепция голосового справочного сервиса 411 исследовалась в течение довольно многих лет (см. например, [3, 4, 5]), и было реализована в различных сервисах, включая 555 Tell [6], Live Search 411 [7] и Free 411 [8] в США. Как нам кажется, GOOG-411 был одной из первых реализованных служб 411, которая включала полный поиск по бизнес-объектам и категориям, и при обработке трудных запросов не происходило переключения на операторов. Наше основное допущение при таком выборе было в том, что, реализуя итерационный подход в обработке данных и соответствующих показателей, система будет автоматически улучшаться с течением времени. Наличие возможности переключения на оператора изменяет способ взаимодействия пользователя с системой. Чтобы избежать этого и сосредоточиться на конечном решении, мы решили не использовать операторов с самого начала. После краткого обзора системной архитектуры мы опишем процесс подготовки данных и измерения, которые мы проводим для улучшения GOOG-411. Затем мы более внимательно сосредоточимся на двух ключевых компонентах, акустических и языковых моделях, и завершим наше рассмотрение обзором высокоуровневых характеристик (UI) и их совершенствованием с течением времени.
2. СИСТЕМНАЯ АРХИТЕКТУРА
На рисунке 1 показаны основные компоненты системы GOOG-411. Они включают в себя телефонную сеть, сервер приложений, который запускает голосовые приложения, TTS-сервер, сервер распознавания с акустическими, языковыми и фонетическим моделями (AM, LM, PM), сервис Google Maps для выполнения бизнес-запросов, и SMS-канал для передачи информации мобильным пользователям. Каждый из этих компонентов содержит свою собственную резервную копию и возможность балансировки нагрузки, потому что эта диалоговая система, многие из процессов которой асинхронны, в целом является достаточно сложным структурным образованием. Мы используем инфраструктуру Google (machine grid, GFS [9], Bigtable [10]) для резервирования, автоматического распределения; а также реализацию процессов несколькими сетями (multi-homed implementation) в целях обеспечения надежности и масштабируемости сервиса. Текущие показатели используются для контроля за системой, и в реальном масштабе времени вновь поступающие данные позволяют нам контролировать их качество.
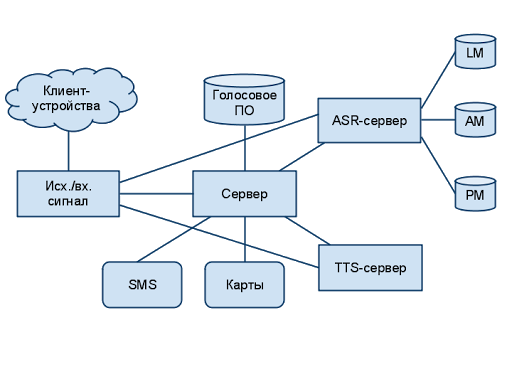
Рис. 1. Блок-схема GOOG-411
3. ПРОЦЕСС ПОДГОТОВКИ ДАННЫХ И ИЗМЕРЕНИЯ
Важным аспектом нашей системы является оптимизация данных. С этой целью мы создали обширную систему подготовки данных. Все входящие звонки анализируются для определения жизнеспособности системы (проверка на сбои компонентов и т.д.) и отслеживается их качество (например, того, какая часть звонков достигла конечной точки в диалоге). Эти данные затем сохраняются, расшифровываются и используются для дальнейшего анализа, а также для перегруппировки основных компонентов системы. Затем эти данные обновляются в функционирующей системе. В течении всего времени новые данные используются для тестирования, остальные данные сгруппированы для тренировочных сетов. Данный тестовый подход позволяет нам контролировать пользовательский интерфейс и изменения инфраструктуры, отслеживать меняющиеся модели использования, и избегать использования устаревших тестовых установок.
Для оценки точности распознавания нашим основным показателем являются кривые оперативного приема (receiving-operating curves, ROC), которые показывают соотношение правильно распознанных (correct-accept, CA) и ложно распознанных (false-accept, FA) сигналов. Они оцениваются на уровне предложения в семантической интерпретации результатов распознавания; например, распознавание «гм, итальянский ресторан» вместо «Итальянский ресторан» считается корректным распознаванием (при условии, что коэффициент уверенности превосходит некоторый предопределенный порог, иначе гипотеза была бы исключена).
На системном уровне мы измеряем показатель успешных соединений (transfer rate), т.е. долю звонков, при которых пользователи соединяются с предприятиями или получают SMS с деталями результата запроса. Несколько упрощая, можно сказать, что этот показатель является в первом приближении верным показателем удовлетворения пользователей. Как показано в главе 6, он отражает изменения пользовательского интерфейса, улучшение инфраструктуры и возрастающей точности.
Наконец, на уровне продукта мы отслеживаем изменение трафика, что является еще одним свидетельством успешности работы этого сервиса. В следующих двух разделах мы рассмотрим более подробно наши эксперименты в области акустики и языкового моделирования. При представлении результатов здесь и в главе 6 мы сознательно избегаем показателей абсолютных значений, указывая вместо них лишь относительные. Отчасти из-за конкурентных причин, отчасти потому, что абсолютные цифры легко становятся ошибочными вне контекста. Например, абсолютные числа зависят от того, сохраняем мы или устраняем из тестовых сетов предложения, которые содержат непонятную речь или молчание, и насколько они часты. Они также зависят от того, включен ли в подсчет итоговый (back-end) поиск. Показатель успешных соединений (transfer rate) зависит от того, включаем ли мы в статистику звонки, когда пользователь повесил трубку прежде, чем что-либо сказать. Мы надеемся, что относительные показатели тем не менее окажутся информативными для научного сообщества.
Эксперименты, описанные ниже, отражают показатели нашего существующего сервиса, которым интересующиеся читатели могут воспользоваться по телефону 1-800-GOOG-411 (1-800-466-4411). В общем, служба получила позитивные отзывы пользователей, демонстрируя высокую точность распознавания речи (уровень точности распознавания в диапазоне 50-80%), что делает ее полезной для пользователей и сопоставимой с коммерческими системами.
4. АКУСТИЧЕСКИЕ МОДЕЛИ
Система распознавания речи – это стандартный recognizer, работающий на большом словаре, с PLP и LDA свойствами, на основе GMM triphone HMMs, моделями деревьев, STC [11] и на основе FST-поиска [12]. Чтобы натренировать систему необходимо совершит максимально возможную оптимизацию, осуществляемую во фреймворке mapreduce [13], что позволяет нам получать готовые модели в течение нескольких часов, даже при наличии больших объемов данных, в настоящее время на нескольких сотнях машин. Акустические модели, сравниваемые в данном разделе, не зависят от пола, одноцикличны и тренированы исключительно на образцах речи сервиса GOOG-411.

Рис. 2. Показатель эффективности в зависимости от количества тренировочных акустических данных.
Рисунок 2 показывает относительную эффективность ряда моделей, тренируемых на увеличивающемся объеме данных. Тест состоит приблизительно из 20,000 недавно собранных высказываний, в ответ на вопрос «Скажите называние компании или категорию?» (“What business name or category?”), охватывающих более, чем 3,000 городов. Структура акустических и языковых моделей постоянно проходят через ряд экспериментов. Тренировочные сеты сгруппированы так, чтобы мы могли представить результаты всех тренировочных материалов, которые собрали в первом полугодии, в первом квартале, в первом месяце и т.д. Наиболее обширные тренировочные сеты содержат выборку из тысяч часов речи.
Интересно отметить, что качество распознавания не увеличивается резко с количеством тренировочных данных (8% корректных распознаваний [CA] на 10% ложных распознаваний [FA] при коэффициенте роста тренировочных данных 64). Одной из причин может быть то, что тренировочные данные качественно подготовлены для тренировочных сетов как фонетически, так и акустически (одни и те же пользователи своими запросами могут участвовать как в тренировке системы, так и в ее тестировании, конечно разными звонками, но, вероятно, на одном и том же устройстве, а иногда и совершая один и тот же запрос). Другая причина может просто состоять в том, что мы еще недостаточно изучили этот факт.
5. ЯЗЫКОВЫЕ МОДЕЛИ
Языковые модели – это комбинация n-грамных статистических лингвистических моделей (SLM) и внеконтекстных (context-free) грамматик. Они обучаются на трех источниках данных, что облегчает оптимизацию ROC’ов при обработке наборов данных.
Итак, во-первых, мы имеем данные по бизнес-объектам и местоположению: они обеспечивают необходимое покрытие покрытие, но официальные наименования компаний не всегда совпадают с теми, какими их именуют люди, например, «Google» вм. «Google Inc.» или «Starbucks» вм. «Starbucks coffee».
Во-вторых, мы имеет логи web-запросов к сервису Google Maps: это обширный корпус печатных запросов, которые лучше всего подходят для сервиса GOOG-411 (пользователи уже научились тому, что можно вводить «Google» или «Starbucks» для получения нужных ответов). Данные о запросах используются для определения вероятности LM, однако их приоритетность на Google Maps и GOOG-411 не всегда совпадают: например, «real estate» [«недвижимость»] является частым web-запросом, но редким голосовым запросом.
В-третьих, мы имеем речевую базу: транскрибированная речь, собранная благодаря обращениям в службу GOOG-411, оказывается наиболее подходящим видом данных. Во всех приведенных ниже экспериментах языковые модели сокращены, дабы приблизиться к распознаванию в реальном времени и ограничить время ожидания всей системы.
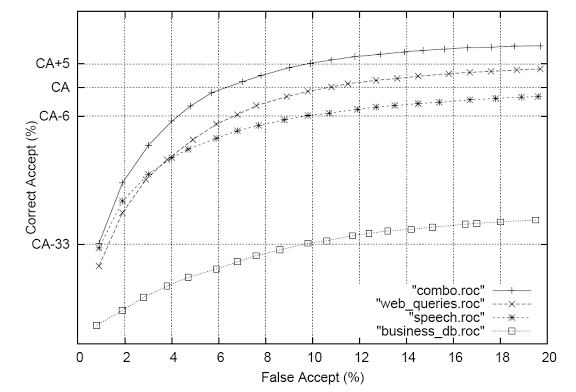
Рис. 3. Показатели эффективности в зависимости от типа данных LM.
Рисунок 3 показывает эффективность работы системы в зависимости от типа данных LM. В настоящее время данные web-журнала демонстрируют, что наилучшими языковыми моделями являются те, которые построены на речевой базе, в процентном соотношении 6% корректных распознаваний на 10% неверных распознаваний между 2-мя LM. Показатели по данным бизнес-объектов гораздо хуже. Объединение 3-х источников данных (combo) дает дополнительно 5% корректных распознаваний (поверх web LM).
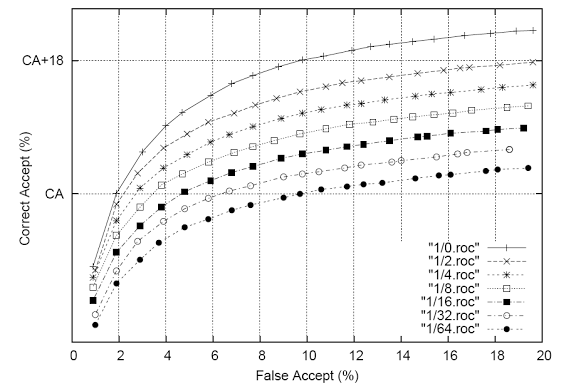
Рис. 4. Показатели эффективности LM, построенные на речевых данных, как функция суммы LM тренировочных данных.
Рисунок 4 показывает эффективность LM по бизнес-объектам, полученную только на речевых данных, как функцию от объема речевых данных. Здесь снова показатели тренировочных данных отличаются на 2 пункта. Так как соответствующие ROC’и расположены примерно одинаково, по логу тренировочных данных мы можем заключить, что точность LM растет линейно. По этому показателю вклад речевых данных будет соответствовать вкладу (текущих) web-запросов, только когда мы соберем в 4 раза больше речевых данных (даже при том, что это все еще будет на порядок меньше, чем объем web-данных).

Рис. 5. Показатели эффективности, как функция от типа и количества LM тренировочных данных.
Рисунок 5 показывает эффективность работы диалога «askCityState», в зависимости от типа (web, речь, комбинированный) и размера речевой LM тренировочных данных. Будучи простой задачей, askCityState возрастает менее линейно. Здесь речевые данные выступают так же, как web-данные, которые были значительно обработаны, чтобы отделить города и штаты от запросов, со множеством показателей (полные уличные адреса и т.д.). Без такой обработки web-данные показали очень большое отклонение показателей. Сочетание речевых и (обработанных) web-данных обеспечивает наилучшее качество распознавания. Базы данных по объектам и местоположению не представили каких-либо дополнительных преимуществ.
6. ОБЩИЕ НАПРАВЛЕНИЯ УСОВЕРШЕНСТВОВАНИЯ
Данный раздел дает общий взгляд на эволюцию GOOG-411 во времени. Многие факторы влияют на структуру использования данной услуги, это и изменение статистических моделей, изменения пользовательского интерфейса, изменения внутренней структуры сервиса, исправление ошибок, а также внешние события, такие как праздники, например.
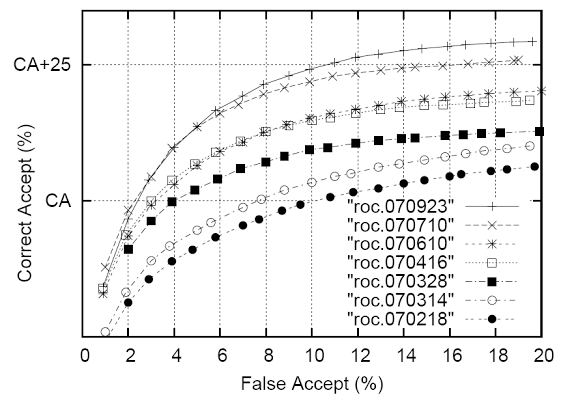
Рис. 6. Показатели эффективности за все время.
Рисунок 6 показывает функцию распознавания во времени. Каждый ROC собирался на различных тестовых сетах (см. концепцию тестирования, описанную в разделе 3). Эти числа показывают, что при норме в 10% корректных распознаваний за прошлые 7 месяцев мы улучшили ее примерно на 25%.
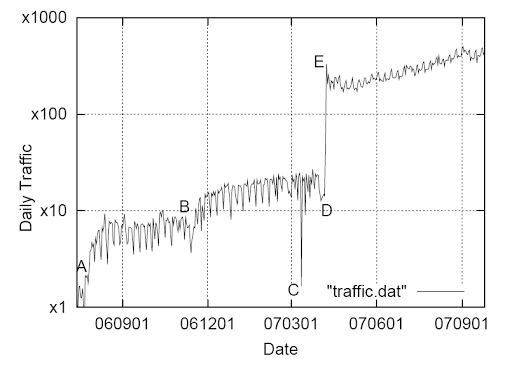
Рис. 7. Дневной трафик как временная функция
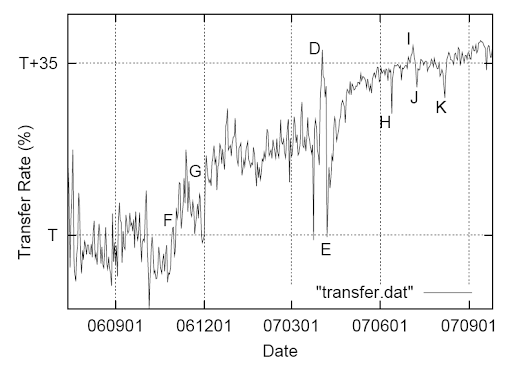
Рис. 8. Показатель успешных соединений в зависимости от времени.
Рисунки 7 и 8 показывают число входящих вызовов в день, а также ежедневный показатель успешных соединений в течение одного года. Здесь отражены несколько интересных моментов. Точки A и B на графике показывают рост трафика в момент увеличения нашей рекламной кампании. Точка C – временный перерыв в работе системы. Точка Е на обоих графиках отмечает официальный старт сервиса GOOG-411 большим увеличением объема трафика, а также большое падение показателя успешных соединений: пользователи экспериментируют с системой и не стремятся дозвониться до компаний. Точке D соответствует спокойный период до официального запуска: мы остановили рекламу сервиса (снижение показателей звонков), поэтому абонентами были в основном пользователи, которые по назначению обращались в данную службу (пик показателя успешных соединений).
Точка F на графике успешных соединений отмечает начало эксперимента с пользовательским интерфейсом, где мы сократили результаты выдачи пользователям. Это провоцирует людей дозваниваться до компаний чаще. Точка G отмечает распространение сервиса на все штаты Америки. Точка H показывает интересную ошибку, когда части звонивших были предоставлены неверные результаты значительного числа запросов. Это отразилось падением показателя успешных соединений. Точки J и K показывают сбои инфраструктуры телефонии, с чем также связано падение показателя успешных соединений. Точка I это 4 июля [День независимости], день, когда пользователи, вероятно, были более заинтересованы в соединении с бизнес-объектами для совершения покупок.
Мы могли бы проанализировать кривые более подробно. Но очевидно, что ни трафик, ни показатели соединений не расскажут нам все о пользователях, несмотря на то, что они отражают удивительно широкий аспект событий и оказываются весьма полезными для контроля за работой и развитием системы. Существует немало помех в кривых, которые являются результатом целого ряда трудно определяемых факторов. Это осложняет on-line эксперименты. Конечно возможно небольшое изменение пользовательского интерфейса, однако не ясно его воздействие на показатель успешных соединений, хотя, бесспорно, оно появится в конечном итоге. Для этого мы должны рассчитывать на нахождение более дробных показателей, и в конечном итоге поверить, что мы все делаем к лучшему, так же, как мы верим, когда оптимизируем модели распознавания.
7. ЗАКЛЮЧЕНИЕ
Итак, мы применили итерационный подход для создания, применения и развития довольно сложной системы, основанной на голосовых запросах. Мы показали как, фокусируясь на данных, измерениях, а также постоянном совершенствовании системы, мы можем быстро улучшить низкоуровневые показатели, такие как точность распознавания речи так же, как высокоуровневые характеристики, связанные с пользователями. Вообще, мы нашли, что наличие доступа ко всему стеку продукта с возможностью гибко изменять его по желанию, а также наличие устойчивого потока увеличивающихся данных являются ключевыми факторами в нашей способности последовательно улучшать обслуживание в течение долгого времени.
8. ССЫЛКИ
[1] “GOOG-411” http://www.google.com/goog411.
[2] “Google Maps” http://maps.google.com.
[3] L. Boves et al., “ASR for automatic directory assistance: The SMADA project” in Proc. ASR, 2000, pp. 249–254.
[4] N. Gupta et al., “The AT&T spoken language understanding system” in IEEE Trans. ASLP, 2006, pp. 213–222.
[5] D. Yu et al., “Automated directory assistance — from theory to practice” Proc. Interspeech, 2007.
[6] “555 Tell” http://www.tellme.com/products/TellmeByVoice.
[7] “Live search 411” http://www.livesearch411.com.
[8] “Free 411” http://www.free411.com.
[9] S. Ghemawat et al., “The google file system” in Proc. SIGOPS, 2003, pp. 20–43.
[10] F. Chang et al., “Bigtable: A distributed storage system for structured data” in Proc. OSDI, 2006, pp. 205–218.
[11] M.J.F. Gales “Semi-tied covariance matrices for hidden markov models” Proc. IEEE Trans. SAP, May 2000.
[12] “OpenFst Library” http://www.openfst.org.
[13] J. Dean et al., “Mapreduce: Simplified data processing on large clusters,” in Proc. OSDI, 2004, pp. 137–150.
Пожалуй, для полноты картину дам ссылку на видео, в котором Bill Byrne рассказывает про голосовую линейку сервисов Google.
АННОТАЦИЯ
Мы описываем наш первый опыт разработки и оптимизации GOOG-411, полностью автоматизированного бизнес-поиска при помощи голоса. Мы показываем, каким образом принятие итеративного подхода к разработке системы позволяет оптимизировать различные компоненты системы, таким образом постепенно улучшая показатели, с которыми взаимодействуют пользователи. Мы показываем, вклад различных источников данных в точность распознавания. Для языковой модели, построенной на списке бизнес-объектов, мы видим почти линейное увеличение производительности с суммарным логарифмом тренировочных данных. На сегодняшний день, мы повысили показатель правильного распознавания на 25% и увеличили показатель успешных соединений на 35%.
1. ВВЕДЕНИЕ
GOOG-411 [1] является сервисом по поиску бизнес-объектов при помощи голоса. Пользователям предлагается назвать город и штат, а затем название конкретного бизнес-объекта или бизнес-категории (например, «компьютерные магазины»). Система распознавания речи преобразует голосовой пользовательский запрос в запрос, который подается в интернет-систему по поиску бизнес-объектов, Google Maps [2]. Google Maps возвращает отсортированный список предприятий. В зависимости от того, насколько точно это соответствует запросу пользователя, выдается от одного до восьми результатов запроса с помощью синтез речи (TTS). Пользователи могут выбрать определенный результат, соединиться по телефону с бизнесом-объектом или запросить SMS с информацией и картой. GOOG-411 в настоящее время работает только с английским языком и охватывает десятки тысяч городов по всей территории Соединенных Штатов.
Концепция голосового справочного сервиса 411 исследовалась в течение довольно многих лет (см. например, [3, 4, 5]), и было реализована в различных сервисах, включая 555 Tell [6], Live Search 411 [7] и Free 411 [8] в США. Как нам кажется, GOOG-411 был одной из первых реализованных служб 411, которая включала полный поиск по бизнес-объектам и категориям, и при обработке трудных запросов не происходило переключения на операторов. Наше основное допущение при таком выборе было в том, что, реализуя итерационный подход в обработке данных и соответствующих показателей, система будет автоматически улучшаться с течением времени. Наличие возможности переключения на оператора изменяет способ взаимодействия пользователя с системой. Чтобы избежать этого и сосредоточиться на конечном решении, мы решили не использовать операторов с самого начала. После краткого обзора системной архитектуры мы опишем процесс подготовки данных и измерения, которые мы проводим для улучшения GOOG-411. Затем мы более внимательно сосредоточимся на двух ключевых компонентах, акустических и языковых моделях, и завершим наше рассмотрение обзором высокоуровневых характеристик (UI) и их совершенствованием с течением времени.
2. СИСТЕМНАЯ АРХИТЕКТУРА
На рисунке 1 показаны основные компоненты системы GOOG-411. Они включают в себя телефонную сеть, сервер приложений, который запускает голосовые приложения, TTS-сервер, сервер распознавания с акустическими, языковыми и фонетическим моделями (AM, LM, PM), сервис Google Maps для выполнения бизнес-запросов, и SMS-канал для передачи информации мобильным пользователям. Каждый из этих компонентов содержит свою собственную резервную копию и возможность балансировки нагрузки, потому что эта диалоговая система, многие из процессов которой асинхронны, в целом является достаточно сложным структурным образованием. Мы используем инфраструктуру Google (machine grid, GFS [9], Bigtable [10]) для резервирования, автоматического распределения; а также реализацию процессов несколькими сетями (multi-homed implementation) в целях обеспечения надежности и масштабируемости сервиса. Текущие показатели используются для контроля за системой, и в реальном масштабе времени вновь поступающие данные позволяют нам контролировать их качество.
Рис. 1. Блок-схема GOOG-411
3. ПРОЦЕСС ПОДГОТОВКИ ДАННЫХ И ИЗМЕРЕНИЯ
Важным аспектом нашей системы является оптимизация данных. С этой целью мы создали обширную систему подготовки данных. Все входящие звонки анализируются для определения жизнеспособности системы (проверка на сбои компонентов и т.д.) и отслеживается их качество (например, того, какая часть звонков достигла конечной точки в диалоге). Эти данные затем сохраняются, расшифровываются и используются для дальнейшего анализа, а также для перегруппировки основных компонентов системы. Затем эти данные обновляются в функционирующей системе. В течении всего времени новые данные используются для тестирования, остальные данные сгруппированы для тренировочных сетов. Данный тестовый подход позволяет нам контролировать пользовательский интерфейс и изменения инфраструктуры, отслеживать меняющиеся модели использования, и избегать использования устаревших тестовых установок.
Для оценки точности распознавания нашим основным показателем являются кривые оперативного приема (receiving-operating curves, ROC), которые показывают соотношение правильно распознанных (correct-accept, CA) и ложно распознанных (false-accept, FA) сигналов. Они оцениваются на уровне предложения в семантической интерпретации результатов распознавания; например, распознавание «гм, итальянский ресторан» вместо «Итальянский ресторан» считается корректным распознаванием (при условии, что коэффициент уверенности превосходит некоторый предопределенный порог, иначе гипотеза была бы исключена).
На системном уровне мы измеряем показатель успешных соединений (transfer rate), т.е. долю звонков, при которых пользователи соединяются с предприятиями или получают SMS с деталями результата запроса. Несколько упрощая, можно сказать, что этот показатель является в первом приближении верным показателем удовлетворения пользователей. Как показано в главе 6, он отражает изменения пользовательского интерфейса, улучшение инфраструктуры и возрастающей точности.
Наконец, на уровне продукта мы отслеживаем изменение трафика, что является еще одним свидетельством успешности работы этого сервиса. В следующих двух разделах мы рассмотрим более подробно наши эксперименты в области акустики и языкового моделирования. При представлении результатов здесь и в главе 6 мы сознательно избегаем показателей абсолютных значений, указывая вместо них лишь относительные. Отчасти из-за конкурентных причин, отчасти потому, что абсолютные цифры легко становятся ошибочными вне контекста. Например, абсолютные числа зависят от того, сохраняем мы или устраняем из тестовых сетов предложения, которые содержат непонятную речь или молчание, и насколько они часты. Они также зависят от того, включен ли в подсчет итоговый (back-end) поиск. Показатель успешных соединений (transfer rate) зависит от того, включаем ли мы в статистику звонки, когда пользователь повесил трубку прежде, чем что-либо сказать. Мы надеемся, что относительные показатели тем не менее окажутся информативными для научного сообщества.
Эксперименты, описанные ниже, отражают показатели нашего существующего сервиса, которым интересующиеся читатели могут воспользоваться по телефону 1-800-GOOG-411 (1-800-466-4411). В общем, служба получила позитивные отзывы пользователей, демонстрируя высокую точность распознавания речи (уровень точности распознавания в диапазоне 50-80%), что делает ее полезной для пользователей и сопоставимой с коммерческими системами.
4. АКУСТИЧЕСКИЕ МОДЕЛИ
Система распознавания речи – это стандартный recognizer, работающий на большом словаре, с PLP и LDA свойствами, на основе GMM triphone HMMs, моделями деревьев, STC [11] и на основе FST-поиска [12]. Чтобы натренировать систему необходимо совершит максимально возможную оптимизацию, осуществляемую во фреймворке mapreduce [13], что позволяет нам получать готовые модели в течение нескольких часов, даже при наличии больших объемов данных, в настоящее время на нескольких сотнях машин. Акустические модели, сравниваемые в данном разделе, не зависят от пола, одноцикличны и тренированы исключительно на образцах речи сервиса GOOG-411.
Рис. 2. Показатель эффективности в зависимости от количества тренировочных акустических данных.
Рисунок 2 показывает относительную эффективность ряда моделей, тренируемых на увеличивающемся объеме данных. Тест состоит приблизительно из 20,000 недавно собранных высказываний, в ответ на вопрос «Скажите называние компании или категорию?» (“What business name or category?”), охватывающих более, чем 3,000 городов. Структура акустических и языковых моделей постоянно проходят через ряд экспериментов. Тренировочные сеты сгруппированы так, чтобы мы могли представить результаты всех тренировочных материалов, которые собрали в первом полугодии, в первом квартале, в первом месяце и т.д. Наиболее обширные тренировочные сеты содержат выборку из тысяч часов речи.
Интересно отметить, что качество распознавания не увеличивается резко с количеством тренировочных данных (8% корректных распознаваний [CA] на 10% ложных распознаваний [FA] при коэффициенте роста тренировочных данных 64). Одной из причин может быть то, что тренировочные данные качественно подготовлены для тренировочных сетов как фонетически, так и акустически (одни и те же пользователи своими запросами могут участвовать как в тренировке системы, так и в ее тестировании, конечно разными звонками, но, вероятно, на одном и том же устройстве, а иногда и совершая один и тот же запрос). Другая причина может просто состоять в том, что мы еще недостаточно изучили этот факт.
5. ЯЗЫКОВЫЕ МОДЕЛИ
Языковые модели – это комбинация n-грамных статистических лингвистических моделей (SLM) и внеконтекстных (context-free) грамматик. Они обучаются на трех источниках данных, что облегчает оптимизацию ROC’ов при обработке наборов данных.
Итак, во-первых, мы имеем данные по бизнес-объектам и местоположению: они обеспечивают необходимое покрытие покрытие, но официальные наименования компаний не всегда совпадают с теми, какими их именуют люди, например, «Google» вм. «Google Inc.» или «Starbucks» вм. «Starbucks coffee».
Во-вторых, мы имеет логи web-запросов к сервису Google Maps: это обширный корпус печатных запросов, которые лучше всего подходят для сервиса GOOG-411 (пользователи уже научились тому, что можно вводить «Google» или «Starbucks» для получения нужных ответов). Данные о запросах используются для определения вероятности LM, однако их приоритетность на Google Maps и GOOG-411 не всегда совпадают: например, «real estate» [«недвижимость»] является частым web-запросом, но редким голосовым запросом.
В-третьих, мы имеем речевую базу: транскрибированная речь, собранная благодаря обращениям в службу GOOG-411, оказывается наиболее подходящим видом данных. Во всех приведенных ниже экспериментах языковые модели сокращены, дабы приблизиться к распознаванию в реальном времени и ограничить время ожидания всей системы.
Рис. 3. Показатели эффективности в зависимости от типа данных LM.
Рисунок 3 показывает эффективность работы системы в зависимости от типа данных LM. В настоящее время данные web-журнала демонстрируют, что наилучшими языковыми моделями являются те, которые построены на речевой базе, в процентном соотношении 6% корректных распознаваний на 10% неверных распознаваний между 2-мя LM. Показатели по данным бизнес-объектов гораздо хуже. Объединение 3-х источников данных (combo) дает дополнительно 5% корректных распознаваний (поверх web LM).
Рис. 4. Показатели эффективности LM, построенные на речевых данных, как функция суммы LM тренировочных данных.
Рисунок 4 показывает эффективность LM по бизнес-объектам, полученную только на речевых данных, как функцию от объема речевых данных. Здесь снова показатели тренировочных данных отличаются на 2 пункта. Так как соответствующие ROC’и расположены примерно одинаково, по логу тренировочных данных мы можем заключить, что точность LM растет линейно. По этому показателю вклад речевых данных будет соответствовать вкладу (текущих) web-запросов, только когда мы соберем в 4 раза больше речевых данных (даже при том, что это все еще будет на порядок меньше, чем объем web-данных).
Рис. 5. Показатели эффективности, как функция от типа и количества LM тренировочных данных.
Рисунок 5 показывает эффективность работы диалога «askCityState», в зависимости от типа (web, речь, комбинированный) и размера речевой LM тренировочных данных. Будучи простой задачей, askCityState возрастает менее линейно. Здесь речевые данные выступают так же, как web-данные, которые были значительно обработаны, чтобы отделить города и штаты от запросов, со множеством показателей (полные уличные адреса и т.д.). Без такой обработки web-данные показали очень большое отклонение показателей. Сочетание речевых и (обработанных) web-данных обеспечивает наилучшее качество распознавания. Базы данных по объектам и местоположению не представили каких-либо дополнительных преимуществ.
6. ОБЩИЕ НАПРАВЛЕНИЯ УСОВЕРШЕНСТВОВАНИЯ
Данный раздел дает общий взгляд на эволюцию GOOG-411 во времени. Многие факторы влияют на структуру использования данной услуги, это и изменение статистических моделей, изменения пользовательского интерфейса, изменения внутренней структуры сервиса, исправление ошибок, а также внешние события, такие как праздники, например.
Рис. 6. Показатели эффективности за все время.
Рисунок 6 показывает функцию распознавания во времени. Каждый ROC собирался на различных тестовых сетах (см. концепцию тестирования, описанную в разделе 3). Эти числа показывают, что при норме в 10% корректных распознаваний за прошлые 7 месяцев мы улучшили ее примерно на 25%.
Рис. 7. Дневной трафик как временная функция
Рис. 8. Показатель успешных соединений в зависимости от времени.
Рисунки 7 и 8 показывают число входящих вызовов в день, а также ежедневный показатель успешных соединений в течение одного года. Здесь отражены несколько интересных моментов. Точки A и B на графике показывают рост трафика в момент увеличения нашей рекламной кампании. Точка C – временный перерыв в работе системы. Точка Е на обоих графиках отмечает официальный старт сервиса GOOG-411 большим увеличением объема трафика, а также большое падение показателя успешных соединений: пользователи экспериментируют с системой и не стремятся дозвониться до компаний. Точке D соответствует спокойный период до официального запуска: мы остановили рекламу сервиса (снижение показателей звонков), поэтому абонентами были в основном пользователи, которые по назначению обращались в данную службу (пик показателя успешных соединений).
Точка F на графике успешных соединений отмечает начало эксперимента с пользовательским интерфейсом, где мы сократили результаты выдачи пользователям. Это провоцирует людей дозваниваться до компаний чаще. Точка G отмечает распространение сервиса на все штаты Америки. Точка H показывает интересную ошибку, когда части звонивших были предоставлены неверные результаты значительного числа запросов. Это отразилось падением показателя успешных соединений. Точки J и K показывают сбои инфраструктуры телефонии, с чем также связано падение показателя успешных соединений. Точка I это 4 июля [День независимости], день, когда пользователи, вероятно, были более заинтересованы в соединении с бизнес-объектами для совершения покупок.
Мы могли бы проанализировать кривые более подробно. Но очевидно, что ни трафик, ни показатели соединений не расскажут нам все о пользователях, несмотря на то, что они отражают удивительно широкий аспект событий и оказываются весьма полезными для контроля за работой и развитием системы. Существует немало помех в кривых, которые являются результатом целого ряда трудно определяемых факторов. Это осложняет on-line эксперименты. Конечно возможно небольшое изменение пользовательского интерфейса, однако не ясно его воздействие на показатель успешных соединений, хотя, бесспорно, оно появится в конечном итоге. Для этого мы должны рассчитывать на нахождение более дробных показателей, и в конечном итоге поверить, что мы все делаем к лучшему, так же, как мы верим, когда оптимизируем модели распознавания.
7. ЗАКЛЮЧЕНИЕ
Итак, мы применили итерационный подход для создания, применения и развития довольно сложной системы, основанной на голосовых запросах. Мы показали как, фокусируясь на данных, измерениях, а также постоянном совершенствовании системы, мы можем быстро улучшить низкоуровневые показатели, такие как точность распознавания речи так же, как высокоуровневые характеристики, связанные с пользователями. Вообще, мы нашли, что наличие доступа ко всему стеку продукта с возможностью гибко изменять его по желанию, а также наличие устойчивого потока увеличивающихся данных являются ключевыми факторами в нашей способности последовательно улучшать обслуживание в течение долгого времени.
8. ССЫЛКИ
[1] “GOOG-411” http://www.google.com/goog411.
[2] “Google Maps” http://maps.google.com.
[3] L. Boves et al., “ASR for automatic directory assistance: The SMADA project” in Proc. ASR, 2000, pp. 249–254.
[4] N. Gupta et al., “The AT&T spoken language understanding system” in IEEE Trans. ASLP, 2006, pp. 213–222.
[5] D. Yu et al., “Automated directory assistance — from theory to practice” Proc. Interspeech, 2007.
[6] “555 Tell” http://www.tellme.com/products/TellmeByVoice.
[7] “Live search 411” http://www.livesearch411.com.
[8] “Free 411” http://www.free411.com.
[9] S. Ghemawat et al., “The google file system” in Proc. SIGOPS, 2003, pp. 20–43.
[10] F. Chang et al., “Bigtable: A distributed storage system for structured data” in Proc. OSDI, 2006, pp. 205–218.
[11] M.J.F. Gales “Semi-tied covariance matrices for hidden markov models” Proc. IEEE Trans. SAP, May 2000.
[12] “OpenFst Library” http://www.openfst.org.
[13] J. Dean et al., “Mapreduce: Simplified data processing on large clusters,” in Proc. OSDI, 2004, pp. 137–150.
Пожалуй, для полноты картину дам ссылку на видео, в котором Bill Byrne рассказывает про голосовую линейку сервисов Google.
