Создание кластера Kubernetes может казаться сложным процессом, который включает в себя множество настроек, но сложные вещи могут стать более понятными, когда их разложить на части. В этой статье мы демистифицируем процесс создания кластера Kubernetes, поднимая минимальный набор компонентов и настроек, необходимых для запуска Kubernetes кластера.
Введение
Прежде всего, важно иметь виртуальную машину (VM), на которой запущено Debian- или RHEL-основное дистрибутивы Linux. Для этого урока мы будем использовать Debian 11 VM, запущенную в виртуальной среде KVM. Сам дистрибутив Debian был слегка модифицирован моими личными так называемыми "dotfiles", которые обеспечат нам более приятный опыт использования командной строкой. Готовые Terraform конфиги, для разворачивания готовых виртуальных машин, также доступны по данной ссылке.

Предварительные требования
После настройки VM мы можем перейти к следующим шагам в создании кластера Kubernetes с использованием cri-o в качестве контейнерного рантайма. Во-первых, нам необходимо внести несколько необходимых изменений, чтобы пройти проверки при инициализации kubeadm init. Об этих пунктах чуть ниже.
В качестве первого шага мы должны следовать главной рекомендации при работе с программным обеспечением — проверка на наличие обновлений и установка последних пакетов:
sudo apt update
sudo apt upgradeКроме того, необходимо загрузить и установить несколько зависимостей:
sudo apt install software-properties-common apt-transport-https ca-certificates gnupg2 gpg sudo1. Отключение swap
В Linux, swap — это полезный способ расширения доступной оперативной памяти, когда физическая память исчерпана, позволяющий процессам продолжать работу. Однако при настройке узла для кластера Kubernetes обычно рекомендуется отключить swap по нескольким причинам.
Во-первых, для эффективной работы Kubernetes требуется значительное количество памяти, и любое снижение производительности из-за использования swap может повлиять на производительность всего кластера. Кроме того, Kubernetes предполагает, что на узле есть фиксированное количество доступной памяти, и если swap включен, это может вызвать путаницу и неожиданное поведение.
Кроме того, отключение swap может помочь предотвратить риск вызова так называемого "OOM killer". OOM killer — это процесс ядра Linux, который отвечает за завершение процессов, когда система исчерпывает свободную память. Хотя это и предназначено для защиты от сбоев системы, это может привести к непредсказуемому поведению при запуске рабочих нагрузок Kubernetes, так как OOM killer может завершить критические компоненты кластера.
Мы можем узнать, использует ли наша машина swap-память, используя команду htop:

В целом, хотя swap-память может быть полезным инструментом для расширения доступной памяти на машине Linux, при настройке узла для кластера Kubernetes обычно рекомендуется отключить его, чтобы обеспечить надежную и предсказуемую производительность. Мы можем сделать это, выполнив следующую команду:
swapoff -aЧтобы убедиться, что swap остается отключенным после запуска, нам необходимо закомментировать строку в файле /etc/fstab, который инициализирует swap-память при загрузке Linux:

В этом конкретном случае в качестве раздела swap использовался файл с именем swap.img, который мы можем удалить после этого с правами root:
sudo rm /swap.img Примечание: В современных дистрибутивах Linux часто используется swap-файл вместо отдельного раздела swap. Если ваша система настроена с отдельным разделом swap, важно учитывать это при настройке кластера Kubernetes и избегать настройки раздела swap при установке виртуальной машины.
Теперь вы можете перезагрузить машину, и swap должен быть отключен. Используйте htop еще раз, чтобы подтвердить это.
2. Включение модулей ядра Linux
Включение необходимых модулей ядра Linux — это важный шаг при настройке контейнерного запуска для кластера Kubernetes. Эти модули необходимы для обеспечения функциональности сетевого подключения и хранения данных в Kubernetes Pods, которые являются наименьшими и простейшими единицами в системе Kubernetes. Модули сетевого подключения позволяют Kubernetes обеспечивать сетевое соединение между различными Pods в кластере, а модули хранения — постоянное хранилище данных в Pods кластера.
Для включения этих модулей ядра обычно нужно изменить параметры ядра Linux и загрузить соответствующие модули ядра с помощью утилиты modprobe. Это обеспечивает доступность необходимой функциональности для кластера Kubernetes и позволяет Pods эффективно общаться и хранить данные. Включая эти модули, мы можем гарантировать, что наш кластер Kubernetes хорошо подготовлен к выполнению широкого спектра задач и может предоставить надежную и масштабируемую платформу для запуска контейнеризованных приложений.
Прежде чем продолжить, мы войдем под учетную запись root и выполним все нижеуказанные действия с привилегиями этого суперпользователя:
sudo su - rootВот два модуля ядра Linux, которые нам нужно включить:
br_netfilter — этот модуль необходим для включения прозрачного маскирования и облегчения передачи трафика Virtual Extensible LAN (VxLAN) для связи между Kubernetes Pods в кластере.
overlay — этот модуль обеспечивает необходимую поддержку на уровне ядра для правильной работы драйвера хранения overlay. По умолчанию модуль overlay может не быть включен в некоторых дистрибутивах Linux, и поэтому необходимо включить его вручную перед запуском Kubernetes.
Мы можем включить эти модули, выполнив команду modprobe вместе с флагом -v(подробный вывод), чтобы увидеть результат:
modprobe overlay -v
modprobe br_netfilter -vПосле этого мы должны получить следующий вывод:

Чтобы убедиться, что модули ядра загружаются после перезагрузки, мы также можем добавить их в файл /etc/modules:
echo "overlay" >> /etc/modules
echo "br_netfilter" >> /etc/modulesПосле включения модуля br_netfilter необходимо включить IP-пересылку в ядре Linux, чтобы обеспечить сетевое взаимодействие между подами и узлами. IP-пересылка позволяет ядру Linux маршрутизировать пакеты с одного сетевого интерфейса на другой. По умолчанию IP-пересылка отключена на большинстве дистрибутивов Linux из соображений безопасности, поскольку она позволяет использовать машину как маршрутизатор.
Однако в кластере Kubernetes нам нужно включить IP-пересылку, чтобы позволить подам общаться друг с другом, а также пересылать трафик наружу. Без IP-пересылки поды не смогут получить доступ к внешним ресурсам или взаимодействовать друг с другом, что приведет к неисправности кластера.
Для этого мы должны записать "1" в файл конфигурации с названием "ip_forward":
echo 1 > /proc/sys/net/ipv4/ip_forwardС этих необходимых шагов для настройки требований нашего кластера Kubernetes мы можем перейти к установке Kubelet — сердцу Kubernetes.
Установка Kubelet
Установка Kubelet, возможно, самый простой шаг, поскольку он очень хорошо описан в официальной документации Kubernetes. В основном, нам нужно выполнить следующие команды:
mkdir /etc/apt/keyrings
sudo curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
apt-get update
apt-get install -y kubelet kubeadm kubectl
apt-mark hold kubelet kubeadm kubectl Строка apt-mark hold kubelet kubeadm kubectl сообщает нашему менеджеру пакетов не обновлять эти компоненты, так как это необходимо делать вручную при обновлении кластера.
Запустите команду, скрестите пальцы и надеемся, что все сработает:

Теперь, когда мы установили kubelet, kubeadm и kubectl, мы можем продолжить установку среды выполнения контейнеров, которая будет запускать компоненты Kubernetes.
Установка нашей среды выполнения контейнеров
Kubernetes — это система оркестрации для контейнеризированных нагрузок. Он управляет развертыванием, масштабированием и работой контейнеризированных приложений на кластере узлов. Однако Kubernetes не запускает контейнеры напрямую. Вместо этого он полагается на среду выполнения контейнеров, которая отвечает за запуск, остановку и управление контейнерами. Среда выполнения контейнеров — это программное обеспечение, которое запускает контейнеры на узлах в кластере Kubernetes.
Существует несколько сред выполнения контейнеров, которые можно использовать с Kubernetes, включая Docker, cri-o, containerd и другие. Выбор среды выполнения контейнеров зависит от таких факторов, как производительность, безопасность и совместимость с другими инструментами в инфраструктуре. Для наших целей мы выберем cri-o в качестве среды выполнения контейнеров нашего Kubernetes кластера.
Следуя официальной документации по cri-o, нам сначала нужно указать переменные, необходимые для загрузки желаемой версии cri-o для нашего конкретного дистрибутива Linux. Учитывая, что мы запускаем Debian 11, а на момент написания 1.24 — это последняя версия cri-o, мы экспортируем несколько переменных:
export OS=Debian_11
export VERSION=1.24Мы также можем проверить, сохранены ли эти переменные в текущей сессии терминала, передав команду env в grep:

Теперь мы можем начать установку контейнерного времени выполнения:
echo "deb https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/ /" > /etc/apt/sources.list.d/devel:kubic:libcontainers:stable.list
echo "deb http://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable:/cri-o:/$VERSION/$OS/ /" > /etc/apt/sources.list.d/devel:kubic:libcontainers:stable:cri-o:$VERSION.list
curl -L https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable:/cri-o:/$VERSION/$OS/Release.key | apt-key add -
curl -L https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/Release.key | apt-key add -
apt-get update
apt-get install -y cri-o cri-o-runcЕсли все прошло успешно, мы должны получить следующий вывод:

Теперь, когда мы установили пакеты cri-o, мы должны включить и запустить cri-o как службу:
systemctl enable crio
systemctl start crio
systemctl status crioКоманда systemctl status crio должна вывести текущее состояние службы:

Поздравляем! Наш узел Kubernetes готов к запуску.
Запуск нашего первого узла
Я надеюсь, вы плотно затянули свои ботинки, потому что наша сеть Pod будет иметь CIDR 10.100.0.0/16.
Что такое сетевой CDR?
CIDR (Classless Inter-Domain Routing) - это обозначение, используемое для представления префикса сети в адресации IP. Это комбинация IP-адреса и маски подсети, представленных в виде "<IP-адрес>/<маска подсети>". Маска подсети определяет, какая часть IP-адреса является сетевой, а какая — хостовой.
В случае диапазона 10.100.0.0/16 это означает, что IP-адрес — 10.100.0.0, а маска подсети состоит из 16 бит. Маска подсети из 16 бит указывает, что первые 16 бит IP-адреса являются сетевой частью, а оставшиеся 16 бит — хостовой частью. Это означает, что наш хост может управлять до 65 536 IP-адресами, находящимися в диапазоне от 10.100.0.0 до 10.100.255.255.
Теперь, когда мы решили, что наш маленький, но удаленький кластер Kubernetes будет иметь сеть из 65 536 IP-адресов, мы можем проверить нашу конфигурацию.
Dry run
Для запуска нашего кластера мы будем использовать официальную утилиту kubeadm. Прежде чем применять наши изменения, мы можем запустить настройку сети с использованием флага --dry-run без каких-либо изменений:
kubeadm init --pod-network-cidr=10.100.0.0/16 --dry-runЕсли наша виртуальная машина была настроена правильно, мы должны получить длинный вывод:

Если так называемые "предварительные проверки" выдают ошибку, то, выполнив быстрый поиск в Google, мы можем исправить проблему и в последствии применить эти изменения без флага --dry-run.
Инициализация нашего кластера
После того, как мы получили виртуальную машину, которая проходит предварительные проверки, мы можем инициализировать наш кластер.
После выполнения этой команды kubeadm превратит нашу виртуальную машину в узел управления Kubernetes, состоящий из следующих основных компонентов:
etcd — хранилище ключ-значение, используемое для хранения состояния всего кластера Kubernetes;
kube-scheduler — компонент управления, который отслеживает вновь созданные Pod без назначенного узла и выбирает для них узел для запуска;
kube-controller-manager — компонент управления, запускающий процессы контроллера.
Если наша инициализация прошла успешно, мы получим вывод с командой, которую можно использовать для присоединения других узлов:

Обратите внимание на эту команду присоединения:
kubeadm join 192.168.122.97:6443 --token nljqps.vypo4u9y07lsw7s2 \
--discovery-token-ca-cert-hash sha256:f820767cfac10cca95cb7649569671a53a2240e1b91fcd12ebf1ca30c095c2d6Примечание: По умолчанию токен этой команды присоединения действителен только в течение 2 часов 24 часа, после чего вам нужно будет сообщить kubeadm, чтобы он выдал новый токен для присоединения других узлов.
После того, как мы запустили первый узел управления, мы можем использовать crictl (инструкция для установки) так же, как используем команду docker, и увидеть, какие компоненты работают в нашем контейнерном времени выполнения cri-o:
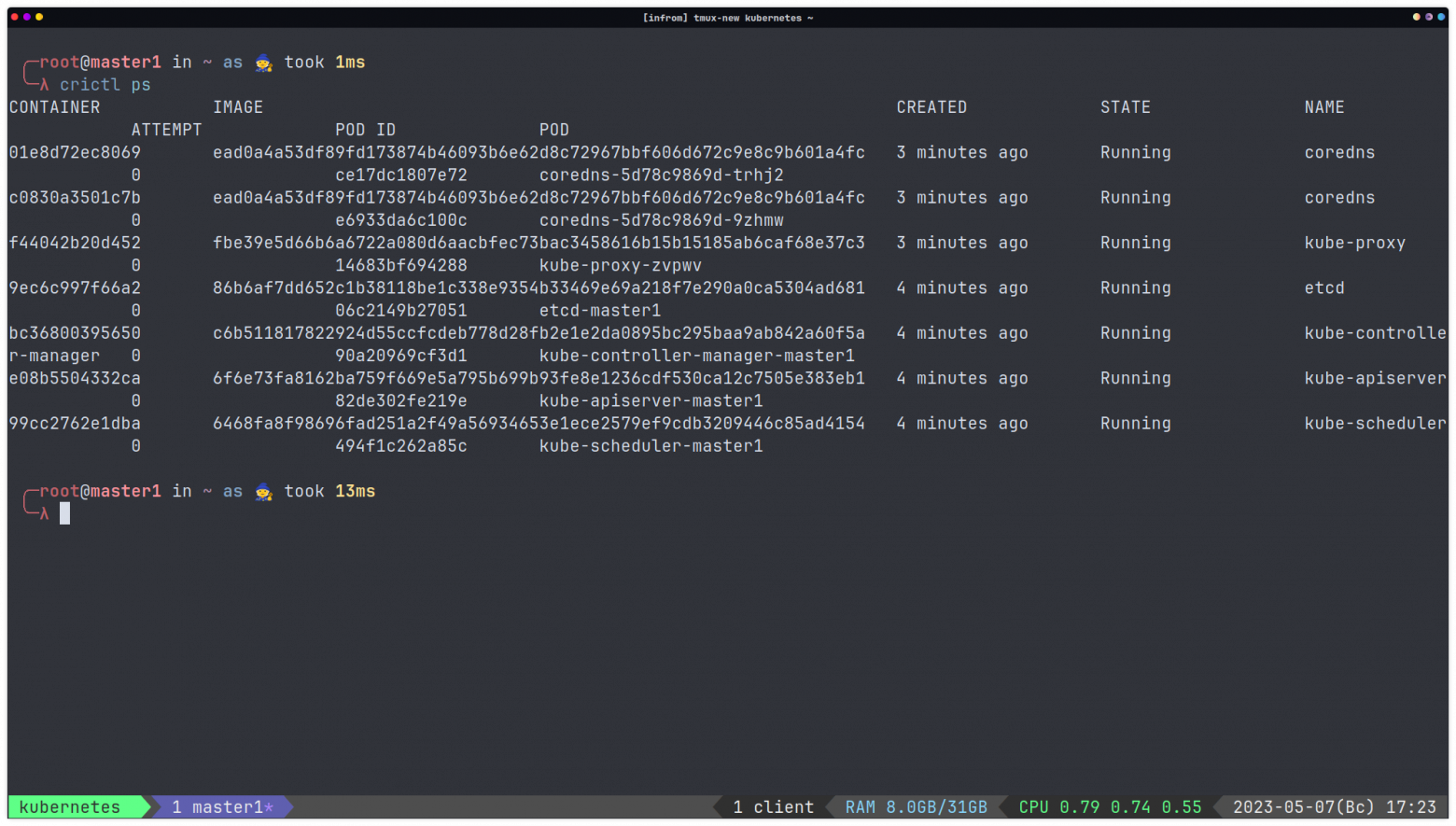
Как мы видим, вышеупомянутые компоненты Kubernetes все работают как контейнеры внутри первой ноды нашего кластера .
Добавляем нашего первого воркера
По умолчанию узел Control Plane запускает только контейнеры, которые являются частью системы Kubernetes, но не Pod-ы с контейнерными приложениями. Теперь, когда у нас есть работающий узел Control Plane ("master1"), мы можем приступить к добавлению первого воркера.
Перед этим мы должны выполнить те же самые шаги, что и при настройке нашего Control Plane узла. Для нашего первого воркера, я создал вторую виртуальную машину под названием "worker1" в правой части моего оконного менеджера терминалов tmux:

После того, как мы выполнили те же процедуры, я копирую токен присоединения из шагов выше:
kubeadm join 192.168.122.97:6443 --token nljqps.vypo4u9y07lsw7s2 \
--discovery-token-ca-cert-hash sha256:f820767cfac10cca95cb7649569671a53a2240e1b91fcd12ebf1ca30c095c2d6И вставляю команду с токеном в окно "worker1". kubeadm снова потребует время, чтобы пройти все проверки, прежде чем присоединить рабочего узла ("worker1") к узлу Control Plane ("master1").

Как только это будет сделано, мы можем поздравить себя с созданием кластера Kubernetes с нуля!
Доступ к нашему кластеру с помощью kubectl
Последний шаг, который нам нужно сделать — скопировать учетные данные администратора, которые будут использоваться kubectl для управления ресурсами нашего кластера через компонент API-сервера Kubernetes, работающий на нашем узле Control Plane.
В целях этого руководства мы будем получать доступ к нашему кластеру через узел Control Plane. Мы скопируем конфигурацию в домашний каталог нашего пользователя следующим образом:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configПосле этого мы можем использовать команду kubectl для управления, создания, редактирования, удаления и развертывания нашего кластера Kubernetes. Для начала мы можем получить список узлов, которые в настоящее время являются частью нашего кластера Kubernetes:
kubectl get nodesИ мы получаем список, состоящий из нашего узла Control Plane ("master1") и главного воркер узла ("worker1"):

Теперь мы можем создавать Pod-ы, сервисы, пространства имен и все прочие замечательные вещи при помощи команды kubectl!
Заключение
В заключение можно сказать, что процесс создания кластера Kubernetes с использованием cri-o в качестве контейнерного рантайма может показаться сложным на первый взгляд, но с правильным пониманием и знанием отдельных компонентов, его можно достичь относительно легко. Следуя шагам, описанным в этом туториале, мы получили более глубокое понимание того, как работает Kubernetes, и требований, необходимых для настройки функционального кластера. Вооруженные этими знаниями, мы теперь можем уверенно экспериментировать и исследовать все возможности Kubernetes в наших средах разработки и эксплуатации.
