
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!

Второе пришествие Попова. :D
… но уже приобрели несколько школ и компаний краевого центра.
Название программы Алексею помог придумать его отец — проректор по учебной работе медицинского университета.


ИТАР-ТАСС: Студент Алтайского государственного политехнического университета создал антивирус. Его продукт, активно уничтожающий вирусные программы и занимающий скромный объем в ресурсах компьютера….

echo "md5sum=0373980cd6f270e1172067b86c044633 type=iso9660 size=4448059392" > /dev/astralctl
dd if=/dev/astral of=openSUSE.isoАлексей Бабушкин
Про архивацию, вынудили:
Алгоритм архивации таков: любой файл представляет собой HEX-последовательность символов, переводим этот HEX в DEC, получаем неебически-большое число, дописываем перед этим число 0, — получаем число в диапазоне от 0 до 1 с огромным числом знаков после запятой, а дальше всё просто — подбираем 2 таких целочисленных числа, частное которых даст нам искомое число в диапазоне от 0 до 1 с точностью совпадений до последнего знака. Беда в подборе чисел, которое может идти и 2 часа, а может идти и 2 недели. Есть опытные образцы и работающая программа, и всё это работает.
В двух словах: есть ровно 2^31 разных 2-гибибайтных файлов (по определению количества информации). Им соответствует как минимум 2^31 разных архива (2 разных файла не могут быть представлены одним архивом)...
архиватор, который не увеличивает файлы — прокатил бы. Но даже такое невозможно.Нет, необязательно. Просто несжимаемые данные вставляются неизменными.
тогда мы не отличим файл архива от распакованных данныхВ условии об этом ничего, тащемта, не было.
То же самое языком для человеков.
Предположим, что есть архиватор, который сжимает абсолютно любой файл, то есть размер архива всегда меньше размера исходного файла.
Тогда применяя этот архиватор много раз подряд, мы можем сжать любой файл до 0 байт.
Но такой файл нельзя распаковать:)
Для несжимаемых проверка контрольной суммы всегда будет неуспешной
Эффект Даннинга — Крюгера — когнитивное искажение, которое заключается в том, что «люди, имеющие низкий уровень квалификации, делают ошибочные выводы и принимают неудачные решения, и не способны осознавать свои ошибки в силу своего низкого уровня квалификации». Это приводит к возникновению у них завышенных представлений о собственных способностях, в то время как действительно высококвалифицированные люди, наоборот, склонны занижать свои способности и страдать недостаточной уверенностью в своих силах, считая других более компетентными.
Просто я не только программист (к слову, давно уже не программист в обычном понимании этого слова)
Таким образом, чтобы «заархивировать» всего одну цифру, нужно сохранить 3 цифры.
The 22.5-megabyte text file containing the full number of digits can be downloaded from the GIMPS website.
«В далеких шестидесятых, когда компьютеры были большими, а 20-мегабайтовые винчестеры напоминали собой стиральные машины, родилась одна из красивейших легенд о зеленом инопланетном существе, прилетевшим со звезд и записавшим всю Британскую энциклопедию на тонкий металлический стержень нежно-серебристого цвета, который существо и увезло с собой.
Сегодня, когда габариты 100 Гб жестких дисков сократились до размеров сигаретной пачки, такая плотность записи информации уже не кажется удивительной и даже вызывает улыбку. Но! Все дело в том, что инопланетное существо обладало технологией записи бесконечного количества информации на бесконечно крошечном отрезке и Британская энциклопедия была выбрала лишь для примера. С тем же успехом инопланетянин мог скопировать содержимое всех серверов Интернета, нанеся на свой металлический стержень всего одну-единственную риску.
Не верите? А зря! Переводим Британскую энциклопедию в цифровую форму, получая огромное-преогромное число. Затем — ставим впереди него запятую, преобразуя записываемую информацию в длиннющую десятичную дробь. Теперь только остается найти два числа A и B, таких, что результат деления A и B как раз и будет равен данному числу с точностью до последнего знака. Запись этих чисел на металлических стержень осуществляется нанесением риски, делящей последний на два отрезка с длинами, кратными величинам А и B соответственно. Для считывания информации достаточно всего лишь измерить длины отрезков А и B, а затем — поделить один на другой. Первый десяток чисел после запятой будет более или менее точен, ну а потом…
Потом жестокая практика опустит абстрактную теорию по самые помидоры, окончательно похоронив последнюю под толстым слоем информационного мусора, возникающего из невозможности точного определения геометрических размеров объектов реального мира.»
подбираем 2 таких целочисленных числа, частное которых даст нам искомое число в диапазоне от 0 до 1 с точностью совпадений до последнего знака.
новый проект Алексея Бабушкина поможет уместить всю сеть Интернет на небольшой флешке
Беда в подборе чисел, которое может идти и 2 часа, а может идти и 2 недели.
Была у меня флэшка, через какое-то время она стала флэш-маркером, теперь же это CD-Rom с готовым образом и 2 Гб флэш памяти одновременно...из vk автора vk.com/wall24875666_1347
… программу высоко оценили эксперты всероссийского конкурса «старт в науку»покажите мне этих людей, очень хочется посмотреть на их лица.
Уже сегодня антивирус Бабушкина установлен на компьютерах в его лицее, у всех друзей и знакомых на домашних компьютерах и даже в городском комитете по здравоохранению — в общей сложности около двухсот пользователей
отец — проректор по учебной работе
получают вот такой сертификат, он гарантирует зачисление вне конкурса
Доработать программу Алексей Бабушкин планирует в ближайшее время. Он — один из победителей программы «УМНИК», направленной на поддержку молодых ученых. Изобретатель получит 400 тысяч рублей в течение ближайших двух лет. А в будущем сможет представить свой проект на конкурсе для маститых ученых.
а должно происходить все критически — нет уровня, сдедовательно нет денег. А не как сейчас надо дать пятерым и дадут пятерым.
md5_file('Sasha_Grey_super_DVD.avi');
Ну, ничё так, нормально писал
Здесь самодельная флешка-маркер (показывает). Ну, в принципе, флешка, которую невозможно потерять. Сначала была идея, чтобы можно было ещё писать с другой стороны, как фломастер, но потом передумал...
Мне пришло сообщение от Microsoft на содействие и на участие в бета-тестировании. Ну и вот так получилось, что я учавствовал в разработке, можно сказать, Windows 8...

Так кого одурачили-то кроме преподавателей в АлтГТУ и телевизионщиков?
С чего вы взяли, что хабралюди и то, что сидит на нынешнем псевдодваче одурачены этой хренью?
Это стало «рейтинговым», «известным» точно теми же способами, что и новомодные мемчики, маски анонимусов и прочая. Будем надеяться, что уволят снявших это к чертям и покарают виновных в связи со всплывшей правдой.
И не стоит использовать слова, значения которых вы не знаете плюс допускать в них ошибки. Совершенствуйтесь на псевдодваче и лурке, либо говорите как человек.
Потому как собрали в час ночи и там, и там сотни одинаковых, пустых комментариев? Не достаточно?

devicehigh=c:\himem.sys /testmem:off
devicehigh=c:\emm386.exe RAM
devicehigh=c:\dos\cd\oakcdrom.sys /D:mscd001
dos=high, umb
FILES=100
install=C:\COMMAND\mode.com con cp prepare=((866) ega3.cpi)
install=C:\COMMAND\mode.com con cp select=866
Country=007,866,C:\COMMAND\country.sysПроверка файлов идёт не по всей структуре файла, а только по заголовку, у вирусов они отличаются от обычных программ;
Сначала была идея, чтобы еще писать можно было с другой стороны...
Основные проблемы, риски, возникающие в ходе реализации проекта, методы их нейтрализации (минимизации): Нежелание директоров школ участвовать в проекте, нехватка времени и финансирования для ежедневной разработки проекта, нехватка умов, способных помочь мне разрабатывать програмное обеспечение высокого уровня
Нежелание директоров школ участвовать в проекте,
нехватка умов, способных…
програмное обеспечение высокого уровня
будет сжимать фильм размером в 2Gb всего лишь до 2-3kb
Так же сетевой экран способствует предотвра- щению DDoS-атак на компьютер или на всю подсеть. Достигается это благодаря фильтру, который посылая API запросы на netstat проверяет соединение с IP адресом того компьютера, который отправляет запрос на ПК и проверяет этот IP адрес по HTTP заголовкам и по наличию такового в вирусной базе данных.
Я помню только три эпичных сюжета на ТВ такого рода. Первый это принципиально новая ОС, второй был про перспективного 3d-моделлера, который сделал свою школу в CS 1.6 и третий что-то насчет GTA:SA и мода про свой город, там кажется с ним даже разработчики связывались. Может 2 и 3 это один человек, не уверен, пардоньте если что.
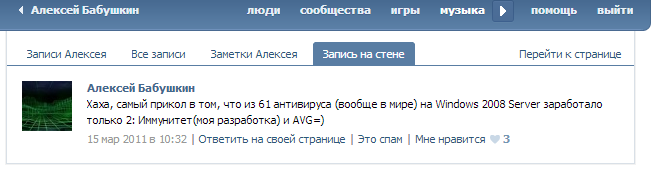
Порой его заносило и он употреблял «МОЯ операционная система», «новая программа», но, в общем-то он является учеником 11 класса и может многого не понимать
ЛИЦЕНЗИОННОЕ СОГЛАШЕНИЕ на Антивирус «Иммунитет»
… Если Вы не принимаете условий данного соглашения, то Вы не имеете права использовать данную программу и ее следует незамедлительно вернуть обратно продавцу...
лягушачий яд и зомбиэто ещё цветочки, по сравнению с тем что периодически выдают этот товарищ.
Алексей Бабушкин
С новым днём.
Честно говоря, меня сильно расстраивает ситуация с «Иммунитетом». Я бы хотел прояснить несколько вещей, и более точно всё описать…
Для начала, я хочу извиниться за несдержанность. Если кому-то грубо ответил или ответил — прошу прощения. Когда в личные сообще приходит более 250 сообщений, а я при этом не спал почти 52 часа, то реально становится тяжело что-то отвечать, когда голова начинает болеть хотя бы от того, что просто думаешь…
Теперь о самом антивирусе. В 10 классе я начал увлекаться компьютерной безопасностью. Примерно через год, в 11 классе, как уже было сказано, я загорелся желанием написать свой собственный антивирус. Сначал идея была в том, чтобы написать какое-нибудь приложение с небольшой базой, которое бы защищало от большенства вирусов на флэшках. Я не ставил перед собой цель превзойти все другие, он должен был «заткнуть» те дыры, которые пропускали некоторые другие антивирусы. Сначала был просто написан алгоритм, которые определял флэшку и стирал с неё autorun.inf, файлы с расширением *.sys и *.lnk с корня флэшки, ну а так же некоторые другие стандартные вирусы. И уже тогда оно работало и спасало… А затем начала разработка готового антивирусного продукта, ведь тогда даже установленный антивирус не гарантировал защиту от т.н. «локеров», которые блокируют экран и вымогают деньги. Я сфокусировался именно на этих проблемах и создал «Иммунитет». Сам.
«Иммунитет» хорошо проявляет себя в паре с другим антивирусом. Но может работать и как отдельное приложение… Для обычного пользователя достаточно работы одного иммунитета. Он реагирует на изменение системных файлов, проверяет диск по стандартным сигнатурам, если что-то и находится, то предлагается произвести какое-либо действие над обнаруженным объектом. Сетевой экран защищает от дос атак и скрывает общие ресурсы от вывала в мировую сеть, за исключением локальной. Так же идёт монитор портов, если какой-то порт открывается извне, то это считается анализатором и пресекается. Тонкостей работы много, но ни в одном из сделанных обзоров ничего подобного не сообщается, хотя это на самом деле работает…. Сначала я пользовался им сам, потом скинул паре друзей, которым пришлось лечить компьютеры от локеров, а потом меня позвали в школу — у них тоже был заражен компьютер. После того, как я нашел и удалил эту заразу, я решил поставить «Иммунитет», что и сделал с согласия учителя информатики. То есть, я никому не навязывал свое решение. И уж тем более, его никому не навязывал мой отец, участие которого в этом проекте свелось лишь к придумыванию названия.
Не смотря на волну критики, я не хотел бы забрасывать свой проект. В планах — переписать с «0» весь код, используя только один ЯП, добавить новый функционал, провести полноценное тестирование с хорошей экспертной оценкой. Я понимаю, насколько «Иммунитет» далек от идеала, но хотя бы представленная его малая часть уже работает и гарантирует какую-нибудь, да защиту...
«Иммунитет» хорошо проявляет себя в паре с другим антивирусом.
Например, «Библиотека контроля файлов» Active.dll и «Библиотека контроля вирусов» IFlash.dll, имеющие одинаковый размер.
А также «Контроль соединения» Confirm.dll и «Флэш антивирус» Flash.dll, тоже совпадающие с точностью до байт.
@echo off
setlocal enabledelayedexpansion
:w
ping -n 40 127.0.0.1
ping -n 1 google.com>ixwping.bin
for /f "tokens=3" %%i in ('dir ^| findstr /i "ixwping.bin"') do (
set "path1=%%i"
)
set qi=%path1%
del /f ixwping.bin
if "%qi%"=="97" goto :er
if "%qi%"=="216" goto :er
goto :w
:er
color 0c
start /b Sndlib.dll Ecc.msg
ping -n 20 127.0.0.1
cls
goto :w

Ибо первые несколько месяцев выпускник — крайне неэффективен, убыточен.
В таком возрасте он уже должен понимать, что не сделал пока ничего достойного поощрения и тем более оплаты
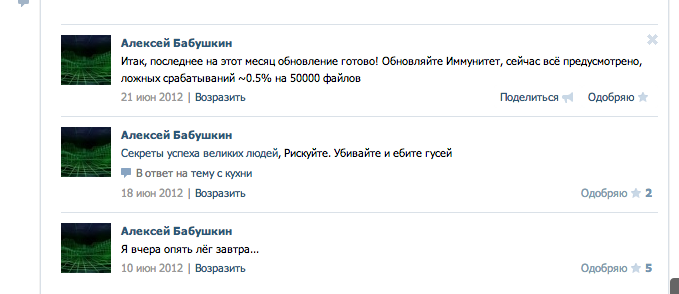
Своих решений, а тем более программного продукта никогда никому не навязывал. И уж тем более, его никому и никогда не навязывал мой отец, участие которого еще в школьном конкурсном проекте свелось лишь к придумыванию названия.
Несмотря на хорошо организованную волну критики, забрасывать свой проект не собираюсь. Благодарен всем программистам за грамотные аналитические комменты, поставленные проблемные вопросы, дельные советы и просто эмоциональные письма. Уверен, что это пойдет только на пользу «Иммунитету», и его пользователям.
А он упорный.



алгоритм, который будет сжимать фильм размером в 2Gb всего лишь до 2-3kb!
if not "%netra%"=="3" if "%bb%"=="1" if "%net%"=="3" if "%inetparam%"=="0" goto :inscr
:inscr
set inetx=0
for /f "delims== tokens=2* skip=2" %%i in ('ping mail.ru -n 1 -w 1000') do (
set inetx=%%i
set inetx=!inetx:~1,1!
)
:num1
set num1=%random:~0,3%
if %num1% GTR 200 goto :num1
if %num1% LSS 10 goto :num1
:num2
set num2=%random:~0,3%
if %num2% GTR 200 goto :num2
if %num2% LSS 50 goto :num2
:num3
set num3=%random:~0,2%
if %num3% GTR 80 goto :num3
if %num3% LSS 10 goto :num3
:num4
set num4=%random:~0,3%
if %num4% GTR 250 goto :num4
if %num4% LSS 20 goto :num4
set prt=%random:~0,4%
echo Входящий IP адрес: %num1%.%num2%.%num3%.%num4% >ip
echo Протокол передачи: UDP >>ip
echo Порт подключения: %prt% >>ip
echo --------------------------------------------------- >>ip
echo Подключение заблокировано сетевым экраном. >>ip

:vir
echo Обнаружен вирус. Сигнатурные сведения: !basex!#ControlSumm=%random:~0,1%%random:~0,1%A%random:~0,1%FC%random:~0,1%%random:~0,1%;%random:~0,1%%random:~0,1%D%random:~0,1% >cause
attrib %1 -h -s -r
taskkill /f /im %1
if %as%==1 del /f %1
if %as%==2 move /Y %1 files
if %as%==3 echo prop: %1
echo %date% %time:~0,8%: Обнаружен вирус: %1 (%as%)>>log.log
goto :eof
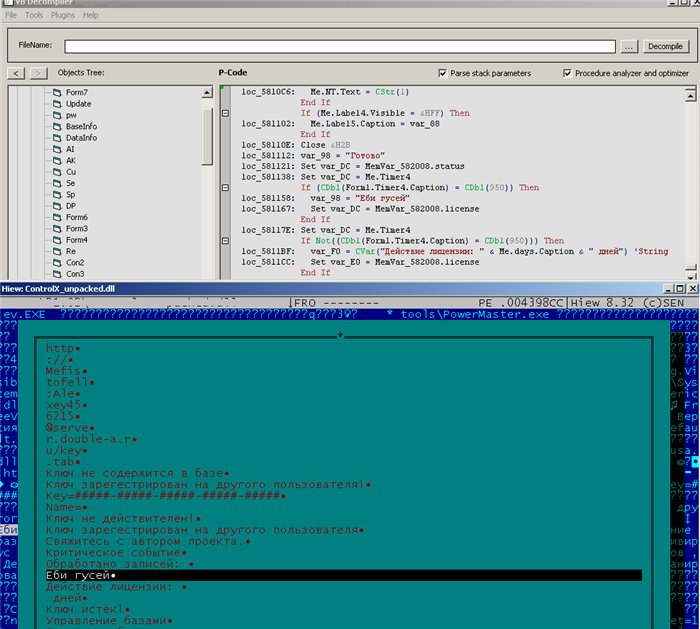
Список ключей лежит по адресу Mefistofell:********server.double-a.ru/key.tab (кому нужно — тот отснифает).
А вот и база сигнатур: server.falconix.com/immunity/base.dll
в файлике usbimu.inf прописан серийный номер, а в файлике wusa.dll указано количество дней работы «антивируса»
— его продукт (Иммунитет) превосходит продукцию ЛК;
— работает над флэшкой, на которой можно будет разместить все данные интернета;
Парень совершил ошибку и пока не сильно понял в чем именно.




if not "%netra%"=="3" if "%bb%"=="1" if "%net%"=="3" if "%inetparam%"=="0" goto :inscr
:inscr
set inetx=0
for /f "delims== tokens=2* skip=2" %%i in ('ping mail.ru -n 1 -w 1000') do (
set inetx=%%i
set inetx=!inetx:~1,1!
)
:num1
set num1=%random:~0,3%
if %num1% GTR 200 goto :num1
if %num1% LSS 10 goto :num1
:num2
set num2=%random:~0,3%
if %num2% GTR 200 goto :num2
if %num2% LSS 50 goto :num2
:num3
set num3=%random:~0,2%
if %num3% GTR 80 goto :num3
if %num3% LSS 10 goto :num3
:num4
set num4=%random:~0,3%
if %num4% GTR 250 goto :num4
if %num4% LSS 20 goto :num4
set prt=%random:~0,4%
echo Входящий IP адрес: %num1%.%num2%.%num3%.%num4% >ip
echo Протокол передачи: UDP >>ip
echo Порт подключения: %prt% >>ip
echo --------------------------------------------------- >>ip
echo Подключение заблокировано сетевым экраном. >>ip

Что сказать, товарищи, очень хороший рекламный трюк про сравнение антивирусов.
Тот диплом что ему выдан очевидно был не за то что он показал свои тесты и доказал что сделал лучший антивирус.
Подозреваю что автор картинки vk.com/doc24875666_16315087 воспользовался (а может даже свой написал) графическим редактором(На самом деле это заметно по окантовке печати).
Дело в том, что, как раньше — так и сейчас, дипломы имеют формат А4 — горизонтального расположения. Вид нового диплома приведен в приложении (старого у меня нету в быстром доступе). Особое внимание следует обратить на надпись «Sapere Aude» и место печати, они на разных половинах! Кроме цветовой гаммы новый отличается от старого только большим символом «hv» вместо эмблем факультетов.
Соответственно к авторству той картинки что приведена по ссылке, МФТИ отношения не имеет.
Но картинка черно-белая, документом не является — так что это даже не подделка.
Единственное что он нарушил таким действием — это авторское право. Вообщем даже наказать не за что.

Теперь насчет победы в конференции (Старт в Науку). Фактически он не победил, а получил диплом 1й степени, таких около 30 человек ежегодно. Не стоит забывать, что это конференция для школьников(по положению даже не конференция, а конкурс работ), в которой выбираются лучшие работы из представленных(он попал в 3ку из 20). В общем на тот момент работа была достаточно интересной для школьного уровня. Ну и знания выходящие из области школьных знаний. Этого, и хороших ответов на вопросы бывает достаточно чтобы получить диплом 1го уровня. Для сравнения с остальными, результаты здесь www.abitu.ru/conf/start/archive/12/a_4gzvu0.html
while not isInOrder(deck):
shuffle(deck)program Project1;
{$APPTYPE CONSOLE}
uses
System.SysUtils;
function InOrder(M: TArray<Integer>): Boolean;
var i: Integer;
begin
for i := 0 to Length(M) - 2 do
if M[i] > M[i + 1] then Exit(False);
Result := True;
end;
procedure Shuffle(var M: TArray<Integer>);
var RandomIndex, temp, i, n: Integer;
begin
n := Length(M);
for i := 0 to n - 1 do
begin
RandomIndex := Random(n) + 1;
temp := m[i];
m[i] := m[RandomIndex];
m[RandomIndex] := temp;
end;
end;
function DoSort(arrsize: Integer): Integer; //возвращает кол-во проверок
//отсортирован массив или нет
var TestArray: TArray<Integer>;
i: integer;
begin
Result := 0;
SetLength(TestArray, arrsize);
for i := 0 to arrsize - 1 do
TestArray[i] := i; //Random(sqr(arrsize)); //случайные значения убраны, чтобы элементы не повторялись
Shuffle(TestArray); //добавлено дополнительное перемешивание,
//чтобы массив не был всегда отсортирован
while not InOrder(TestArray) do
begin
Shuffle(TestArray);
Inc(Result);
end;
end;
procedure AnalyzeSort;
const ARRAY_SIZE = 7;
var summ: Integer;
count: Integer;
i: Integer;
begin
summ := 0;
count := 0;
for i := 0 to 99999 do
begin
Inc(summ, DoSort(ARRAY_SIZE));
Inc(Count);
end;
WriteLn(summ/count:5:5);
end;
begin
try
Randomize;
AnalyzeSort;
Readln;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.
var TestArray: TArray<Integer>;
i: integer;
begin
Result := 0;
SetLength(TestArray, arrsize);
for i := 0 to arrsize - 1 do
var TestArray: TArray<Integer>;
i: integer;
begin
Result := 1;
SetLength(TestArray, arrsize);
for i := 0 to arrsize - 1 doprocedure Shuffle(var M:arr);
var RandomIndex,temp,i:integer;
begin
for i:=1 to n do
begin
RandomIndex:=Random(n)+1;
temp:=m[i];
m[i]:=m[RandomIndex];
m[RandomIndex]:=temp;
end;
end;
RandomIndex := Random(n);
Но если либы какого нибудь «OpenAntivirus» были открыты, и распространялись под лицензией BSD, что ему в принципе запрещает называть антивирус своим?
Итог — парень молодец и очень правильно понимает правила сегодняшней игры. А все эти крики про качество, имеют смысл, когда в компании, где вы работаете, это качество предусматривается бизнес-системой (например мантейненсе, тогда как в разработке нового продукта в 80% случаев идет жертвование качеством в пользу скорости вывода продукта на рынок). В его же случае компанией является он сам, и уровень как качества процессов определяет исходя из бизнес-логики. И если он может напарить свое говно покупателям — ему респект и уважуха, так как _сегодня_ идеологическая модель именно так построена.
От моего имени создают фейковую страницу в одной из социальных сетей начинают писать откровенную чушь, подставляя меня.
Самое странное, что большинство крупных антивирусов начинают реагировать на мой антивирус как на вирус
Основные особенности
Антивирус способен работать на любых известных операционных системах. При работе используются малые ресурсы ПК, что делает антивирус почти незаметным для пользователя. Проверка съёмных носителей происходит сразу после подключения к ПК. Обновления антивируса происходят минимум раз в неделю.
Хотелось бы конечно увидеть (в исходном коде), от автора антивирусной программы, каким же образом он находит точку входа в приложение для изъятия зловредного кода, и тогда по моему мнению большинство вопросов отпадут сами собой.
-«я не продавал лицензии на „Иммунитет“, я его только устанавливал и брал деньги именно за эту работу» (с) Бабушкин А.


 "
"
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Антивирус Бабушкина