Когда пользуешься сложными алгоритмами для решения задач компьютерного зрения — нужно знать основы. Незнание основ приводит к глупейшим ошибкам, к тому, что система выдаёт неверифицируемый результат. Используешь OpenCV, а потом гадаешь: «может, если сделать всё специально под мою задачу ручками было бы сильно лучше?». Зачастую заказчик ставит условие «сторонних библиотек использовать нельзя», или, когда работа идёт для какого-нибудь микроконтроллера, — всё нужно прогать с нуля. Вот тут и приходит облом: в обозримые сроки реально что-то сделать, только зная как работают основы. При этом чтения статей зачастую не хватает. Прочитать статью про распознавание номеров и попробовать самому такое сделать — огромная пропасть. Поэтому лично я стараюсь периодически писать какие-нибудь простенькие программки, включающие в себя максимум новых и неизвестных для меня алгоритмов + тренирующих старые воспоминания. Рассказ — про один из таких примеров, который я написал за пару вечеров. Как мне показалось, вполне симпатичный набор алгоритмов и методов, позволяющий достичь простенького оценочного результата, которого я ни разу не видел.

Сидя вечером и страдая от того, что нужно сделать что-то полезное, но не хочется, я наткнулся на очередную статью по нейросетям и загорелся. Нужно сделать наконец-таки свою нейросеть. Идея банальная: все любят нейросети, примеров с открытым кодом масса. Мне иногда приходилось пользоваться и LeNet и сетями из OpenCV. Но меня всегда настораживало, что их характеристики и механику я знаю только по бумажкам. А между знанием «нейросети обучаются методом обратного распространения» и пониманием того, как это сделать пролегает огромная пропасть. И тогда я решился. Пришло время, чтобы 1-2 вечера посидеть и сделать всё своими руками, разобраться и понять.
Обратите внимание, статья 2014 года. А сейчас 2021. С тех пор произошло пару революций в ComputerVision и нейронных сетях. Делает ли это приведенные тут методы неправильными? Нет. Но, скорее всего это не то тут есть — уже немного не актуально. Что использовать сегодня? Сложно сказать, очень много вариаций, зависит от задачи. Если хотите оставаться в курсе событий — советую читать мой канал (vk, telegram) про более новые методы/подходы.
Нейросеть без задачки, что конь без всадника. Решать сделанной на коленке нейросетью серьёзную задачу — тратить много времени на отладку и обработку. Поэтому нужна была простая задачка. Одной из простейших задачек в обработке сигналов, которую можно решить чисто математически является задачка детектирования белого шума. Плюс задачи именно в том, что её возможно решить на бумажке, можно оценить точность полученной сети в сравнении с математическим решением. Ведь не в каждой задачке можно оценить то, насколько хорошо отработала нейросеть просто сверевшись с формулой.
Для начала сформулируем задачу. Пусть у нас есть последовательность из N элементов. В каждом из элементов последовательности имеется шум, с нулевым матожиданием и единичной дисперсией. Имеется сигнал E, который может находиться в этой последовательности с центром от 0.5 до N-0.5. Сигнал зададим Гауссианой с такой дисперсией, чтобы при нахождении в центре пикселя большая часть энергии была в этом же пикселе (с совсем точечным будет скучно). Требуется принять решение, есть ли сигнал в последовательности или нет.
«Что за синтетическая задача!», скажете вы. Но это не совсем так. Такая задача встаёт каждый раз, когда вы работаете с точечными объектами. Это могут быть звёзды на изображении, это может быть отражённый радио (звуковой, оптический) импульс в временной последовательности, это могут даже быть какие-то микроорганизмы под микроскопом, не говоря про самолётики и спутники в телескопе.
Запишем чуть более строго. Пусть имеется последовательность сигналов l0…In, содержащих нормальный шум с постоянной дисперсией и нулевым математическим ожиданием:
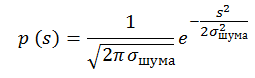
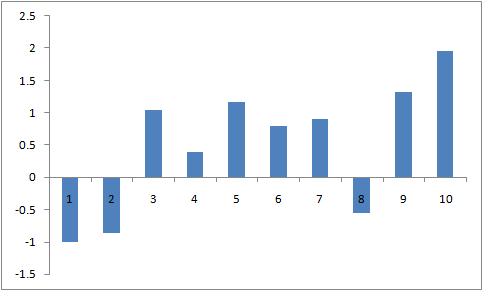
Вероятность того, что в пикселе содержится сигнал s равна p(s). Пример последовательности, заполненной нормально распределённым шумом с дисперсией 1 и матожиданием 0:
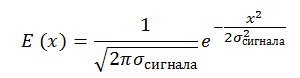
Так же имеется сигнал c постоянным отношением сигнал/шум, SNR=E_сигнала/σ_шума =const. Мы имеем право так записать, когда размер сигнала примерно равен размеру пикселя. Сигнал у нас тоже задаётся Гауссианой:
Для простоты будем полагать, что σ_сигнала=0.25∙L, где L -размер пикселя. А это значит, что для сигнала, расположенного в центре пикселя пиксель будет содержать энергию сигнала от — 2σ до + 2σ:
Вот так будет выглядеть прошлая последовательность с шумом, поверх которой наложен сигнал с SNR=5 с центром в точке 4.1:
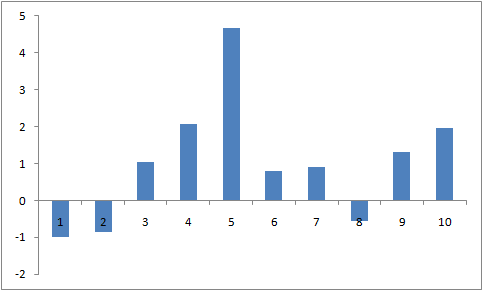
Кстати, а вы знаете, как генерировать нормальное распределение?
Забавно, но многие пользуются для его генерации центральной предельной теоремой. В этом способе складывается 6 линейно распределённых величин на интервале -0.5 до 0.5. Считается, что получается величина, распределена нормально с дисперсией равной единице. Но этот способ даёт некорректные хвосты распределения, при больших отклонениях. Если брать именно 6 величин, то max=|min|=3=3*σ. Что сразу отрезает 0.2% реализаций. При генерации изображения 100*100 такие события должны произойти в 20 пикселях, что не так уж и мало.
Есть хорошие алгоритмы: Преобразование Бокса-Мюллера, Преобразование Джорджа Марсальи
На Хабре есть хорошая статья на эту тему.
Все эти методы основаны на том, чтобы математическим образом перевести линейное распределение на интервале [0;1] в нормальное распределение.
Про нейросети написано очень много. Попробую не вдаваться в подробности, ограничившись лишь ссылками и основными моментами.
Нейросеть состоит из нейронов. Как устроен нейрон у человека досконально никто не знает, но есть много красивых моделей. На хабре было много интересных статей про нейроны: 1, 2, и.т.д.
В задачке я взял за основу простейшую схему нейронов, когда на вход нейрона подаётся последовательность сигналов, которая суммируется и прогоняется через функцию активации:
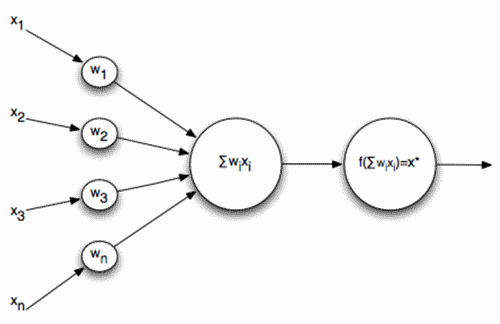
Где функция активации:
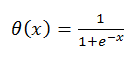

Что делает такой нейрон в такой модели и зачем ему функция активации?
Нейрон производит сравнение с неким паттерном, на который он обучается. А функция активации это триггер, который выносит решение о том, насколько паттерн совпал и производит нормировку решения. Почему-то мне зачастую кажется, что нейрон похож на транзистор, но это лирическое отступление:
Почему не делать функцию активации ступенькой? Тут много причин, но основная, про которую будет рассказано чуть ниже — особенность обучения, при котором требуется дифференцируемость функции нейрона. У приведённой функции активации очень хороший дифференциал:
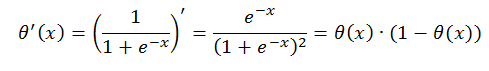
У нас есть сеть. Как решать задачу? Классический способ решения простой задачи, создать нейронную сеть такого вида:
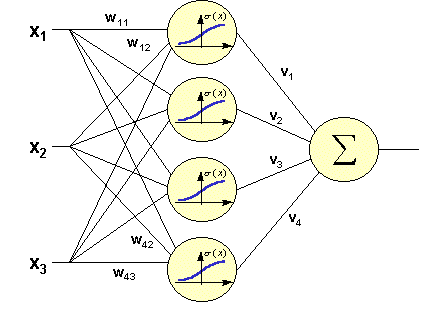
В ней имеется входной сигнал, один скрытый слой (где каждый нейрон соединён со всеми входными элементами) и выходной нейрон. Обучение такой сети — это, по сути, настройка всех коэффициентов w и v.
Сделаем почти так, но проведя оптимизацию под задачку. Зачем обучать каждый нейрон скрытого слоя по каждому пикселю входного изображения? Сигнал максимум занимает три пикселя, а скорее всего даже два. Поэтому, соединим каждый нейрон скрытого слоя только с тремя соседними пикселями:
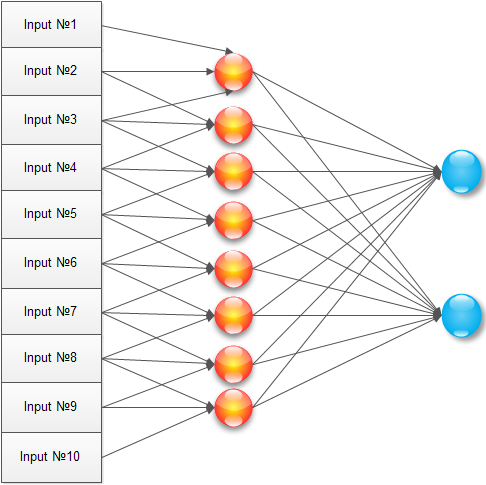
При такой конфигурации нейрон обучается на окрестность изображения, начиная работать локальным детектором. Массив обучаемых элементов для скрытого слоя (1..N) будет выглядеть как:
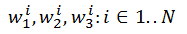
В качестве эксперимента я ввёл два выходных нейрона, но особого смысла, как окажется позднее, это не возымело.
Нейронные сети такого типа — одни из самых старых, используемых в работах. В последнее время всё чаще и чаще народ использует свёрточные сети. Про свёрточные сети уже неоднократно писали на хабре: 1, 2.
Свёрточная сеть — это такая сеть, которая ищет и запоминает существующие паттерны, универсальные для всего изображения. Обычно, чтобы продемонстрировать, что такое нейронная сеть, рисуют такое изображение:
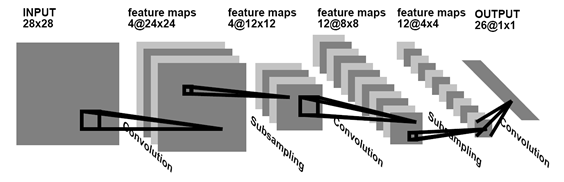
Но когда начинаешь это пробовать закодить, мозг входит в ступор от того «как же это применить к реальности». А в реальности, приведённый выше пример нейросети, всего лишь одним действием переводится в свёрточную сеть. Для этого при обучении достаточно полагать, что элементы w11,…,w1N — это не разные элементы, а один и тот же элемент w1. Тогда, в результате обучения скрытого слоя будет найдено только три элемента w1,w2,w3, представляющие собой свёртку.
Правда, как оказалось, одной свёртки для решения задачи не хватает, нужно ввести вторую, но это просто сделать, увеличив количество элементов в скрытом слое до 1..2N, при этом элементы 1..N обучают первую свёртку, а элементы N..2N — вторую.
Нейросеть просто нарисовать, но не так просто обучить. Когда это делаешь в первый раз мозг немножко выворачивает. Но, к счастью, в рунете есть две очень хорошие статьи, после которых всё становится ясно как день: 1, 2
Первая очень хорошо иллюстрирует логику и порядок обучения, во второй хорошо расписана математическая суть: откуда что получается из формул, как инициализируется нейронная сеть, как правильно считать и применять коэффициенты.
В целом метод обратного распространения ошибки состоит в следующем: подать на вход известный сигнал, распространить его на выходные нейроны, сравнить с требуемым результатом. Если имеется несовпадение, то величину ошибки домножить на вес связи и передать всем нейронам на прошлом слое. Когда все нейроны будут знать свою ошибку, тогда сдвинуть их коэффициенты обучения таким образом, чтобы ошибка уменьшилась.
Если что, то пугаться обучения не стоит. Например определение ошибки делается в одну строчку так:
А коррекция весов вот так:
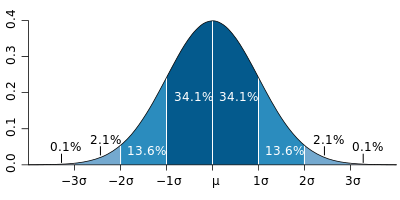
Для начала, как и обещали, посчитаем «а что должно быть». Пусть мы имеет соотношение SNR (сигнал/шум) = 3. В этом случае сигнал в 3 раза выше дисперсии шума. Давайте нарисуем вероятность того, что сигнал в пикселе принимает значение X:
На графике сразу отображены графики только для вероятностного распределения шума и график вероятностного распределения сигнала+шума в точке при отношении SNR=3. Для того, чтобы принять решение о нахождении сигнала нужно выбрать некий Xs, все значения больше него считать сигналом, все значения меньше — шумом. Нарисуем вероятность того, что мы приняли решение о ложной тревоге и о пропуске объекта (для красного графика это его интеграл, для синего «1-интеграл»):
Точка пересечения для таких графиков обычно называется EER (Equal Error Rate). В этой точке вероятность неправильного принятия решения равна вероятности потери объекта.
В рассматриваемой задачке у нас имеется 10 входных сигналов. Как для такой ситуации выбрать точку EER? Достаточно просто. Вероятность того, что при выбранном значении Xs не произошло ложной тревоги будет равна (интеграл по синему графику с первого рисунка):
Соответственно вероятность того, что в 10 пикселях не произошло ложной тревоги равна:
Вероятность того, что произошла хотя бы 1 ложная тревога равна 1-P. Отрисуем график 1-P и, рядом с ним график вероятности пропуска объекта (продублируем со второго графика):
Значит точка EER для сигнала и шума при SNR=3 находится в районе двойки и в ней EER≈0.2. А что даст нейросеть?
Видно, что нейронная сеть будет чуть хуже, чем задачка решённая на пальцах. Но, не всё так плохо. При математическом рассмотрении мы не учли несколько особенностей (например, сигнал может попадать не в центр пикселя). Не вдаваясь особо глубоко можно сказать, что это не сильно ухудшает статистику, но всё же ухудшает.
Если честно, меня такой результат ободрил. Сеть неплохо справляется с чисто математической задачкой.
Всё же, моей основной задачкой было создать нейронную сеть с нуля и потыкать в неё палочкой. В этом разделе будет пара забавных гифок о поведении сети. Сеть получилась далеко не идеальной (думаю, что статью будут сопровождать разгромные комментарии профессионалов, ибо эта тематика популярна на Хабре), но достаточно много особенностей проектировки и написания я выучил в результате написания и отныне попробую не повторяться, так что лично я доволен.
Первая гифка для обычной сети. Верхняя полоска это входной сигнал во времени. SNR=10, явно виден сигнал. Нижние две полоски — вход на суммирование последнего нейрона. Видно, что сеть стабилизировала изображение и при включении-выключении сигнала изменяется только контраст входов последнего нейрона. Забавно, что при отсутствии сигнала изображение практически стационарно.
Вторая гифка — тоже самое для свёрточной сети. Количество входов на последний нейрон увеличивается в 2 раза. Но в принципе структура не изменяется.
Все исходники лежат тут — github.com/ZlodeiBaal/NeuronNetwork. Написано на C#. Дллки у OpenCV большие, поэтому после скачивания нужно распаковать внутрь папки lib.rar. Либо скачать тут сразу проект, распаковывать ничего не надо — yadi.sk/d/lZn2ZJ_BWc4DB.
Код написан за 2 вечера где-то, так что далёк от промышленных стандартов, но вроде понятен (статью на хабр писал я дольше, надо признать).
Сидя вечером и страдая от того, что нужно сделать что-то полезное, но не хочется, я наткнулся на очередную статью по нейросетям и загорелся. Нужно сделать наконец-таки свою нейросеть. Идея банальная: все любят нейросети, примеров с открытым кодом масса. Мне иногда приходилось пользоваться и LeNet и сетями из OpenCV. Но меня всегда настораживало, что их характеристики и механику я знаю только по бумажкам. А между знанием «нейросети обучаются методом обратного распространения» и пониманием того, как это сделать пролегает огромная пропасть. И тогда я решился. Пришло время, чтобы 1-2 вечера посидеть и сделать всё своими руками, разобраться и понять.
NB!
Обратите внимание, статья 2014 года. А сейчас 2021. С тех пор произошло пару революций в ComputerVision и нейронных сетях. Делает ли это приведенные тут методы неправильными? Нет. Но, скорее всего это не то тут есть — уже немного не актуально. Что использовать сегодня? Сложно сказать, очень много вариаций, зависит от задачи. Если хотите оставаться в курсе событий — советую читать мой канал (vk, telegram) про более новые методы/подходы.
Нейросеть без задачки, что конь без всадника. Решать сделанной на коленке нейросетью серьёзную задачу — тратить много времени на отладку и обработку. Поэтому нужна была простая задачка. Одной из простейших задачек в обработке сигналов, которую можно решить чисто математически является задачка детектирования белого шума. Плюс задачи именно в том, что её возможно решить на бумажке, можно оценить точность полученной сети в сравнении с математическим решением. Ведь не в каждой задачке можно оценить то, насколько хорошо отработала нейросеть просто сверевшись с формулой.
Задачка
Для начала сформулируем задачу. Пусть у нас есть последовательность из N элементов. В каждом из элементов последовательности имеется шум, с нулевым матожиданием и единичной дисперсией. Имеется сигнал E, который может находиться в этой последовательности с центром от 0.5 до N-0.5. Сигнал зададим Гауссианой с такой дисперсией, чтобы при нахождении в центре пикселя большая часть энергии была в этом же пикселе (с совсем точечным будет скучно). Требуется принять решение, есть ли сигнал в последовательности или нет.
«Что за синтетическая задача!», скажете вы. Но это не совсем так. Такая задача встаёт каждый раз, когда вы работаете с точечными объектами. Это могут быть звёзды на изображении, это может быть отражённый радио (звуковой, оптический) импульс в временной последовательности, это могут даже быть какие-то микроорганизмы под микроскопом, не говоря про самолётики и спутники в телескопе.
Запишем чуть более строго. Пусть имеется последовательность сигналов l0…In, содержащих нормальный шум с постоянной дисперсией и нулевым математическим ожиданием:
Вероятность того, что в пикселе содержится сигнал s равна p(s). Пример последовательности, заполненной нормально распределённым шумом с дисперсией 1 и матожиданием 0:
Так же имеется сигнал c постоянным отношением сигнал/шум, SNR=E_сигнала/σ_шума =const. Мы имеем право так записать, когда размер сигнала примерно равен размеру пикселя. Сигнал у нас тоже задаётся Гауссианой:
Для простоты будем полагать, что σ_сигнала=0.25∙L, где L -размер пикселя. А это значит, что для сигнала, расположенного в центре пикселя пиксель будет содержать энергию сигнала от — 2σ до + 2σ:
Вот так будет выглядеть прошлая последовательность с шумом, поверх которой наложен сигнал с SNR=5 с центром в точке 4.1:
Кстати, а вы знаете, как генерировать нормальное распределение?
Забавно, но многие пользуются для его генерации центральной предельной теоремой. В этом способе складывается 6 линейно распределённых величин на интервале -0.5 до 0.5. Считается, что получается величина, распределена нормально с дисперсией равной единице. Но этот способ даёт некорректные хвосты распределения, при больших отклонениях. Если брать именно 6 величин, то max=|min|=3=3*σ. Что сразу отрезает 0.2% реализаций. При генерации изображения 100*100 такие события должны произойти в 20 пикселях, что не так уж и мало.
Есть хорошие алгоритмы: Преобразование Бокса-Мюллера, Преобразование Джорджа Марсальи
На Хабре есть хорошая статья на эту тему.
Все эти методы основаны на том, чтобы математическим образом перевести линейное распределение на интервале [0;1] в нормальное распределение.
Нейрон
Про нейросети написано очень много. Попробую не вдаваться в подробности, ограничившись лишь ссылками и основными моментами.
Нейросеть состоит из нейронов. Как устроен нейрон у человека досконально никто не знает, но есть много красивых моделей. На хабре было много интересных статей про нейроны: 1, 2, и.т.д.
В задачке я взял за основу простейшую схему нейронов, когда на вход нейрона подаётся последовательность сигналов, которая суммируется и прогоняется через функцию активации:
Где функция активации:
Что делает такой нейрон в такой модели и зачем ему функция активации?
Нейрон производит сравнение с неким паттерном, на который он обучается. А функция активации это триггер, который выносит решение о том, насколько паттерн совпал и производит нормировку решения. Почему-то мне зачастую кажется, что нейрон похож на транзистор, но это лирическое отступление:
Почему не делать функцию активации ступенькой? Тут много причин, но основная, про которую будет рассказано чуть ниже — особенность обучения, при котором требуется дифференцируемость функции нейрона. У приведённой функции активации очень хороший дифференциал:
Нейронная сеть
У нас есть сеть. Как решать задачу? Классический способ решения простой задачи, создать нейронную сеть такого вида:
В ней имеется входной сигнал, один скрытый слой (где каждый нейрон соединён со всеми входными элементами) и выходной нейрон. Обучение такой сети — это, по сути, настройка всех коэффициентов w и v.
Сделаем почти так, но проведя оптимизацию под задачку. Зачем обучать каждый нейрон скрытого слоя по каждому пикселю входного изображения? Сигнал максимум занимает три пикселя, а скорее всего даже два. Поэтому, соединим каждый нейрон скрытого слоя только с тремя соседними пикселями:
При такой конфигурации нейрон обучается на окрестность изображения, начиная работать локальным детектором. Массив обучаемых элементов для скрытого слоя (1..N) будет выглядеть как:
В качестве эксперимента я ввёл два выходных нейрона, но особого смысла, как окажется позднее, это не возымело.
Нейронные сети такого типа — одни из самых старых, используемых в работах. В последнее время всё чаще и чаще народ использует свёрточные сети. Про свёрточные сети уже неоднократно писали на хабре: 1, 2.
Свёрточная сеть — это такая сеть, которая ищет и запоминает существующие паттерны, универсальные для всего изображения. Обычно, чтобы продемонстрировать, что такое нейронная сеть, рисуют такое изображение:
Но когда начинаешь это пробовать закодить, мозг входит в ступор от того «как же это применить к реальности». А в реальности, приведённый выше пример нейросети, всего лишь одним действием переводится в свёрточную сеть. Для этого при обучении достаточно полагать, что элементы w11,…,w1N — это не разные элементы, а один и тот же элемент w1. Тогда, в результате обучения скрытого слоя будет найдено только три элемента w1,w2,w3, представляющие собой свёртку.
Правда, как оказалось, одной свёртки для решения задачи не хватает, нужно ввести вторую, но это просто сделать, увеличив количество элементов в скрытом слое до 1..2N, при этом элементы 1..N обучают первую свёртку, а элементы N..2N — вторую.
Обучение
Нейросеть просто нарисовать, но не так просто обучить. Когда это делаешь в первый раз мозг немножко выворачивает. Но, к счастью, в рунете есть две очень хорошие статьи, после которых всё становится ясно как день: 1, 2
Первая очень хорошо иллюстрирует логику и порядок обучения, во второй хорошо расписана математическая суть: откуда что получается из формул, как инициализируется нейронная сеть, как правильно считать и применять коэффициенты.
В целом метод обратного распространения ошибки состоит в следующем: подать на вход известный сигнал, распространить его на выходные нейроны, сравнить с требуемым результатом. Если имеется несовпадение, то величину ошибки домножить на вес связи и передать всем нейронам на прошлом слое. Когда все нейроны будут знать свою ошибку, тогда сдвинуть их коэффициенты обучения таким образом, чтобы ошибка уменьшилась.
Если что, то пугаться обучения не стоит. Например определение ошибки делается в одну строчку так:
public void ThetaForNode(Neuron t1, Neuron t2, int myname) { //Величина ошибки считается как обратная проекция нейрона BPThetta = t1.mass[myname] * t1.BPThetta + t2.mass[myname] * t2.BPThetta; }
А коррекция весов вот так:
public void CorrectWeight(double Speed, ref double[] massOut) { for (int i = 0; i < mass.Length; i++) { //Старый вес + скорость*ошибку*вход*результат*(1-результат) massOut[i] = massOut[i] + Speed * BPThetta * input[i] * RESULT * (1 - RESULT); } }
Результат
Для начала, как и обещали, посчитаем «а что должно быть». Пусть мы имеет соотношение SNR (сигнал/шум) = 3. В этом случае сигнал в 3 раза выше дисперсии шума. Давайте нарисуем вероятность того, что сигнал в пикселе принимает значение X:
На графике сразу отображены графики только для вероятностного распределения шума и график вероятностного распределения сигнала+шума в точке при отношении SNR=3. Для того, чтобы принять решение о нахождении сигнала нужно выбрать некий Xs, все значения больше него считать сигналом, все значения меньше — шумом. Нарисуем вероятность того, что мы приняли решение о ложной тревоге и о пропуске объекта (для красного графика это его интеграл, для синего «1-интеграл»):
Точка пересечения для таких графиков обычно называется EER (Equal Error Rate). В этой точке вероятность неправильного принятия решения равна вероятности потери объекта.
В рассматриваемой задачке у нас имеется 10 входных сигналов. Как для такой ситуации выбрать точку EER? Достаточно просто. Вероятность того, что при выбранном значении Xs не произошло ложной тревоги будет равна (интеграл по синему графику с первого рисунка):
Соответственно вероятность того, что в 10 пикселях не произошло ложной тревоги равна:
Вероятность того, что произошла хотя бы 1 ложная тревога равна 1-P. Отрисуем график 1-P и, рядом с ним график вероятности пропуска объекта (продублируем со второго графика):
Значит точка EER для сигнала и шума при SNR=3 находится в районе двойки и в ней EER≈0.2. А что даст нейросеть?
Видно, что нейронная сеть будет чуть хуже, чем задачка решённая на пальцах. Но, не всё так плохо. При математическом рассмотрении мы не учли несколько особенностей (например, сигнал может попадать не в центр пикселя). Не вдаваясь особо глубоко можно сказать, что это не сильно ухудшает статистику, но всё же ухудшает.
Если честно, меня такой результат ободрил. Сеть неплохо справляется с чисто математической задачкой.
Приложение 1
Всё же, моей основной задачкой было создать нейронную сеть с нуля и потыкать в неё палочкой. В этом разделе будет пара забавных гифок о поведении сети. Сеть получилась далеко не идеальной (думаю, что статью будут сопровождать разгромные комментарии профессионалов, ибо эта тематика популярна на Хабре), но достаточно много особенностей проектировки и написания я выучил в результате написания и отныне попробую не повторяться, так что лично я доволен.
Первая гифка для обычной сети. Верхняя полоска это входной сигнал во времени. SNR=10, явно виден сигнал. Нижние две полоски — вход на суммирование последнего нейрона. Видно, что сеть стабилизировала изображение и при включении-выключении сигнала изменяется только контраст входов последнего нейрона. Забавно, что при отсутствии сигнала изображение практически стационарно.
Вторая гифка — тоже самое для свёрточной сети. Количество входов на последний нейрон увеличивается в 2 раза. Но в принципе структура не изменяется.
Приложение 2
Все исходники лежат тут — github.com/ZlodeiBaal/NeuronNetwork. Написано на C#. Дллки у OpenCV большие, поэтому после скачивания нужно распаковать внутрь папки lib.rar. Либо скачать тут сразу проект, распаковывать ничего не надо — yadi.sk/d/lZn2ZJ_BWc4DB.
Код написан за 2 вечера где-то, так что далёк от промышленных стандартов, но вроде понятен (статью на хабр писал я дольше, надо признать).

