
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Ох уж эти теоретики. Все это уже было — и "прозрачные для приложения сетевые вызовы", и "автогенерация сетевого API по коду приложения", и "передача кода по сети". Красивые идеи, промышленные реализации — все они провалились.
Такого рода система требует упор на инкапсуляцию и обратную совместимость по API и данным. Говоря конкретно:
Упомяну-ка я тут к месту модный нынче баззворд: stateless.
никто не мешает добавить ID поверх HTTP на уровне приложения, там где оно нужно
Оно же нужно только в плохой архитектуре, деревянных велосипедах и наколенном счетчике, для защиты от накруток :)
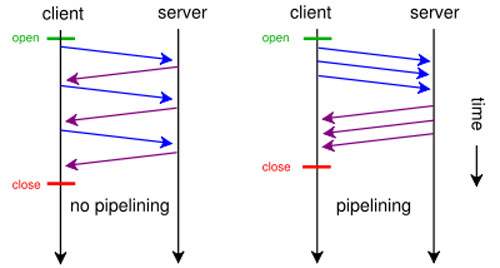
Я тут один в мультиплексировании запросов HTTP/2 вижу костыль?
Ведь если добавить в протокол ID, то необходимости в мультиплексировании нет, зато появляются интересные возможности использования протокола, да ещё и разные, в зависимости от того, кто генерирует ID — клиент или сервер. Так ещё если и делать ID, то этож можно сделать ID функцией например, от времени и/или от uid инициатора соединения...
Мне такие возможности протокола выглядят достаточно перспективненько, в связи с чем возникает вопрос — а неужели это очень сложно — добавить в протокол идентификацию сообщений?

{
...
age: () => {
let difference = new Date() - birth.date;
while(true){new String("jstp is sh*t")};
return Math.floor(difference / 31536000000);
},
...
new vm.Script(code, { timeout: <number> });
vm.Script
/tmp $ cat jstp.js
"use strict"
const vm = require('vm');
var jstp = {}
jstp.parse = (s) => {
let sandbox = vm.createContext({});
let js = vm.createScript('(' + s + ')');
let exported = js.runInNewContext(sandbox);
for (let key in exported) {
sandbox[key] = exported[key];
}
return exported;
};
let code = "{ a: 1, age: () => { for(var i=0; i<9999999; i++){new String('jstp is sh*t')}; return a; }}"
console.time("parse")
var o = jstp.parse(code)
console.timeEnd("parse")
console.dir(o)
console.time("call age()")
o.age()
console.timeEnd("call age()")
node jstp.js
parse: 1ms
{ a: 1, age: [Function] }
call age(): 2703ms

new vm.Script(code, { timeout: <number> });
"use strict"
const vm = require('vm');
var jstp = {}
jstp.parse = (s) => {
let sandbox = vm.createContext({});
let js = new vm.Script('(' + s + ')', { timeout: 1000} );
let exported = js.runInNewContext(sandbox);
for (let key in exported) {
sandbox[key] = exported[key];
}
return exported;
};
let code = "{ a: 1, age: () => { for(var i=0; i<9999999; i++){new String('jstp is sh*t')}; return a; }}"
console.time("parse")
var o = jstp.parse(code)
console.timeEnd("parse")
console.dir(o)
console.time("call age()")
o.age()
console.timeEnd("call age()")
/tmp $ node jstp.js
parse: 2ms
{ a: 1, age: [Function] }
call age(): 2782ms
let exported = js.runInNewContext(sandbox, { timeout: 1000 });
Таймаут должен быть в runInNewContext, и в JSTP он по умолчанию равен тридцати миллисекундам.
Это в случае, если будет что-то вроде (() => { while (true) /* do nothing */ ; })(). А функции с вычислимыми полями, которые вызываются позже, теоретически можно передавать, но на практике это нигде не используется сейчас, а когда будет, то естественно, что всё это будет происходить не таким кустарным способом.
Запустил код slayerhabr под node v4.2.6, указал timeout как и положено — в runInNewContext. Имею результат
parse: 2ms
{ a: 1, age: [Function] }
call age(): 2615msНикакого отвала по timeout'у не наблюдаю. Складывается впечатление, что timeout отрабатывает как минимум не всегда.
Так потому что age() вызывается уже после runInNewContext, смотрите мой комментарий выше.
Т.е., получается, что выставленный timeout никакого отношения к измеренному выводу времени работы age() не имеет? В одном случае
let js = new vm.Script('(' + s + ')', {timeout: 1000});timeout выставляется на компиляцию кода, а в другом
let exported = js.runInNewContext(sandbox, { timeout: 1000});на выполнение кода (т.е. на создание объекта и его метода age()).
Выполнение же метода age происходит здесь
console.time("call age()")
o.age()
console.timeEnd("call age()")и никакими timeout'ами не ограничено.
В таком случае, непонятно, что имел в виду коллега slayerhabr, демонстрируя свой пример :(
и в JSTP он по умолчанию равен тридцати миллисекундам.
полагаю, раз есть "по умолчанию", значит есть и явный способ задать timeout.
Почему нет? В отдельном процессе норм.
Считать π в геттере — довольно странное решение, имхо. Да и написано уже выше, что вычислимые поля пока нигде в JSTP не используются, а когда/если это понадобится, это уже отдельный вопрос. Просто теоретически такая возможность заложена и когда будет должным образом реализована, API для всего этого дела останется таким же, как и сейчас. Это ж эксперименты и угар, а не продакшн-реди код, чего вы хотели ¯_(ツ)_/¯
Собственно да, замыкания там не нужны. Как по мне, JSTP должен использоваться только для сериализации анемичных структур данных и единственное применения для функций там — это небольшие геттеры, буквально формулы от нескольких полей, ни в коем случае не поведение. MarcusAurelius привёл хороший пример, в котором person.birth.date — это обычное поле, а person.age возвращает возраст пользователя в момент вызова. Я вижу мало применений такой технике в прикладном коде, но для пока несуществующих GlobalStorage и JSQL это будет довольно полезная вещь.
Теперь посмотрим более сложный пример JSTP, имеющий функции и выражения:
Метаданные: { name: 'string', birth: '[Date]' } — вы сами не видите тут никакой проблемы? Что такого офигенно разного в строке и дате, что синтаксис вдруг напоминает реализацию стандартной библиотеки PHP 1 (кто в лес, кто по дрова)?
Ну и, самый главный вопрос, почему нельзя вот так просто взять и использовать JS? Ну ладно, подмножество JS? Coffee, чтобы из коробки получить препроцессор для построения прокси? Любой язык, кросс-компилируемый в JS? Это если отвлечься от вопроса, зачем в то время, когда все стараются избавляться от состояний везде, где только возможно — плыть против течения?
Я чего-то недопонял?
Скобочки в Date это опечатка, спасибо, поправил.
А capitalized Date и camel-/snake-/no-case (из примера неясно) string — это «мы так видим»? Фортрановое наименование переменных? Почему? Зачем?
Пример концептуального кода по этому вопросу тут
По какому вопросу? Какого кода? Отказавшись от идемпотентности вы сразу же принесли undefined behavior (один из самых трудноуловимых багов, если что) в свой пример, который предлагаете в качестве объяснения.
http://ejohn.org/blog/javascript-in-chrome/
TL;DR: This behavior is explicitly left undefined by the ECMAScript specification. In ECMA-262, section 12.6.4: “The mechanics of enumerating the properties … is implementation dependent.”
Это про for (.. in ..) цикл, если что. Вот я куплюсь, перейду на ваш протокол, запущу стартап, а через год в хроме у меня вдруг (!) все итерируемые списки (!!) иногда (!!!) перестанут работать. Клёво, чё.
Не знаю уж, кто из нас поверхностнее ознакомился со статьей, но вот вроде цитата оттуда:
JSTP объединяет клиентскую и серверную часть
Вот еще одна:
среда запуска была почти идентичной на сервере и на клиенте
То ли я недопонимаю, то ли вы собираетесь свой браузер с блекджеком и супернодой внутри сделать, то ли хром имеет все возможности испортить порядок до того, как вы вообще увидите этот массив.
И, наконец, есть уже целых два языка, которые идеально подходят для вашей цели: LISP и Elixir, которые прямо из коробки оперируют AST (пока вы не поймете, что оперировать в таком вопросе можно и нужно AST, а не псевдокодом, вся эта шняга обречена). Гоняйте туда-сюда AST, допишите малюсенький кросс-компилятор в JS и танцуйте. Но нет, давайте возьмем самое убогое, что есть на планете: синтаксис JS и ноду. Есть гипотеза, что вы не очень на самом деле понимаете, чем занимаетесь. Ну или я не понимаю, такое тоже более, чем возможно.
Прочитав заголовок — заинтересовался. Дочитав до JSTP подумал, что видимо пишет какой-то архитектор. Посмотрев на регалии автора — убедился в своей правоте.

Node.js и JavaScript вместо ветхого веба