Недавно Google предоставил бесплатный доступ к своим тензорным процессорам (tensor processing unit, TPU) на облачной платформе для машинного обучения Colaboratory. Тензорный процессор — это специализированная интегральная схема (ASIC), разработанная Google для задач машинного обучения с использованием библиотеки TensorFlow. Я решил попробовать обучить на TPU сверточную сеть на Keras, которая распознает объекты на изображениях CIFAR-10. Полный код решения можно посмотреть и запустить в ноутбуке.

Фото cloud.google.com
На Хабре уже писали о том, как устроены TPU (здесь, здесь и здесь), а также почему TPU хорошо подходят для обучения нейронных сетей. Поэтому я не буду углубляться в детали архитектуры TPU, а рассмотрю только те особенности, которые нужно учитывать при обучении нейонных сетей.
Сейчас есть три поколения тензорных процессоров, производительность TPU последнего, третьего поколения составляет 420 TFlops (триллионов операций с плавающей точкой в секунду), он содержит 128 ГБ памяти High Bandwidth Memory. Однако на Colaboratory доступны только TPU второго поколения, у которых 180 TFlops производительности и 64 ГБ памяти. В дальнейшем я буду рассматривать именно эти TPU.
Тензорный процессор состоит из четырех чипов, каждый из которых содержит два ядра, всего в TPU восемь ядер. Обучение на TPU ведется параллельно на всех ядрах с помощью репликации: на каждом ядре работает копия графа TensorFlow с одной восьмой объема данных.
Основа тензорного процессора — матричное устройство (matrix unit, MXU). Оно использует хитрую структуру данных систолический массив размером 128х128 для эффективной реализации операций с матрицами. Поэтому, чтобы наиболее полно использовать ресурсы оборудования TPU, размерность мини-выборки или признаков должна быть кратна 128 (источник). Также из-за особенностей системы памяти TPU желательно, чтобы размерность мини-выборки и признаков была кратна 8.
Colaboratory — это облачная платформа от Google для продвижения технологий машинного обучения. На ней можно получить бесплатно виртуальную машину с установленными популярными библиотеками TensorFlow, Keras, sklearn, pandas и т.п. Самое удобное, что на Colaboratory можно запускать ноутбуки, похожие на Jupyter. Ноутбуки сохраняются на Google Drive, можно их распространять и даже организовать совместную работу. Вот так выглядит ноутбук на Colaboratory (картинка кликабельна):
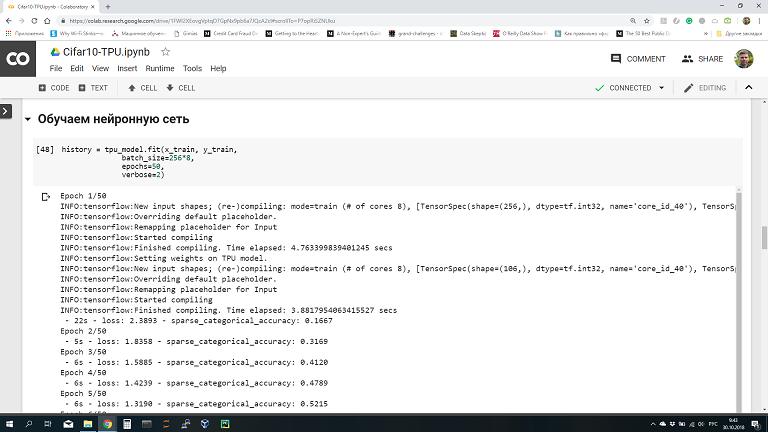
Вы пишите код в браузере в ноутбуке, он выполняется на виртуальной машине в облаке Google. Машина выдается вам на 12 часов, после этого она останавливается. Однако ничто не мешает вам запустить еще одну виртуальную машину и работать еще 12 часов. Только имейте в виду, что после остановки виртуальной машины все данные с нее удаляются. Поэтому не забывайте сохранять нужные данные на свой компьютер или Google Drive, а после перезапуска виртуальной машины загружать заново.
Подробные инструкции по работе на платформе Colaboratory есть здесь, здесь и здесь.
По умолчанию Colaboratory не использует ускорителей вычислений GPU или TPU. Подключить их можно в меню Runtime -> Change runtime type -> Hardware accelerator. В появившемся списке выбираем «TPU»:
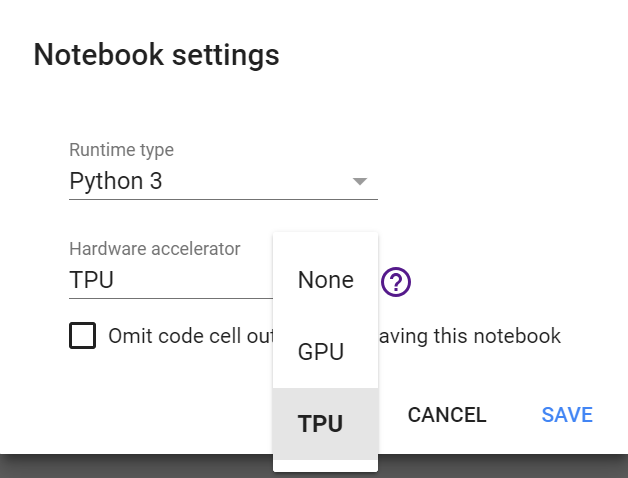
После выбора типа ускорителя виртуальная машина, к которой подключается ноутбук Colaboratory, перезапустится и станет доступен TPU.
Если вы загружали на виртуальную машину какие-то данные, то в процессе перезапуска они будут удалены. Придется загружать данные заново.
В качестве примера попробуем обучить на TPU нейронную сеть на Keras, которая распознает изображения из набора данных CIFAR-10. Это популярный набор данных, содержащий небольшие изображения объектов 10 классов: самолет, автомобиль, птица, кот, олень, собака, лягушка, лошадь, корабль и грузовик. Классы не пересекаются, каждый объект на картинке принадлежит только одному классу.
Загружаем набор данных CIFAR-10 средствами Keras:
Для создания нейронной сети я завел отдельную функцию. Мы будем создавать одинаковую модель два раза: первый вариант модели для TPU, на котором будем обучать, а второй для CPU, где будем распознавать объекты.
Пока на TPU нельзя использовать оптимизаторы Keras, поэтому при компиляции модели указывается оптимизатор из TensorFlow.
Создаем модель Keras для CPU, которую на следующем этапе преобразуем в модель для TPU:
Модели на Keras и TensorFlow можно обучать на GPU без каких-либо изменений. На TPU пока так делать нельзя, поэтому придется преобразовать созданную нами модель в модель для TPU.
Для начала нужно узнать, где находится доступный нам TPU. На платформе Colaboratory это можно сделать следующей командой:
В моем случае адрес TPU оказался таким —
Теперь можно получить модель для TPU с помощью функции
В первой строке включено логирование на уровне Info. Вот что в логе конвертации модели:
Можно видеть, что найден TPU по указанному нами ранее адресу, в нем 8 ядер. Также мы видим предупреждение, что
Модель для TPU можно обучать обычным для Keras образом с помощью вызова метода
Какие здесь особенности. Мы помним, что для эффективного использования TPU размер мини-выборки должен быть кратен 128. Кроме того, на каждом ядре TPU выполняется обучение с использованием одной восьмой всех данных в мини-выборке. Поэтому размер мини-выборки при обучении задаем в 128*8, получается по 128 картинок для каждого ядра TPU. Можно использовать больший размер, например, 256 или 512, тогда производительность будет выше.
В моем случае на обучение одной эпохи требуется в среднем 6 с.
Качество обучения на 50 эпохе:
Доля верных ответов на данных для обучения составила 90,06%. Проверяем качество на тестовых данных используя TPU:
Теперь сохраним веса обученной модели:
TensorFlow выдаст нам сообщение, что веса переданы с TPU на CPU:
Следует отметить, что веса обученной сети сохранились на диск виртуальной машины Colaboratory. Когда виртуальная машина будет остановлена, то все данные с нее сотрутся. Если вы не хотите терять обученные веса, то сохраните их на свой компьютер:
Теперь давайте попробуем использовать модель, обученную на TPU, для того, чтобы распознавать объекты на изображениях с помощью CPU. Для этого создаем модель заново и загружаем в нее обученные на TPU веса:
Модель готова к использования на центральном процессоре. Давайте попробуем распознать с ее помощью одно из изображений тестового набора CIFAR-10:

Картинка маленькая, но можно понять, что это самолет. Запускаем распознавание:
Получаем список выходных значений нейронов, почти все из них близки к нулю, кроме первого значения, которое соответствует самолету.
Распознавание прошло успешно!
Удалось продемонстрировать работоспособность TPU на платформе Colaboratory, его вполне можно применять для обучения нейронных сетей на Keras. Однако набор данных CIFAR-10 слишком маленький, его недостаточно для полной загрузки ресурсов TPU. Ускорение по сравнению с GPU получилось небольшим (можете проверить сами выбрав в качеству ускорителя GPU вместо TPU и переобучив модель заново).
На Хабре есть статья, в которой измеряли производительность TPU и GPU V100 на обучении сети ResNet-50. На этой задаче TPU показал такую же производительность, как и четыре GPU V100. Приятно, что Google дает такой мощный ускоритель обучения нейронных сетей бесплатно!
Видео с демонстрацией обучения нейросети Keras на TPU.
Фото cloud.google.com
Тензорные процессоры
На Хабре уже писали о том, как устроены TPU (здесь, здесь и здесь), а также почему TPU хорошо подходят для обучения нейронных сетей. Поэтому я не буду углубляться в детали архитектуры TPU, а рассмотрю только те особенности, которые нужно учитывать при обучении нейонных сетей.
Сейчас есть три поколения тензорных процессоров, производительность TPU последнего, третьего поколения составляет 420 TFlops (триллионов операций с плавающей точкой в секунду), он содержит 128 ГБ памяти High Bandwidth Memory. Однако на Colaboratory доступны только TPU второго поколения, у которых 180 TFlops производительности и 64 ГБ памяти. В дальнейшем я буду рассматривать именно эти TPU.
Тензорный процессор состоит из четырех чипов, каждый из которых содержит два ядра, всего в TPU восемь ядер. Обучение на TPU ведется параллельно на всех ядрах с помощью репликации: на каждом ядре работает копия графа TensorFlow с одной восьмой объема данных.
Основа тензорного процессора — матричное устройство (matrix unit, MXU). Оно использует хитрую структуру данных систолический массив размером 128х128 для эффективной реализации операций с матрицами. Поэтому, чтобы наиболее полно использовать ресурсы оборудования TPU, размерность мини-выборки или признаков должна быть кратна 128 (источник). Также из-за особенностей системы памяти TPU желательно, чтобы размерность мини-выборки и признаков была кратна 8.
Платформа Colaboratory
Colaboratory — это облачная платформа от Google для продвижения технологий машинного обучения. На ней можно получить бесплатно виртуальную машину с установленными популярными библиотеками TensorFlow, Keras, sklearn, pandas и т.п. Самое удобное, что на Colaboratory можно запускать ноутбуки, похожие на Jupyter. Ноутбуки сохраняются на Google Drive, можно их распространять и даже организовать совместную работу. Вот так выглядит ноутбук на Colaboratory (картинка кликабельна):
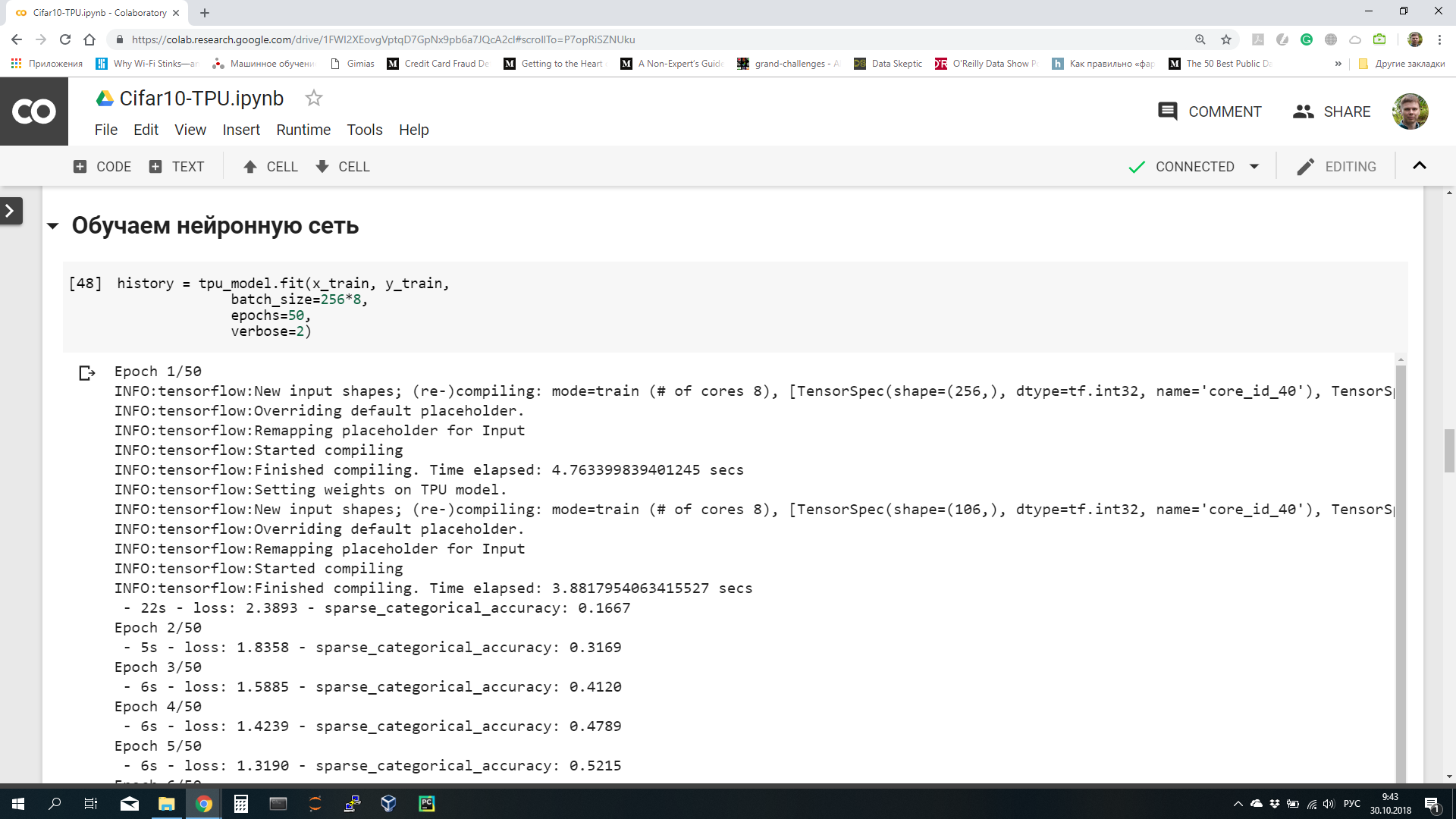
Вы пишите код в браузере в ноутбуке, он выполняется на виртуальной машине в облаке Google. Машина выдается вам на 12 часов, после этого она останавливается. Однако ничто не мешает вам запустить еще одну виртуальную машину и работать еще 12 часов. Только имейте в виду, что после остановки виртуальной машины все данные с нее удаляются. Поэтому не забывайте сохранять нужные данные на свой компьютер или Google Drive, а после перезапуска виртуальной машины загружать заново.
Подробные инструкции по работе на платформе Colaboratory есть здесь, здесь и здесь.
Подключаем тензорный процессор на Colaboratory
По умолчанию Colaboratory не использует ускорителей вычислений GPU или TPU. Подключить их можно в меню Runtime -> Change runtime type -> Hardware accelerator. В появившемся списке выбираем «TPU»:
После выбора типа ускорителя виртуальная машина, к которой подключается ноутбук Colaboratory, перезапустится и станет доступен TPU.
Если вы загружали на виртуальную машину какие-то данные, то в процессе перезапуска они будут удалены. Придется загружать данные заново.
Нейронная сеть на Keras для распознавания CIFAR-10
В качестве примера попробуем обучить на TPU нейронную сеть на Keras, которая распознает изображения из набора данных CIFAR-10. Это популярный набор данных, содержащий небольшие изображения объектов 10 классов: самолет, автомобиль, птица, кот, олень, собака, лягушка, лошадь, корабль и грузовик. Классы не пересекаются, каждый объект на картинке принадлежит только одному классу.
Загружаем набор данных CIFAR-10 средствами Keras:
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
Для создания нейронной сети я завел отдельную функцию. Мы будем создавать одинаковую модель два раза: первый вариант модели для TPU, на котором будем обучать, а второй для CPU, где будем распознавать объекты.
def create_model(): input_layer = Input(shape=(32, 32, 3), dtype=tf.float32, name='Input') x = BatchNormalization()(input_layer) x = Conv2D(32, (3, 3), padding='same', activation='relu')(x) x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D(pool_size=(2, 2))(x) x = Dropout(0.25)(x) x = BatchNormalization()(x) x = Conv2D(64, (3, 3), padding='same', activation='relu')(x) x = Conv2D(64, (3, 3), activation='relu')(x) x = MaxPooling2D(pool_size=(2, 2))(x) x = Dropout(0.25)(x) x = Flatten()(x) x = Dense(512, activation='relu')(x) x = Dropout(0.5)(x) output_layer = Dense(10, activation='softmax')(x) model = Model(inputs=[input_layer], outputs=[output_layer]) model.compile( optimizer=tf.train.AdamOptimizer(0.001), loss=tf.keras.losses.sparse_categorical_crossentropy, metrics=['sparse_categorical_accuracy']) return model
Пока на TPU нельзя использовать оптимизаторы Keras, поэтому при компиляции модели указывается оптимизатор из TensorFlow.
Создаем модель Keras для CPU, которую на следующем этапе преобразуем в модель для TPU:
cpu_model = create_model()
Конвертируем нейросеть на Keras в модель для TPU
Модели на Keras и TensorFlow можно обучать на GPU без каких-либо изменений. На TPU пока так делать нельзя, поэтому придется преобразовать созданную нами модель в модель для TPU.
Для начала нужно узнать, где находится доступный нам TPU. На платформе Colaboratory это можно сделать следующей командой:
TPU_WORKER = 'grpc://' + os.environ['COLAB_TPU_ADDR']
В моем случае адрес TPU оказался таким —
grpc://10.102.233.146:8470. Адреса отличались для разных запусков.Теперь можно получить модель для TPU с помощью функции
keras_to_tpu_model:tf.logging.set_verbosity(tf.logging.INFO) tpu_model = tf.contrib.tpu.keras_to_tpu_model( cpu_model, strategy=tf.contrib.tpu.TPUDistributionStrategy( tf.contrib.cluster_resolver.TPUClusterResolver(TPU_WORKER)))
В первой строке включено логирование на уровне Info. Вот что в логе конвертации модели:
INFO:tensorflow:Querying Tensorflow master (b'grpc://10.102.233.146:8470') for TPU system metadata.
INFO:tensorflow:Found TPU system:
INFO:tensorflow:*** Num TPU Cores: 8
INFO:tensorflow:*** Num TPU Workers: 1
INFO:tensorflow:*** Num TPU Cores Per Worker: 8
...
WARNING:tensorflow:tpu_model (from tensorflow.contrib.tpu.python.tpu.keras_support) is experimental and may change or be removed at any time, and without warning.Можно видеть, что найден TPU по указанному нами ранее адресу, в нем 8 ядер. Также мы видим предупреждение, что
tpu_model является экспериментальной и может быть изменена или удалена в любое время. Надеюсь, что со временем можно будет обучать модели Keras напрямую на TPU без всякого преобразования. Обучаем модель на TPU
Модель для TPU можно обучать обычным для Keras образом с помощью вызова метода
fit:history = tpu_model.fit(x_train, y_train, batch_size=128*8, epochs=50, verbose=2)
Какие здесь особенности. Мы помним, что для эффективного использования TPU размер мини-выборки должен быть кратен 128. Кроме того, на каждом ядре TPU выполняется обучение с использованием одной восьмой всех данных в мини-выборке. Поэтому размер мини-выборки при обучении задаем в 128*8, получается по 128 картинок для каждого ядра TPU. Можно использовать больший размер, например, 256 или 512, тогда производительность будет выше.
В моем случае на обучение одной эпохи требуется в среднем 6 с.
Качество обучения на 50 эпохе:
Epoch 50/50
- 6s - loss: 0.2727 - sparse_categorical_accuracy: 0.9006Доля верных ответов на данных для обучения составила 90,06%. Проверяем качество на тестовых данных используя TPU:
scores = tpu_model.evaluate(x_test, y_test, verbose=0, batch_size=batch_size * 8) print("Доля верных ответов на тестовых данных: %.2f%%" % (scores[1]*100))
Доля верных ответов на тестовых данных: 80.79%Теперь сохраним веса обученной модели:
tpu_model.save_weights("cifar10_model.h5")
TensorFlow выдаст нам сообщение, что веса переданы с TPU на CPU:
INFO:tensorflow:Copying TPU weights to the CPUСледует отметить, что веса обученной сети сохранились на диск виртуальной машины Colaboratory. Когда виртуальная машина будет остановлена, то все данные с нее сотрутся. Если вы не хотите терять обученные веса, то сохраните их на свой компьютер:
from google.colab import files files.download("cifar10_model.h5")
Распознаем объекты на CPU
Теперь давайте попробуем использовать модель, обученную на TPU, для того, чтобы распознавать объекты на изображениях с помощью CPU. Для этого создаем модель заново и загружаем в нее обученные на TPU веса:
model = create_model() model.load_weights("cifar10_model.h5")
Модель готова к использования на центральном процессоре. Давайте попробуем распознать с ее помощью одно из изображений тестового набора CIFAR-10:
index=111 plt.imshow(toimage(x_test[index])) plt.show()
Картинка маленькая, но можно понять, что это самолет. Запускаем распознавание:
# Названия классов из набора данных CIFAR-10 classes=['самолет', 'автомобиль', 'птица', 'кот', 'олень', 'собака', 'лягушка', 'лошадь', 'корабль', 'грузовик'] x = x_test[index] # Добавляем размерность, т.к. Keras распознает массив изображений x = np.expand_dims(x, axis=0) # Запускаем распознавание prediction = model.predict(x) # Печатаем значения на выходе из сети print(prediction) # Печатаем название класса объекта prediction = np.argmax(prediction) print(classes[prediction])
Получаем список выходных значений нейронов, почти все из них близки к нулю, кроме первого значения, которое соответствует самолету.
[[9.81738389e-01 2.91262069e-07 1.82225723e-02 9.78524668e-07
5.89265142e-07 6.76223244e-10 1.03252004e-10 9.23009047e-09
3.71878523e-05 3.16599618e-08]]
самолетРаспознавание прошло успешно!
Итоги
Удалось продемонстрировать работоспособность TPU на платформе Colaboratory, его вполне можно применять для обучения нейронных сетей на Keras. Однако набор данных CIFAR-10 слишком маленький, его недостаточно для полной загрузки ресурсов TPU. Ускорение по сравнению с GPU получилось небольшим (можете проверить сами выбрав в качеству ускорителя GPU вместо TPU и переобучив модель заново).
На Хабре есть статья, в которой измеряли производительность TPU и GPU V100 на обучении сети ResNet-50. На этой задаче TPU показал такую же производительность, как и четыре GPU V100. Приятно, что Google дает такой мощный ускоритель обучения нейронных сетей бесплатно!
Видео с демонстрацией обучения нейросети Keras на TPU.

