Утром, не сделав и глотка кофе, открываешь почту и видишь баг репорты по тому, что вполне себе нормально работало, не сбоило и особо не беспокоило. Идей с ходу ноль, подозреваемых нет, больших изменений в коде тоже не было — нужно лезть в логи.
А туда ты не ходил так давно, что раздало файл с логами аж до 100 мб. или до 500 мб. Черт! А может и до 10 Гб (*). И лежат драгоценные улики где-то там среди 10 737 418 240 байтов, что надо срочно пробежать, дабы выяснить, что ж вообще происходит, меж тем как кофе уже остывает.
А может к рапорту прицепом шёл и архив с двумя сотнями файлами (скажем по 5 Мб каждый) разбитых логов и надо их как-то клеить, а потом смотреть, копать и думать.
Знакомо?
В общем все мы так или иначе сталкиваемся с необходимостью анализа «следов жизнедеятельности» наших творений и хорошо если файл весит пару Мб, потому как открыть лог в 1 Гб блокнотом, да ещё и попытаться поиск сделать — занятие весьма сомнительное.
Под катом поведаю об одном инструменте, не имеющим лимитов (**) по размерности открываемых файлов, зато обладающим весьма шустрым поиском.
А ещё приглашу к разработке присоединиться.
И да, будет много интересных картинок.
Итак, казалось бы тривиальная задача, открыть логи и поискать, может порой упереться в банальный размер файла. Мелочь то можно открыть чем угодно, да хоть бы тем же блокнотом или notepad++, а на маках и линуксах, так вообще порой проще бросить cat`ом все в консоль и сделать поиск.
Кроме всего прочего можно использовать упомянутый notepad++, atom, logExpert, sublime, bare vim, bbedit, glogg и etc. Скажу сразу, гигабайта 2 откроют не все, а некоторые из выживших увы сломаются на поиске. Да и из всех выше приведённых, пожалуй лишь atom воистину кроссплатформенный, а так хочется иметь что-то одно, когда вынужден работать на нескольких платформах параллельно. А уж сколько некоторые съедят RAM для обработки хотя бы пары сотен мегабайт логов — это отдельная история.
Вот собственно поэтому имеем тулзу chipmunk, запиленную было под узкие задачи, но быстро выросшую в комплексное решение по анализу логов. Ничего другого chipmunk не умеет, его задачи сводятся к простому:
Ну давайте обо всем по порядку.
Chipmunk ничего не грузит в оперативную память, кроме того куска логов, что виден на экране (ну ещё немного буферизации, но это мелочь). Гуляя по файлу, chipmunk, читает кусок файла (соответствующий позиции скролинга) и только лишь его и подгружает в память. Благодаря этому аппетиты по отношению к RAM вполне вразумительные и не колеблются, а первый «экран» с содержанием файла показывается немедленно (хотя фоном индексация будет продолжаться).
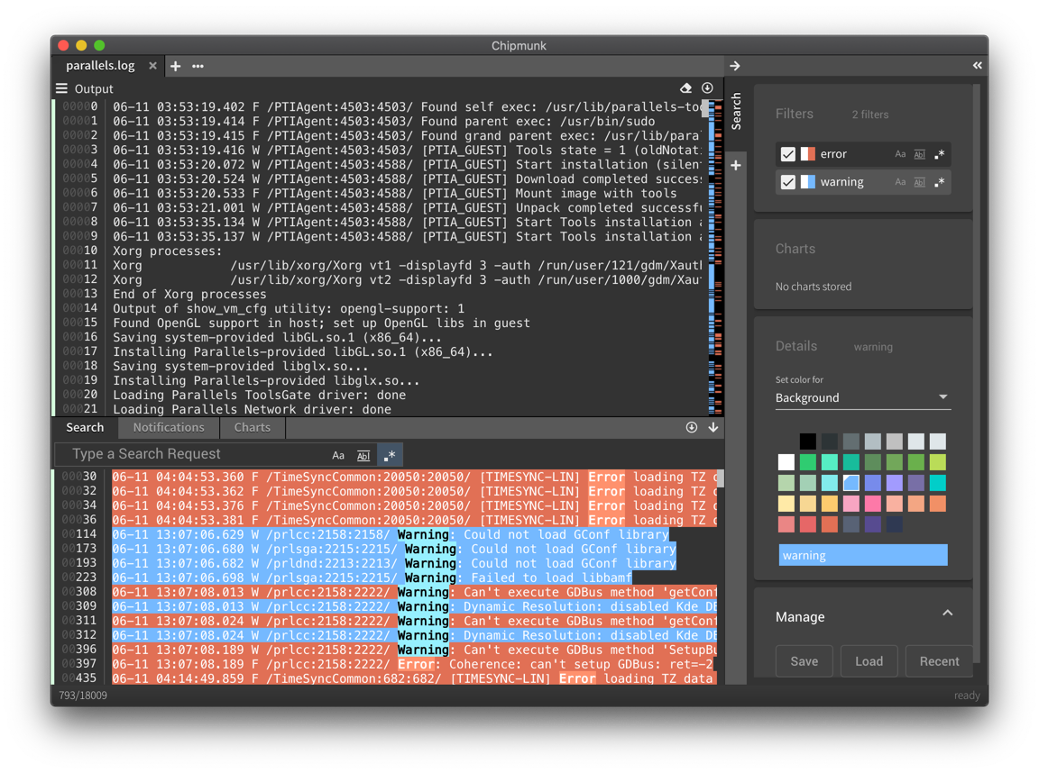
Имеется менеджер поисковых запросов, где можно:
Можно, например, посмотреть по файлу частоту совпадений (чем выше столбик, тем больше совпадений во фрагменте файла).
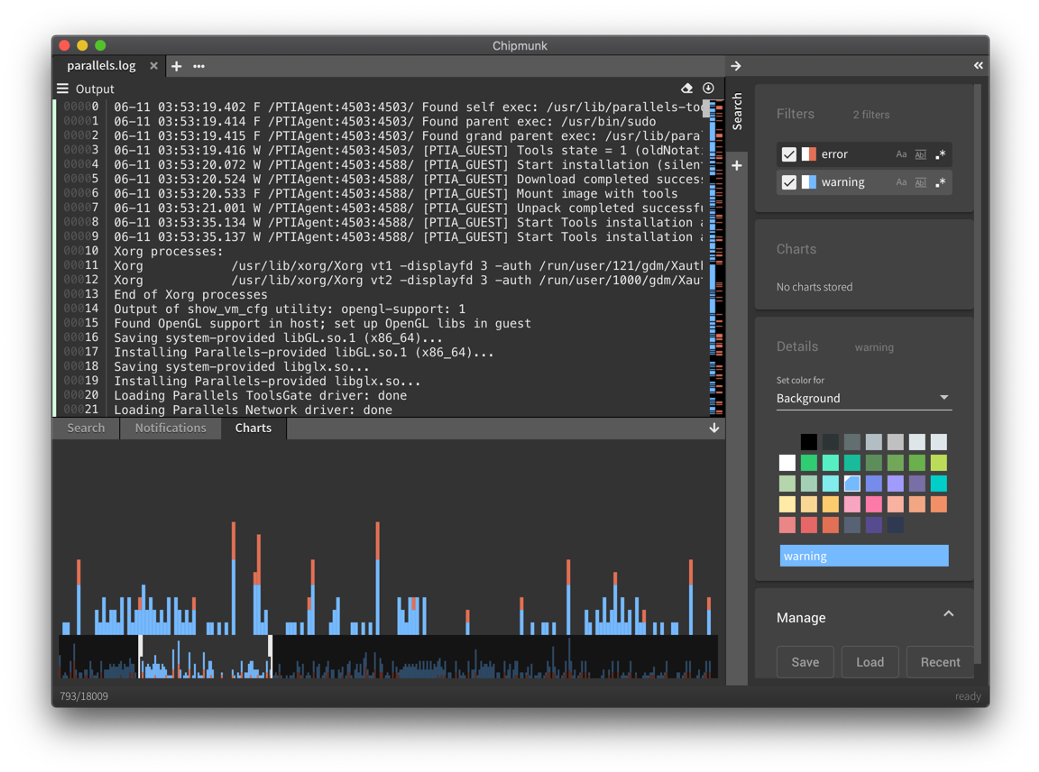
А можно указать группу в регулярном выражении и получить красивый график (в приведённом примере используется выражение CPU usage:\s+(\d+\.\d+)). И теперь вы видите, где потребление CPU было аномальным и какой кусок логов следует изучить внимательнее.

Кроме поиска самого по себе, отдельные строки логов можно кидать в закладки, которые всегда будут представлены в окне результатов поиска. Это весьма удобно, когда увидел что-то важное среди пары миллионов строк и не хочешь терять это из виду.
Для решения задач, связанных с несколькими файлами chipmunk может слепить файлы в один (например по дате последнего изменения в файле). Все что нужно:

Как результат мы получим в окне последовательность из всех выбранных файлов.
Если же требуется более сложный механизм комбинирования логов (например, если у вас имеются логи с разных девайсов/источников), то можно воспользоваться функцией merge, которая определить формат метки времени для каждого файла и выведет логи в хронологическом порядке.
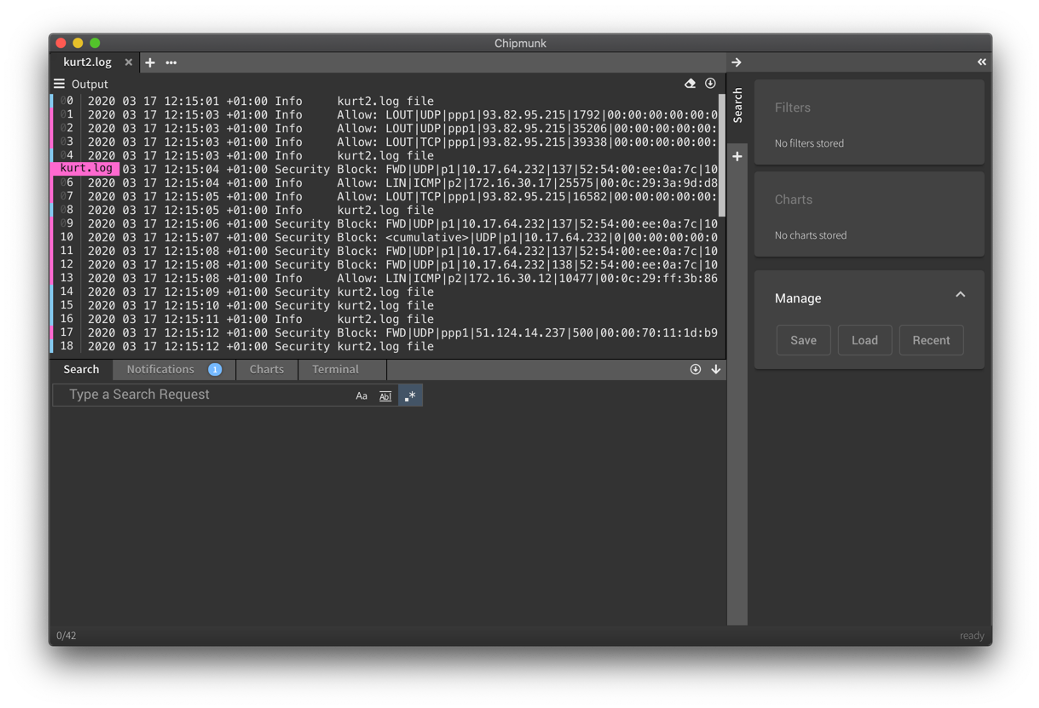
Обратите внимание на цветовые метки слева от вывода — это метки файлов. То есть вы видите не вывод одного файла за другим (concatenation), а отсортированный по времени вывод из всех файлов (merging).
Если вы когда-либо сталкивались с DLT, то вы знаете, какая это боль использовать DLTViewer. Хорошая новость в том, что chipmunk представляет собой альтернативу для открытия и анализа DLT файлов. Кроме того он поддерживает и подключение DLT потоку.
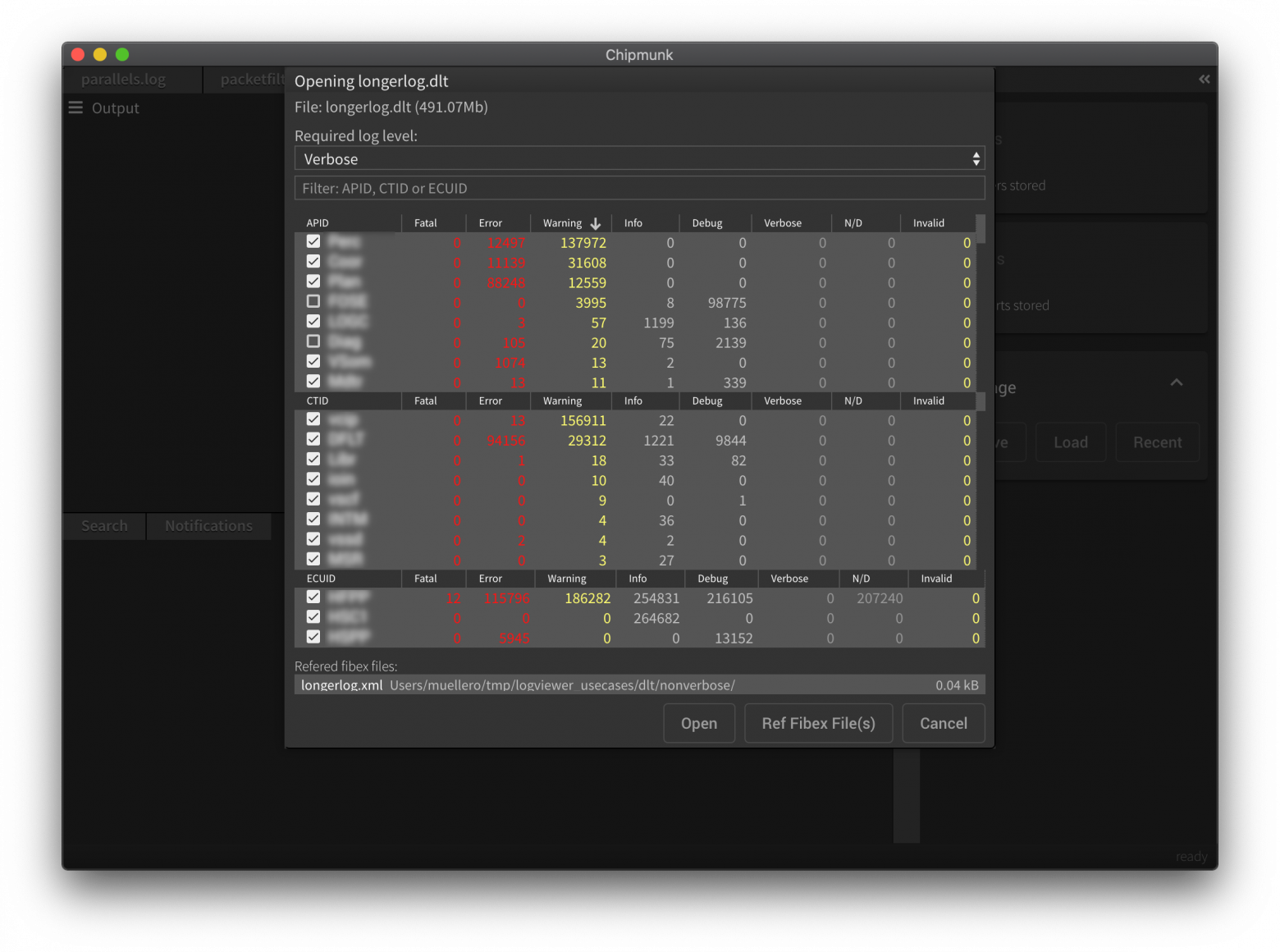
При открытии же DLT файла вы сразу увидите сводку по файлу, включающую перечень всех компонентов, что удобно если вас интересует какое-то конкретное APID, а не весь лог целиком.
Из коробки с chipmunk идёт простенький плагин «Commands», который позволят запустить любую консольную команду и получать вывод в chipmunk с возможностью поиска по этому выводу. Естественно, если у вас есть активный поиск (например, сохранённый фильтр), то данные результатов будут обновляться по мере обновления потока от вашей консольной команды.
Их, пока, мало. Вот прямо правда мало. Публичных всего 5 (тех что в открытом доступе и доступны для менеджера плагинов), не публичных, я даже не знаю, может пара десятков.
Написать свой плагин очень просто (оговорюсь, для простой задачи просто).
Например, если в ваших логах встречаются сообщения представленные в виде байтов, а вам хотелось бы их видеть сразу в читаемом виде (то есть декодированными); можно легко запилить плагин, который будет как ввод получать выделенный пользователем фрагмент логов, а декодированный вывод кидать в панель. А может и вообще на лету декодировать и на экран выводить уже вразумительный текст, а не A5 FF 13 EE … etc.
В целом есть два типа расширений: первые работают с рендером, то есть позволяют изменять представление вывода: хотите столбики — пожалуйста; хочется что-то на лету декодировать — можно; есть желание воткнуть графику (например иконки) — не ясно зачем оно вам, но можно.
Другой тип плагинов (и он более интересен), те что могут поставлять данные (создавать потоки). Например, хотите видеть вывод с serial-порта? Не проблема: делам новый npm проект, включаем в него любимую либу по работе с портами, добавляем немного UI по вкусу и вот уже ваш плагин может кидать данные в chipmunk.
Для удобства и первых свиданий, как водится в приличных семьях, имеется quickstart репозиторий с парой тройкой примеров.
Если заинтересует, дайте знать в коментах — я сделаю отдельный пост-гайд по созданию и публикации плагинов (кстати для публикации никакой регистрации не требуется).
Вот, пожалуй, и все. Я не хочу делать из этого поста ни рекламного буклета, ни манула для пользователей — поэтому так кратко с минимумом букв. Моя цель — поделиться с вами ещё одним инструментом по работе с логами, который может оказаться годным подспорьем для решения многих задач.
Проект полностью опенсоурсный и открыт для вашего участия, любого вашего участия. Хотите увидеть поддержку чего-то этакого? Создавайте issue и выбирайте «Feature request». Нашли баг? Будем счастливы увидеть от вас bug-report с кратким (но достаточным) описанием проблемы. Английский язык приветствуется, но русский не возбраняется.
Ну и конечно, поставив заветную звёздочку на github, вы уже через несколько секунд почувствуете лёгкое тепло и улучшение настроения от нашей благодарности за одобрение того, что мы делаем. Для вас клик — для нас обратная связь и воодушевление.
Спасибо.
А туда ты не ходил так давно, что раздало файл с логами аж до 100 мб. или до 500 мб. Черт! А может и до 10 Гб (*). И лежат драгоценные улики где-то там среди 10 737 418 240 байтов, что надо срочно пробежать, дабы выяснить, что ж вообще происходит, меж тем как кофе уже остывает.
А может к рапорту прицепом шёл и архив с двумя сотнями файлами (скажем по 5 Мб каждый) разбитых логов и надо их как-то клеить, а потом смотреть, копать и думать.
Знакомо?
В общем все мы так или иначе сталкиваемся с необходимостью анализа «следов жизнедеятельности» наших творений и хорошо если файл весит пару Мб, потому как открыть лог в 1 Гб блокнотом, да ещё и попытаться поиск сделать — занятие весьма сомнительное.
Под катом поведаю об одном инструменте, не имеющим лимитов (**) по размерности открываемых файлов, зато обладающим весьма шустрым поиском.
А ещё приглашу к разработке присоединиться.
И да, будет много интересных картинок.
Итак, казалось бы тривиальная задача, открыть логи и поискать, может порой упереться в банальный размер файла. Мелочь то можно открыть чем угодно, да хоть бы тем же блокнотом или notepad++, а на маках и линуксах, так вообще порой проще бросить cat`ом все в консоль и сделать поиск.
Кроме всего прочего можно использовать упомянутый notepad++, atom, logExpert, sublime, bare vim, bbedit, glogg и etc. Скажу сразу, гигабайта 2 откроют не все, а некоторые из выживших увы сломаются на поиске. Да и из всех выше приведённых, пожалуй лишь atom воистину кроссплатформенный, а так хочется иметь что-то одно, когда вынужден работать на нескольких платформах параллельно. А уж сколько некоторые съедят RAM для обработки хотя бы пары сотен мегабайт логов — это отдельная история.
Вот собственно поэтому имеем тулзу chipmunk, запиленную было под узкие задачи, но быстро выросшую в комплексное решение по анализу логов. Ничего другого chipmunk не умеет, его задачи сводятся к простому:
- открывать логи, не парясь над размером файла;
- искать так, что б не ждать, а видеть результат сразу;
- помнить все ваши поиски и бережно хранить их до востребования;
- помогать вам визуально воспринимать информацию;
- вести себя скромно по отношению к RAM;
- решать и иные более узкие задачи, но всегда сводящиеся к анализу логов.
Ну давайте обо всем по порядку.
Ресурсы
Chipmunk ничего не грузит в оперативную память, кроме того куска логов, что виден на экране (ну ещё немного буферизации, но это мелочь). Гуляя по файлу, chipmunk, читает кусок файла (соответствующий позиции скролинга) и только лишь его и подгружает в память. Благодаря этому аппетиты по отношению к RAM вполне вразумительные и не колеблются, а первый «экран» с содержанием файла показывается немедленно (хотя фоном индексация будет продолжаться).
Удобство и визуализация
Имеется менеджер поисковых запросов, где можно:
- назначить цвета фильтрам (что облегчает восприятие данных)
- сохранить коллекцию фильтров в файл, дабы всегда иметь под рукой готовый паттерн поиска.
Можно, например, посмотреть по файлу частоту совпадений (чем выше столбик, тем больше совпадений во фрагменте файла).
А можно указать группу в регулярном выражении и получить красивый график (в приведённом примере используется выражение CPU usage:\s+(\d+\.\d+)). И теперь вы видите, где потребление CPU было аномальным и какой кусок логов следует изучить внимательнее.
Кроме поиска самого по себе, отдельные строки логов можно кидать в закладки, которые всегда будут представлены в окне результатов поиска. Это весьма удобно, когда увидел что-то важное среди пары миллионов строк и не хочешь терять это из виду.
Комбинирование файлов
Для решения задач, связанных с несколькими файлами chipmunk может слепить файлы в один (например по дате последнего изменения в файле). Все что нужно:
- кинуть группу файлов в окно chipmunk
- если нужно отсортировать файлы, как душе угодно
- в дополнение можно сделать поиск по всем файлам и, например, исключить те файлы, что не имеют совпадений по слову «error» (ну а зачем нам лезть туда, где итак все спокойно?)
Как результат мы получим в окне последовательность из всех выбранных файлов.
Если же требуется более сложный механизм комбинирования логов (например, если у вас имеются логи с разных девайсов/источников), то можно воспользоваться функцией merge, которая определить формат метки времени для каждого файла и выведет логи в хронологическом порядке.
Обратите внимание на цветовые метки слева от вывода — это метки файлов. То есть вы видите не вывод одного файла за другим (concatenation), а отсортированный по времени вывод из всех файлов (merging).
Особые штучки
Если вы когда-либо сталкивались с DLT, то вы знаете, какая это боль использовать DLTViewer. Хорошая новость в том, что chipmunk представляет собой альтернативу для открытия и анализа DLT файлов. Кроме того он поддерживает и подключение DLT потоку.
При открытии же DLT файла вы сразу увидите сводку по файлу, включающую перечень всех компонентов, что удобно если вас интересует какое-то конкретное APID, а не весь лог целиком.
Кстати, о потоках
Из коробки с chipmunk идёт простенький плагин «Commands», который позволят запустить любую консольную команду и получать вывод в chipmunk с возможностью поиска по этому выводу. Естественно, если у вас есть активный поиск (например, сохранённый фильтр), то данные результатов будут обновляться по мере обновления потока от вашей консольной команды.
Ах, да, плагины
Их, пока, мало. Вот прямо правда мало. Публичных всего 5 (тех что в открытом доступе и доступны для менеджера плагинов), не публичных, я даже не знаю, может пара десятков.
Написать свой плагин очень просто (оговорюсь, для простой задачи просто).
Например, если в ваших логах встречаются сообщения представленные в виде байтов, а вам хотелось бы их видеть сразу в читаемом виде (то есть декодированными); можно легко запилить плагин, который будет как ввод получать выделенный пользователем фрагмент логов, а декодированный вывод кидать в панель. А может и вообще на лету декодировать и на экран выводить уже вразумительный текст, а не A5 FF 13 EE … etc.
В целом есть два типа расширений: первые работают с рендером, то есть позволяют изменять представление вывода: хотите столбики — пожалуйста; хочется что-то на лету декодировать — можно; есть желание воткнуть графику (например иконки) — не ясно зачем оно вам, но можно.
Другой тип плагинов (и он более интересен), те что могут поставлять данные (создавать потоки). Например, хотите видеть вывод с serial-порта? Не проблема: делам новый npm проект, включаем в него любимую либу по работе с портами, добавляем немного UI по вкусу и вот уже ваш плагин может кидать данные в chipmunk.
Для удобства и первых свиданий, как водится в приличных семьях, имеется quickstart репозиторий с парой тройкой примеров.
Если заинтересует, дайте знать в коментах — я сделаю отдельный пост-гайд по созданию и публикации плагинов (кстати для публикации никакой регистрации не требуется).
Вместо заключения
Вот, пожалуй, и все. Я не хочу делать из этого поста ни рекламного буклета, ни манула для пользователей — поэтому так кратко с минимумом букв. Моя цель — поделиться с вами ещё одним инструментом по работе с логами, который может оказаться годным подспорьем для решения многих задач.
Проект полностью опенсоурсный и открыт для вашего участия, любого вашего участия. Хотите увидеть поддержку чего-то этакого? Создавайте issue и выбирайте «Feature request». Нашли баг? Будем счастливы увидеть от вас bug-report с кратким (но достаточным) описанием проблемы. Английский язык приветствуется, но русский не возбраняется.
Ну и конечно, поставив заветную звёздочку на github, вы уже через несколько секунд почувствуете лёгкое тепло и улучшение настроения от нашей благодарности за одобрение того, что мы делаем. Для вас клик — для нас обратная связь и воодушевление.
Спасибо.
Другие ссылки
- код
- quickstart для разработки плагинов
- документация
Уточнение
(*) на счёт логов, раздутых до неприличия (1 Гб <). Не стоит спешить с выводами, что ПО не должно генерировать столько логов. Должно. Для некоторых ситуаций файл в 10-20 Гб, вполне себе нормальное явление. В embedded это встречается сплошь и рядом.
(**), конечно, безлимитного ничего не бывает. И chipmunk все же ограничен размером свободного места на вашем диске. Кроме того, так как chipmunk не хранит данные в RAM, а читает их с диска, то и работать он будет заметно лучше с SSD.
(**), конечно, безлимитного ничего не бывает. И chipmunk все же ограничен размером свободного места на вашем диске. Кроме того, так как chipmunk не хранит данные в RAM, а читает их с диска, то и работать он будет заметно лучше с SSD.

