
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
А если именно программировать – то алгебра уровня старших классов школы нужна как минимум (а это немало; я в свою очередь класса с 7-го не в то русло энергию направлял и в алгебре страшные провалы, о чём сейчас порой очень жалею).
Конкретно алгебра не особо нужна, всем нужна пожалуй только алгебра логики. Остальное же от задач зависит — кому-то нужен весь матан, кому-то только матрицы, а кому-то ничего.
Я сам ни разу не программист и вкатиться не пытаюсь, но мне показалось странным что автор не понимает вот этого:
выражение типа N=N+1 и более сложные уравнения меня загоняли в легкий ступор
Это не уравнение. Это команда машине увеличить переменную N на единицу. То есть конкретно этот пример может работать как счетчик.
Мне кажется, что автору статьи сейчас нужен обычный школьный репетитор по информатике, который за месяц занятий покажет основы на примере бейсика или паскаля, и если даже после этого луч света не появится — тогда точно можно забыть про программирование как про страшный сон, а если что-то будет получаться — уже думать что делать дальше.
Основы программирования на паскале изучаются в школе. Думаю, обычный школьный репетитор по информатике не сможет помочь с решением задачек на java.
По моим школьным воспоминаниям, в паскале более или менее легко разобраться. Соответственно, можно быстрее попробовать себя в более осознанном программировании, чем "Hello, World!"
Да, сам недавно узнал. В мое-то время учились основам программирования на черепашке и паскале
Видел у К.Ю.Полякова робота для браузера с возможностью выбора языка из Python, JS, PHP, Dart, Lua. Ну и там еще прикручен редактор blockly для визуального конструирования.
Школьная алгебра нужна для того чтобы научить:
1) Точно выражать свои мысли (чтобы задача вообще была решена)
2) Оформлять их в строгой нотации (чтобы код скомпилировался)
3) Преобразовывать выражения из одной формы в другую без потери смысла (чтобы рефакторить)
Если человек не научился на алгебре раскрывать скобки у многочленов, то у него будут проблемы и в программировании.
Подробнее эту тему я раскрывал в своей статье Вот зачем нужна школьная алгебра
Конечно дорогу осилит идущий и полюбить можно после свадьбы...
А где там статистика может быть нужна?
Мне тоже так казалось до того как я попробовал обучить программированию своего брата. Выяснилось, что кроме умения читать книжки (о программировании) нужно ещё уметь мыслить как программист. А это навык, типа умения быстро бегать или боксировать, просто так, из воздуха не берётся. Несмотря на все наши попытки понять что такое массив и как его обрабатывать не получилось. Проблемы была в том, что братишка не мог в голове собрать как из мелких шагов на каждом этапе возникает целое решение.
Несмотря на все наши попытки понять что такое массив и как его обрабатывать не получилось.
Математика один из путей, допускаю, что работа историка по исследованию документов, поиску противоречий и построению непротиворечивой картины событий тоже тренирует нужный навык. У гипотетического двоечника проблемы могут возникнуть не с реактом и не с тем, чтобы прочитать кучу документации и туториалов. Ему может быть сложно понять что делает цикл for, как составить даже тривиальный алгоритм типа «переверни список», как соотносится между собой тело цикла и конечный результат работы.
Без хорошей школьной математики в программировании всегда будет. Всё-таки хорошая математическая база даёт преимущества в восприятии, написании, мышлении. В общем без математики никуда
Точно подмечено про магию. Так же и в математике сначала просто надо принять, почему на ноль делить нельзя например, а потом уже потихоньку начинаешь понимать почему нельзя. И вполне можно остановиться на уровне где деление на ноль просто магия которую нужно принять. В программировании также, есть решения и технологии которые просто работают и можно пользовать их не вникая как там все внутри устроено.
а почему не -∞?
Почему сразу врали? Все зависит от набора аксиом, задающих основу. А набор аксиом может зависеть от раздела математики или от выбранной математической модели.
В арифметике на ноль делить по жизни нельзя. Когда в школе говорят о невозможности деления на ноль, внезапно, проходят не математику вообще, а именно арифметику. И потому на самом деле никак нельзя.
Когда мы выходим за рамки арифметики, то получаем несколько иной базис (как минимум появляется понятие бесконечности), и уже тогда появляется возможность делить на ноль.
С параллельными прямыми такая же неувязка. У Евклида они не пересекаются. Пока мы в рамках евклидовой геометрии, это железобетонная истина.
А кое у кого очень даже пересекаются, но это уже совсем не евклидова геометрия.
А кое у кого очень даже пересекаются
А кое у кого очень даже пересекаются, но это уже совсем не евклидова геометрия.
Нет же, параллельные прямые не пересекаются по определению. Ни в какой из геометрий.
Нет же, параллельные прямые не пересекаются по определению. Ни в какой из геометрий.
Пес его знает.
Естественно, что далеко не в каждой неевклидовой геометрии имеются пересекающиеся параллельные прямые, но как-то случайно наткнулся на какую-то математическую модель, описывающую что-то, мне неведомое.
Зацепился сознанием за это и запомнил именно из-за параллельных прямых.
Во-первых, они вводились там как взаимно перпендикулярные третьей прямой (и назывались при этом именно параллельными).
Во-вторых, они не пересекались ни в какой из взятых на прямой точек, но однозначно пересекались в бесконечности (именно так, пересекались в бесконечности, оно там через предел как-то выводилось).
Кстати, еще немного о делении на ноль.
За пределами арифметики не везде можно делить на ноль.
Более того, кое-где в математике вообще деление не предусмотрено как класс.
Так что математика — она такая. Какой надо базис — такой и введут. И получат пространство с нужными свойствами. И будут люди, что не в теме, ужасаться и путаться, поскольку термины в этом пространстве будут знакомыми, но означать будут сущности с совершенно другим поведением (хотя и близкие "по духу").
Параллельность при этом остается синонимом непересекаемости.
Не обязательно. Скажем, параллельность по Лобачевскому — это частный случай непересекаемости. Через точку, не лежащую на прямой, можно провести бесконечно много прямых, не пересекающих данную, две из которых будут параллельными данной по Лобачевскому.
Причём, если пространство Лобачевского "распрямить" — то всё это множество непересекающих данную прямых "схлопнется" в одну прямую, параллельную данной и по Евклиду и по Лобачевскому.
там интересно получается
пусть у нас 2 продольных и n поперечных заборов. при любом n максимум площади будет при длине продольного забора равной 25. при n=2, это будет квадрат, но в задаче n=3
наилучшее соотношение площадь\периметр имеет квадрат, после круга, естественно
Ложное утверждение. Например, правильный шестиугольник лучше квадрата.
Дальше надо максимизировать величину х*(50 — 1,5*х), она же 50*х — 1,5 *х^2.
для полной картины понимания Computer Science, мне необходимо будет заново учить алгебру, а затем и ВысшМат
Неужели чтобы стать программистом без технической базы, требуется так много времени?
Меня конечно вдохновляют статьи в интернете, где люди пишут, что за 1,5 года стали Java developer-ом и уехали в Германию, Канаду, США, однако оценивая свои печальный опыт я не уверен что такое возможно.
1С это ведь по сути VisualBasic с русским синтаксисом. Так что вполне язык программирования и навык качает. Пересесть с процедурного программированмя на ООП, не так и сложно. Особенно если практика ООП была в универе.
Вообще то там есть ООП, просто объекты фиксированы)
Такие выражения как: пределы, математическое мышление, экстремум, производные, многочлены и т.д. для меня оказались как речь на языке племени Майя.
.Для 99% программ это не нужно.
.Паскаль в 2020 году это за гранью разумного
Почему? Вполне симпатичный язык для обучения.
И полный по Тьюрингу естественно.
с я развлекаюсь с разным ретро, вот там Паскаль
Какая радость для начинающего от возможности обратится к массиву пятью различными способами? Или написать инкрементацию тремя?
С Сями можно потратить полчасика на рассказ про git
Если речь про обучение программированию с нуля в школе, то никак вы за полчасика с гит не разберётесь.

Пффф, вы не видели глубин изобретательности, до которых могут дойти люди, поставившие себе четкую цель не использовать контроль версий.
Вы переоцениваете возможности обычных учеников. Я раньше на курсах всегда уделял час, чтобы рассказать основные команды гита. Более того, я даже сделал методичку с картинками, чтобы можно было с ее помощью дома все повторить.
Но так у меня сбежало 2 ученика. В обратной связи оставили "я даже не могу понять как сохранять проект, куда мне изучать программирование?".
Поэтому я гит даю только тем, кто умненький и не раньше второго занятия.
Язык для обучения должен быть неудобен. Он должен постоянно заставлять выкручивать мозги. Он обязан содержать минимум инструкций. Он должен научить человека программировать что угодно при помощи говна и палок.
Вы принципиально путаете
1) обучение на профессионального хакера (в реймондовском смысле),
2) обучение на программиста вообще,
3) обучение на не-программиста с навыком автоматизации с помощью компьютера.
Ваш подход годится для (1) и изредка для (2), в то время как на них вообще статистически не нужно тратить усилия — сами обучатся — а основные методики надо нарабатывать для (3), потому что критична массовая компьютерная неграмотность.
Сравните write/writeln/read/readln, доступными из коробки в паскале.
Сравнил.
Почему write(a, b, c), где a, b, c типа real, и в то же время write(out, a, b, c), где a, b, c типа file? Как мне различить эти конструкции? Что будет, если я вызову write(a, b, c, out)?
В C было сразу понятно — есть printf с stdout, а есть fprintf с конкретным файлом (и можно тоже указать stdout).
Почему надо было писать write(a:15:3), что это за конструкция? Почему тут особый случай и почему я не могу сделать свою функцию с таким же? (Реально хотелось, как раз как переходник для вывода результатов.)
Почему в конце программы "end.", а не "end;"?
Почему перед else нельзя ставить точку с запятой, а перед end — можно, но она ни на что не влияет?
Почему var перед программой (процедурой, функцией) и почему один на все переменные?
Почему в списке формальных параметров var вдруг начинает значить передачу по указателю (или in-out, не помню точно)? Почему не отдельное слово?
Почему такое резкое отличие между procedure и function?
Зачем возможность вызова функции или процедуры просто по их имени, без скобок? (Сравнивая с современными, Паскаль ни капельки ни ФП, чтобы это можно было оправдать.)
И ещё два десятка подобных недоумённых вопросов, но, думаю, уже достаточно.
это запредельное количество синтаксических конструкций на старте, смысл которых невозможно объяснить человеку, который только-только начинает изучать язык.
Вот для меня как учившего оба в конце 80-х — в Паскале было больше подобных непонятных конструкций, которые надо было зазубрить без понимания их причины, чем в C, и они были каждая сама по себе непонятнее.
Сам же принцип "надо добавить определённые заклинания" был понятен с первого упоминания. Люди же здороваются и прощаются, так и тут...
Вы просто натягиваете опыт C на Паскаль, из-за чего и возникает недопонимание. Забудьте C, и тогда Паскаль станет простым и логичным языком.
Почему write(a, b, c), где a, b, c типа real, и в то же время write(out, a, b, c), где a, b, c типа file? Как мне различить эти конструкции? Что будет, если я вызову write(a, b, c, out)?
Только в отличие от C, где вы в printf можете запихнуть вообще всё, что угодно, выстрелив себе в ногу, в Паскале всё строго типизировано. Вы никак не сможете передать аргументы типа file в качестве параметров, кроме первого.
Почему надо было писать write(a:15:3), что это за конструкция? Почему тут особый случай и почему я не могу сделать свою функцию с таким же?
Потому что Write в Паскале — это compile-time конструкция. Так решили авторы языка. И если бы в Паскале был C-style printf, то он бы тоже был compile-time с проверкой типов аргументов при компиляции и без возможности генерации строки форматирования в рантайме.
Почему в конце программы "end.", а не "end;"? Почему перед else нельзя ставить точку с запятой, а перед end — можно, но она ни на что не влияет?
Потому что ; в C — это признак конца выражения, а в Паскале — разделитель между выражениями в блоке. Оба подхода имеют право на жизнь.
Почему var перед программой (процедурой, функцией) и почему один на все переменные?
Не забывайте, что Паскаль — язык для обучения азам. В С можно себе выстрелить в ногу, объявив scoped-based переменную с тем же именем, что и внешняя переменная. А ещё в C можно случайно перепутать вызов функции, объявление функции и объявление переменной.
Почему в списке формальных параметров var вдруг начинает значить передачу по указателю (или in-out, не помню точно)? Почему не отдельное слово?
А хрен его знает. Видимо, чтобы не плодить ключевые слова.
Почему такое резкое отличие между procedure и function?
Скорее, больше бесит, что функция не может вернуть record. И вызов без скобок тоже бесит, да.
Забудьте C, и тогда Паскаль станет простым и логичным языком.
Сколько ещё и каких нормальных языков я должен забыть, чтобы кривости Паскаля стали "простыми и логичными"?
Большинство языков таких тараканов не держат. Хотя можно сравнить этот write/writeln, например, с C++, где на шаблонах ещё и не такое можно построить (например, у парсеров на Spirit несколько разнотипных аргументов шаблонов в любом порядке)… но там юзер уже заранее готов к подобным шуткам, в отличие от тех, кто вообще впервые учится Паскалю.
(Заметьте, я сказал и про плюсы Паскаля. Но они не сыграли в его пользу, чтобы он выжил.)
Вы никак не сможете передать аргументы типа file в качестве параметров, кроме первого.
Почему собственно? Может, я хочу, чтобы напечатало тип аргумента и основные свойства как файла (имя, режим открытия и т.п.)?
Но главное таки не это, а то, что:
1) Эти якобы функции на самом деле не функции, а похожий механизм, но разбираемый компилятором,
2) Я не могу сделать такое же своими средствами, это нерасширяемый хак компилятора.
Если бы их не оформляли в виде "типа функций", это было бы честнее. Если бы дали аналогичное средство самим, это было бы полезнее и для учёбы, и для продуктина.
Потому что Write в Паскале — это compile-time конструкция. Так решили авторы языка. И если бы в Паскале был C-style printf, то он бы тоже был compile-time с проверкой типов аргументов при компиляции и без возможности генерации строки форматирования в рантайме.
Ну так где оно? Почему недоступно? Почему я не могу сделать свой write?
Ах, "язык для обучения"… ну так язык, который пригоден только для обучения, не будет в итоге вообще использоваться для обучения.
Видимо, поэтому в Delphi в итоге сделали впараллель C-подобный подход.
Потому что; в C — это признак конца выражения, а в Паскале — разделитель между выражениями в блоке. Оба подхода имеют право на жизнь.
С таким подходом любая глупость "имеет право на жизнь", хотя бы в качестве легаси.
Но если мы думаем о побочных эффектах решения, то вариант с разделителем имеет их сильно больше, и это от языка не зависит.
То же самое относится к необязательности блоковых скобок.
Скорее, больше бесит, что функция не может вернуть record. И вызов без скобок тоже бесит, да.
Тип возврата — да, проблема (в C это тоже полу-костыль).

Каждая буковка, каждый символ должны стоять строго на своем месте.
Ну судя по строке 37 (3700, если по разметке) и дальше, не всё так жёстко? Или тут две разные разметки?
Я писал на стандартном (фиксированного формата) Фортране, и не сказал бы, что это какой-то существенный ужас. В RPG меня больше напрягает сама логика языка — что и как делается — а не его конкретное представление. Не хочу выворачивать мышление на эту логику, для моих задач не окупится :)
Давайте начнём хотя бы с того, что Паскаль появился на пару лет раньше С. И для языка, которому исполнилось уже 50 лет и который дошёл до наших дней практически в неизменном виде — это отличный результат.
Конечно, современные языки избавились от многих проблем, но вот выделить среди них хороший язык, который хорошо подходит для обучения программированию, я затрудняюсь. У всех имеются различные проблемы.
И для языка, которому исполнилось уже 50 лет и который дошёл до наших дней практически в неизменном виде — это отличный результат.
В практическом применении (которое надо с микроскопом искать) остался разве что Delphi, который очень изменился по сравнению с Паскалем 1970-го года. Поэтому нету ни "неизменного вида", ни "отличного результата": результат ужасный — язык вымер, причём завалив всю цепочку потомков (разве что Ada выжила на госзаказах).
Конечно, современные языки избавились от многих проблем, но вот выделить среди них хороший язык, который хорошо подходит для обучения программированию, я затрудняюсь. У всех имеются различные проблемы.
По сравнению с языком, который для этого уже не менее 20 лет не подходит, они все относительно неплохи. Python в этой роли разве что ленивый не предлагал. Я вот ещё смотрю на Swift.
Так совсем хорошо выйдет и с парой Си/Питон уже любой язык будет знаком и похож на что-то уже выученное.
Да они ведь во многом похожи как языки, на базовом уровне. Те же переменные, if/for/etc, функции, etc — разница в чуть другом стиле синтаксиса и явном указании типа в Си. Паскаль и иже с ним туда же.
Если говорить о разнообразии, то есть множество используемых языков, которые намного сильнее отличаются — из относительно популярных например скала/f#/лиспы/хаскель.
А вот нужно ли разнообразие при обучении программированию — зависит, думаю, от уровня. Не вижу особой проблемы начинать с паскаля в школе, кто заинтересуется изучит и другие.
Да они же во многом похожи как языки, на базовом уровне. Те же переменные, if/for/etc, функции, etc — разница в чуть другом стиле синтаксиса и явном указании типа в Си. Паскаль и иже с ним туда же.
из относительно популярных например скала/f#/лиспы/хаскель.
Хотя бы полгода Коммон Лиспа курсе на четвертом это хорошо и полезно. Но не раньше. Человек перед изучение должен уметь код писать. Обычный и простой код.
Мы тут про азы. На чем рассказывать про циклы с переменными и на чем первый пузырек писать.
Есть какие-то исследования, что условный питон эффективнее для начального обучения программированию, чем условный лисп? По-моему это совершенно неочевидно. Конечно, если речь не идёт о курсах типа "дата саенс за 21 день".
Ну а как вы себе это представляете? Берём студентов и начинаем экспериментировать с их жизнью, а если провал — ну ничего, новые через год придут?
хм. а почему нет-то? вы предлагаете ровно так же экспериментировать со всеми студентами, обучая их только по одному варианту (ведь неизвестно же, что он лучший).
Если же продвигать идею «а давайте обучать на языке X; пусть он непопулярен, зато проще для обучения», то надо сперва доказать, что он и вправду проще, потому что иначе в этой идее совсем смысла нет.
хм, я бы говорил не про «проще для изучения», а про «лучше для обучения».
При выборе языка программирования в школе/университете самый простой критерий — это смотреть, какие языки по факту востребованы на рынке, а из них уже выбирать объективно наименее навороченные.
в раннем возрасте — не вижу ничего плохого в специальных языках для обучения.
читать дети тоже не по «Войне и миру» учатся, для этого придумали азбуки и красочные книжки с минимумом текста.
в университете — наверное, да, тут подразумевается, что начальные навыки программирования уже есть, можно выбирать из востребованных на рынке (и почему менее навороченные?).
впрочем, не вижу ничего плохого в изучении какого-то академического языка в университете (разумеется, знакомство с «реальными» языками при этом обязательно). впрочем, многие проекты, начинавшиеся как академические, со временем находят себе применение и в «гражданской жизни».
про «лучше для обучения».
не вижу ничего плохого в специальных языках для обучения.
Осталось выяснить, как понять, какой же лучше.Если брать «программирование вообще», то максимально отвязанный от железа: лисп, тикль, питон или ещё что-то выразительное, но очень медленное.
ненамного хуже «любого другого языка», и при этом очень популярен на практике.Это да. Но именно как учебный мне больше нравится лисп, просто потому, что на нём в силу единства данных и кода можно сделать вообще всё, и это будет достаточно лаконично. Своя система типов? Своё ООП с плюшками? ФП? Рекомендательные системы? Логическое программирование? Всё это можно реализовать в сотни-тысячи строк поверх ванильного лиспа. Тикль, внебрачный сын плюсов и лиспа, кстати, всё это же поддерживает, просто там синтаксис ещё более мутный. А вот как в питоне, например, перейти от ООП на классах к ООП на прототипах я вообще не пойму.
Типов нет же.
Что, сегодня отменили? Вчера ещё были.
PS: да, я понимаю. Но давайте строже в деталях. Динамичность как раз достаточно мало мешает учебным задачам.
Скиньте, plz. Уложу в коллекцию.
Вообще, не то, чтобы я не был согласен — я как раз считаю, что расставлять статичность по максимуму (кроме явно огороженных мест) оно полезно всегда. Но чувство — не доказательство.
Даже в вашей цитате последней фразой написано, что использование термина "динамическая типизация" является стандартом :) И по факту непонимания (почти?) никогда не создаёт.
Привязывание более строгой терминологии, чтобы она покрывала все имеющиеся случаи, кажется весьма затруднительным. Например, по приведённой цитате не особо понятно, что означает "tractable syntactic method" или "static approximation [of behaviour]". Как к этому относиться в случае языка, который позволяет тьюринг-полные вычисления на уровне типов/во время компиляции? А если язык типа C# вроде бы статически типизированный (кроме "dynamic"), но с помощью reflection во время выполнения можно много чего нагородить?
так что для неподготовленного читателя тут написано «n равно n + 1».
Добавлю, что частое заблуждение в связи с присваиванием в виде "a = b + c" что "a" это нечто, что вы бы называли функцией. Это нечто не хранит значение, а вычисляется в момент использования, используя значения из "b" и "c". Думаю это заблуждение как раз идет из школьной алгебры или физики.
Поэтому "a = a + 1" — конструкция, которая всегда вызывает вопросы "а так разве можно?".
Это заблуждение возникает поголовно у всех, с кем я занимался с "честного" нуля.
Ага. Вот что делает следующая конструкция?
if (n = n + 1) { ... }Несмотря на то, что побочное действие оператора присваивания бывает иногда полезно и удобно, оно является источником ошибок.
Какие критерии?
Можно начать рассматривать со Swift или Go.
OK. Против Swift есть претензии?
Я ещё смотрю на старых зверей типа Java и на всякие Julia.
с вкраплениями магии
В последние годы появилось достаточно много "быстрых выразительных" языков для разных сфер применения. К предыдущему комментатору добавлю julia.
Я не смогу это доказать, но подозреваю, что благодаря JIT компилятору многие языки на платформе Java вполне дадут питону фору в производительности
То, что это так — к гадалке не ходи — в Питоне слишком много тратится на постоянную проверку типов, лукапы по словарям методов и т.п. Так что ускорение раза в 5-10 от их исключения вполне можно предсказать. Но вот точные цифры будут катастрофически зависеть от задачи. Мои текущие это в основном общение со сложными объектами с развесистыми атрибутами… на них, может, больше 5 и не выйдет. На математике, понятно, и 1000 может быть (но её и так всю переложили на numpy с продолжателями).
читать дети тоже не по «Войне и миру» учатся, для этого придумали азбуки и красочные книжки с минимумом текста.Но читать дети учатся все-таки сразу именно на реальном языке, а не придумывают для этого специально искусственный. А азбуки и красочные книжки — это аналог «Hello World» и подобных простых учебных программ, но не другого языка.
Ну а как вы себе это представляете? Берём студентов и начинаем экспериментировать с их жизнью, а если провал — ну ничего, новые через год придут?
Так иного варианта-то нет. Так и экспериментируют, только (почти) никому не говоря, что это эксперимент. Если у вас есть маховик времени из саги про ГП — можно попробовать часть студентов учить впараллель. Но ведь его нет?
Просто начинают с относительно небольшой группы и пытаются по ней оценивать, стоит ли расширять эксперимент… (в лучшем случае)
А если вы, условно, флагман типа MIT, там можно попытаться, но тоже не знаю, кому там подобные телодвижения интересны
хорошо, что не все рассуждают так, как вы
Люди туда работать идут не ради того, чтобы выяснять, первокурсник лучше освоит лисп или питон.
нет, конечно, они приходят с убеждением «XXX лучше», спорят друг с другом, пробуют доказать верность своего подхода, пишут по этому поводу научные работы…
что такого рода научная работа не представляется мне особенно интересной.
А она и будет составлять 1% от того, что делается в нормальном университете — но она должна выполняться, иначе там так и будут преподавать Паскаль вместе с программированием для ЕС ЭВМ на перфолентах.
ЕС-ЭВМ, по вашему
Я как раз хорошо отличаю, где ЕС ЭВМ, а где современный zSeries.
программистов не хватает. ;-)
Платить не пробовали, простите за резкость?
За деньги даже на RPG будут писать без особого плача.
Так платят… Но все умчались в стильно-модно-молодёжно, аджайл-кубернетис-девопс и прочие смузи. А серьёзные машины это типа кровавое легаси
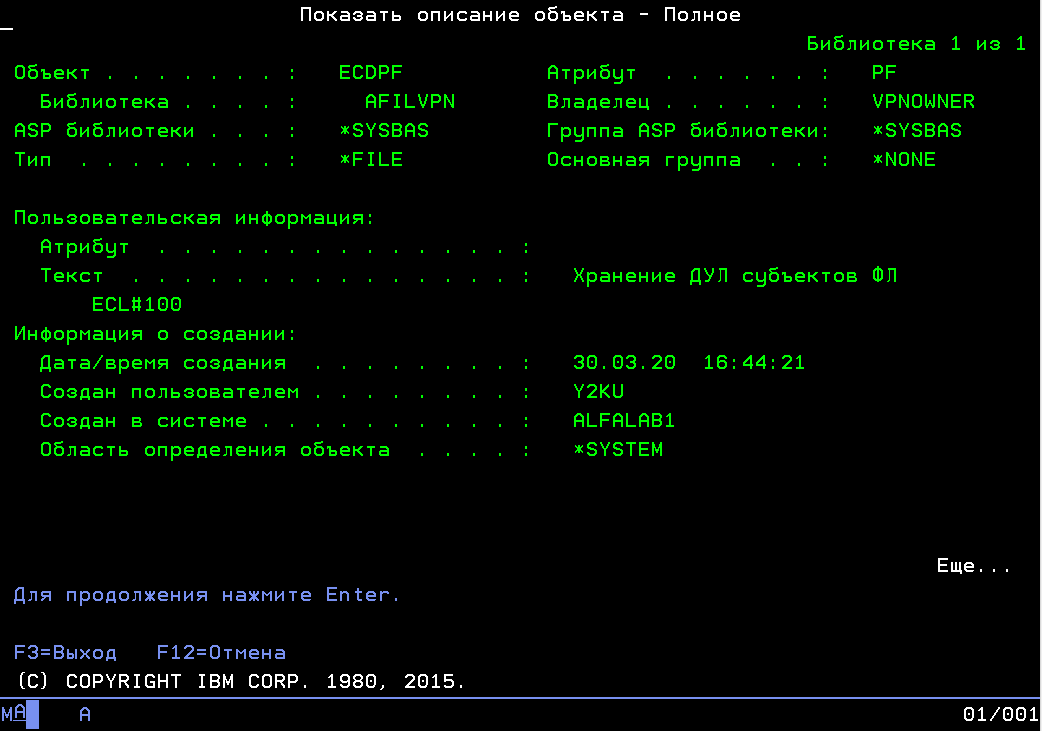
Из PEX статистики работы XXXXXXXXX видно, что 33% времени и 36% ресурсов CPU тратится на выполнение QSQRPARS в программе YYYYYYYYY, т.е. парсинг статических выражений при подготовке SQL запроса.
Сократить данные ресурсозатраты практически до нуля можно путем описания параметров sql запросов через SQL Descriptor Area (SQLDA).
Поскольку NNNNNN один из наиболее активно используемых сервис модулей, необоснованное повышенное ресурсопотребление является малодопустимым. Просьба инициировать доработку YYYYYYYYY.
SELECT DISTINCT ELWWRD FROM ELWPF
LEFT JOIN EWFPF ON ELWWID=EWFID
WHERE EWFEWF IN (...) AND EWFTES='N'SELECT ELWEID, ELWSPE FROM ELWPF
WHERE ELWWRD IN (...) and ELWTES='N'
GROUP BY ELWEID, ELWSPE
HAVING COUNT(*)=MAX(ELWCNT)Тестирование проведено в копии пром среды, запуск СМ осуществлен 34648 раз.
Среднее время получения ответа, при запуске СМ:
Текущая версия функционала (копия в пром среды от 25.01.2020) — 7.98 м. сек
Обновленная версия, СМ — 6.71 м. сек
Рессурсовзатратность QSQRPARS уменьшилась до незначительных показателей.
О них на модных митапах, видимо, как-то стыдновато рассказывать
Есть и еще более забавные задачки. Недавно вот на комбинаторику была — в записи 10 полей. Нужно составить все возможные их комбинации. Товарищ очень изящно ее решил.Такие вопросы программисту я бы даже постыдился задавать.
Или вот такое — 15 программ. Первой может быть запущена любая из них (с передачей некоторого набора параметров). Из нее может вызываться также любая из оставшихся. Как это реализовать чтобы избежать ситуации когда
Мне теперь стало интересно, у вас есть какой-то принципиально другой способ решать задачи на комбинаторику, не используя циклы?
Или вам просто конструкция цикла не нравится и вы ожидаете чего-то вроде итераторов или джойнов?
Будет еще внутренний цикл, он определяется количеством записей в таблице.
В какой таблице?
Ну и еще один цикл, его параметр будет переменным, это количество уже собранных наборов.
Зачем нам цикл по уже собранным наборам?
Покажите код, пожалуйста, действительно интересно. Из словесного описания пока что не складывается в чем смысл решения.
Что значит набросать план? Шедулер написать? Или какие-то примитивы для параллелизма даны, и надо в рамках них это сделать?
Ну и там ещё миллион вопросов последует.
Но дьявол в деталях. Что будет с пакетом, если воркер упал во время обработки? Кто должен фиксировать результат обработки так, чтобы нагрузка распределялась равномерно?
Что будет, если заданно максимальное время и оно вышло, а обработка не завершена (такое допустимо например, когда задача одноразовая, ее можно выполнить не за один проход, но на ее выполнение можно выделить, скажем, полчаса в сутки в определенный период минимальной загрузки системы).
SELECT DISTINCT ELWWRD FROM ELWPF
LEFT JOIN EWFPF ON ELWWID=EWFID
WHERE EWFEWF IN (....) AND EWFTES='N'Из PEX статистики работы XXXXXXXX видно, что 33% времени и 36% ресурсов CPU тратится на выполнение QSQRPARS в программе YYYYYY, т.е. парсинг статических выражений при подготовке SQL запроса,
Поскольку MMMMM один из наиболее активно используемых сервис модулей, необоснованное повышенное ресурсопотребление является малодопустимым. Просьба инициировать доработку YYYYYY.
Вы сейчас про какие очереди говорили?
MessageQueue (MQ)? DataQueue (*DTAQ)? UserQueue (*USRQ)? Их тут всех есть. Они все разные и работают по-разному. В том числе и по эффективности и скорости.
Был пример — некий австралийский банк решил заменить весь легаси код, написанный на коболе. Обошлось им это в сумму с шестью нулями и несколько лет работы.
Вы работаете с полностью несовместимым с мейнстримом стеком технологий.
Ваши решения и даже ваши задачи оказываются абсолютно другими чем все привыкли. В обычном мире разработки всего этого нет, зато есть все другое. Подозреваю что с совместимостью у вас тоже не очень.
Тут лучший пример это наши банки. Без тонн легаси на Коболе. Тинек, Альфа и далее по списку. Они уже на голову выше всех типовых иностранных банков. По качеству софта и обслуживания клиентов.
Судя по их рассказам они все делают на типовых технологиях. И это хорошо работает.
некий австралийский банк решил заменить весь легаси код, написанный на коболе. Обошлось им это в сумму с шестью нулями и несколько лет работы.
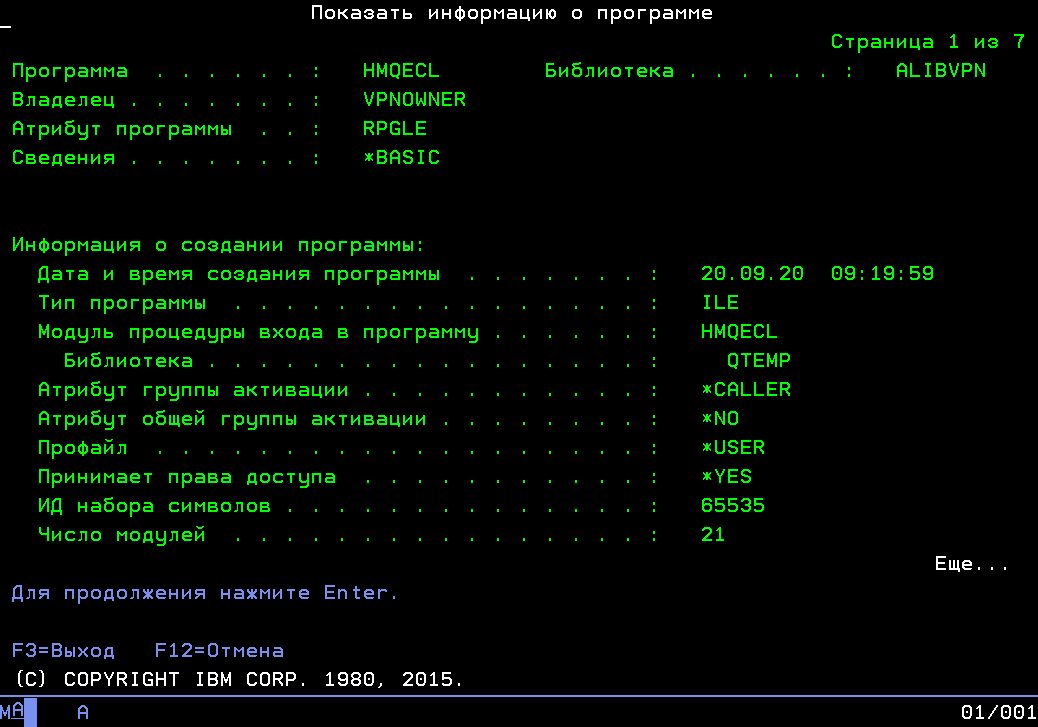
Одной из особенностей платформы IBM System i является использование высокоуровневой системы команд TIMI («Technology Independent Machine Interface», рус. Машинный интерфейс, независимый от технологии[3]), которая позволяет программам быть переносимыми и при этом получать пользу от более современного аппаратного и программного обеспечения без перекомпиляции.
TIMI является виртуальной системой команд, не зависящей от реальной системы команд центрального процессора. Приложения, работающие в режиме пользователя, могут содержать одновременно машинные коды TIMI и машинные коды конкретного процессора. Концептуально система сходна с архитектурой виртуальных машин, таких как Smalltalk, Java, .NET. Основное отличие от них — глубокая интеграция TIMI в архитектуру AS/400, таким образом, что приложения являются переносимыми между системами System i с различными микропроцессорами.
Особо надо отметить, что в отличие от других виртуальных машин, которые интерпретируют виртуальные инструкции при запуске ПО, инструкции TIMI не интерпретируются. При компиляции ПО, в объектном файле сохраняется как машинный код конкретного процессора, так и TIMI-код. Если приложение, скомпилированное для оригинальных 48-битных процессоров CISC AS/400, будет запущенно на системе с более новым RISC-процессором, например, 64-битном PowerPC, то операционная система проигнорирует машинный код старого процессора и оттранслирует[3] TIMI-код в инструкции нового процессора перед запуском.
Как у вас обстоят дела с феноменами вроде Undefined Behavior из C++?
Как выглядит версионирование софта?
Как у вас обстоят дела с феноменами вроде Undefined Behavior из C++?
Как выглядит версионирование софта?


Очень интересно, спасибо что так развернуто отвечаете.
Жаль только что это в комментариях останется, хотя уже тянет на статью.
Я понимаю, но таки посмотрите на это всё с позиции приходящих к вам людей. Люди приходят, чтобы (в разных пропорциях) получать денежную компенсацию, решать интересные задачи, улучшать мир, получать новые навыки, получать трансферабельные новые навыки.
Оплата по рынку
А поскольку сфера специфическая и платформа специфическая, то и навыки будут специфическими.?
А человек, который будет прокачивать скиллы чтобы через два года уйти в другое место нам не нужен.
не значит что везде так.
И вот точно не будут сокращать людей с опытом
Никого не сократили, никому не понизили оклад.
Оплата по рынку. Плюс стабильность (тут не будет ситуации когда вдруг скажут «извините, но работы больше нет, проект закончился, нового заказчика не нашли, разбегаемся»).
Люди туда работать идут не ради того, чтобы выяснять, первокурсник лучше освоит лисп или питон.
Вот честно хотелось бы, чтобы именно ради таких вопросов и шли.
А то наши (большей части exUSSR) типовые вузы, где большинство преподавателей пенсионного возраста и в лучшем случае пишут фанфики по мотивам настоящей науки (а то и этим себя не озадачивают) — годятся только ради корочки.
вы как налогоплательщик считаете, что тратить деньги общества на выяснение «что лучше для университета — Питон или Лисп» — это хорошее расходование средств?
Я как налогоплательщик считаю, что образование должно быть чем выше качества, тем лучше, и для этого эксперименты жизненно необходимы — разумеется, по правильным методикам (включающим осторожное начало и независимое оценивание), но необходимы.
В остальном же резкий перевод на тему налогов выглядит приёмом некорректной полемики.
если бы какой-то язык давал прирост производительности труда по сравнению с другим хотя бы на 5%, все на нём бы сидели.
Это откровенная ерунда, потому что приросты бывают и в 500 и в 100500 процентов, но — в конкретных областях и для конкретных типов задач. Иначе бы новые языки просто не выстреливали, и мы бы действительно сидели на одном Фортране или Коболе. Если вы видите язык, который вышел из породившей его лаборатории и пошёл по миру, то он даёт прирост не 5%, а как минимум десятки процентов — иначе легаси не дало бы ему развиться.
потому что с практической точки зрения если даже студенты полгода посидят на Лиспе, всё равно ради реальной жизни через полгода они начнут изучать Питон или C, а если им это слишком сложно, то скорее всего, они для этой профессии слабо пригодны всё равно.
"Реальная жизнь" она разная бывает. Вон если больше половины (навскидку и например) применений Python это врапперы вокруг numpy/pandas/etc., то тем, кто использует его для таких задач, LISP нафиг не сдался.
А вот тем, кто целится на широкий спектр понимания CS, надо учить и LISP, и Forth, и обычные процедурные языки, и акторные цепочки из промисов… а вообще такому надо пройти, например, этот список до указанного уровня (знать по каждому слову, что оно и чем характерно). (Может, чуть устарел — ну так обновлять.)
резкий перевод на тему налогов выглядит приёмом некорректной полемики.Смотрите, этот приём корректен потому, что именно таким образом оцениваются предложения учёных в грантовых комиссиях. Если кто-то захочет провести подобную работу и выбить под это деньги, то проект будут изучать на предмет научной интересности, новизны и да, impact/spillover effects/importance, вот и всё.
Это откровенная ерунда, потому что приросты бывают и в 500 и в 100500 процентовБезусловно. Эта цитата относилась к языку «общего назначения» в рамках написания «софта широкого профиля». Сейчас мы имеем куда больший зоопарк языков и сфер применения, но если сосредоточиться на «учебных» языках, то назовите любую десятку — пусть там будет и Паскаль, и Питон, и Руби, и что угодно ещё. Вот я уверен, что не найдётся такого языка, который вот прямо все понимают, а Питон не понимают. Ну ведь уже учили и на Бейсике, и на Лого, и на чём только не. Любой не слишком замороченный язык плюс-минус одинаков.
А вот тем, кто целится на широкий спектр понимания CS,Мы здесь по сути обсуждаем «вход в IT», то есть с чего начать, а не чего в принципе стоит освоить. Это другой вопрос.
Есть какие-то исследования, что условный питон эффективнее для начального обучения программированию, чем условный лисп?
MIT таки писал какое-то обоснование, почему они перевели CISP со Scheme на Python. Можете поискать.
Не вижу особой проблемы начинать с паскаля в школе
Пачка граблей, которые непонятны и которые надо тупо запомнить, я об этом писал несколько раз: 1 2 и т.д.
Я понимаю критику C, но тогда надо брать не Pascal, а хотя бы Modula-3.
кто заинтересуется изучит и другие.
Школьное образование должно быть рассчитано не на того, кто заинтересуется, а на то, что останется в голове у того, кто не интересуется. Иначе вообще держать предмет нет смысла.
Я понимаю критику C, но тогда надо брать не Pascal, а хотя бы Modula-3.
а нужно ли детям SO? мы же о первом языке говорим, это должна быть чуть ли не начальная школа
Начальная школа это вы преувеличиваете.
помните «математику уже затем учить надо, что она ум в порядок приводит»? программирование «приводит ум в порядок» ничем не хуже, я считаю, что его стоит изучать для развития детей, а не потому, что оно действительно многим пригодится в жизни.
и ещё есть одна мысль (не моя): программирование — это единственная «серьёзная» школьная дисциплина, где разрешено ошибаться (ситуация, когда программа не работает с первого раза, нормальна). и это тоже очень важно именно для развития детей.
первый язык должен ИМХО изучаться достаточно рано, никак не в ВУЗе. ну пусть не начальная школа, 5-6 класс.
уже в седьмом классе дети начинают изучение геометрии с почти полноценным аксиоматическим подходом, то есть ожидается, что они способны понимать и самостоятельно создавать достаточно сложные логические построения. так что и в программировании уже есть где развернуться.
Пусть привыкают что на правильно сформулированный вопрос как сделать тото интернет всегда ответит.
а вот как раз не всегда ответит.
нужно учить решать задачи самостоятельно, если этот навык есть — гуглить всегда научатся. обратное же неверно.
Мы же используем so. Так почему обучающимся не надо?
хотя бы потому, что он превратится ещё в один сайт с набором ГДЗ.
P. S. хотя за «правильно сформулированный вопрос» поставил плюс. но этот навык, наверное, нужно вырабатывать уже позже (по сути он не так уж сильно отличается от навыка самостоятельного поиска информации в библиотеке; что ранее ожидалось от студента, может быть старшеклассника)
первый язык должен ИМХО изучаться достаточно рано, никак не в ВУЗе. ну пусть не начальная школа, 5-6 класс.
уже в седьмом классе дети начинают изучение геометрии
но этот навык, наверное, нужно вырабатывать уже позже (по сути он не так уж сильно отличается от навыка самостоятельного поиска информации в библиотеке; что ранее ожидалось от студента, может быть старшеклассника)
хотя бы потому, что он превратится ещё в один сайт с набором ГДЗ.
Нет смысла гнать. Я бы сказал раньше 9 класса точно рано. 9-10 только самые начала, остальное не влезет.
какой-нибудь лого в девятом классе? не смешно )
Вот этим программирование и отличается от многих предметов. Правильный ответ это приличное количество текста
гхм. что в математике, что в физике, что в химии проверяется решение, и это тоже «много текста».
Который незнающий предмет даже прочитать не сможет
и кого это останавливало? списывают всё подряд не разбираясь и не понимая что за символы списывают.
гхм. что в математике, что в физике, что в химии проверяется решение, и это тоже «много текста».
и кого это останавливало? списывают всё подряд не разбираясь и не понимая что за символы списывают.
Ко всяким Лого и прочим «детским» языкам я отношусь с большим подозрением и не понимаю зачем оно вообще нужно.
ровно затем же, зачем и геометрия, например. я же выше написал. для развития абстрактного мышления. плюс для обучения планированию действий, умению заглядывать на несколько шагов вперёд.
побочный эффект: когда мы в старших классах начнём изучать «настоящий» язык, у учеников уже будет понимание того, что такое алгоритм, условие, цикл, переменная, а то и функция с рекурсией.
это обычная практика, когда одно и то же изучают несколько раз, та же площадь прямоугольника боюсь даже вспомнить сколько раз, тут вспоминали экстремумы функций, которые «наивно» проходят в 7-8 классе, а потом аналитически в 10 классе, s=v⋅t, которое проходится и в математике, и в физике, и т. д., и т. п.
BTW, вот обучение «настоящему» языку ИМХО можно уже сделать опциональным, далеко не всем оно нужно.
А почему этот цикл вот такой? А не вот сякой.
а что такое a⃗? а что означает стрелочка сверху? а в каких единицах оно измеряется?
Тот же пузырек правильно реализованный без понимания человек не расскажет что и почему. С кодом перед глазами.
вы опять про студентов, а я про детей.
И в итоге геометрия это один из самых непонятных и ненавистных предметов для школьников. Слишком сложно.Классическая проблема: есть хороший учитель и хороший учебник — можно и в 5-7 классе давать, и никакой ненависти не будет. Учебники Пойа, Локхарта или Киселёва вполне себе понятные и последовательные, а вот более новые, «академичные» учебники я бы школьникам в руки не давал, минимум студентам.
Нет смысла гнать. Я бы сказал раньше 9 класса точно рано.
Паскаль по факту не сильно от него отличается (да, есть анклавы дельфистов и т.п. — но это чудовищно далеко от мейнстрима). Да, надо было сказать "надо было брать лет 20 назад", или даже раньше.
Сейчас обстановка интересна тем, что ломается всё — ждём, что выживет из новой волны языков. Хоть выбирай между Swift и Julia какими-нибудь...
Бейсик, тот да, ужасен.
А серьезно я сторонник строгой типизации
Так в питоне как раз строгая типизация и есть. Может, путаете с динамической типизацией?
Может, путаете с динамической типизацией?
В питоне, в переменной может быть все что угодно. Сейчас там число, чуть позже строка, а потом массив.
let x = 3;
let x = "blah";В смысле как dynamic_cast с++?
let msg = 'fuck my brain' + [1, 2]Питон хорош для маленьких поделок, на один, два, три листа кода. А вот с объемными проектами гарантированно будут проблемы.
Неудобно как неудобная обувь.
Не так. В Питоне переменная, по-сути, является нетипизированной ссылкой на строго типизированный объект. Т.
Но при этом сам "строго типизированный объект" тоже может быть достаточно непредсказуемого типа из-за динамичности — можно менять поля и методы, можно заменить класс-подложку…
то, что он не допускает 2+"3", конечно, немного повышает порог, после которого начинаются чудеса и проблемы анализа (как ручного, так и машинного), но по сравнению с более устойчивыми в этом смысле языками — порог чудовищно низок.
Форматирование.
Его главная проблема не холивар — а когда встают вопросы типа "а сколько блоков и какие закрываются вот на этом сдвиге влево?"
При наличии {} все адекватные современные редакторы позволяют перейти на парную скобку, тут же такого нет (ну можно самому написать #end, конечно, но это локальное хакерство).
Сам синтаксис языка провоцирует совершать множество мелких ошибок, которые в C++ или Java спалил бы еще IntelliSense. А тут давай, до свиданья, в смысле, до рантайма.
Странно, ни разу не видел такого. Можно примеры?
Иногда не хватает перегрузки функций — то, что легко и изящно делается на этапе объявления в таком неуклюжем языке, как C++, в минималистичном Питоне выглядит каким-то извращением.
Имеется в виду необходимость писать с кучей именованных параметров со значениями по умолчанию?
Форматирование.
Странно, ни разу не видел такого. Можно примеры?
Имеется в виду необходимость писать с кучей именованных параметров со значениями по умолчанию?
Code folding работает, если что, во всех адекватных редакторах — можно свернуть блок, выделить строку, развернуть блок — выделенным окажется и всё содержимое.
Меня интересует вариант без фолдинга. С фолдингом слишком много движений.
Навигацию я знаю — вон в vim есть роскошный плагинчик indentwise — но она в принципе не способна справиться с "тут закрываются сразу 3 блока, вам какой?" Тут нужно, чтобы появлялся отдельный попап с показом сразу всех подобных начал блоков. Вот такого я ни в одном IDE не видел, они явно не рассчитывают на проблемы таких языков.
Они, конечно, и на сишный
if (a)
if (b)
if(c)
d;
else
e;не рассчитывают, но там поставить обязательные {} это вопрос стиля и понимания от того, кто хотя бы раз сам походил по граблям.
Дык как раз всякая мелочь типа 2 + «3», когда код рефакторили, рефакторили, да не вырефакторововали.
Вы говорили про синтаксис языка. Этот случай не имеет отношения к синтаксису: это семантика типов и операций с ними.
Проблемы этой семантики известны, но их и IDE ловит, и линтеры — не всё, конечно, из-за неустранимой динамичности типизации, но заметную часть.
Таки есть замечания по синтаксису в этом плане?
не способна справиться с «тут закрываются сразу 3 блока, вам какой?»
Этот случай не имеет отношения к синтаксису: это семантика типов и операций с ними.
это, думаю, должно быть удобнее просмотра попапа с показом начал.
Мне — нет. Многим, по отзывам, тоже.
Спасает только обычно малый размер функций.
Ой, да назовите, как хотите, у меня нет настроения заниматься буквоедством — семантика так семантика.
Не буквоедство, просто я в этом копался и хорошо чувствую разницу. OK, понятно.
IDE и линтеры, вроде бы, что-то ловят, но «не всё, конечно» — задолбать задолбают, а гарантий никаких.
Да, тут возможности сильно ниже типового языка со статической типизацией даже без современных плюшек типа систем типов.
При наличии {} все адекватные современные редакторы позволяют перейти на парную скобку, тут же такого нет (ну можно самому написать #end, конечно, но это локальное хакерство).
Всё есть. Адекватные Python-IDE позволяют. Даже Notepad++, что уж про PyCharm говорить. Точнее, не переход — а обозначение и сворачивание.
в языке с нестрогой типизацией вы запросто можете сложить вместе строку и массив целых чиселТипизация — это всё же больше о том, когда вы убираете у ваших данных поведение (или используете интерфейс иным неправильным образом), и они перестают тайпчекаться.
Большие проекты на Python требуют MyPy.
и абстрактные классы и самодельные интерфейсыТут еще привычка к другим ЯП может сказываться. Абстрактные классы не особо нужны (inheritance coupling), самодельные интерфейсы покрываются Protocols из Python 3.8+.
флаг компилятора
Ну не совсем. Типы-то вы можете указать, но рантайм Питона не обращает на них никакого внимания. Типы это для type checker, а оных немного и возможности их ограничены.
К сожалению, для data science библиотеки сплошной Питон.
Чем вам Керниган-Ритчи и Си как первый язык для обучения основам не угодилВ Си (и асме) ломает мозг и потом значительно усложняет освоения более высокоуровневых языков определение переменной: в С это именованный адрес (ячейка памяти), а в высокоуровневых языках — именованное значение.
Ну там всё равно будет фактический эквивалент адреса в виде какого-нибудь id объекта и проверки его на идентичность другому такому же.
(Уточнение: мне недавно доказывали, что в Haskell этого нет. Готов поверить: для таких языков идентичность может не являться чем-то важным по сравнению с равенством.)
Ну я ровно про это же. Проверить идентичность там таки доступно, и это типовой вариант для таких средств. Что этот адрес, даже если доступен, может меняться — это уже неизбежная специфика реализации.
Можно его сравнить на равенство другому.
У человека проблема с пониманием N=N+1 и несложной задачки, а вы тут про примеры по 50-100 строк…
В школе тоже начинают с азов, а потом наращивают обороты. Язык С низковат уровнем и достаточно сложен для написания. Паскаль же весьма идеален для обучения базовым принципам программирования.
Сообщество разработчиков решило что Паскаль плохой и они не хотят на нем писать.
Сообщество бизнесменов решило что Паскаль плохой и они не хотят платить за написание на нем.
Ни сообщество разработчиков, ни не сообщество бизнесменов ничего такого не решали.
Некоторые разработчики как пользовали Паскаль (не тот самый виртовский, конечно, а обновленный и дополненный, но и на С++ сейчас в основном пишут тоже не на том самом, доисторическом, а хотя бы на 11-м), так и пользуют.
Некоторые бизнесмены как полагались на программное обеспечение, которое было написано, сопровождается и пишется на Паскале (сейчас это как правило Delphi), так и полагаются до сих пор (как и на тот же Кобол, кстати).
И все, что характерно, деньги зарабатывают.
Понятно, что не будь наследия старого кода, никто бы на Паскале не программировал нигде, кроме как в хоббийных проектах или в научной компьютерной археологии (если такая существует).
Но это совсем не от того, что Паскаль "плохой", а от того, что основная часть индустрии работает на более других языках, соответственно, для тех языков богаче библиотеки, больше наработок, которые можно использовать.
Но молодежь мы по прежнему будем заставлять жрать кактус.
Я учился программированию в школе на Фортране (весьма популярный и очень широко используемый на тот момент язык) и ЯМБе (занятный такой язык, очень ограниченный в возможностях, чуть сложнее языка программирования программируемых калькуляторов).
Только потом в работе я их вообще никогда, нигде и никак не использовал. Программировал совсем на других языках (очень разных).
Вот точно то же самое может статься с любым "актуальным" языком, выбранным для обучения в школе — пока пациент дозреет до реальной работы, язык может стать нишевым, редко используемым, или окажется широко используемым, но в сфере, которая пациенту совершенно неинтересна.
Так что актуальность языка для начального обучения — так себе аргумент.
А вот общие навыки программирования, приобретенные при изучении Фортрана и даже ЯМБа, очень даже пригодились. В том числе даже в понимании фишек языков, которых в изученном мной Фортране не было как класса (тех же классов, кстати).
сейчас это как правило Delphi
Но это совсем не от того, что Паскаль «плохой», а от того, что основная часть индустрии работает на более других языках, соответственно, для тех языков богаче библиотеки, больше наработок, которые можно использовать.
Вот точно то же самое может статься с любым «актуальным» языком, выбранным для обучения в школе — пока пациент дозреет до реальной работы, язык может стать нишевым, редко используемым, или окажется широко используемым, но в сфере, которая пациенту совершенно неинтересна.
Так что актуальность языка для начального обучения — так себе аргумент.
Кстати, Си спокойно съест if (i = 1), а Паскаль if (i:=1) не пропустит никак, да и заметно, что в сравнении что-то не так.
Полгода-год и вперед деньги зарабатывать. Питон или js.
Джунов готовых работать за еду набирают много где
А оставшаяся часть стажировок ещё и требует денег от вас — это всякие «платные курсы с трудоустройством», причём трудоустройство по итогу не слишком-то и гарантированное оказывается.
Чтобы не думать и голоде и физическом выживании.
Для москвича сидящего на шее у родителей
Ваш личный пример не доказывает, что это работает в общем случае.
Открыл хедхантер, указал москву, вакансии для джунов. От 40-50к цифры
Вообще в Москве стандартный уровень для стажера колеблется от 15 до 25
Да примерно везде. Надо искать не стажера, а джуна. Стажер это обычно студент не на полный день.
Ищите не большие корпорации, а мелкие конторки. Им люди сильнее нужны.
Рядом подтверждают что даже в провинции 25 платят.
Дельфисты атакуют
Насильников? ;)
Не знаю, мне нравится
github.com/Clozure/ccl/releases
released this on 20 Apr
Понятно, что это стёб, но вообще Lisp вполне хорошо подходит для обучения программированию в нормальном режиме (а не как у автора статьи, когда надо через год на работу устроиться). Правда, я бы посоветовал взять Racket — прекрасная современная реализация Scheme.
У него плохой синтаксис.
?!?
Посмотрите например пассаж про яблоки апельсины и целые числа.
program p1;
type
apple = integer;
orange = integer;
var
apple1 : apple = 0;
orange2 : orange = 0;
begin
apple1 := 1;
orange2 := 2;
writeln(apple1 + orange2);
end.В свете сползания с к плюсам половина текста уже не релевантна.
PS Да и посмотрите на его собственное детище язык AWK.
#include <stdio.h>
typedef int apple;
typedef int orange;
apple apple1 = 0;
orange orange2 = 0;
int main()
{
apple1 = 1;
orange2 =2;
printf("%d\n",apple1+orange2);
return 0;
}Ключевое слово typedef позволяет программисту создать псевдоним для любого типа данных и использовать его вместо фактического имени типа. Чтобы объявить typedef (использовать псевдоним типа) — используйте ключевое слово typedef вместе с типом данных, для которого создается псевдоним, а затем, собственно, сам псевдоним.
#include <stdio.h>
enum apple{one, two};
enum orange{four,five};
enum apple apple1 = 0;
enum orange orange2 = 0;
int main()
{
apple1 = 1;
orange2 =2;
printf("%d\n",apple1+orange2);
return 0;
}#include <stdio.h>
enum apple{one, two};
enum orange{four,five};
enum apple apple1 = 0;
enum orange orange2 = 0;
int main()
{
apple1 = 1;
orange2 =200;
printf("%f\n",1.0+2.0f+apple1+orange2+'b'+'a'+'n'+'a'+'n');
return 0;
}Те, кто считает, что для того, чтобы научиться программировать, надо учить конкретные языки программирования, никогда программистами не станут. Язык — это не цель, а всего лишь инструмент. И изучать надо общие принципы работы с инструментами.
Да и просто новичков не хотим учить вымершему языку.
Тут Кобол никак похоронить не могут, а вы Паскаль в вымершие записали.
На Паскале (точнее на Object Pascal, еще точнее на Delphi) написано огромное количество кода, который до сих пор используется и развивается. Лично знаю людей, которые занимаются не просто поддержкой такого кода, но и написанием нового.
Что еще интереснее, несмотря на среду разработки и диалект языка, далеко не весь код написан и пишется в парадигме ООП. Значительная часть — это просто старый добрый голый процедурный Паскаль (когда там в него юниты завезли?)
Более того, тот факт, что Embarcadero при наличии совершенно свободного (хотя и не столь продвинутого) конкурента (Free Pascal) пока не разорилась, продавая Delphi (не так уж и дешево, кстати, продавая), как бы намекает, что оно востребовано не только на уровне DIY.
Понятно, что язык стал весьма нишевым, но жив, и еще не подает признаков приближения смерти.
Ну очень просто. Объективные показатели есть? Скажем, простота и эффективность парсера/компилятора (с этим у семейства C так себе обстоит). Не то чтобы они покрывали все аспекты, но попробовать сформулировать можно.
На мой взгляд, синтаксис в этом деле дело не то чтобы десятое, а скажем примерно пятое. Скажем, Java считается по синтаксису близким к C. Ну, насколько близки — это вопрос темный, но с другой стороны, не к паскалю же, верно? Если ли у них что-то общее в применении? Я бы сказал, что нифига — ниши разные. Популярны ли они за счет своего синтаксиса? Я бы тоже сказал, что нифига — популярны, но каждый по своему, за счет разных своих характеристик.
А Дельфи убила потеря совместимости исходников между восьмой и седьмой версиями. :(
Скорее её платность. Когда даже MS выкатила бесплатную VS Express, Delphi продолжала оставаться платной, даже для учебных целей. Поэтому популярность её более-менее держалась только в СНГ, где всем тогда было плевать на лицензионную чистоту. Но где-то после 2008 года, у нас тоже началось движение в сторону легализации используемого софта.
Хотя попытка погнаться за .NET тоже была не на пользу. За Delphi никогда не стояло столь крупной компании, чтобы эффективно и успешно двигаться в разных направлениях.

А потом совсем уж какая-то "наркомания" вышла, в виде Delphi for PHP. В общем, полная расфокусировка.
Вот на простоту парсера/компилятора всем глубоко пофиг. Их пишут специальные люди, которым это нравится. Массам все равно.
Это не так, когда
1) Нужно поднимать компилятор, чтобы обеспечить просто правильную раскраску в редакторе,
2) Путаность синтаксиса доходит до той степени, что сообщения об ошибках просто становятся непонятными.
У меня как-то тупой ляп вызвал генерацию >7000 строк в выхлопе GCC, причём он сказал, что ещё самые длинные простыни урезал.
Но для учебных целей это тоже не так важно. Проекты маленькие, собираются быстро в любом случае.
Вот и у меня и было 7000 строк ошибок на учебном проекте. Ну да, он был с применением Boost.Spirit.
Vim вам все покрасит без проблем. Думаю что даже Notepad++ справится.
Подозреваю что если очень постараться их раскраску можно сломать, но зачем?
Плохие сообщения об ошибках известная проблема. Ну не могут же быть одни плюсы. Для действительно начальных проектов в 50-100 строк она не должна стрелять часто. А дальше обучение можно переводить на Питон.
Vim вам все покрасит без проблем. Думаю что даже Notepad++ справится. Подозреваю что если очень постараться их раскраску можно сломать, но зачем?
Так цель не сломать сам редактор, а написать что-то под конкретную задачу и принятый стиль. А сломается разметка сама, я уверен, что мало-мальски запутанные конструкты оно тупо ниасилит.
По вашему коду даже если совершенно не знать языка, на котором написано, легко выделяются некоторые структуры. Например, ясно что каждая из строк со знаком "=" это объявление чего-то вроде функции, знак ":" некоторым образом задаёт типы, в скобках после названия определяемой функции стоят аргументы, некоторые используемые операторы можно догадаться что делают, и т.п. А по APL из предыдущего коммента не понятно ни-че-го.
Я обосновывал неоднократно, повторю основное:
Это то, на чём шёл регулярный взрыв мозга у моих учеников.
Разумеется, есть и вкусности — паскалевский порядок определения переменных (var x: int вместо int x) начинают только сейчас массово ценить, или различие двух делений. Но при его старте они были сильно менее важны, чем все названные диверсии.
Никогда не было взрыва мозга от таких конструкций.
if ... then
begin ...
end
else
begin
end;Мозг сразу успокоится.
В С/С++ те же проблемы.
Во-первых, не те же. ';' в качестве разделителя они не вводили.
Во-вторых, не зря почти все современные языки имеют принудительные блоки — или в форме {} (Rust, Go, Swift), или в форме then/else — end (Ruby).
Считайте, что write в паскале не функция, а оператор (по крайней мере нам так объясняли). Мозг сразу успокаивается.
Ну как и говорилось — ещё одно исключение, которое надо тупо зазубрить.
Это вы еще с MUMPS не имели дело
Я имел дело с kdb+. Там приоритетов считай нет и порядок разбора — справа налево. Но почему я должен этим загромождать мозги свежеобучаемых?
А в чем проблема?
В неестественности.
В моем комментарии циферки пунктов после 2-го пропали почему-то, не уследил, ну да ладно,
"';' в качестве разделителя" — это уже второй пункт.
А вот проблемы со скобочками блоков у С/С++ и Паскаля общие (если не считать repeat… until).
На
if (...)
...;
...;
многие обожглись (хотя современные компиляторы вроде предупреждать должны).
Ну как и говорилось — ещё одно исключение, которое надо тупо зазубрить.
Таких исключений и неестественностей в любом языке достаточно, чтобы создать некоторые сложности обучаемому. Одно то, что char — число, которое можно прибавить к другому числу, но 1+'1' почему-то равно совсем не 2, многим тоже взрывает мозг. И ничего, как-то собирают потом его в кучу.
delhi_heir
Лучше писать вот так:
Это хабр отступы съел, хотя и обрамил вроде тегом кода на Delphi. Да и действительно, кое-где оно явно не "по феншую" получилось. Не углядел, однако. Впрочем, формирование отступов у языковых конструкций — тема холливарная сама по себе.
Так и я не лично для себя. Но когда это продвигают пригодным для сейчас учебным языком — выглядит, мягко говоря, странно.
Что названо словом «это»?
Паскаль.
Первый и главный минус Паскаля в том, что он (Паскаль, а не какие-то современные потомки в виде Delphi с заметными отклонениями от предка) непригоден для сколь-нибудь реальных задач. Даже массивы переменной длины и модули это уже расширение языка.
Я даже не рассматривал в своих предыдущих комментариях классический Паскаль Вирта; все оценки шли хотя бы от уровня TP5, где всё это уже есть. Возможно, это стоило упомянуть раньше, но я рассматривал его именно как учебный язык при условии, что самые большие ляпы уже нейтрализованы. Но если и их включать, то получится вообще абсолютная непригодность.
С по сравнению с этим реален, а его сложные проблемы вроде указателей можно вводить в обучение постепенно.
что если знаешь любой C-подобный язык, то перед тобой открываются широкие возможности
Идущему на профессионала перейти на C-подобные после Паскаля нет проблем, если уже научен базе. Я это наблюдал неоднократно.
А вот тем, для кого программирование только малая (хоть и обязательная) часть профессионального багажа, тем будет сложно.
из-за динамической типизации, Питону не хватает Строгости
Личный опыт показывает, что для обучения динамичность не мешает до определённого момента — грубо говоря, выхода на 200-строчные программы. Но этот рубеж и так проходят те, кто идут в программисты — поэтому им и смена языка не проблема.
И вы тоже путаете сильную типизацию (лучше так говорить, чем "строгую"), которая в Питоне есть для примитивных типов и в значительной мере — для объектов, со статической, которой там таки нет, если не подключать всякие аннотации и линтеры.
Я частично согласен с предполагаемой сутью вашего утверждения, но давайте быть таки чуть строже в терминах и не путать ортогональные вещи.
Вот, откровенно не считаю книгу Кернигана и Ритчи древней. Мне кажется она открывает глаза на многое. По крайней мере с другими языками жить становится проще и понятней.
Математика не то чтобы сильно нужна, но если даже с квадратным уравнением проблемы, стоит заняться чем-то другим, правда.
А какие могут быть сложности с линейными уравнениями или это шутка?
Не знать — это нормально. Ненормально — не уметь загуглить и разобраться.
Я формулу тоже, конечно же, не помню. Ну выведу минут за 10-15, если окажусь без интернета и будет очень надо.
Кстати, раз вы разработкой игр занимаетесь, наверняка знаете, только не задумывались. Какой ray tracing без квадратного уравнения?
Отличие химиков-биологов от настоящих программистов заключается в том, что их код не имеет ничего общего с индустриальным программированием, потому что конечной целью не является написание и сопровождение кода. Для химика-биолога программирование — это просто использование вспомогательного инструмента для решения своих задач.
Я не знаю, у меня это личная нелюбовь, или действительно звоночек, когда человек по любому поводу, вот прямо начиная с квадратного уравнения и знакомства с языком С, лезет смотреть видеоролики? Я понимаю, что времена такие, но все же мне кажется, что чтение — это в крови, если человек по умолчанию настроен на аудио/видео канал, то кодерство не совсем его стезя. А по теме — ну да, потому и существует в этой области высшее образование и вообще наука всякая, не всё так просто.
Не кодер, но всё же с чтением документации проблем обычно не возникает.
Но не смотря на это, обычно выбираю видео, а не текст по многим причинам:
1) Легче воспринимается
2) Привычная единая площадка. Обычно это Ютуб или Khan academy
3) В большинстве видео (да хоть по квадратным уравнениям) есть живые примеры и их решения
4) Легче рассчитать время которое будет потрачено на ознакомление с материалом
Но есть и недостатки, такие как:
1) Высокая фрагментированность контента — найти полный глубокий видеокурс по некой теме сложнее, чаще всего это просто запись лекций. В книге по языку можно найти в одном месте и теорию и практику; различные темы структурированы и разбиты на главы.
2) Может не быть подходящего видео, даже на английском языке. Тогда именно приходится читать, а не смотреть.
Но в целом, мне чаще необходимо разобраться с некой проблемой здесь и сейчас, а нужный видеоролик, в отличие от книги, находится в паре нажатий кнопок, что и определяет тип контента.
Как мне кажется, для глубокого изучения больше подходят либо книги, либо курсы, наподобие тех, что предлагает Cisco, пускай последние и являются книгами с интерактивной практикой.
Также, посмею предположить, что вы учились до эпохи интернета, из-за чего учебная литература вам привычней. Заранее извиняюсь, если не прав.
1) Легче воспринимается
вот это и непонятно.
текст можно читать с любой скоростью. эту скорость можно произвольно менять. непонятные вещи можно перечитывать несколько раз.
видео же идёт с какой-то заданной кем-то другим скоростью. перемотать ровно на пару предложений назад — тот ещё квест.
Также, посмею предположить, что вы учились до эпохи интернета, из-за чего учебная литература вам привычней
дело не только в этом. психологи говорят, что люди делятся в визуалов, аудиалов и т. п.
но программирование подразумевает работу с текстом. много текста. если же для вас работа с текстом некомфортна, то зачем же туда полезли?
психологи говорят, что люди делятся в визуалов, аудиалов и т. п
В таком случае мы, похоже, спорим о вкусе фломастеров
видео же идёт с какой-то заданной кем-то другим скоростьюСкорость меняется легко, как угодно, разве нет? Можно по хоткеям скорость менять, можно сразу позицию выбирать, никаких проблем.
перемотать ровно на пару предложений назад — тот ещё квестЕсли открыть скрипт субтитров (на youtube или на coursera), то можно сразу ткнуть куда нужно (кстати, это неплохой вариант, хотя конечно книжка все-равно выигрывает).
психологи говорят, что люди делятся в визуалов, аудиалов и т. пЧитал, что это полнейший бред, нет четкого деления.
если же для вас работа с текстом некомфортна, то зачем же туда полезлиТак он же не программист, он что-то другое по видео изучает, насколько я понял из первого предложения.
Скорость меняется легко, как угодно, разве нет?
да, меняется. но не так легко, как при чтении, и не как угодно, но меняется.
Если открыть скрипт субтитров (на youtube или на coursera), то можно сразу ткнуть куда нужно
спасибо, не знал, что на ютубе можно посмотреть список субтитров.
это возражение снимается.
Читал, что это полнейший бред, нет четкого деления.
«нет чёткого деления» — да, как и на умных и глупых, например.
«полная ернуда» — нет, конечно.
Так он же не программист, он что-то другое по видео изучает, насколько я понял из первого предложения.
фраза была обращена не только (не столько) к 1tuz
не как угодно, но меняетсяЕсли именно онлайн, то существуют расширения (например github.com/igrigorik/videospeed, скорость от 0.1x до 16x). Оффлайн, как минимум vlc.
да, как и на умных и глупых, например.«полная ернуда» — нет, конечноДеление на визуалов/аудиалов/кинестетиков (вак), это одна из многих теорий обучения, полно других, но почему-то именно идея вак всем запомнилась. Проблема в том, что те, кто предложили эту модель, еще постулировали, что со временем приоритет меняется и выравнивается, а еще то, что сила влияния какого-либо из факторов, который человек сам себе выбрал, часто не совпадает. И да, модель вак критикуют.
ничего, скоро натренируют нйеросети на распознавание видео и можно будет программы в видео писать
А «новое поколение» уже местами просто с текстами работать умеет хуже чем с видео/аудио.
Если это то же "новое поколение", для которого голосовой звонок без предварительного согласования — почти преступление, то что-то не сходится.
дело больше в проработке, потому что смотреть его интересноНу я примерно о том же, что видеоматериал бывает полезен, если хорошо сделан.
в сельской школе училсяСельские школы не обязательно слабые. У меня друг тоже из маленькой сельской школы, так у него подготовка намного лучше моей пгт'вской (у меня в классе были люди, которые читать нормально не могли, не то, что в математику думать, впрочем сами не учились). Это уже частности, впрочем.
> перемотать ровно на пару предложений назад — тот ещё квест
Если открыть скрипт субтитров (на youtube или на coursera), то можно сразу ткнуть куда нужно (кстати, это неплохой вариант, хотя конечно книжка все-равно выигрывает).А как это сделать на ютубе? Я вижу как включить субтитры, и как их выбрать или настроить, но где посмотреть весь скрипт и куда там можно "ткнуть" в упор не вижу.


Сейчас же я не могу найти видео с субтитрами, но без такой возможности. И даже в тех видео эти кнопки уже есть. Хотя если нажать на «поработать над переводом» на открывшейся странице выводится фигвам — «В видео, которое вы выбрали, нельзя переводить субтитры и метаданные». Но кнопка-то есть..
Как хорошо спрятали! Спасибо!
текст можно читать с любой скоростью. эту скорость можно произвольно менять. непонятные вещи можно перечитывать несколько раз.
видео же идёт с какой-то заданной кем-то другим скоростью.
но по факту по целому ряду причин среднестатистическое видео содержит информацию менее высокого качества, нежели текстОднако Coursera и прочие ведь нормально заходит, и не только из-за проверки заданий. Приходится смотреть видео потому, что там легче найти понятную поверхностную информацию (когда этого достаточно).
1) Легче воспринимается
Меня видео (да и вообще лекции) нереально утомляют, потому что скорость подачи материала не соответствует скорости его усвоения. Если материал подаётся слишком медленно, то становится скучно, мозг начинает отвлекаться, теряется концентрация, материал не усваивается. Если же подаётся слишком быстро, то просто перестаёшь материал понимать, потому что непонимание нарастает как снежный ком.
2) Привычная единая площадка. Обычно это Ютуб или Khan academy
А какая разница, какая площадка?
3) В большинстве видео (да хоть по квадратным уравнениям) есть живые примеры и их решения
Ага. А если дело касается кода, то что, просто перенабирать куски программ с экрана, вместо того, чтобы просто сделать копи-паст текста?
4) Легче рассчитать время которое будет потрачено на ознакомление с материалом
Одного видео мало. Полноценное изучение материала невозможно без самостоятельной работы (практики), а сколько времени уйдёт на это, оценить уже невозможно.
чаще всего это просто запись лекций.
Потому что так тупо проще. Вместо того, чтобы потратить кучу времени на создание качественных материалов, просто пишем видео. Пипл схавает.
Заметьте, в технических вузах вам лектор ведет лекцию, а не выдают книгу со словами — учите. Лично мне, тяжело дается чтение. По моим ощущениям лекция/видеоурок раз 5 эффективнее чем чтение документации. Естественно, без документации никак и гугл наше все. Когда тебе нужно не всю тему понять, а лишь ньюансы — документация лучшее средство, но когда нужно с нуля что-то освоить, то эффективность преподавателя заметно выше.
Заметьте, в технических вузах вам лектор ведет лекцию, а не выдают книгу со словами — учите.
Это уже давно не так или не везде. Наблюдаю за обучением своих детей. Какая-то "методичка" (пусть даже примитивная) обязательна, и опираются на неё даже больше, чем на живые лекции.
Живые лекции, с одной стороны, пережиток отсутствия лёгкого копирования данных (окончательно закончилось около 2000-го), с другой стороны, метод общения с аудиторией — но польза будет только тогда, когда это реальное общение ("мы не поняли, объясните детальнее", "а зачем такой сложный путь?" и т.п.)
И то сейчас это лучше делать, если сначала попытаются сами прочитать и понять (и решить стартовые задачи) и только потом спрашивать (на семинарах).
Знания самой математики вам не много дадут в плане изучения программирования как профессии. Но умение решать уравнения, строить доказательства и логические размышления тренирует те же навыки, которые программист использует при поиске багов, проектировании алгоритмов (даже тривиальных), изучении кода, документации и книг. Все остальное в программировании это мириада фактов (типа устройство CPU, POSIX API и т.д.) которые служат основой для построения логических цепочек с помощью вышеозначенного навыка.
Так как мы говорим о навыке, то потребуется немалое время для его выработки (сколько времени нужно чтобы получить разряд по боксу?). Новые нейронные связи не быстро формируются. Хорошая новость заключается в том, что навык можно набивать практикой и одновременно читать и разбираться в языках, платформах, сетях, БД, железе и т.д. Не знаю сколько времени уйдёт до достижения «нанимаемого» уровня, но я бы готовился к 6-18 месяцам довольно интенсивной работы по несколько часов в день.
Странно что сразу программистом и переезд. Может сначала хотя бы устроиться "джуном" на полгодика тут? Это помогло бы "быстро въехать".
IT конечно та ещё кроличья нора.
Я долго вникал почему 0 в степени 0 равен 1, и у меня ощущение что я до конца так и не понял всей сути.
это хорошо, что не поняли.
Выражение 0⁰ (ноль в нулевой степени) многие учебники считают неопределённым и лишённым смысла
впрочем, не обижайтесь, но бессмысленно рассуждать о 0⁰ человеку, который не знает/понимает производных.
по остальному… боюсь вас обидеть, но как-то слишком сложно у вас всё заходит. того же k&r я читал подростком и я был поражён изящностью и … какое слово подобрать? очевидностью? … выбранных решений. это одна из немногих вещей, которые не нужно учить, а нужно понять и оно навсегда останется в памяти.
выражение типа N=N+1 и более сложные уравнения меня загоняли в легкий ступор.
если спустя несколько лет в IT вы говорите такое, программирование — не ваше.
btw, а как же вы админили? я не представляю админства без скриптов, и выражения вроде N=$((N+1)) вполне обыденны.
ИМХО чтобы стать хорошим специалистом в любой области нужно гореть, интересоваться этой темой. сколько вам лет? судя по ребёнку, к которому ходит репетитор, не так уж и мало. если вы к этому возрасту не проявили склонности к программированию, то почему сейчас что-то должно измениться?
BTW, а почему вы решили стать программистом? из-за зарплаты? так нейрохирурги или дантисты получают не меньше. адвокаты, думаю, много больше.
что-то подумал я… скорее всего, история придумана.
не верится, что вот такой вот человек, любящий видеотуториалы, написал вдруг написал статью для хабра. откуда он узнал про хабр? тут нет видеороликов. как решил сам писать статьи?
А еще адекватный взрослый человек должен прекрасно понимать, что никому "там" он не нужен без профильного образования, опыта работы, рекомендаций, портфолио (не обязательно все пункты сразу). Ну и ещё момент: очень сложно вот так вот взять и кардинально поменять свою жизнь, когда в ней столько якорей. Это я если что про ребенка, который уже с репетитором занимается. Так что согласен с вами, статья с большой долей вероятности ничего общего с действительностью не имеет.
Статья на Хабре это неплохая строчка в резюме.
Ломанулись толпы которые программировать не любят и не хотят, но хотят денег.Многие работают только ради денег, и вполне рационально поступают. Я тоже так делаю. А развлечения по интересам — по вечерам.
и не получать от работы никакого удовольствияХотя зря вы так фривольно с квантификаторами всеобщности. В любом упорядоченном труде находишь хоть какое-удовольствие, в том числе и интеллектуальное. Вопрос в том, что днём рутинно
очень сложно вот так вот взять и кардинально поменять свою жизнь, когда в ней столько якорей. Это я если что про ребенка...
откуда он узнал про хабр? тут нет видеороликов. как решил сам писать статьи?
почему вы решили стать программистом? из-за зарплаты? так нейрохирурги или дантисты получают не меньше. адвокаты, думаю, много больше

Нейрохирурги и дантисты требуют 1. мед.диплома, 2. хорошей практики 3. невероятно прямых рук 4. высокой стрессоустойчивости 5. высокий уровень ответственности 6. конкуренция не обязательно ниже 7. хирургия требует некоторой доли таланта и т.д.
1. без диплома по специальности получить программисту рабочую визу в США реально?
2. как и программирование;
7. как и программирование.
Пошли бы вы к специалисту, который переучился в нейрохирурги из админов после 25 лет?
почему бы и нет? разумеется, не к самоучке, который сам решил, что он готов работать нейрохирургом, а к человеку, имеющему право заниматься медицинской практикой.
более того, я почти уверен, что такой нейрохирург, если найдётся, будет лучше среднестатистического (ибо он не случайно попал в медиститут подростком и чудом не был отчислен, а сознательно в зрелом возрасте понял, что хочет стать врачом и положил на это кучу сил и времени).
впрочем, речь-то была совсем не про это. почему-то то, что стать нейрохирургом сложно, понимают все.
но вот вот автор статьи (если это не фейк, в чём я сомневаюсь) решил стать программистом без каких-либо предпосылок к этому за пару месяцев просмотра видеороликов на досуге. притом не просто джуном, а получить приглашение на релокацию в США.
программисту рабочую визу в США реально
сознательно в зрелом возрасте понял, что хочет стать врачом и положил на это кучу сил и времени).Эээ, мне бы ваш оптимизм. Мне попадались только люди переходящие из медицины в другие области, но не в нее. Возможно я преувеличиваю сложности перехода в нейрохирургию и мед., но что-то не вижу рвущихся в нее взрослых людей.
почему-то то, что стать нейрохирургом сложно, понимают все но вот вот автор статьи (если это не фейк, в чём я сомневаюсь) решил стать программистомНу это же желание стать, не факт что получится. Может и фейк, раз «НЕ» в заголовке. Зарплаты, наверное, привлекают и примеры (которыми наводнена сеть). Это ведь практически единственный шанс для обычного человека получить неплохую зарплату умом и упорством.
btw, а как же вы админили? я не представляю админства без скриптов, и выражения вроде N=$((N+1)) вполне обыденны.
если вы к этому возрасту не проявили склонности к программированию, то почему сейчас что-то должно измениться?
BTW, а почему вы решили стать программистом? из-за зарплаты? так нейрохирурги или дантисты получают не меньше.
Есть множество причин считать 0⁰ = 1.
сорри, хотел вот это написать:
https://www.wolframalpha.com/input/?i=lim+0%5Ex+as+x-%3E0%2B
это достаточная причина не считать 0⁰ = 1
Если я захочу углубиться, я начну экспериментировать с хлебом, толщиной нарезки, добавлять\убирать сыр, менять овощи, а не уходить в селекцию семян зерна, выбор плодородной почты и качественных удобрений.
хороший шеф-повар будет интересоваться и сортом («селекция семян»), и регионом происхождения («выбор плодородной почвы»), и т. п.
Повар-технолог обычной столовой всё-таки таким не заморачивается
в ПТУ поваров не учат, что есть картофель разных сортов, один больше пригоден для одних блюд, другой для других? не верю. и что пшеница бывает разных сортов, уверен, тоже учат. и чем разные сорта муки/манки друг от друга отличаются.
да что там профессиональный повар, почти любая хорошая домохозяйка вам про это расскажет (пусть, быть может и в бытовых терминах).
и любой человек, неравнодушный к вину, расскажет вам, что вкус вина зависит не только от сорта винограда и способа приготовления вина, но и от местности произрастания винограда (читай почвы и климата), года (читай погоды) и т. п.
да что там говорить, на рынке астраханские помидоры стоят дороже волгоградских, и все понимают, что это из-за того, что астраханские слаще — в астрахани банально солнца больше (может быть есть и другие причины, кстати).
У "Thinking in Java" ("Философия Java") было аж целых три издания, так вот первое — как раз вполне для новичков. В следующих напихали больше конкретных технологий. Не знаю, правда, есть ли у 1-го официальный русский перевод.
P.S. А, нет — даже уже четыре.
Аааарррр Java и Js разные языки
Может быть программирование просто не ваше? Может быть не стоит себя мучатт, если не идёт?
Решение то получил, однако понять, как преподаватель решила не смог:Например так:
Алгоритм, построенный мной для изучения программирования, дал сбой практически в самом начале.Возможно потому, что стоило ставить конкретные цели? Хотя бы лабораторные работы из университета по джаве. Они очень простые.
Я не то что не помню, как решаются такие задачи, — я элементарно, как выяснилось, попросту не знаю Алгебру за 10-11 класс!Ммм нет, эта задача 7 класса.
Или все-таки это не моё? И профессия «разработчик» — это для элиты, «касты особенных людей»?Да, для тех, кто в школе учился. Школьных знаний математики достаточно в программировании веба.
Так вот, проанализировав прошедший месяц-полтора самостоятельного обучения, для меня стало очевидно, что я как «хомяк в колесе», вроде как бы и бегу (учусь), а по факту стою на месте.Нет конкретных целей, вот невидно прогресса, даже если он есть.
Ммм нет, эта задача 7 класса.
хм, и как её решить ограничиваясь знаниями семиклассника? или под решением вы имели в виду использование вольфрама?
подумал, решил, ограничиваясь курсом 7 класса. но, всё-таки в этом случае задача становится олимпиадной, а с использованием производной — типовой, так что я бы не говорил, что это задача 7 класса.
Покажите пожалуйста задачник для 7го класса где ищут экстремумы, правда интересно. Ах да, спец школы в расчет, конечно же, не берём.
Ммм нет, эта задача 7 класса.
Программиста сразу видно по тому, что он считает с нуля :)
(тоже думал, что седьмой, но оказался всё же восьмой https://www.yaklass.ru/p/algebra/8-klass/kvadratichnaia-funktciia-funktciia-y-k-x-11012/funktciia-y-ax-bx-c-ee-svoistva-i-grafik-9108/re-92d9d602-f9c6-43f6-8f78-6f80b2c8227a)
ой ли. многие математики активно используют подобный софт.
Да где угодно. Вот вы строите загон для животных (Робинзон что-то подобное делал) — какой толщины должны быть ветки? Какая должна быть высота забора? Как прочно надо приматывать? Итд итп…
(Да, это физика, но выливается снова в математику)
Если вы в селе, то есть десятки более опытных соседей, которые в случае чего подскажут просто из своего опыта готовые практические результаты. А когда один-два — экспериментировать слишком дорого, надо подсчитать с запасом...
(Да, это физика, но выливается снова в математику)
Почему сразу аут? Человек знает возможности инструмента и адекватно оценивает свои силы.
Нужно дополнительные вопросы задавать:
В общем то тащить несколько фреймворков в один проект тоже плохая идея, поэтому неплохо задать вопрос:
есть задание на разработку от бизнеса, мы его реализуем.
У вас бизнес никогда не просил дичь, которую в постановке бизнеса просто нецелесообразно делать?
Да, вы правы. Когда человек совсем не подходит под ваши требования — ему лучше выбрать другое место работы.
Вот только вы подаете это так, что если человек не может вписаться в произвольный стек технологий, то он профнепригоден.
Тут с вашей стороны косяк. Зачем вы брали нового разработчика, который "писал на питоне", и давали задачи по всяким другим языкам?
Нет, экстремум квадратичной функции выводится аналитически через выделение полного квадрата, безо всяких производных. У меня в школе это точно было, и пресловутое "минус бэ на два а" запомнилось как отче наш. Погуглил учебники, это вроде даже 9 класс, хотя техника та же, что в 8 классе для вывода формулы корней уравнения.
Как человек, всю свою профессиональную карьеру стоящий на грани "зарыться навсегда в одну узкую область" могу сказать, что в этом неудачном пути обучения отсутствовал навык breath vs depth. И навык делегирования ответов.
Объясняю: в любой области всегда можно копать дальше. Например, начинаем мы копать в Computer Science. CS нас быстро подводит к пониманию вычислимости, которое напрямую связано с перечисляемостью и разрешимостью множеств, что в свою очередь нас утыкает лицом в математическую логику и теорию множеств, которая совершенно не стесняется перепрыгивать из счётных множеств в несчётные, что опасно близко нас подводит к множеству R и открывающейся при этом несчётной бездне. Где-то тут рядом с лёгкостью всплывает функциональный анализ, теория групп и понеслось…
Это мы всё ещё не прочитали первую главу CS, которая к программированию не относится.
Вместо этого надо уметь принимать часть решений на веру. Запоминать, что там "есть что-то такое" и вовремя останавливаться. Приспичит — можно нырнуть. Не приспичит — держать голову над водой.
Программирование — это не наука, это смесь ремесла и искуства. Кусок программирования уводит нас в район теории алгоритмов, кусок — в другие интереснейшие области теории. Но, основная часть — это навык, а не знания. Навык отличается от знания в том, что знание всегда либо ищет ответ, либо опирается на другие знания; а навык опирается на опыт.
Таким образом надо уметь в нужный момент прекращать искать знания и начинать рабатывать опыт. Одно другое не исключает (знания сильно помогают), но без опыта никакого результата не будет, даже если вы выучите все курсы MIT'а наизусть.
Программирование — как рисование. 10000 часов теории сильно помогут вам научиться рисовать. 10000 часов рисования научат вас рисовать.
Что надо делать: программировать. Берёте и пишите программу. Копипаста, "оно работает но я не знаю почему" и т.д. Опыт — важнее, чем 100% понимание происходящего.
Копипаста, "оно работает но я не знаю почему" и т.д. Опыт — важнее, чем 100% понимание происходящего.
гхм, это однозначно вредный совет.
я понимаю, что это продолжение вот этого правильного совета:
Вместо этого надо уметь принимать часть решений на веру. Запоминать, что там "есть что-то такое" и вовремя останавливаться. Приспичит — можно нырнуть. Не приспичит — держать голову над водой.
но бездумная копипаста ни к чему хорошему не приводит (и не учит программировать тоже).
"Бездумную копипасту" придумали вы. Я говорил про копипасту. Она — основна для начала изучения любой области. Берёшь готовое и пробуешь использовать. Работающее можно ломать и смотреть как оно не работает (или работает). А если работающего нет, что ломать не понятно.
"оно работает но я не знаю почему"
это можно понять как руководство к действию: «работает — и ладно, нечего разбираться»
Вы не можете копипастить код не разбираясь — он не будет работать. Переменные не те, отступы не те и т.д. Как только начинаете "сшивать" код, начинаете разбираться. Хотя бы поверхностно — но для общей интуиции очень полезно.
вы недооцениваете упорство и нежелание думать некоторых людей.
«что тут думать, прыгать надо»
про это даже на stackoverflow написано «this practice should be avoided»
то выражение типа N=N+1 и более сложные уравнения меня загоняли в легкий ступор.Потому что это никакая не математика. Это инструкция для процессора достать число из ячейки с именем N, прибавить к нему 1 и снова положить в ячейку N. Это инструкция для машины а не уравнение. То что это выглядит как уравнение — плохая аналогия, сбивающая с толку. На самом деле здесь записано что-то типа «PutTo N value (N+1)».
То что это выглядит как уравнение — плохая аналогия, сбивающая с толку.
Чем глубже я ухожу в хорошо написанный код, тем больше там оказывается этих "туманных абстракций". В системе конфигурации реализовывать ковариантное или контрвариантное наследование свойств? Является ли exception методом сохранения инварианта функции?
Забавно, что большая часть теоретических результатов CS, применяемых для "конструктивного программирования" (другого у нас нет) доказывается неконструктивными методами (собственно, одним-единственным — диагональным методом Кантора).
Вот только не надо считать конструктивными методы, которые говорят "возьмите бесконечное множество элементов бесконечной длины, разложите их квадратной матрицей, для каждой из бесконечного числа позиций, выполните вот это простое действие...".
В системе типов результатом такого вычисления будет bottom type.
fn diagonal_build () ->! {
loop {
loop {
...
}
}
}И без единого break'а, замечу. Чистой воды divergence type.
Во всех учебниках по теории алгоритмов такой тип зацикливания принимается за ответ "нет" вне зависимости от того, насколько вкусные результаты нас ждут после достижения бесконечности.
Даже если мы примем, что это перечисляющий метод, то разрешающим он не является.
Потому что в финале у нас assert diagonal(S) not in S, что требует досчитать до бесконечности дважды.
Это как раз и есть разница между перечислимыми и разрешимыми множествами. Есть множества, которые мы можем перечислить (перечислять), но для которых мы не можем в конечное время дать ответ, относится ли данный элемент к указанному множеству или нет. Приличная доля всех теорем в теории алгоритмов с ответом "нет, не можем" как раз сводится к ситуации, когда перечисление есть, а разрешения нет.
(https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B5%D1%87%D0%B8%D1%81%D0%BB%D0%B8%D0%BC%D0%BE%D0%B5_%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%BE)
Теория алгоритмов говорит, что попытка разрешения для неразрешимого множества невозможна (алгоритм никогда не закончится). Собственно, в районе assert diagonal(S) in S мы это видим интуитивно, если S — бесконечный генератор.
Можно ли считать конструктивной математику, оперирующую неразрешимыми множествами? Я (основываясь на программистской интуиции) так считать не могу.
Вы подняли крайне интересный вопрос. Анализировать приятнее перечислимые множества и перечисляющие алгоритмы. При этом перечисляющие алгоритмы не дают нам ответа на наши вопросы, к ним нужно применить ту самую злосчастную функцию минимизации, после которой наш компьютер (может быть) зависает и никто не может сказать заранее зависнет он или нет.
Т.е. с точки зрения практического программиста, конструктивная математика — это математика, которая даёт нам независающие разрешающие алгоритмы. Т.е. она решает наши проблемы и не глючит.
При этом у нас есть теоремы, которые говорят, что статический анализ может быть только для перечисляющих.
Вот тут вот главная драма программирования и зарыта.
Вот где-то тут мною прочитанная книжка либо убежала в скучные дали, либо не осветила этот вопрос. Вообще, практические и философвские вопросы разобраны там на удивление скудно. Видимо, сказывается то, что автору хотелось про теорию алгоритмов рассказывать, а не про программирование (а мне интересно было больше про последствия для программирования).
Забавно, что большая часть теоретических результатов CS, применяемых для «конструктивного программирования» (другого у нас нет) доказывается неконструктивными методами (собственно, одним-единственным — диагональным методом Кантора).Доказательство само по себе — это уже нечто не совсем конструктивное, потому что «конструктивный» факт можно просто проверить. Вообще, это удивительная загадка, как не детерминированная по своей сути нейронная сеть мозга может воспроизводить такую вещь, как доказательства, которые предполагают 100% уверенность. Например, если мы видим довольно сложный, если его разобрать до бита алгоритм, который увеличивает счетчик до 5, а потом сбрасывает на 0 и повторяет, то мы точно знаем, что число 6 там не появится. В этой уверенности первично ощущение нейронной сети, что такого не может быть никогда. А все формальные доказательства — вторичны, и предназначены только для того, чтобы привести нейронную сеть мозга в состояние уверенности. Когда-то математика и наука об интеллекте сойдутся в одно целое и это было бы очень интересно.
Ну, бывают конструктивные доказательства. Например, хорошим вариантом доказательства существования чего-либо является эффективный алгоритм его конструирования.
А насчёт "уверенности нейронных сетей" — броуновское движение молекул полностью хаотичное, но мы можем быть полностью уверены, что молекулы не сгруппируются в половине комнаты сами по себе. Все "уверенные" события — всегда результат микроскопической вероятности обратного; поскольку "снизу" там квантовая физика с волновыми функциями, мы никогда не может быть уверены, что какое-то событие произойдёт точно, просто вероятность обратного такова, что ей можно пренебречь.
В каком-то смысле это как анализ через пределы. dt устремляем к нулю, и отбрасываем ничтожно малые.
N=N+1Дело в том что после этой записи практически сразу следовала задача. Мое подсознание автоматом применило аналогию с формулой a=b+c, ну и следом представилось а=а+1.
PutTo N value (N+1)Благодарю за разъяснение, теперь разобрался.
В программировании математика как таковая не нужна.
Математика и программирование — отличающиеся вещи. Очень большая ошибка полагать, что программирование будет похоже на математику. Это верный способ так и не понять элементарных вещей.
Есть две большие ошибки.
Первая, считать, что программирование состоит только из обычной математики.
Вторая, считать, что в программировании математика вообще не нужна.
Начнем с того, что программирование само по себе некоторыми считается (не без оснований) разделом прикладной математики. И, если принять это, получаем, что изучая программирование человек изучает математику.
Кроме того, даже самому убогому формошлепу нужны азы арифметики и геометрии (отличить прямоугольник от круга и прикинуть количество строк, влезающих в элемент интерфейса). А это, внезапно, тоже математика.
На более серьезных уровнях программирования вылезают другие разделы математики — булева алгебра (те самые операции над битиками), теория множеств и т.п. И что занятно, многие, пользуясь всеми этими математическими знаниями, отрицают то, что они используют математику.
Описание предметной области, внезапно, очень часто без сложной математики не обходится.
Если есть желание понимать, "о чем программа", а не замыкаться в своем уютном мирке исполнителя чужих заданий, не понятных смыслом своим, то знать хотя бы основы высшей математики просто приходится.
Ну и еще математика тренирует многие навыки, потребные при программировании.
А уж как в некоторых случаях тяжело работать с программистами, отрицающими необходимость математики в программировании.
Но и замыкаться на "чистой математике" нельзя. Ее недостаточно. Еще нужны лингвистические навыки в виде как минимум умения связно выражать то, что должна делать программа, на используемом языке программирования.
Кстати, еще один пример проникновения "ненужной" математики в различные сферы, в том числе "исключительно гуманитарные" ("лингвистам математика точно не нужна", (с) школьник старших классов, желающий поступать на соответствующий факультет вуза).
Впрочем, математическая модель, описывающая объекты, изучаемые лингвистикой, не обеспечивает сама по себе владение лингвистическими навыками, как и уравнения математической физики — это далеко не вся физика, хотя без математики в физике уже давно совсем никак.
хотя без математики в физике уже давно совсем никак.
это далеко не вся физика,
а что вы знаете в физике — что не является математикой?
Как минимум интерпретация математических выражений применительно к окружающей реальности.
U=IR не имеет особого смысла без представления о том, что такое напряжение, сила тока и сопротивление, и какова их природа.
В математике нет понятий сопротивления, напряжения и силы тока.
Математика описывает только зависимости между этими величинами.
Или, если не замыкаться в рамках закона Ома, математика в рамках физики описывает только закономерности в поведении и структуре физических объектов и их систем. Интерпретация смысла знаков в уравнениях — это уже не математика, а физика
При этом одна и та же математическая конструкция может описывать разные физические процессы. И знание, какой именно процесс в данном конкретном случае описывает данное уравнение, лежит вне пределов математики.
В математике нет понятий сопротивления, напряжения и силы тока.
В математике нет понятий сопротивления, напряжения и силы тока.
математика в рамках физики описывает только закономерности в поведении и структуре физических объектов и их систем.
И знание, какой именно процесс в данном конкретном случае описывает данное уравнение, лежит вне пределов математики.
Эти понятия — более высокий уровень абстракции, точнее сказать — прикладной
Вот этот уровень абстракции и есть та физика, которая совсем не математика
Попробуйте без математики объяснить зависимость напряжение от силы тока, чисто физическими понятиями.
Это естественно для современной физики, и я никак это не оспариваю, но есть нюанс.
U=IR
F=ma
С точки зрения математики это одно и то же — одна величина равна произведению двух других. Только "переменные" промаркированы по разному (что может с точки зрения математики говорить как о принципиальном различии смысла величин в формулах, так и о том, что это просто разные случаи одного и того же).
С точки зрения физики это два совершенно разных физических закона из разных разделов физики (тот самый более высокий уровень абстракции).
U=IR
С точки зрения математики это одно и то же — одна величина равна произведению двух других.
Начнем с того, что программирование само по себе некоторыми считается (не без оснований) разделом прикладной математики.
Я долго вникал почему 0 в степени 0 равен 1, и у меня ощущение что я до конца так и не понял всей сути.
На мой вопрос: «как решаются такие уравнения?», ответ был очень прост: «учи исследование функции, начало анализа и задачи на оптимизацию. Алгебра 10-11 класс».
Начинаю осознавать, что для полной картины понимания Computer Science, мне необходимо будет заново учить алгебру, а затем и ВысшМат.
Программисту математика нужна именно как точка опоры, в основном ради абстрактного мышления.
Не соглашусь. Я давно заметил, что из крутых математиков редко получаются хорошие программисты. Понимание навороченных математических абстракций слабо связано с пониманием абстракций программистских.
Иначе, как вы будете придумывать собственные алгоритмы, не имея абстрактного мышления? Возможно только тупое использование чужих наработок, но любой шаг в сторону будет очень болезненным.
Так современное программиование — это не придумывание новых алгоритмов, а переиспользование уже существующих. Велосипеды обычно не нужны, потребность в новых реализациях и новых алгоритмах не насколько велика.
Пример, возьмите опенсорсную библиотеку компьютерного зрения OpenCV. Ее использование – современный тренд в распознавании чего-либо с помощью элементов искусственного интеллекта. Так там большинство алгоритмов используют не просто высшую математику, а математику из арсенала мехмата МГУ, т.е., нечто запредельного уровня сложности.
Вот только эта библиотека разрабатывалась не математиками для математиков, она нацелена на широкие массы. Да, там реализованы сложные алгоритмы. Но пользователю этой библиотеки совершенно не обязательно уметь эти алгоритмы реализовывать самостоятельно.
Не соглашусь. Я давно заметил, что из крутых математиков редко получаются хорошие программисты. Понимание навороченных математических абстракций слабо связано с пониманием абстракций программистских.
Так современное программиование — это не придумывание новых алгоритмов, а переиспользование уже существующих.
Вот только эта библиотека разрабатывалась не математиками для математиков, она нацелена на широкие массы. Да, там реализованы сложные алгоритмы. Но пользователю этой библиотеки совершенно не обязательно уметь эти алгоритмы реализовывать самостоятельно.
Велосипеды обычно не нужны, потребность в новых реализациях и новых алгоритмах не насколько велика.
Увы, реализация нужного алгоритма очень глубоко интегрирована в фреймворк — просто так его не «выкусить» отдельно.
Что тут можно сделать? Портировать весь фреймворк на нашу платформу. Возможно.
а какой смысл в использовании столь экзотической архитектуры?
унаследованный код — понятно, но вы же, судя по вашим сообщениям, занимаетесь активной разработкой.
Менее года назад я был в Буэнос-Айресе на встрече с группой пользователей этой системы. По окончании встречи молодой репортер газеты «La Nacion» спросил меня: «Сформулируйте, пожалуйста, коротко причины того, почему в AS/400 столь много новшеств?». И я ответил: «Потому что никто из ее создателей не заканчивал MIT.» Заинтригованный моим ответом, репортер попросил разъяснений. Я сказал, что не собирался критиковать MIT, а лишь имел в виду то, что разработчики AS/400 имели совершенно иной опыт, нежели выпускники MIT. Так как всегда было трудно заставить кого-либо переехать с восточного побережья в 70-тысячный миннесотский городок, в лаборатории IBM в Рочестере практически не оказалось выпускников университетов, расположенных на востоке США. И создатели AS/400 — представители «школ» Среднего Запада — не были так сильно привязаны к проектным решениям, используемым другими компаниями.
Френк Солтис, „Основы AS/400“
И почему указатели 16-ти байтные при терабайтах памяти?
У Солтиса это разъяснено. Не то чтобы он убедил, но по крайней мере объяснил мотивы.
Но конкретная реализация может и сократить их длину.
Ваша система вызывает страх и ужас. Своей изощренностью, закрытостью и уникальностью. Это действительно другой мир, который принять могут «не только лишь все».
Думаю, что сразу можно предположить, что в системах подобного типа нет вирусов. Это так?
А как насчет интерфейсов программ? Насколько удобно иметь с ними дело?


И почему указатели 16-ти байтные при терабайтах памяти?
Программы, и прикладные, и системные адресуют объекты при помощи 16-байтовых указателей; которые точнее было бы называть 128-разрядными (их используют все прикладные программы с момента появления System/38 в 1978 году). Но не все разряды: этого указателя используются, поэтому AS/400 обычно не называют 128-разрядным компьютером. Указатель содержит 64-разрядный адрес одноуровневой памяти, а также несколько разрядов дескриптора и неиспользуемые разряды, зарезервированные для будущих расширений.
И, интересно, а дома вы какую операционку используете?
Вы хорошо объясняете, может быть, у вас талант технического писателя?
Какой смысл вникать в ее закрытые системы, если нет ни желания, ни возможности там работать?
Спасибо. Талант не талант, но все свои наработки всегда документирую. Как для других, так и для себя.
Я читал Солтиса, но проблема этой книги в том, что она переполнена совершенно нетехническими восторгами по поводу буквально каждой мелочи. Есть какая-то более сухая альтернатива (но связная и последовательная, а не внутренние доки)?
при x, меньших нуля, эта функция неопределенна
На вашем рисунке нет никакой функции в отрицательной полуплоскости аргумента.А вот я вижу, что есть:

Поэтому непрерывности, при x < 0, у этой функции нет, а гладкости тем более. А поскольку речь шла, о предельном значении по непрерывности справа, то я и утверждал, что данная функция не определенна по непрерывности слева.А вольфрам считает иначе: www.wolframalpha.com/input/?i=lim+x%5Ex+as+x-%3E0-
Сложнее вопрос обстоит с рациональными аргументами, здесь помимо действительных, могут быть комплексные значения, а для отрицательных иррациональных чисел функция не определенна даже в комплексной плоскости и вообще для любых числовых множеств.
Вас такой ответ устроит :)?Не устроит, ибо я не вижу на графике разрывов.
Не устроит, ибо я не вижу на графике разрывов.А то, что в левой части графика изображена комплексная функция, вы видите? На рисунке представлены действительная (real) и мнимая (imaginary) части комплексного значения. Действительного предела (по непрерывности) слева для этой функции нет. Есть только предел слева для real-части комплексного значения. А это, как бы, не одно и то же.
Тоже самое для минус пи в степени минус пи. Это выражение многозначно, как, скажем sin(x) на бесконечности.
Скорее оно многозначно так же, как квадртаный корень: sqrt(4) — это либо +2, либо -2. Но вы же не хотите сказать, что квадратный корень — разрывная функция?
Простите, что с вами спорю, но "неопределена" и "многозначна" — разные понятия. Функция sin(1/x) в нуле неопределена — у нее нет значения. Функция x^x определена везде, включая x = 0 и x = -pi, и при определенных аргументах она многозначна.
Ситуация с извлечением корня и возведением в степень x^x ровно одна и та же. У этих функций есть разные ветви, и нужно для каждого конкретного применения эту ветвь выбирать. Просто для корня в силу его популярности решили, что обычно проще использовать одну конкретную ветвь. При этом если рассматривать эту ветвь, но такая комплексная функция по необходимости получается разрывной. Вот и с x^x то же самое — если брать "обычную" ветвь логарифма, то неоднозначности не будет. И такая функция тоже будет разрывна — всё как у sqrt.
В треде, к которому относятся эти комментарии, речь про комплексные числа и соответсвующие функции. Хоть в школе хоть не в школе, у функции корня при этом никак не одно значение.
Если коротко, то функция y = x^x аналитическая на всей комплексной плоскости, за исключением может быть каких-то особых точек. Функция эквивалентна следующей: y = exp[x ln(x)], поэтому если логарифм аналитичен для всех комплексных x, тогда проблем нет — мы рассматриваем композицию аналитических функций.
Пусть x = r exp[i q], тогда ln(x) = ln(r) + i q, это основная ветвь логарифма, остальные отличаются на 2pi, т.е. i q, i (q + 2pi), i (q + 4pi) и так далее. Таким образом, при x = x_r, где x_r — строго отрицательное вещественное число, представимое как |x_r| exp[i pi], то ln(x) = ln(|x_r|) + i pi. Т.е. логарифм определен для всех отрицательных вещественных чисел, x ln(x) тоже, exp[ x ln(x)] тоже.
Остается проблема x = 0. Формально, ln(x = 0) = -Inf, но это не помогает. Попробовать разобраться можно так: посмотрим, как себя ведет x ln(x) при x близком к 0. Если эта величина примерно 0, значит x^x = exp[ x ln(x)] = exp [0] = 1 и проблема решена. Можно попробовать приложить правило Лопиталя, у которого есть ряд ограничений, но суть такова: если у вас есть две 'хорошие' функции, предел каждой из которых в какой-то точке это 0 или бесконечность, а вы хотите найти предел отношения этих двух функций, то если существует предел отношения производных этих двух функций (функции хорошие и должны быть дифференцируемы вплоть до предельной точки), то предел отношения этих двух функций равен пределу отношения их производных. Прикладываем эту теорию к нашему случаю:
x ln(x) при x -> 0 это f(x) / g(x), где f(x) = ln(x), g(x) = 1/x, обе функции 'хорошие' вплоть до x = 0, обе стремятся к бесконечности. Берем производные, получаем f'(x) = 1 / x, g'(x) = - 1/x^2, предел отношение f'(x) / g'(x) = (1 / x) / (-1 / x^2) = -x, что при x -> +0 едет к -0. Таким образом, x ln(x) при x = 0 это 0*, а значит exp[x ln(x)] = 1, а значит x ^ x при x = 0 это 1.
Как проверить численно? Берем убывающую последовательность x = 1 / w, где w = 10, 100, 1000, 10000, ..., считаем exp [x ln(x)] = exp [- ln(w) / w]. Не силен в питоне, но вот такой говнокод
import numpy as np
[np.exp(-np.log(w) / w) for w in
[10 ** i for i in range(1, 20, 2)]
]выдает
[0.7943282347242815, 0.9931160484209338, 0.9998848773724686, 0.9999983881917339, 0.9999999792767343, 0.9999999997467156, 0.9999999999970066, 0.9999999999999655, 0.9999999999999996, 1.0]Если я не ошибся, то (-pi)^(-pi) = pi^(-pi) (cos(pi^2 + 2 pi^2 n) + i sin(pi^2 + 2 pi^2 n)), где n — целое число. Интересный результат заключается в том, что не существует чисто вещественного значения, потому что для этого необходимо, чтобы pi^2 + 2 pi^2 n = 2pi k, где k — целое, или n = k / pi - 1/2. Если k=0, n = -1/2 и не целое, k!=0 — n даже не рациональное, а скорее всего трансцендентное. Т.е. (-pi) ^ (-pi) представляет собой бесконечное количество чисто комплексных чисел, расположенных на окружности r = pi^(-pi).
Не уверен правда, что это легко показать с помощью двух по-разному сходящихся последовательностей, нужно придумать пример.
Моя попытка была показать, что 0^0 = 1 это не просто 'кто-то так решил', а это действительно предельное поведение функции x^x в 0, и что с помощью комплексных чисел это можно прямо посчитать.
Моя попытка была показать, что 0^0 = 1 это не просто 'кто-то так решил', а это действительно предельное поведение функции x^x в 0, и что с помощью комплексных чисел это можно прямо посчитать.
x^x имеет пределы с обеих сторон от 0, эти пределы равны, это даже видно из графика который вам присылали:
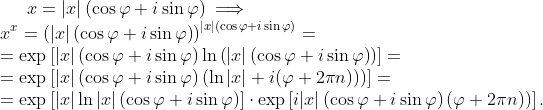
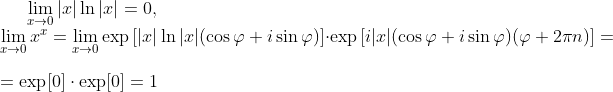
Значение предела не зависит от того, с какой "стороны" к нему приближаться. "Сторона" регулируется phi — для 0+0 phi = 0, для 0-0 phi = pi, а если с чисто мнимой оси, то phi = +- pi/2. Любые значения между тоже допустимы.
Слева предел не существует, просто потому, что x^x не является непрерывной функцией и даже, вообще говоря, однозначной.Напоминаю, вольфрам считает иначе: www.wolframalpha.com/input/?i=lim+x%5Ex+as+x-%3E0-
А я всё думал, когда же дойдёт до этой функции. Осталось только заявить, что иррациональных чисел больше, чем рациональных.
Только вот эта функция не имеет никакого отношения к x^x. И поэтому обсуждать, чему равен интеграл от функции дирихле я не стану.
Смотря что вы имеете ввиду под 0^0. x^x имеет предел единицу, x^(1/ln(x)) = exp(ln(x)/ln(x)) = exp(1) это вообще константа и любой ее предел будет exp(1).
Ну т.е. ситуация 0^0 это ситуация f(x) * g(x) где f(x) -> 0 а g(x) -> inf. А дальше все просто — какие функции выберете, такой результат и получите. Вот в 0 x быстрее едет к 0 чем ln(x) к -inf, поэтому x^x в нуле будет единицей. Возьмите вместо ^x степень, которая будет ехат к 0 медленнее чем ln(x) к бесконечности — получите предел exp(-inf) = 0. Делов-то.
inf/inf не то что неопределённость, а даже смысла не имеет, потому что в R нет такого элемента, как inf.Поэтому есть дополненный R
Но какова причина вводить 0^0 как неопределённость?Почитайте учебник высшей математики, или погуглите.
Вы не вводите 2^3 как неопределённость просто потому, что неопределённость и всё?Это же вполне конкретное число.
Чему равно 2 \infty?
signum тоже в нуле имеет неустранимый разрыв, что не мешает ей быть в нуле определённой.
Операция взятия целой части (или дробной части) тоже имеет довольно много неустранимых разрывов.
Ну и 0^0 — вполне конкретное число
Ничего запредельного там нет. За запредельное получают Филдса, а не зачёт по матану и линалу на младших курсах. Давайте всё же не девальвировать определения.
Физкультура ещё была. Из-за физкультуры я тоже чуть не вылетел, дважды.
Когда я несколько лет назад занимался машинным обучением, у меня не было проблем с тем, чтобы взять произвольную статью с arxiv и зашарить, что там происходит. Математика в машинном обучении на самом деле довольно простая.
Хотите запредельное — возьмите Жирара и почитайте восьмую главу и дальше.
Почему жы все нетехнари пытаются зайти в самые высококонкурентные сферы программирования. Сфера мобильной разработки и вообще Java — высококонкурентна. Обратить стоит лучше усилия на WEB разработку. Особенно на фронтенд. Знаю много гуманитариев преуспевших на фронтенде как таковом при большом желании. Математика там вообще не нужна. Профессия скажем react разработчика котируется везде и в России и в Европе и Америке. Но не нужно циклиться на книгах. Набирается минимум знаний из книг и люди устраиваются джуном в офис. Там учиться надо у опытных людей. Потом поменяв несколько работ, и поднявшись хотя бы до реального миддла, можно пытаться устраиваться зарубеж. Без реального опыта в офисе хорошим разработчикам не стать никак. У кого-то до крепкого миддла путь по офисам занимает год, у кого-то 5. Тут уж все зависит от желания учиться.
Там очень много некомпетентных разработчиков. Много просто знающих по верхам HTML и css. Среди java программистов или C# не найдешь тех, кто не знает паттерны разработки и работу с БД и сервером, во фронтенде сплошь и рядом. В фронтенде гораздо ниже порог входа в разработку. Но реально грамотных разработчиков во фронтенде знакомых со всеми тонкостями JS и построения правильных архитектур, глубокими знаниями js фреймворков днем с огнём не найдешь — они всегда при деле и имеют зарплаты не ниже всех остальных разработчиков в других языках с таким уровнем.
И вот на первом уроке по программированию я всегда говорю, что программирование — это в первую очередь математика. Если в голове нет математики, то никакого программирования не получится. Соответственно, если дитятко решило пойти в вуз по направлению программирования (а это я узнаю, потому что нужно сдавать ЕГЭ по информатике)Я правильно понял, что в качестве разработчика вы не работаете, и при этом судите о программировании основываясь на задачах из егэ?
ближайшие несколько лет векторами, матрицами и прочими тройными интегралами вперемешку с диффурами, ведь всё равно мозгов на матанализНе стоит путать полезную в программировании линейную алгебру, с довольно бесполезным матанализом.
Я правильно понял, что в качестве разработчика вы не работаете, и при этом судите о программировании основываясь на задачах из егэ?
он говорит, что ученики, выбравшие информатику на ЕГЭ без достаточного знания математики, ошибаются.
потому что в ВУЗе на тех специальностях, на которые можно поступить по результатам этого экзамена, будет много высшей математики.
Почему вы думаете, что ваша "вражда с математикой" не является "враждой со школьным/институтским преподавателем математики"?
Вы бы хоть постеснялись публично такие вещи говорить. Потому что вам скорее всего с окружением в детстве повезло, в генетической лотерее выиграли и поэтому получилось наверстать необходимые навыки мышления другими способами.
Но широкая публика ведь видит только верхушку айсберга и будет думать что математика действительно не нужна. Потом индивидуумы из широкой публики пытаются осилить программирование и у них закономерно возникают проблемы. И приходится им наверстывать навыки мышления применительно к программированию, хотя можно было бы проще и раньше.
Я сочувствую, что у вас такие обстоятельства.
Но в свете них ваш посыл еще более вреден. У вас — типичная ошибка выжившего. На одного такого как вы приходятся миллионы людей, которые так и останутся в своем окружении алкоголиков.
Вы хотите чтобы все вокруг превозмогали так же как и вы когда-то?
А автор статьи человек взрослый. И ему все это программирование не очень интересно. Ему нужны деньги и только.
Вот откуда берётся подобный максимализм?Преподаватели делятся на 2 типа: первые считают, что их предмет самый важный, а вторые — что единственный.
Ну а я преподаю в университете. И сделал вывод, что познания в математике вообще никак не коррелируют со способностями писать код. Да, есть корреляция между математическими способностями и способностями придумывать и реализовывать алгоритмы. Но и без математики вполне себе можно быть высокооплачиваемым формошлёпом.
Но и без математики вполне себе можно быть высокооплачиваемым формошлёпом.
Интересы решают. Если человек умеет и в математику, и в программирование, то он в итоге сваливается в то, чем ему нравится заниматься больше: становится либо крутым математиком, либо крутым программистом.

Ну perl язык с точки зрения прода — так себе, больше похож на эзотерический язык — чего только стоят программы из одной строки.
… я как «хомяк в колесе», вроде как бы и бегу (учусь), а по факту стою на месте.К сожалению столкнулся с точно такой-же ситуацией=( Было интересно изучить Kotlin не имея за спиной ничего связанного с dev. Но все свелось к тому, что помимо изучения синтаксиса, в котелке должен быть определенный бэкгрануд, на изучение которого уйдет ещё больше времени, чем на изучение конкретного языка.
Или все-таки это не моё? И профессия «разработчик» — это для элиты, «касты особенных людей»?
Автор себя загрузил чисто психологически. Постараюсь подсказать решение. Учился в школе 8 классов, потом в училище 3 года. Но потом решил поступить в политех и так как надо было сдавать вступительные экзамены — то выяснилось, что у меня немаленький такой провал в знаниях за последние 5 лет учебы. С осени родители заплатили за заочные подготовительные курсы, там мне дали материалы и задачи, которые я должен освоить и научиться решать, чтобы успешно сдать экзамены. Но до нового года я еще ходил на учебу в училище, после была практика. Так как работать по профессии я не хотел(передумал), то решил приложить все усилия, чтобы поступить в политех. Для этого решил прогулять двухмесячную практику(но без последствий) и вместо неё каждый день самостоятельно по 5-6 часов учился. Учился следующим методом — взял толковые учебники и вначале полностью прочитывал одну тему по которой были задачи из подготовительных курсов, потом решал эти задачи, а формулы и основные понятия и способы решения записывал на отдельных листочках А4. Таким способом за 2 месяца я освоил материал за последние 5 обучения, успешно здал экзамены — более 80 баллов(82 и 84) из 100 и успешно поступил в политех на бесплатное обучение да ещё и со стипендией. Так что тут есть два урока: 1 в общеобразовательных заведениях все обучение очень разтянуто во времени и освоить эту информацию можно за короткое время; 2 — если не отчаиваться, то при определенном усердии можно освоить даже очень большой объем информации за разумное время.
Но для начала такого обучения я бы посоветовал прочитать книгу "Думай как математик" Барабары Оакли, там есть все необходимые психологические моменты и подходы для успешного даже очень сложных наук и решения задач любого уровня сложности и глубины. Ну чтобы было интересно при обучении, то придумайте и создайте небольшое приложение или сайт в той области где хотели бы работать, первый блин может получится комом, но заметите что чем дальше — тем все лучше и быстрее у вас будет получаться. Это я к тому, что обучение без практического применения — это как научиться водить без машины. И тут на хабре есть много толковых планов по обучению например. Так что все в ваших руках!
P.S. и было хорошо после того как вам тут дадут много советов в комментариях, узнать ваши выводы в конце статьи. Успехов!
Переводчик – это специалист, который умеет не просто перевести, но и интерпретировать речь или текст с одного языка на другой.
В строительстве есть еще проектировщики разных разделов, которые как раз и выступают "переводчиками" между архитектором-гуманитарием и строителями. И в IT то же самое — кто-то визуализирует желание заказчика в архитектуру, а потом кто-то рубит код разной степени "технарности". Даже если это один и тот же человек, это разные роли. Автор комментария выше, похоже, этого нюанса не учел.
— Бывает гусеница, а зайка? Червячок, а верблюд?
— Юра, ну что ты какие спрашиваешь глупости!
Сейчас же — «глупости». И сейчас же предположение, что ребёнок болтает зря, только чтобы болтать. Юра краснеет.
— А как же бывает жук-олень, жук-носорог?(с)
Мне кажется, что все это — наоборот, хороший знак. То, что вы решили докопаться до основ, а не фигачить формочки в продакшон, как некоторые любят. Да, это не простой путь, да, он займет больше времени, но, мне кажется, вы осилите. Главное — найти мотивацию, т.е. не просто молотить книги, но и закреплять практическими задачами. Мне кажется, я знаю алгебру 10-11 класса только потому, что она помогала мне тогда постигать программирование, а не наоборот.

Если закончилась еда, то <сходить в магазин>.
Процедура <сходить в магазин>:
Дойти до магазина.
Купить нужные продукты.
Вернуться домой.
А скажите, только у меня, гуманитария(*), вопрос, откуда вообще взялась задача про скотный двор? Программист ее решит, вообще не имея представления о математике. А потом еще и оптимизирует это. И в этом весь смысл — программистское решение задачи даст на порядок больше знаний и навыков, чем математическое.
Очень печально, что автор поста не понимает, что тут главное:
предполагает определенное знакомство с основными понятиями программирования такими как переменные, операторы присваивания, циклы, функции
И если вот этого "определенного знакомства" нет, то суши весла. Ну в самом деле же!
(*) de jure у меня есть свидетельство среднего образования "лаборанта-программиста", но де-факто и по диплому я гуманитарий.
На мой взгляд неправильно говорить, что вы изучили основы программирования "за месяц", если до этого год "теряли" на сценарий автора статьи.
Потому что обучение у вас происходило в тот год, о котором вы в своем комментарии решили много не рассказывать.
нужна боевая модель обучения СРАЗУ на проектах (конечно изучив основы предварительно, 1-2 месяца максимум)
Я все еще сомневаюсь в таком подходе. Потому что если человек не потратил год вечеров на изучение тех самых основ языка, то при получении ТЗ на проект будет просто ступор: "Что тут вообще делать?".
Я согласен, что для человека важна мотивация к изучению, но это не обязательно должно быть изготовление чего-нибудь полезного и применимого. Многим достаточно ощущения прогресса и одобрение со стороны преподавателя.
Заметьте, у вас все таки сначала был год разбирательства с основами, а уже потом — месяц того, что вы называете "изучением js". Поэтому ваш пример не совсем подходит для доказательства того, что подход "сразу боевой проект" — удачная идея.
Чтобы наглядно показать что этот подход работает, нужно взять человека который действительно раньше никак не изучал программирование и дать ему боевой проект.
По моим наблюдениям, "основы за месяц" получается только у тех, кто уже раньше изучал программирование, пусть даже в школе и на другом языке.
выражение типа N=N+1 и более сложные уравнения
в 90-х годах, когда был выбор из 2-3 языков
Потому что Java не нужна. Учи Flutter.
твердо решил максимум за 1 год самостоятельно выучить Kotlin и строить планы по иммиграции на ПМЖ в США.Я считаю именно это главной причиной провала. Вам не нужен был ни Котлин, ни Джава как сама цель, вам нужно было ПМЖ в США. В принципе, я это часто вижу, ведь многие в профессию идут из-за денег, каких-то личных амбиций или иных причин, совершенно не связанных с программированием.
я это часто вижу, ведь многие в профессию идут из-за денег, каких-то личных амбиций или иных причин, совершенно не связанных с программированием
Если работник не засыпал с детства в обнимку с работой — это плохой работник, и он не может выполнять свои обязанности?
Если работник не засыпал с детства в обнимку с работой — это плохой работник, и он не может выполнять свои обязанности
В принципе, я это часто вижу, ведь многие в профессию идут из-за денег
он будет делать ровно то, за что ему платят
выполнять ровно то, что ему поручат.
Прогресс всегда и везде двигается энтузиастами
Это плохо?
Выполнять свои обязанности и двигать прогресс — это разве одно и то же?
Мне кажется, вы по умолчанию (почему-то) отождествляете работу программистом и развитие цивилизации.
Для человека же, профессия которого требует постоянного саморазвития это плохо.Не понимаю этого тезиса. На работу ходят за деньгами, и надо чётко соизмерять доход с затраченными силами и возможными проблемами из-за выхода в чужую компетенцию и за пределы должностной инструкции, иными словами — если сделать полезную для работодателя в понимании исполнителя штуку, что он получит: премию (какого размера?), почётную грамоту или по шапке за то, что занимался фигнёй, когда сроки горят. То же с «саморазвитием»: если работодатель хочет, чтобы исполнитель изучал новые технологии или инструменты после работы, то не исключено, что применяться полученные знания будут уже у другого работодателя. Короче, классика — «Кому надо, тот и платит».
Везде, где мне приходилось работать последние… сколько? лет тридцать, наверное… ценилась проактивность.Вам повезло, мне нет: где-то говорили большое человеческое спасибо, где-то оплачивали материалы в двойном размере и время как пойдёт, где-то ругали, утверждая, что это нам не надо, а потом с удовольствием пользуясь… Так что теперь только письменное распоряжения, ТЗ и в идеале предоплату. Не скажу, чья история более типовая, то ли я неудачник, то ли кругом куча мудаков :)
Вам повезло, мне нет: где-то говорили большое человеческое спасибо, где-то оплачивали материалы в двойном размере и время как пойдёт, где-то ругали, утверждая, что это нам не надо, а потом с удовольствием пользуясь…
Это говорит о том, что люди у нас работают малограмотные, либо бюджеты на разработку/проектирование очень сильно заниженыЯ бы не был столь категоричен. Зато я заметил другую особенность: процесс производства у нас куда важнее конечного результата. Всем наплевать, насколько ты гениален и крут, главное — это сдавать таски вовремя, не подводить руководство, не материться, не быть токсичным, соглашаться со всеми, поддерживать корпоративный дух. Обязательно приходить в белой рубашке. Не опаздывать к 8 утра. Улыбаться и не считать работницу ХР за свинью.
Зато я заметил другую особенность: процесс производства у нас куда важнее конечного результата. Всем наплевать, насколько ты гениален и крут, главное — это сдавать таски вовремя, не подводить руководство, не материться, не быть токсичным, соглашаться со всеми, поддерживать корпоративный дух. Обязательно приходить в белой рубашке. Не опаздывать к 8 утра. Улыбаться и не считать работницу ХР за свинью.
«у нас»? ИМХО это во всём мире так (скорее к нам пришло с запада)
Посмотрите на Яндекс, Mail, VK и т.д. все эти продукты очень сильно уступают своим зарубежным аналогам(жалкое подобие)
а можете подкрепить свои тезисы конкретными примерами?
да, мне поиск и переводчик от яндекса нравятся меньше, чем гугловские аналоги, но говорить «жалкое подобие» я бы не стал, отличные продукты на самом деле, просто у гугла ещё чуть лучше.
по поводу vk и fb — плотно не пользуюсь ни тем, не другим, но явно, что в области UI/UX fb проектируют марсиане, в vk старательно копируют, но тут уже работают человеки, волей-неволей у них получается более user-friendly.
либо бюджеты на разработку/проектирование очень сильно занижены
разумеется, бюджеты локальных русскоязычных продуктов будут на порядки ниже, чем глобальных (или даже локальных штатовских, европейских и китайских). просто потому, что экономики разные по масштбам, да и людей у нас меньше.
какое недоумение у них вызывают online-сервисы иностранных банков, после того, чем они пользовались в России.
у нас вендор сказал что надо систему через год полностью обновить, все банки как один взяли под козырек и бахнули кучу ярдов на переписывание софта
Точно знаете? Что-то я такого не замечал у нас.
Конкретно у нас уже несколько лет взят курс на отказ от услуг вендоров и переход на разработку собственными силами.
И еще — пользовательские сервисы и «банковский софт» (что вы вообще под этим имели ввиду?) это две большие разницы
Ну вот что я видел, в конце 2000х приходит виза/mc и говорит, «к концу года у вас должна быть поддержка EMV и обязательный PCI DSS compliance (я застал времена когда он был еще опциональным), иначе фиг вам, а не продление лицензии»
точно также была история с PayWave и PayPass… типа «как минимум 70% точек должно его поддерживать, если нет — давайдосвидания, остальные 30% через год»
и что у вас и процессинговый софт самописный? я вот заметил обратную тенденцию в этой сфере.
я уж молчу, что в некоторых процессинговых системах нет транзакций в БД, помню у меня волосы на голове шевелились когда я писал модуль для этой штуки.
1) списываем со счета x руб
2) зачисляем на счет x руб
3) если мигнёт свет между 1 и 2… то в течении 5 дней бухгалтерия разъедется менеджеры увидят и поправят
4) «Это норма» (с)
+1) а теперь объясни клиенту что вообще происходит
+2) один зеленый банк, который несколько лет назад начислял штрафы по 2-5 рублей в месяц за овердрафт по дебетовкам, когда вы делали операции которые арифметически никогда не приводили к минусу
забавно, но я работал (относительно давно) в процессинге который был связан с альфой, хоть и не совсем напрямую, удивительно как вы не замечаете реалий :)
PCI DSS в 2006-м году стал обязательным стандартом для европы. Естественно, что все банки, которые попадают в эту юрисдикцию, обязаны ему следовать.
Странно, что сервера не прикрыты никакой резервной системой питания.
По поводу технических овердрафтов — тут от АБС зависит.
А на самом деле, вы должны знать что всегда периодически чтото падает у банков… если вы периодически общаетесь со своим коллцентром, то должны знать что существует такое событие как «сбер упал», когда это к вам никакого отношения не имеет но телефоны обрывают — вам и насколько часто такое происходит.
потом есть ночные остановки у всех банков на обновление ПО
простая операция:
1) вы перевели 100р через c2c например
2) вам упала смс что пришло 100р
3) вы их сняли в банкомате.
в реальности:
1) у отправителя ставится холд на 100р (на счете 100р, на балансе 0)
2) вам система пишет что у вас 100р (на счете 0р, на балансе 100р)
3) вы снимаете 100р в банкомате (на счете -100р, на балансе 0р, овердрафт!)
4) в течении 5-30 дней реальное бабло приходит и становится 0,0
5) банк начисляет штраф за овердрафт
На самом деле, это не остановка. Это переход на новый банковский день.
Правда, за это не штрафовали т.к. считалось что это особенность функционирвания системы.
У нас такого нет — все доступные остатки считаются с учетом холдов.
Карточный процессинг не останавливается при переходе на новый день, я имею в виду именно реальную остановку прода, когда вы не сможете расплатиться карточкой и сделать любую операцию по ней.
это для клиентов, банк то должен считать реальные деньги
плюс есть вполне реальная вероятность что операция всётаки не пройдет и тех.овердрафт превратится в настоящий
Для клиента для операций доступна сумма в виде остатка на счет минус сумма холдов. Это ограничение не дает ему уходить в технический овердрафт.
Тем более что они всё равно все потихоньку пеереезжают с Кобола, ну добавить к общей смене системы приличный онлайн-банк это же копейки. В чём там проблема?
Такой, чтобы вкладывать в ее решение сотни тысяч доллларов.
Может ли быть такое, что в решение деньги уже вложили, просто вы этого не знаете, т.к. варитесь в собственном соку?
Ну а легаси систему держат потому что она пока что справляется.
Может ли быть такое, что в решение деньги уже вложили, просто вы этого не знаете, т.к. варитесь в собственном соку?
Про модные даже речи не идет.
Хотя бы плюс-минус актуальные технологии.
Вы предлагаете все законсервировать, заманивать разработчиков деньгами и стабильностью и делать всего по минимуму. То что требуется регуляторами или без чего вообще работать нельзя.
Это же путь в никуда. Заманивать хороших разработчиков будет все тяжелее и тяжелее. Денег везде неплохо, писать черти на чем не хочется и в резюме плохо смотреться будет. Молодые и дерзкие точно что-нибудь придумают после чего у них будет на голову удобнее все. И захват рынка случится сам собой. Что это будет я не знаю. Наверно ни кто не знает, но точно что-то будет.
Не знаю насколько применимо но из свежего: момпнтпльные пернводы, одноразовые карточки, pci dss (для тех знает что такое) тянут на выкидывание с рынка тех кто не сможет так работать.
И все банки живущие в стабильности и экономящие сотни тысяч останутся у разбитого корыта.
Про модные даже речи не идет.
Хотя бы плюс-минус актуальные технологии.
Молодые и дерзкие точно что-нибудь придумают после чего у них будет на голову удобнее все.
Не знаю насколько применимо но из свежего: момпнтпльные пернводы, одноразовые карточки, pci dss (для тех знает что такое) тянут на выкидывание с рынка тех кто не сможет так работать.
Ну назовите «актуальные» с Вашей точки зрения технологии разработки под IBM i (софт, работающий на серверах IBM PowerS9). Фактически это менфреймы ориентированные на одновременную работы тысяч задач в фоне, с интегрированной в ОС БД DB2 for i
Повторюсь — это не сайт ООО «Рога и копыта», который упал на час, да и фиг с ним. Поднимем, гнилой палкой подопрем и дальше как-нибудь работать будет. Зато бантики вон какие красивые у нас. А что тормозит — так это у вас браузер хреновый — обновите и все будет.
И все, что придумают «молодые и дерзкие» на фронтах, будем реализовывать мы на уровне ядра. И реализовывать так, чтобы оно не перегружало сервера, даже в пике, чтобы оно правильно стыковалось с еще 100500 работающими на сервере процессами и т.д. и т.п.
Я не готов это вообще назвать актуальной системой. Не Кобол, конечно. Но уже неактуально. Насколько неактуально и пора ли переписывть? Не знаю. Кобол точно пора.
Зря вы с таким пренебрежением говорите о всех вокруг. Поверьте в мире есть много неглупых людей которые умеют делать хороший и надежный софт. И простои не только у вас стоят сотни миллионов в час.
Почем вы оцените простой крупного сервиса ФАНГ? Или поближе к нам час недоступности Вайлдберриз какого-нибдуь?
И чем старее ваши технологии тем это сложнее. Наслаивание легаси, сложность найма, неизвестность стека, сложность изучения.
Пока конкуренты с Коболом и технологиями 80х сидят Эппл просто предоставил нормальные услуги клиентам
Да и просто новые технологии они не просто новые, они лучше старых. Иначе бы они их не вытеснили. Вы каждый день тратите лишние силы на разработку из за устаревших технологий. Это тоже большие деньги. Тайм ту маркет стоит дорого.
Хорошо. Назовите актуальную. Которая удовлетворяла бы всем требованиям по производительности, надежности, способности восстановления в случае сбоя и т.д. и т.п. И скажите, в какой еще системе старое ПО при переносе на более современную платформу не только не потребует пересборки, но и автоматически подстроится под новые возможности и будет их эффективно использовать?
А заодно объясните, почему эта неактуальная система продолжает развиваться как на уровне аппаратуры, так и на уровне ОС.
Вы поймите, мы не предоставляем услуги клиенту. Мы делаем возможным это делать другим. С минимальными для них затратами. Если угодно — мы делаем тот самый «фреймворк», которым пользуются вася-петя-коля чтобы предоставить клиенту современную красивую услугу.
Не все так просто. Есть маркетинг. Который убеждает человека покупать то, что ему не нужно. И успех того же Эппла — это чисто маркетинговый успех.
TTM — палка о двух концах. Классический пример — MS Windows. Скорее выбросить на рынок недотестированный продукт чтобы занять нишу, а потом латать дыры бесконечными обновлениями (часть из которых закрывая одну проблему, приносит другую).
В общем, тут не все так просто. Вы смотрите сверху и не видите того, что скрывается внутри. Пользуетесь фреймворками, не задумываясь о том, кто их для вашего удобства сделал и как.
Эти проблемы успешно решены. У вашей платформы нет ничего что не было бы сделано в типовых вещах. Иногда по другому, но скорее лучше а не хуже чем у вас.
Джава отлично возится куда угодно. Без пересборки.
Хотя я не понимаю почему пересобрать это проблема.
А так все типовое. rest, база, очереди
У них именно прорыв по качеству сервиса, по сравнению с другими банками.
Банки в этом смысле самые медленные.
Боюсь, Вы бесконечно далеки от системного программирования.
Вот скажите, на какой платформе реализована одноуровневая модель памяти, не требующая переключения сегментов (перезагрузки сегментных регистров) при переключении процессов?
На какой платформе реализован TIMI (набор машинных инструкций, не зависящий от технологии), позволяющий автоматически персобирать исполняемый код при переносе софта на, например, новый процессор?
Вот вы сейчас серьзно? Правда думаете что hiload с 3млрд изменений (только изменений!) БД в сутки будет нормально работать на джаве? У нас под джаву выделен отдельный сервер (один из трех в кластере) и это вечная головная боль — низкая производительность при неумеренном потреблении ресурсов.
Вот скажите честно — вы когда-нибудь занимались разработкой на уровне ОС? Не вот эти все внешние красивые плюшки, а то, на что они опираются? Судя по Вашем взгляду на жизнь — нет.
Вы можете себе представить, что к сложному запросу по нескольким таблицам по несколько десятков миллионов записей в каждой может предъявляться требование что он должен выполняться не более 100мс (при том, что решение «в лоб» дает 1500-2000мс)? И этот запрос вызывается по несколько тысяч раз за день (например, проверка получателя платежа по спискам террористов-экстремистов, жуликов-мошенников, санкционным спискам, и еще черт знает по чему) с разным набором параметров.
Много вам лично приходилось работать с системами подобного масштаба? Именно на уровне ядра.
Для вас быстрые переводы C2C это просто удобный клиентский сервис, а для меня это длинная цепочка проверок (того же получателя надо по всем параметрам прогнать по всем спискам — совпадение имени полное-частичное, совпадение реквизитов ДУЛ, совпадение ИНН, уровни рисков, степени подозрительности и еще черт знает что) в первую очередь.
Считать и обновлять табличку отдельным процессом, на скорости запросов никак не скажется.
а как же всякие race conditions?
Глобально эта проблема в таких ситуациях решаема. И она всегда решаема так чтобы не аффектить чтение.
именно с балансом счёта — не уверен.
впрочем, балансы — это только малая часть; приводимые примеры с оценкой рисков точно могут быть легко кэшированы/шардированы/etc.
Боюсь, Вы бесконечно далеки от системного программирования. Вот скажите, на какой платформе реализована одноуровневая модель памяти, не требующая переключения сегментов (перезагрузки сегментных регистров) при переключении процессов?
Если дословно: x86, внезапно. Потому что "сегментные регистры" (CS/DS/ES/SS) в современных реализациях на x86-32 могут использоваться, но практически никто в современных ОС это не делает (все обычные Unix, и Windows, и пр. — один раз инициализируют при переключении в целевой режим и больше не трогают; для x86-64 они вообще несут в себе только указание на выбранный режим. Всё остальное делается только страничным механизмом.
А если учитывать, что в POWER та же страничная адресация — разницы тут и нет.
(Если быть въедливым — в POWER, точно так же как в zSeries, страничный механизм работает по комбинации address space + linear address. Но это становится важным только для виртуализации уровня ОС.)
Специфика AS/400, если въедливо читать источники — в том, что поверх этой плоской системы сделана объектная модель с контролем доступа. Возможно, тут страничная система помогает — а, возможно, и нет. Если нельзя произвольно создать ссылку на то, чего тебе не давали, проитерировать списки всех объектов и т.п., есть контроль доступа по правам и спискам и разделение пространств видимости по этим правам — то система надёжна даже при работе всех пользовательских приложений под общими правами. Но это, считаем, обеспечивает сейчас любой браузер (если исключить костыли всяких легасей). А вот чем именно тут могла бы помочь страничная защита, где границы между адресными пространствами — никакой Солтис не пишет.
На какой платформе реализован TIMI (набор машинных инструкций, не зависящий от технологии), позволяющий автоматически персобирать исполняемый код при переносе софта на, например, новый процессор?
JVM. Дотнет. Это только с ходу две, которые существуют уже десятилетиями.
И для них (как минимум для JVM) есть все варианты в диапазоне: интерпретация всегда; JIT после интерпретации; JIT на первом старте с возможной перекомпиляцией; AOT (ahead of time — предкомпиляция до старта) — активно используется, например, в Android.
Так что и тут нет ничего уникального. Новое — возможно, на 80-е (можно спорить, были ли подходы JVM мотивированы разработкой AS/400 или нет), но уникальность давно закончилась.
Так что "бесконечно далеки от системного программирования" давно вы тут (и, боюсь, книга Солтиса своими неуместными восторгами тут очень мешает объективному сравнению).
IBM берёт своё не этим.
Про highload на Java уже сказали — полно его. Хотя вот сейчас подумалось — любовь IBM к Java во внешнем слое может быть как раз вызвана сходством подходов :)
Вы можете себе представить, что к сложному запросу по нескольким таблицам по несколько десятков миллионов записей в каждой может предъявляться требование что он должен выполняться не более 100мс (при том, что решение «в лоб» дает 1500-2000мс)?
Я могу. Только не понимаю, при чём тут ОС. Больша́я часть успеха тут 1) достигается современным грамотным железом, и 2) собственно оптимизацией на уровне БД. От ОС требуется только чтобы мешала по минимуму :)
Ну ещё в случае AS/400, как прочитал, драйвера БД фактически находятся на уровне ОС. Это не обязательно хорошо — Oracle показывает работу и на плоских дисках.
Как вы сами написали новому разбираться надо чуть ли не годами.
А на тесте выяснилось, что региональные устанавливает она корректно, но снимает в процессе страновые.
Стали разбираться — выяснился косяк аналитика — не выделена отдельная группа под региональные риски. Опытный разраб это дело сразу бы просек и не тратил бы время, а ткнул бы аналитика носом. А неопытный потратил время на разработку неработающего модуля.
В каком еще языке есть нативный тип данных с фиксированной десятичной точкой (см. рекуррентное соотношение Мюллера, тут на эту тему была статья, как раз про кобол).
Я тут одного не понимаю — зачем именно нативный тип?
Полноценная реализация такого на любом процедурном языке это задача для студента на неделю или для спеца на день. Где-то оно будет, конечно, компактнее выглядеть, как на C++ или любом другом современном ООП языке с дженериками или темплетами, где-то не так явно, но будет.
Можно, конечно, вспомнить встроенную поддержку десятичной плавучки в zSeries и POWER, но вот в чём цирк — у неё не фиксированная точка. Поэтому я вообще плохо понимаю, зачем она такая (особенно с Chen-Ho BCD), для какой легаси она нужна? Может, кто объяснит (без рекламных лозунгов)?
И почему вы думаете, что все вот так прямо спят и видеть как бы работать на фронте с новомодными стеками (и бросать привычный стек каждый раз как появилось что-то более модное)?
Естественно, не все. Но работать на современном языке, который применим ещё где-то кроме тысячи банков, лучше, чем на древнем.
Я сейчас могу написать программу их нескольких модулей, включая кобол, С/С++ и еще других языках.
Ну вот поэтому плавная миграция должна происходить.
Переходить с Кобола все равно придется. Как нанимать на него я не представляю. Даже если залить деньгами желающих не очень много будет.
Думаю, тут переход можно делать только по модулям или вообще по функциям, используя методы, которые позволяют интеграцию с коболом. Грубо говоря, если в Коболе это foo(a, b), где a и b — numeric(10,2), то для C++ это будет void foo(const Numeric<10,2>&a, const Numeric<10,2>&b) (не вчитывался в коболовские конвенции, но предполагаю передачу по ссылке).
И только после того как целый слой и его стыки с соседними переведены — начинать трансформацию дальше.
Да, процесс будет многолетний. Но скорее всего он того стоит.
Хотя я бы переводил не на С++ (я его упомянул потому, что ваш оппонент назвал его в числе языков для своей платформы), а просто на что-то сходное процедурное, без тяжёлых тараканов Кобола, но и без опасных указателей и тому подобных низкоуровневых штук. Может, PL/1. Может, что-то совсем иное.
В начале 90-х я видел контору, которая занималась переводом софта с Кобола на ещё тогдашний C++. Вряд ли это были, конечно, столь центральные банковские системы.
все эти продукты очень сильно уступают своим зарубежным аналогам(жалкое подобие)
Должна у тебя появиться цель — то чего ты хочешь достичь с помощью программирования. Твой пэт проджект например, который решает твои собственные потребности. Не нужно учить всё программирование целиком. Изучай только то, что тебе нужно для достижения цели. Реализуй. Поставь новую цель. Повтори.
Как НЕ надо начинать изучать программирование