Продолжая тему, которую я начал в предыдущих постах #1 и #2, хотел бы ознакомить всех желающих с прогрессом по своей идее-технологии. У технологии появилось рабочее название – Pushkin, в честь понятно кого.
Основной тезис
Идея о полезности этой технологии отталкивается от предположений, что:
Разработчики не обязаны быть ответственны за все тексты в продукте (UX, коммуникации). Разработчики пишут код, они не копирайтеры
Коллеги разработчиков из других отделов хотят и должны полноценно участвовать в управлении текстами продукта. При этом они не умеют работать с кодом и хотят современную среду для работы
Правильность, соответствие текстов в продукте напрямую влияют на уровень счастья пользователей и на нагрузку на службу поддержки
Предполагается, что технология может быть очень полезна для всех проектов от среднего до крупного размера вне зависимости от наличия переводов на другие языки. Pushkin – не средство для локализации. Pushkin – намного больше, Pushkin – это средство для управления всеми текстами продукта. Это контроль диалога продукта с пользователями.
Проблема
Я сам разработчик и очень уважаю нашу профессию, но регулярно сталкиваюсь с подобными сообщениями на сайтах, которые, очевидно, писали разработчики:


Далеко не все разработчики умеют красиво выражать свои мысли письменно, но даже если в вашей команде все "Шекспиры", есть и другие проблемы – тексты быстро устаревают, выводятся при наличии каких-то редких условий, плохо выглядят на настоящей странице и так далее.
И тут многие скажут, да в чем проблема? Есть же gettext, есть разные реализации i18n?
Да, есть. Но это, во-первых, замедляет разработчика – разработчику надо выбрать новый уникальный ключ для куска текста каждый раз, а коллегам и переводчикам предлагается работать не со страницами продукта, а с тысячами ключей, с тысячами фрагментов текста, вырванными из контекста.

Разработчик в какой-то момент точно знал, где он использовал этот ключ. Скажем, "registration.form.ssn" – это поле, которое запрашивает SSN при регистрации, но только у пользователей из США. Переводчик же этого не знает, и чтобы взглянуть на страницу в действии – ему надо воссоздать правильные условия, допустим зайти на американскую версию сайта с американского IP.
Во-вторых, тяжело в целом контролировать точность всех текстов и их соответствие, так как практически полностью отсутствует контекст. Ну, скажем, я хочу посмотреть как происходит процесс регистрации нового пользователя у нас в продукте, если пользователь пришел из Испании. Шаг за шагом, включая посланные имейлы. Как это сделать, когда передо мной 10 тысяч ключей и их значений?
Кончается всё тем, что переводчики машинально переводят всё, что поступило, и как результат, даже у гигантских компаний появляются глупые ошибки в продукте.
Установка
Предлагается оборачивать все тексты в продукте в специальную функцию или директиву. За пару месяцев я сделал рабочий прототип плагина для Laravel (PHP) и админку. Вот так выглядит шаблон с текстами, это то, что предлагается сделать разработчику, чтобы начать пользоваться Pushkin:

При вызове этой специальной функции, Pushkin через debug_backtrace() определит текущий контекст – какой это маршрут, какой файл шаблона, класс Mailable и так далее. Вместо примитивных текстовых ключей (идентификаторов), Pushkin использует настоящий контекст в продукте.
После синхронизации через API с Pushkin, эти тексты появятся в админке:

Начиная с этого момента, разработчики и их коллеги могут не трогать тексты в шаблоне, а управлять ими через такие вот редакторы, которые:
Позволяют редактировать прямо поверх рендера – мы видим, как это будет смотреться на телефонах, на компьютерах в реальности
Позволяют работать со страницами продукта, а не с шаблонами или отдельными текстами. Концепция страниц интуитивней, это то, как люди в реальности говорят о своем опыте с продуктом. У страниц человеческие, а не технические названия.

Очень удобная абстракция для работы над текстами – сценарии поведения. Допустим, определяем такой сценарий как "Пользователь создает учетную запись", состоящий из трех шагов, включая имейл с подтверждением:
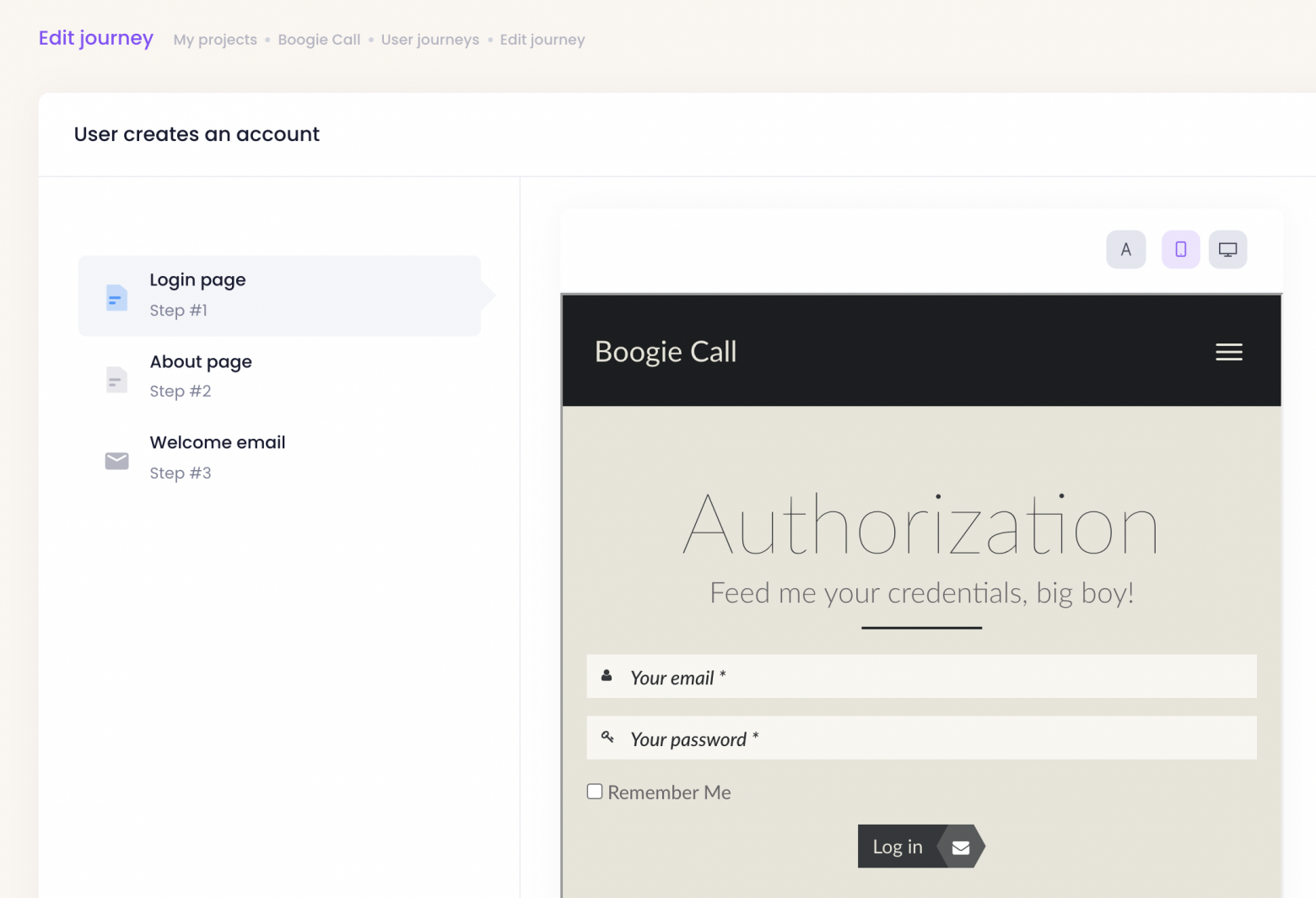
Поддержка всяких особенных условий (состояний) через дропдаун на каждой странице. То есть одна и та же страница, скажем Welcome, может иметь любое количество состояний, допустим: "Для анонимных пользователей", "Для вошедших пользователей" и так далее:

Переводить еще никогда не было так просто. Поменяли язык в дропдауне и начали редактировать поверх настоящего рендера. Прогресс оценивается по настоящим страницам, а не по вырванным из контекста тысячам кусочков текста:

Тем не менее, если по каким-то причинам есть желание работать на низком уровне, вроде уровне шаблонов или отдельных текстов, такая возможность всегда есть:
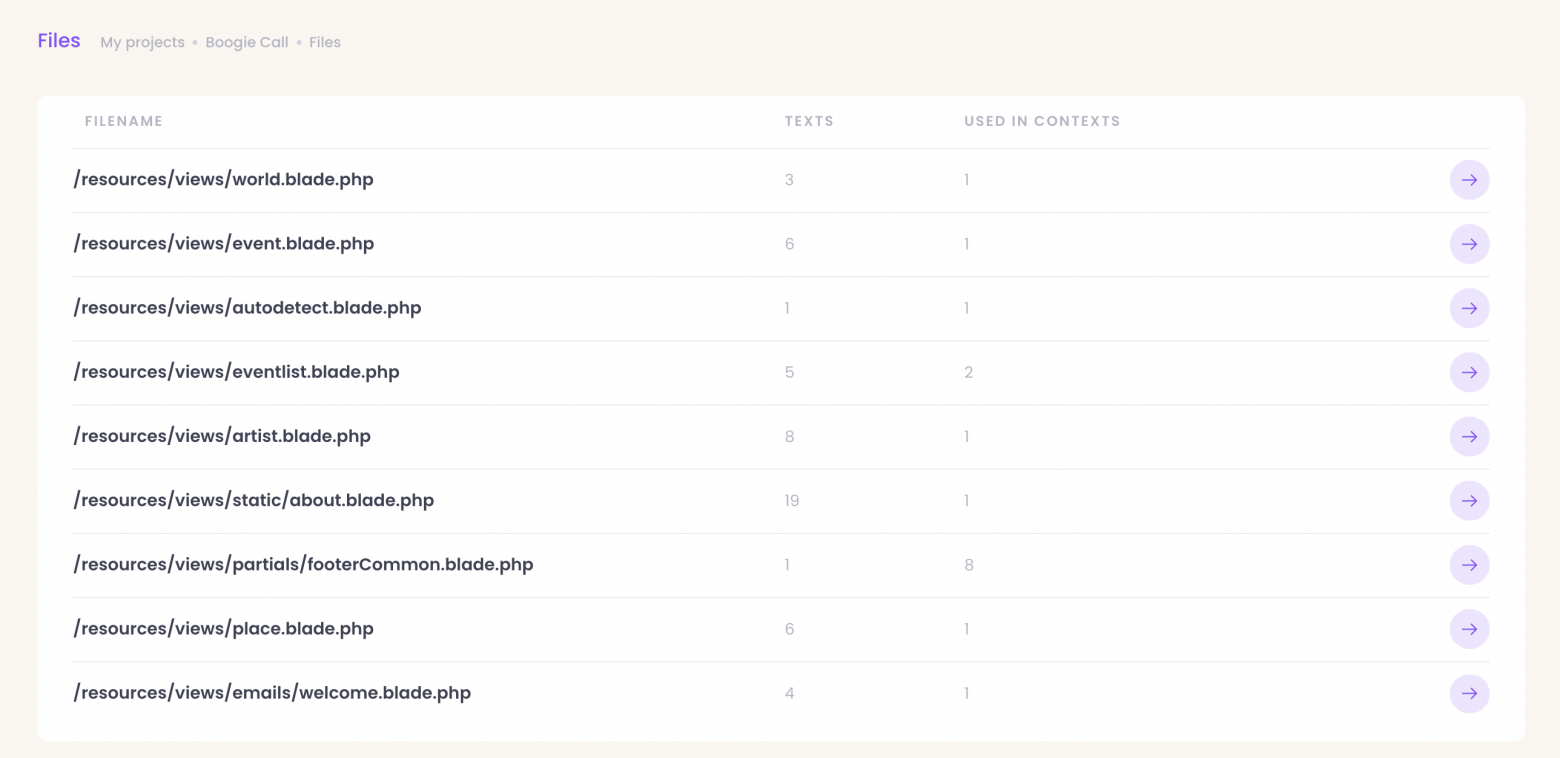
Это полезно если, скажем, у нас передается какая-то строка через сессию, и в рендере страницы её просто так не видно.
Сценарии и состояния
Чтобы хорошо описать разные сценарии поведения в продукте и разные состояния страниц, предлагается делать очень простые псевдо-тесты – используя стандартные средства (factories) фреймворка создавать нужные конкретные состояния и открывать страницы:
<?php class PagesTest extends TestCase { use RefreshDatabase, WithFaker, WithPushkin; /** * @test */ public function journey() { $this->sequence('User creates account', function () { $this->name('About page')->get('/en/about'); $this->name('Sign up page')->get('/sign-up'); $this->post('/sign-up', ['email' => $this->faker->email]); }); } }
Мой trait WithPushkin будет автоматически отправлять всё, что удалось найти во время HTTP-запросов в тесте в Pushkin, используя описания отсюда вроде "User creates account" – будет автоматически создан такой сценарий. Если во время тесты были посланы какие-то письма или сообщения, они будут автоматически пойманы, так как Pushkin подменил почтовый драйвер внутри этого класса тестов.
Я также смонтировал среднее по длине (9 минут) видео на английском, которое пытается доказать полезность моей идеи, начиная с самых азов. Первая половина видео будет понятная любому зрителю, вторая для разработчиков:
Я работал в нескольких стартапах, и такая технология была бы полезна во всех. Я также провёл видео-созвоны с друзьями-разработчиками и предпринимателями, и в целом я слышу очень хорошую обратную связь – все говорят, что боль реальна и такое решение могло бы сработать.
Заключение
Что вы думаете по этому поводу? Считаете ли, что проблема действительно существует? Стали ли пользоваться чем-то подобным тому, что представлено выше?
Если кому-то идея кажется перспективной, а себя Вы считаете достойным разработчиком, имейте, пожалуйста, ввиду, что я ищу себе в проект партнера-кофаундера, и тут на Хабре запостил на днях объявление
Если не нравится, кажется глупой затеей, то прошу конструктивной критики :)

