Во время учебной сессии (май-июнь и декабрь-январь) пользователи просят нас проверить на наличие заимствований до 500 документов каждую минуту. Документы приходят в файлах различных форматов, сложность работы с каждым из которых различна. Для проверки документа на заимствования нам сперва необходимо извлечь из файла его текст, а заодно и разобраться с форматированием. Задача — реализовать качественное извлечение полутысячи текстов с форматированием в минуту, при этом падать нечасто (а лучше не падать совсем), потреблять мало ресурсов и не платить за разработку и эксплуатацию конечного детища половину галактического бюджета.
Да-да, мы, конечно, знаем, что из трех вещей — быстро, дешево и качественно — нужно выбрать любые две. Но самое противное, что в нашем случае мы ничего не можем вычеркнуть. Вопрос в том, как хорошо у нас это получилось...

Источник изображения: Википедия
Нам часто говорят, что от качества нашей работы зависят судьбы людей. Поэтому приходится воспитывать в себе перфекционистов. Конечно, мы постоянно повышаем качество работы системы (во всех аспектах), так как недобросовестные авторы придумывают все новые пути обходов. И, надеюсь, что близок тот день, когда сложность обмана, с одной стороны, и чувство удовлетворения от качественно выполненной работы, с другой, побудят абсолютное большинство студентов отказаться от столь любимого желания схалтурить. При этом мы понимаем, что ценой ошибки могут быть возможные страдания невинных людей, если вдруг схалтурим мы.
К чему это я? Если бы мы были перфекционистами, то вдумчиво подошли бы к написанию цикла статей о работе системы «Антиплагиат». Мы бы кропотливо сформировали план публикаций, чтобы изложить все наиболее логичным и ожидаемым для читателя образом:
- Сперва мы бы рассказали о том, как устроена наша Система (пятая публикация на Хабре), и описали бы три основные этапа обработки документа при его проверке на заимствования:
- Извлечение текста документа (you are here!);
- Поиск заимствований (кусочки уже есть в нескольких наших статьях);
- Построение отчета по документу (в планах).
- Далее, мы бы начали посвящать читателя в устройство интересных вспомогательных механизмов, таких как поиск переводных заимствований (первая статья), определение парафраза (четвертая) и тематическая классификация (вторая).
- И, наконец, добрались до поискового движка — индекса шинглов (седьмая статья).
Внимательный читатель наверняка заметил, что избыточным перфекционизмом мы все-таки не страдаем, поэтому пришло время перейти к рассмотрению первого этапа — извлечения текста и форматирования документов. Этим мы сегодня и займемся, по пути размышляя о бренности бытия и о свете в конце тоннеля, о несуществовании ничего идеального и о стремлении к совершенству, о наличии плана и следовании ему и о компромиссах, к которым нас всегда склоняет жизнь.
В начале было слово
Сперва мы извлекали из документов лишь самое необходимое для проверки их на заимствования — сам текст документов. Поддерживались основные форматы — docx, doc, txt, pdf, rtf, html. Затем добавлялись менее распространённые ppt, pptx, odt, epub, fb2, djvu, правда, от работы с большинством из них пришлось в дальнейшем отказаться. Каждый из них обрабатывался по-своему — где-то отдельной библиотекой, где-то своим парсером. В среднем извлечение текста длилось порядка сотен миллисекунд. Казалось бы, основной и чуть ли не единственной сложностью извлечения текста является «парсинг» самого формата, что особенно актуально для бинарных форматов pdf и doc (а проприетарность последнего делает работу с ним еще более проблемной). Однако, уже на данном этапе, когда наши желания ограничивались лишь извлечением текста, стало ясно, что любой способ чтения нужных нам форматов несет с собой ряд неприятных особенностей. Самые существенные из них:
- Исключения даже при обработке некоторых валидных документов, не говоря уж об обработке некорректно сформированных «битых» документов. Еще больше проблем создает то, что падать может нативный код, и обработка подобных ситуаций в .net-коде затруднительна;
- Неадекватно высокое потребление памяти, что может сделать больно как соседним процессам, так и текущему, обрабатывающему «проблемный» документ (out of memory в управляемом или неуправляемом коде);
- Слишком долгая обработка документа, что усугубляется отсутствием механизмов отмены операции у большинства библиотек, а иногда и сложностью (читай: практически невозможностью) отмены вызова неуправляемого кода из управляемого;
- «Текста извлечение из документов». Формирование текста pdf-документа (а этот формат является для нас ключевым), парсинг которого уже произведен, вопреки ожиданиям, является нетривиальной задачей. Дело в том, что формат pdf изначально разрабатывался в первую очередь для электронного представления полиграфических материалов. Текст в pdf'ках представляет собой множество текстовых блоков, расположенных на страницах документа. Причем, блок может представлять собой как параграф текста, так и отдельно взятый символ. Задача же восстановления текста в исходном виде из данного набора блоков ложится на библиотеку (код/программу), читающую документ. Да, формат, начиная с определенной его версии, предоставляет возможность задания порядка следования блоков, но, к сожалению, документы с размеченным порядком следования текстовых блоков встречаются достаточно редко. Поэтому библиотеки чтения текста pdf'ок содержат ряд эвристик (ну тут стандартно: машинное обучение,
бигдата, блокчейн,...), позволяющих с той или иной точностью восстановить текст в правильном виде, причем, ожидаемо, получаемый результат отличается от библиотеки к библиотеке.

Источник нижнего изображения: Статья
Источник верхнего изображения: Хм...
Нужно больше данных!
Если для анализа документа на заимствования нам было достаточно текстовой подложки документа, то реализация целого ряда новых возможностей невозможна либо очень затруднительна без извлечения дополнительных данных из документа. Сегодня, помимо текстовой подложки, мы также извлекаем форматирование документа и рендерим изображения страниц. Последние мы используем для оптического распознавания текста (OCR), а также для определения некоторых разновидностей обходов.
Форматирование документа включает геометрическое расположение всех слов и символов на страницах, а также размер шрифта всех символов. Данная информация позволяет нам:
- Красиво отображать отчет о проверке документа, отрисовывая обнаруженные заимствования прямо на исходном виде документа;

- С большей точностью определять блоки документа (титульный лист, библиография) и извлекать его метаданные (авторы, название работы, год и место выполнения работы и т.д.);
- Обнаруживать попытки обхода системы.
Для унификации процесса обработки документов и набора извлекаемых данных мы конвертируем документы всех поддерживаемых нами форматов в pdf. Таким образом, процедура извлечения данных документа производится в два этапа:
- Конвертация документа в pdf;
- Извлечение данных из pdf.
Конвертация в pdf. Выбор библиотеки
Поскольку нельзя так просто взять и сконвертировать документ в pdf, мы решили не изобретать велосипед и исследовать готовые решения, выбрав наиболее подходящее нам. Дело было в далеком 2017 году.
Критерии отбора кандидатов:
- Библиотека на .net, в идеале — .net core и кроссплатформенность Спойлер!В итоге, на тот момент, идеал оказался недостижим
- Поддержка требуемых форматов — doc, docx, rtf, odf, ppt, pptx
- Стабильность
- Производительность
- Качество техподдержки
- Цена вопроса
Мы проанализировали доступные решения, отобрав среди них 6 наиболее подходящих под наши задачи:
| Библиотека | Проблемы на поверхности |
|---|---|
| MS Word. Interop | Требует: MS Word. Вызов Microsoft Word через COM. Метод имеет много минусов: необходимость установленного MS Word, неустойчивость, низкая производительность. Есть лицензионные ограничения. |
| DevExpress (17) | Не поддерживает ppt, pptx |
| GroupDocs | — |
| Syncfusion | Не поддерживает ppt, pptx, odt |
| Neevia Document Converter Pro | Требует: MS Word. Не поддерживает odt |
| DynamicPdf | Требует: MS Word, Internet Explorer. Не поддерживает odt |
MS Word Interop, Neevia Document Converter Pro и DynamicPdf требуют установки MS Office на продакшне, что могло бы окончательно и бесповоротно привязать нас к Windows. Поэтому эти варианты мы больше не рассматривали.
Таким образом, у нас осталось три основных кандидата, причем лишь один из них полностью поддерживает все необходимые нам форматы. Что ж, самое время посмотреть, на что они способны.
Для тестирования библиотек мы сформировали выборку из 120 тысяч реальных пользовательских документов, соотношение форматов в которой примерно соответствует тому, что мы видим каждый день на продакшене.
Итак, первый раунд. Посмотрим, какую долю документов смогут успешно сконвертировать в pdf рассматриваемые библиотеки. Успешно, в нашем случае, — это не кинуть исключение, уложиться в 3-х минутный таймаут и вернуть непустой текст.
| Конвертер | Успешно (%) | Не успешно (%) | ||||
|---|---|---|---|---|---|---|
| Всего | Пустой текст | Exception | Timeout (3 минуты) | Падение процесса | ||
| GroupDocs | 99.012 | 0.988 | 0.039 | 0.873 | 0.076 | 0 |
| DevExpress | 99.819 | 0.181 | 0.123 | 0.019 | 0.039 | 0 |
| Syncfusion | 98.358 | 1.632 | 0.039 | 0.848 | 0.745 | 0.01 |
Сразу выделился Syncfusion, который не только смог успешно обработать наименьшее количество документов, но и на некоторых документах свалил весь процесс (сгенерировав неотлавливаемые без танцев с бубном исключения типа OutOfMemoryException или исключений из нативного кода).
GroupDocs'у не удалось обработать примерно в 5.5 раз больше документов, чем DevExpress'у (все видно на табличке сверху). Это при том, что лицензия на одного разработчика у GroupDocs стоит примерно в 9 раз дороже лицензии на одного разработчика у DevExpress. Это так, к слову.
Второе серьезное испытание — время конвертации, те же самые 120 тысяч документов:
| Конвертер | Mean (сек.) | Median (cек.) | Std (сек.) |
|---|---|---|---|
| GroupDocs | 1.301966 | 0.328000 | 6.401197 |
| DevExpress | 0.523453 | 0.252000 | 1.781898 |
| Syncfusion | 8.922892 | 4.987000 | 12.929588 |
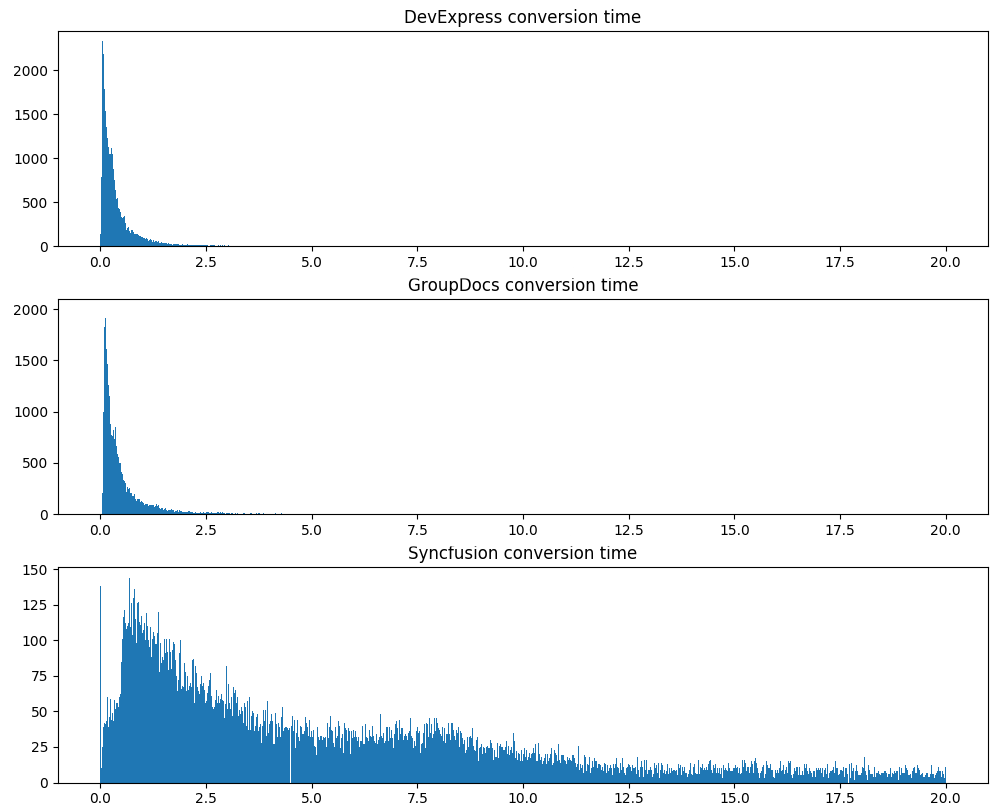
Заметим, что DevExpress не только значительно быстрее обрабатывает документы в среднем, но и показывает значительно более стабильное время обработки.
Но стабильность и скорость обработки ничего не значат, если на выходе получается плохая pdf'ка. Может, DevExpress пропускает половину текста? Проверяем. Итак, те же 120 тыс документов, на этот раз посчитаем общий объем извлеченного текста и среднюю долю словарных слов (чем больше извлеченных слов являются словарными, тем меньше мусора/некорректно извлеченного текста):
| Конвертер | Общий объём текста (в символах) | Средняя доля словарных слов |
|---|---|---|
| GroupDocs | 6 321 145 966 | 0.949172 |
| DevExpress | 6 135 668 416 | 0.950629 |
| Syncfusion | 5 995 008 572 | 0.938693 |
Отчасти предположение оказалось верным. Как выяснилось, GroupDocs, в отличие от DevExpress, умеет работать со сносками. DevExpress же их просто пропускает при конвертации документа в pdf. Кстати да, текст из получаемых pdf'ок во всех случаях извлекаем посредством DevExpress'а.
Итак, мы изучили скорость и стабильность рассматриваемых библиотек, теперь тщательно оценим качество конвертации документов pdf. Для этого мы проанализируем не просто объем извлекаемого текста и долю словарных слов в нем, а сравним извлекаемые из полученных pdf'ок тексты с текстами pdf'ок, полученных посредством MS Word. Принимаем результат конвертации документа посредством MS Word за эталонную pdf'ку. Для данного теста было подготовлено около 4500 пар «документ, эталонная pdf'ка».
| Конвертер | Текст извлекся (%) | Близость по длине текста | Близость по частоте встречаемости слов | ||||
|---|---|---|---|---|---|---|---|
| Среднее | Медиана | СКО | Среднее | Медиана | СКО | ||
| GroupDocs | 99.131 | 0.985472 | 0.999756 | 0.095304 | 0.979952 | 1.000000 | 0.102316 |
| DevExpress | 99.726 | 0.971326 | 0.996647 | 0.075951 | 0.965686 | 0.996101 | 0.082192 |
| Syncfusion | 89.336 | 0.880229 | 0.996845 | 0.306920 | 0.815760 | 0.998206 | 0.348621 |
Для каждой пары «эталонная pdf'ка, результат конвертации» мы вычислили схожесть по длине извлеченного текста и по частотам извлеченных слов. Естественно, данные метрики были получены только в тех случаях, когда конвертация была произведена успешно. Поэтому результаты Syncfusion мы здесь не рассматриваем. DevExpress и GroupDocs показали примерно одинаковые показатели. На стороне DevExpress'а — значительно больший процент успешной конвертации, на стороне GD — корректная работа со сносками.
Учитывая полученные результаты, выбор был очевиден. Мы по сей день используем решение от DevExpress и в скором времени планируем обновиться уже до 19-й его версии.
Есть Pdf, извлекаем текст с форматированием
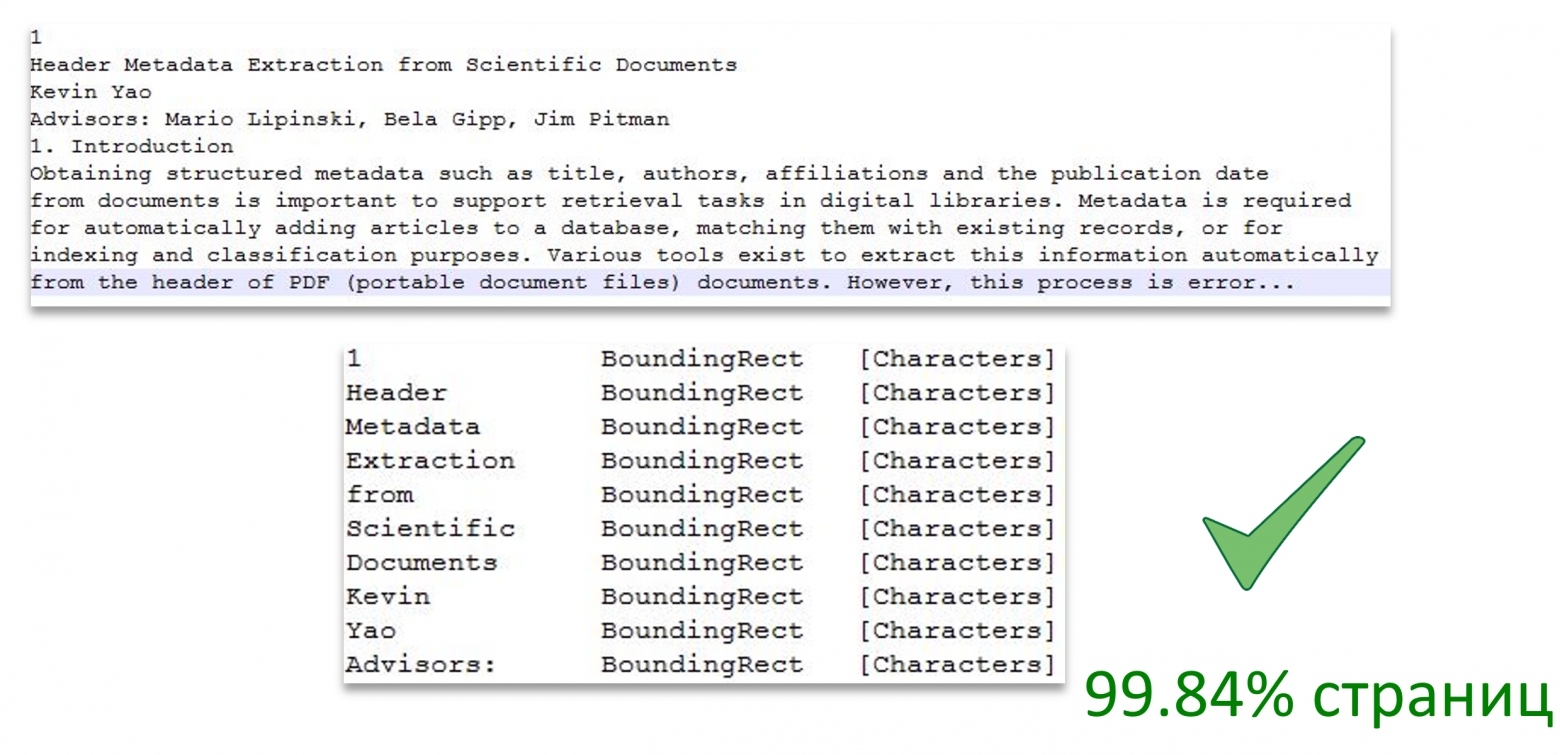
Итак, мы умеем конвертировать документы в pdf. Теперь перед нами стоит другая задача: с помощью DevExpress'а извлечь текст, зная о каждом слове всю необходимую нам информацию. А именно:
- На которой странице слово;
- Расположение слова на странице (обрамляющий прямоугольник);
- Размер шрифта слова (символов слова).
На изображении представлено разбиение текста по страницам, а также проиллюстрировано соответствие слова текста области страницы.

Источник изображения: Header Metadata Extraction from Scientific Documents
Казалось бы, все должно быть просто. Смотрим, какой API нам предоставляет DevExpress:
- Имеем метод, возвращающий текст всего документа. Обычный string;
- Имеем возможность итерации по словам документа. Для каждого слова можем получить:
- Текст слова;
- Страницу, на которой слово находится;
- Обрамляющий прямоугольник слова;
- Информацию по отдельным символам слова (значение символа, обрамляющий прямоугольник, размер шрифта, ...).
Окей, вроде как все необходимое есть. Только вот как получить необходимые данные по каждому слову в тексте документа, который возвращает DevExpress? Самим собирать текст документа из слов не очень хочется, так как, например, у нас нет информации, где между словами просто пробел, а где перевод строки. Придется придумывать эвристики на основе местоположения слов… Текст же — вот он, перед нами, уже собранный.

Источник изображения: Эврика!
Очевидное решение — сопоставлять слова с текстом документа. Смотрим — действительно, в тексте документа слова расположены в том же порядке, в котором их возвращает итератор по словам документа.
Быстренько реализуем простой алгоритм сопоставления слов с текстом документа, добавляем проверки на то, что все корректно сопоставилось, запускаем...
Действительно, на подавляющем большинстве страниц все корректно работает, но, к сожалению, не на всех страницах.

Источник верхнего изображения: Are you sure?
На части документов мы видим, что слова в тексте расположены не в том порядке, в котором они идут при итерации по словам документа. Более того, видно, что открывающая квадратная скобка в тексте в списке слов представлена как закрывающая скобка и находится в другом «слове». Корректное отображение данного фрагмента текста можно увидеть, открыв документ в MS Word. Что еще более интересно, если документ не конвертировать в pdf, а напрямую извлечь текст из doc'а, то мы получаем третий вариант фрагмента текста, не совпадающий ни с правильным порядком, ни с двумя другими порядками, получаемыми от библиотеки. В данном фрагменте, как и в большинстве остальных, на которых возникает подобная проблема, дело в невидимых «RTL» символах, меняющих порядок следования рядом стоящих символов/слов.
Тут стоит вспомнить о том, что немаловажным при выборе библиотеки мы называли качество техподдержки. Как показала практика, в этом аспекте взаимодействие с DevExpress достаточно эффективно. Проблема с представленным документом была оперативно исправлена после создания нами соответствующего тикета. Также был исправлен ряд других проблем, связанных с исключениями/большим потреблением оперативной памяти/долгой обработкой документов.
Однако, пока DevExpress не предоставляет прямого способа получения текста с нужной информацией по каждому слову, мы продолжаем сопоставлять порой несопоставимое. Если не можем построить точное соответствие слов с текстом, применяем ряд эвристик, допускающих небольшие перестановки слов. Если же ничего не помогло — документ у нас остается без форматирования. Редко, но такое случается.
Пока :)

{kind=link}
{kind=link}