Комментарии 23
Спасибо за работу. В этой статье есть всё, что нужно. Отправилась в закладки.
В выводах пункте 4 «Избегайте переполнения стека» — тут имеется ввиду http://stackoverflow.com/, с теми самыми готовыми ответами. :)
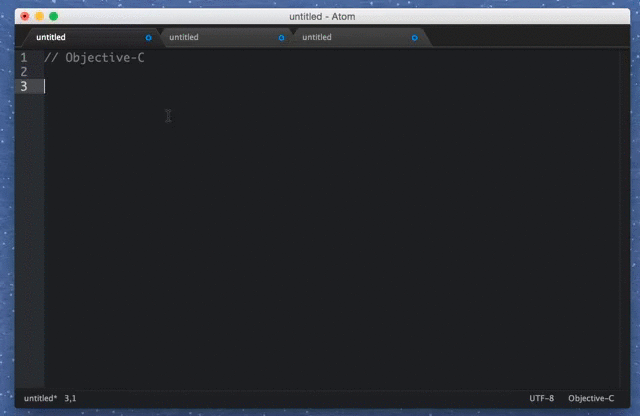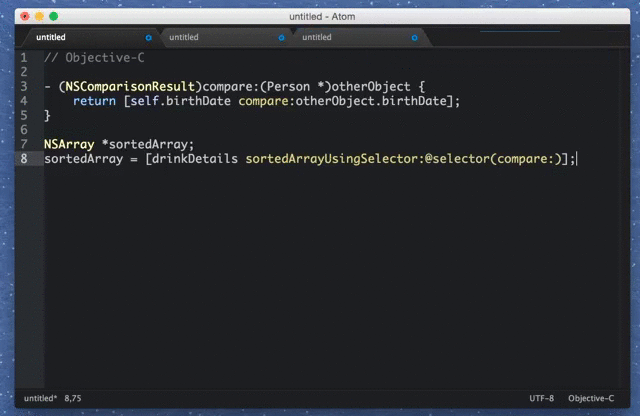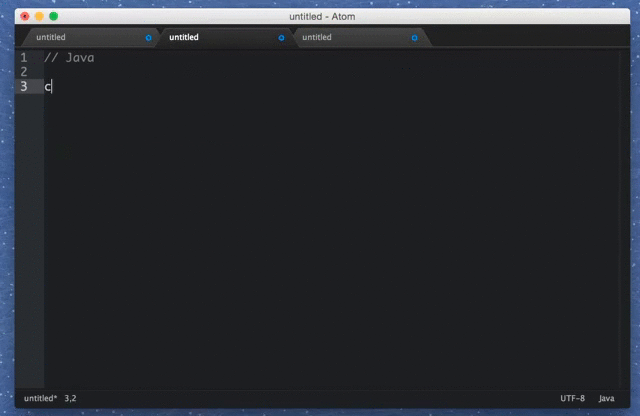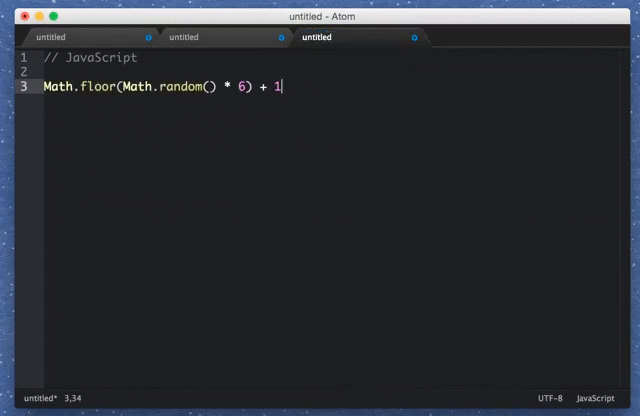
Первый раз вижу статью, в которой бечмарк селекторов jQuery соседствует с аффинити маской.
>>что код обходит дерево DOM три раза
Вы серьезно? я думаю, автора этого кода нужно уволить, а не указывать на такие банальные ошибки)
Вы серьезно? я думаю, автора этого кода нужно уволить, а не указывать на такие банальные ошибки)
Ха! подобный код встречается и в серьезных веб-проектах. просто, он валяется там, где никто не видит, или очень редко использует.
Вызов document.getElementById три раза вместо одного не может существенно замедлить выполнение скрипта. Дело в том, что при вызове этого метода никакой код не обходит весь DOM. Браузеры сами индексируют все элементы с id, поэтому доступ к ним получается довольно быстрым (хотя конечно не таким быстрым, как если бы вы закешировали данную выборку сами). Попробуйте сделать html файлик со следующим содержанием и загляните в консоль:
Вот на что действительно следует обратить внимание, так это на глобальные выборки не по id-селекторам, по которым коду на самом деле приходится обходить весь DOM (вроде «div.some_class»).
<div id="aaa"></div>
<script>console.log(aaa);</script>
Вот на что действительно следует обратить внимание, так это на глобальные выборки не по id-селекторам, по которым коду на самом деле приходится обходить весь DOM (вроде «div.some_class»).
Тут просто явный такой в лоб пример, подобного много, просто вызовы разнесены например в коде. Место того что бы присвоить переменной один раз получив селектор, могут просто время от времени делать обращение в коде. Не подряд как в примере но результат будет тот же самый.
а я вот покритикую.
раздел LINQ. первый пример не имеет отношения к LINQ, это идет от Entity Framework.
через Include вы сказали EF, что вам будут нужны данные от Courses, и в итоге у вас идет жадная загрузка, а не ленивая по умолчанию.(об этом почему то не слова)
Второй пример это традиционный пример где лучше применять var, а не пытаться самому угадать тип.
раздел JS, первый пример.
это правило актуально везде, кэширование сложных функций и прочего.
а про контекст актуально и без JQuery, тоже можно искать не от корня.
раздел LINQ. первый пример не имеет отношения к LINQ, это идет от Entity Framework.
через Include вы сказали EF, что вам будут нужны данные от Courses, и в итоге у вас идет жадная загрузка, а не ленивая по умолчанию.(об этом почему то не слова)
Второй пример это традиционный пример где лучше применять var, а не пытаться самому угадать тип.
раздел JS, первый пример.
это правило актуально везде, кэширование сложных функций и прочего.
а про контекст актуально и без JQuery, тоже можно искать не от корня.
Вместо того, чтобы выдать каждому элементу класс item, взять список один раз через $('.item') и обойти, автор пишет тысячу обращений по классу, дёргая каждый раз DOM. Вместо использования нативного getElementById. который будет быстрее даже с учётом оборачивания результата в $(), если уж так сильно нужны именно jQuery-коллекции, автор тысячу раз ходит через регэкспы в $().
А потом у нас вагон статей о том, какой тормознутый JS и DOM.
А потом у нас вагон статей о том, какой тормознутый JS и DOM.
мы должны быть многофункциональными ресурсами
Обидно…
Главное уловить суть, а не цепляться за каждое сказанное слово ибо всех примеров правильных, неправильных не перечислить, суть была наверника такова что массовую задачу нужно решать таким образом что бы масса задачи была максиально ефективнна и меине затратна в ресурсах прибегая к тонкостям и мудростям которые требуют усердия и вниательности к изучению, а локальные задачи решать индивидуально не мение осторожно.
но когда возникает необходимость разработать программу, то вы, скорее всего, постараетесь выбрать фреймворк/язык программирования/операционную систему/архитектуру.
В этом нет ничего плохого. Такой подход зачастую приводит к ускорению разработки. С другой стороны, при этом вы лишитесь возможности изучить что-либо новое. При использовании такого подхода крайне редко удается выкроить время, чтобы как следует проанализировать код и понять не только алгоритм, но и внутреннюю работу каждой строки кода.
вам шашечки или ехать?
В этом нет ничего плохого. Такой подход зачастую приводит к ускорению разработки. С другой стороны, при этом вы лишитесь возможности изучить что-либо новое. При использовании такого подхода крайне редко удается выкроить время, чтобы как следует проанализировать код и понять не только алгоритм, но и внутреннюю работу каждой строки кода.
вам шашечки или ехать?
Просто дополню… На практике изменение affinity mask редко помогает повысить производительность. Как правило, получается все наоборот, поэтому уж лучше это значение не трогать.
Сборник разрозненных советов непонятно для кого.
Чтобы кататься на велосипеде, надо научиться на нём кататься. Для краткости не буду рассказывать как это делается
И т.д.
В SQL необходимо изучить множество особенностей, чтобы добиться наивысшей производительности базы данных… Для краткости я не буду приводить конкретных примеров...
Чтобы кататься на велосипеде, надо научиться на нём кататься. Для краткости не буду рассказывать как это делается
И т.д.
Отменное качество картинок с кодом.


Как выше заметили про LINQ пример спорный и сильно зависит от особенностей решаемой задачи. Буквально только что напоролся на такое же решение с жадной обработкой, но только с использованием Xpath. Всё было хорошо до тех пор пока xml документ на входе не стал весить 29 мегабайт и иметь очень очень много считываемых в запросе тегов. В итоге у используемого фреймворка «рот оказался меньше куска».
И если с пунктом 1 по DOM особых вопросов в подходе как таковых не возникает, то пример с LINQ это очень спорный момент.
И если с пунктом 1 по DOM особых вопросов в подходе как таковых не возникает, то пример с LINQ это очень спорный момент.
Как-то… не впечатлила статья. Типа, не надо делать плохо и неграмотно, а надо грамотно и хорошо. Я в шоке от таких «откровений». :)
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Как ухудшить производительность вашего приложения — типичные ошибки разработчиков