Deep Learning Inference Benchmark — измеряем скорость работы моделей глубокого обучения

Перед разработчиками встает задача определения производительности железа в задаче исполнения глубоких моделей. Например, хочется решить проблему анализа пола-возраста покупателей, которые заходят в магазин, чтобы в зависимости от этого менять оформление магазина или наполнение товаром. Вы уже знаете какие модели хотите использовать в вашем ПО, но до конца не понятно как выбрать железо. Можно выбрать самый топ и переплачивать как за простаивающие мощности, так и за электроэнергию. Можно взять самый дешевый i3 и потом вдруг окажется, что он может вывезти каскад из нескольких глубоких моделей на 8 камерах. А может быть камера всего одна, и для решения задачи достаточно Raspberry Pi с Movidius Neural Compute Stick? Поэтому хочется иметь инструмент для оценки скорости работы вашего инференса на разном железе, причем еще до начала обучения.





 Итак, это случилось. После периода ожиданий, утечек и предположений Intel представила свои процессоры 11 поколения. Первыми по традиции анонсированы модели для мобильных и ультра-мобильных устройств (в предыдущих поколениях они имели индексы U и Y). Теперь подход к именованию изменился, и не только он. Вместе с процессорами представлен и новый их логотип. Это, между прочим, тоже событие: за 50-летнюю историю Intel ребрендинг происходит всего лишь второй раз. Новые эмблемы получат и другие продукты компании, ну а мы сейчас сосредоточимся на процессорах. Давайте по горячим следам посмотрим, что же в них нового.
Итак, это случилось. После периода ожиданий, утечек и предположений Intel представила свои процессоры 11 поколения. Первыми по традиции анонсированы модели для мобильных и ультра-мобильных устройств (в предыдущих поколениях они имели индексы U и Y). Теперь подход к именованию изменился, и не только он. Вместе с процессорами представлен и новый их логотип. Это, между прочим, тоже событие: за 50-летнюю историю Intel ребрендинг происходит всего лишь второй раз. Новые эмблемы получат и другие продукты компании, ну а мы сейчас сосредоточимся на процессорах. Давайте по горячим следам посмотрим, что же в них нового.

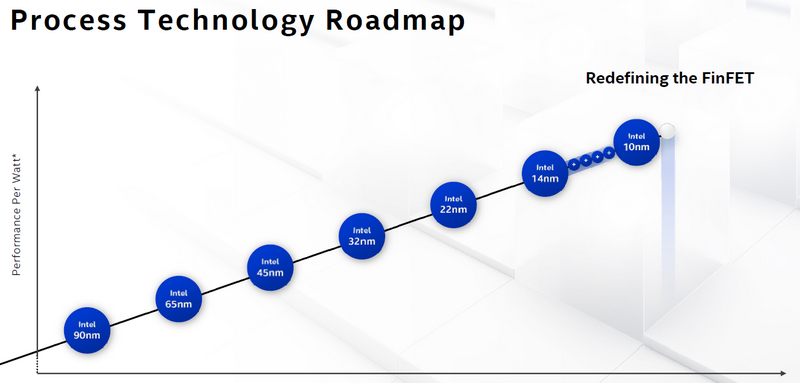






 Череда обновлений 2020-го процессорного года дошла, наконец, до самых больших, дорогих и серверных моделей — Xeon Scalable. Новое, теперь уже третье поколение Scalable (семейство Cooper Lake), по-прежнему использует 14-нм техпроцесс, но сформовано в новый сокет LGA4189. Первый анонс включает в себя 11 моделей линеек Platinum и Gold для четырех- и восьми-сокетных серверов.
Череда обновлений 2020-го процессорного года дошла, наконец, до самых больших, дорогих и серверных моделей — Xeon Scalable. Новое, теперь уже третье поколение Scalable (семейство Cooper Lake), по-прежнему использует 14-нм техпроцесс, но сформовано в новый сокет LGA4189. Первый анонс включает в себя 11 моделей линеек Platinum и Gold для четырех- и восьми-сокетных серверов.
