
Всем привет!
В данной статье хочу поделиться с вами историей о том, как одна и та же архитектура модели принесла сразу две победы в соревнованиях по машинному обучению на платформе topcoder с интервалом месяц.
Речь пойдёт о следующих соревнованиях:
- Urban 3d mapper — поиск домиков на спутниковых снимках. Соревнование длилось 2 месяца, было 54 участников и пять призовых мест.
- Spacenet: road detection challenge — поиск графа дорог. На решение также давалось 2 месяца, включало 33 участника и пять призовых позиций.
В статье рассказывается об общих подходах к решению таких задач и особенностях реализации для конкретных конкурсов.
Для комфортного чтения статьи желательно обладать базовыми знаниями о свёрточных нейронных сетях и их обучении.
Небольшая предыстория
В прошлом году, после просмотра нескольких тренировок по машинному обучению, я загорелся идеей поучаствовать в соревнованиях. Мой первый конкурс завершился неожиданно высоким для меня результатом, что ещё больше прибавило уверенности и мотивации. Так, я довольно быстро увлекся соревновательным машинным обучением, особенно задачами по обработке изображений.
Первым для меня стало соревнование на подсчёт морских львов на Алеутских островах. На тот момент моих знаний хватало лишь на то, чтобы брать за основу чужие решения, разбираться в них и пытаться улучшить. Именно так я и рекомендую поступать всем, кто хочет чему-то научиться и/или зайти в соревнования. Читать книжки до посинения без практического использования знаний — плохая идея. Таким образом, я обучил детектор, который работал очень даже неплохо, и принес мне 13 место из 385 участников, чему я был несказанно рад. Подробнее о задаче можете прочитать в следующем посте от Артёма.
Следующим было соревнование на классическую классификацию космических снимков, в котором я познакомился с классическим машинным обучением и множеством различных архитектур нейронных сетей. В этот раз мы работали в команде и финишировали на 7 позиции из 900 команд. Статья по мотивам соревнования.
После этого я был готов копать глубже и заниматься более серьёзными исследованиями, что сыграло свою роль в моей первой победе в соревновании по машинному обучению — Carvana image segmentation challenge. Подробнее о решении можете прочитать в нашем интервью в блог посте на kaggle. (А ещё там есть ссылка на исходные коды)
Пара слов о площадках и соревновательном машинном обучении
Лидером среди платформ для проведения соревнований по машинному обучению является kaggle. Но есть и другие платформы, на которых проходят не менее интересные конкурсы с хорошими призами. В моём случае оба соревнования проводились на платформе topcoder. Различия между платформами могут стать предметом долгой дискуссии, но сейчас хочется сосредоточить ваше внимание на некоторых занимательных особенностях, которые достойны отдельного внимания.
Во-первых, ограничения времени на обучение модели и предсказание. Для Urban 3d — 7 дней на тренировку на p2.xlarge и 8 часов на предсказание на том же инстансе. Для Spacenet: road detection на тренировку выделили приличную машину с 4 titan xp, однако для предсказания были такие же ограничения. На мой взгляд, это великолепные ограничения, позволяющие применять полученные решения задач в реальных условиях, в отличие от многих решений, которые находятся в топе kaggle. Например, чтобы воспроизвести наше решение в соревновании Сarvana image segmentation, необходимо или 20 GPU и неделя времени, как это было у нас, или один Titan X и 90 дней. Конечно же, это невозможно применять на практике. Даже Карпаты со мной согласен.
- Во-вторых, по завершению конкурса, для проверки решения организаторы просят всех из топ10 public leaderboard оформить код в docker контейнер и сдать контейнеры. Это спорный момент, так как лучшее и самое простое решение может не попасть в призовые места, но при этом уйти заказчику соревнования. Однако, это полностью исключает читерство, а значит к победе чаще приходят более качественные модели.
Из-за того, что платформа topcoder не такая известная и удобная, а также из-за этих ограничений, количество участников в соревнованиях остается не очень большим, однако там есть мотивированные профессионалы, с которыми можно побороться за 1 место.
Постановка задач
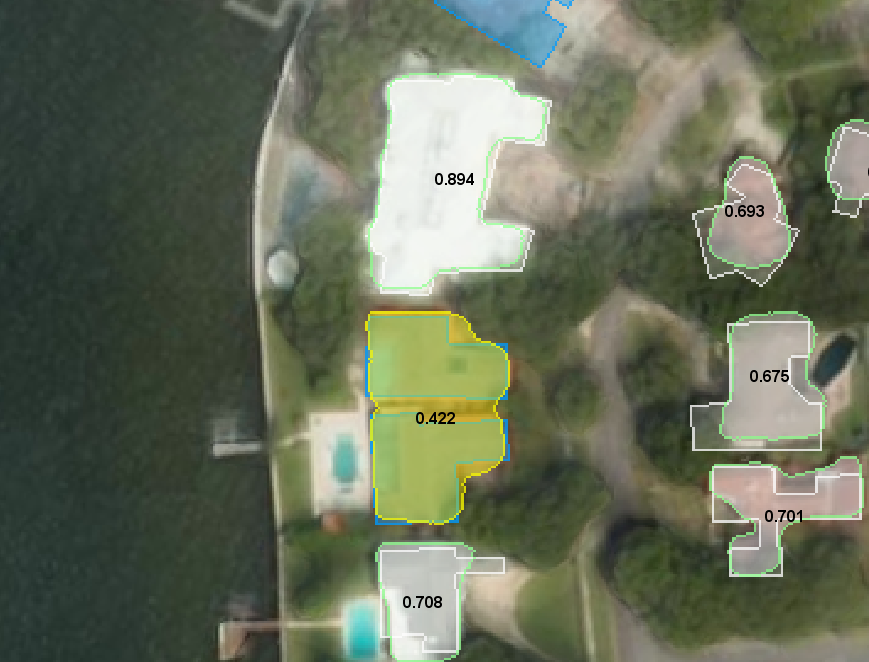
Задача Urban 3d заключалась в сегментировании крыш домов, на первый взгляд классическая задача semantic segmentation. Но на самом деле задача была на instance segmentation, то есть дома, стоящие рядом, должны определяться как отдельные элементы. И метрика очень сильно штрафовала за "слипающиеся дома". Метрика была следующая:
Берём все найденные связные компоненты и для каждой из них ищем в разметке ту компоненту, с которой наибольший индекс Жаккарда (intersection over union, отношение пересечения к объединению), и если  , то компонента записывается в
, то компонента записывается в  (true positive). Все компоненты, для которых не найдено ни одной соответствующей, записываются в
(true positive). Все компоненты, для которых не найдено ни одной соответствующей, записываются в  . Все компоненты в разметке, для которых не нашлось компоненты в предсказании, записываются в
. Все компоненты в разметке, для которых не нашлось компоненты в предсказании, записываются в  .
.


И финальная метрика получается такой:

Получается, что за каждое слипшееся здание мы получаем  , если это здание в разметке состоит из двух компонент и нам не повезло превысить порог 0.45 ни для одной из них. (здесь и далее на картинке голубым цветом , белым , желтым )
, если это здание в разметке состоит из двух компонент и нам не повезло превысить порог 0.45 ни для одной из них. (здесь и далее на картинке голубым цветом , белым , желтым )
Задача Spacenet: road detection выглядела значительно интересней. Заказчики придумали метрику, которая учитывает связность получаемого графа дорог, реализовали ее на java и python, подробно описали на medium. [1], [2], [3]. Эта метрика заинтриговала, хотелось применить не только навыки обучения сетей, но и классическое компьютерное зрение и теорию графов.
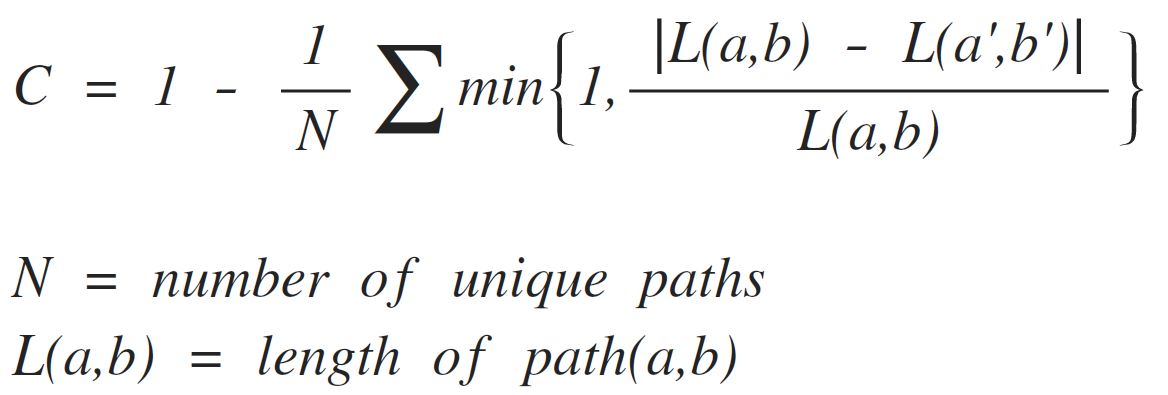
В итоге оказалось, что она очень нестабильная и чувствительная к ошибкам.
Urban 3d — распознавание домиков на спутниковых снимках
Для начала, немного слов о разметке, которая могла стать причиной негодования. Она была выполнена некачественно — часто дома в разметке были там, где их по факту не оказывалось. Но об этом вскоре сообщили организаторам, и они пообещали исправить ошибки в финальном тесте. На самом деле, проблемная разметка встречается во многих задачах, поэтому в тренировочном наборе я никак с ней не боролся, сеть должна сама справиться. Однако, если есть возможность что-то подправить — лучше это сделать.

Теперь перейдём ко входным данным задачи:
- RGB изображения;
- DTM (digital terrain model);
- DSM (digital surface model).
Если с RGB всё понятно, то DTM/DSM — что-то новое. Грубо говоря, DSM — это карта высот всех объектов на земле, а DTM — карта высот без объектов. Со спутниковых снимков они получаются в очень плохом разрешении, но данные новые и коррелируют с RGB (стандартное трёхцветное изображение) довольно слабо, так что их нужно было использовать. Поэтому четвертым каналом в сеть вошло (DSM-DTM)/9. Вычитаем их, чтобы получить высоту объектов и убрать высоты там, где земля. Костанту можно получить разными способами, например взять 98th percentile (хотя я просто взял средний максимум). Она нужна, чтобы привести вход в тот же порядок, что и RGB (номировать в промежуток 0-1), чтобы в первой свертке не доминировал ни один из каналов.
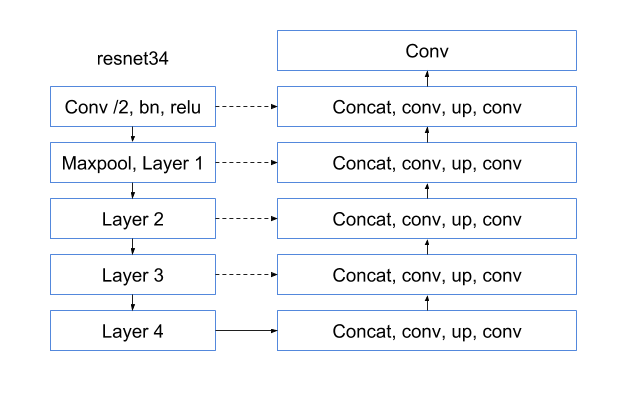
Первая свёртка заслуживает особого внимания. Дело в том, что раньше в основном использовались самодельные Unet-like архитектуры, которые не используют предобученных энкодеров. Подробнее о них можно почитать здесь и здесь. Но после соревнования Carvana всё изменилось. На сцену вышли архитектуры, в которых энкодером является претренированная на imagenet сеть, подробно об этом можно почитать в ternausnet. Также после этого соревнования стала популярна сеть Linknet с различными resnet-like энкодерами. Именно Linknet была доработана и взята за основу решения задачи.
Энкодером выступил resnet34, так как он обладает большой выразительностью и скоростью, а также требует немного видеопамяти. Я пробовал и другие энкодеры, но с resnet34 сходимость была лучше. Обзор архитектур нейронных сетей выходит за рамки этой статьи, но вы можете прочитать о них в следующем хорошем обзоре.
В качестве декодера использовалась последовательность блоков: свертка 3х3, upsampling, свертка 3х3. Здесь и далее “свертка 3х3” — это операция свертки с ярдром 3х3, шагом(stride) 1 и дополнением(padding) 1. Опыты показали, что upsampling работает не хуже, чем transposed convolution (которые еще и генерируют нежелательные артифакты), а нужды в понижающей или повышающей размерность свертке 1х1, которая была в linknet, вообще нет, так как скорость обучения меня устраивала. На вход свертке 3х3 поступают признаки с соответствующего слоя resnet через skip connection, соединенные по каналу глубины с выходом предыдущего слоя. Всё это можно заменить на простую операцию +, так как входы имеют одинаковую размерность, иногда я так и делаю.
Итоговая схема сети (после всех сверток, кроме первой и последней — relu):
Вернёмся к первой свёртке. Всего 4 канала, но у претренированного энкодера входная размерность по оси каналов — 3. Можно было пойти по нескольким путям. Кто-то предложил инициализировать нулями, кто-то предпочёл перемасштабировать имеющиеся веса. Я выбрал другой способ.
Для начала я обучил 5 эпох без 4 канала, как бы подогревая веса всех остальных слоев. Затем полностью переинициализировал первый слой и начал подавать на вход 4 канала. Я не менял learning rate и не морозил веса. Безусловно, стоило заморозить веса всех слоев, кроме первого. Но и так получалась неплохая сходимость, а на дополнительные эксперименты времени уже не хватало.
В качестве функции потерь (loss) была выбрана хорошо зарекомендовавшая себя связка:  . В этом соревновании веса были 0.5/0.5, но в последние две эпохи давалось чуть больше веса в bce. Визуально это совсем немного улучшило результат и разделимость домиков, о которой как раз и продолжится повествование. Обычно dice coefficient пытается сильно точить края и выдавать более уверенные предсказания, а binary cross entropy его сдерживает.
. В этом соревновании веса были 0.5/0.5, но в последние две эпохи давалось чуть больше веса в bce. Визуально это совсем немного улучшило результат и разделимость домиков, о которой как раз и продолжится повествование. Обычно dice coefficient пытается сильно точить края и выдавать более уверенные предсказания, а binary cross entropy его сдерживает.
Теперь вспомним, что мы решаем именно задачу instance segmentation, а при бинаризации по порогу большинство домов будет сливаться. Обычно там, где не хватает способностей сети, применяют трюки из классического компьютерного зрения, что и было в итоге использовано в данной задаче. Было замечено, что ближе к центру домика сеть почти всегда предсказывает с очень высокой вероятностью, а ближе к границе ее уверенность падает.

Но бинаризация по высокому порогу не даст нужного результата — дома теряют эффективную площадь, а метрика этому не сильно рада. Поэтому бинаризация проводилась по двум порогам, с поддержкой в виде алгоритма watershed. Алгоритм, как бы, выливает из сидов воду, которая распространяется по уровням одинаковых значений. И там, где вода из разных сидов встречается — появляется линия раздела. Пиксели, полученные бинаризацией по более высокому порогу, являлись сидами для watershed, а по низкому порогу — пространством разделения. В итоге площадь домов бралась с низкого порога, а разделение — с высокого. Также были удалены все дома меньше 100 пикселей (примерно 3 на 3 метра), так как у них в среднем было не очень высокое пересечение с разметкой.
В итоге: одна сеть на 4 фолда (для правильной валидации на out of fold предсказаниях), претренированный энкодер resnet34 и почти классический Unet-like декодер. Легкая постобработка результата алгоритмом watershed, трюки в обучении и немного везения.
На public leaderboard к финишу я пришел на второй позиции, что меня вполне устраивало из-за равномерного распределения призов (11-9-7). На private был новый город, и меня перебросило на 1 место.
Spacenet: road detection challenge — Распознавание дорог и построение графа
По традиции начнём с разметки и данных. К сожалению, и тут не обошлось без сложностей.
Организаторы обещали качественную разметку, но всё равно попадались серьёзные огрехи, которые сильно влияли на метрику. Например, на картинке ниже в разметке полосы шоссе не соединяли в местах соединения, что сразу приводило к падению скора на 30%, хотя в целом граф выглядит хорошо. Здесь и далее голубым — разметка, желтым — предсказанный граф.

Теперь посмотрим на данные, которых было очень много по объёму, но недостаточно много по смыслу. Дело в том, что организаторы выложили всё, что у них есть — MUL, MUL-PAN, PAN, RGB-PAN. Я визуально изучил данные и принял решение тренироваться только на RGB, так как не обнаружил полезной дополнительной информации в других каналах. Ведь чем проще данные с точки variance, тем проще научить модель обобщаться на них. RGB я нормировал на mean min/max. Для построения масок организаторы предложили рендерить дороги из geojson в изображения, тут ничего менять не пришлось. Были идеи, что надо делать разную ширину дороги в зависимости от типа, но всё работало и так.
Все данные я скормил моей прошлой сети, ничего не поменяв в архитектуре. При базовом постпроцессинге (о котором позже) на следующий день после начала участия в соревновании я получил 610/620k (~6-8 место на конец соревнования). Как обычно, прогнав несколько раз обучение с разными гиперпараметрами — увеличил количество эпох обучения и поставил веса 0.8/0.2 для loss. Это дало вторую базовую отметку 640к, дальше улучшения давал только постпроцессинг.
Построить граф из пиксельной карты вероятностей является нетривиальной задачей. К счастью, на просторах интернета первой же ссылкой гугла был найден пакет sknw, который удалось приспособить под мои потребности. Он получает на вход скелетон, а на выходе выдает мультиграф — очень удобно. Оставалось только добавить вершины туда, где дорога меняет свое направление, для чего был использован алгоритм Дугласа-Пекера, а точнее его реализация на opencv. Также сильное влияние на скор оказали дороги по краям картинки. Дело в том, что если на краю картинки есть часть дороги — алгоритм посчитает это дорогой, но дороги там может не быть, если ширина реальной дороги больше, чем в 2 раза.

Правильно было бы использовать соседние тайлы для этого, но это создавало определенные трудности, так как было неясно, будут ли они доступны на этапе тестирования. Плюс к тому же мой отрыв на LB уже был огромным, поэтому я пошёл по пути наименьшего сопротивления и просто оставил отпиливание всех дорог, которые меньше 2 пикселей, что в среднем работало неплохо. Кроме того, были небольшие улучшения графа — удалить короткие терминальные ребра, соединить ребра, которые лежат почти на одной прямой и находятся недалеко друг от друга, но всё это не дало существенного прироста метрики.
Итого: только RGB данные (самые распространенные в мире, то есть решение должно легко масштабироваться на другие источники), та же сеть, те же трюки, добавилась только серьезная постобработка, заключавшаяся в построении скелетона по бинарной маске, преобразовании скелетона в граф, проецирование графа в отрезки, работа с границами и немного не сильно полезных трюков.
О валидации
Во всех соревнованиях очень важно правильно валидироваться, чтобы в конце не было обидно. Дело в том, что просто достичь максимально высокого результата на лидерборде не всегда достаточно — ещё нужно, чтобы решение было устойчивым и хорошо работало не только на данных с публичного лидерборда, но и на других — которые спрятаны от разработчика и даже получение значения метрики на них не представляется возможным. Для валидации я использую стандартную технику k-fold cross validation. Она заключается в том, что тренировочный набор данных делится на k частей (у меня k=4) и обучаются k моделей следующим образом: каждая из моделей обучается на k-1 фолдах, а оставшийся фолд идёт в валидацию, то есть мы предсказываем на тех данных, которая модель не видела. В итоге мы получаем k наборов предсказаний, которые покрывают все множество тренировочных данных, но никакие из этих данных ни одна модель не видела. Эти предсказания называются OOF (out of fold predictions), на них можно подбирать пороги и экспериментировать. Кроме того, часто оставляют небольшую часть данных, чтобы проводить на них финальную проверку. Но в соревнованиях будет достаточно и LB.
Вместо заключения
А теперь немного экшена и личных переживаний. За 6 часов до окончания соревнования Spacenet: road detection challenge, пока я спал, участник с 3-4 места, отрыв от которого был очень большим и сабмиты последних дней не приносили успеха, смог подняться до второго места. Спустя ещё три часа он оказался первым.
Кроме того, под конец соревнования коллеги с соседних мест сообщили о баге в наборе данных, который состоял в том, что мультиспектральные данные были немного неполными, и в результате те, кто учился на RGB, получали незаслуженно более высокие результаты на лидерборде, в тесте такое пообещали исправить. Поэтому я ожидал падения на несколько мест ниже. С объявлением результатов сильно затянули, так как долго переучивали модели, это заняло у организаторов больше месяца. Теперь вы представляете ту радость и удивление, когда я обнаружил своё имя в первой строчке LB.
В конце я бы хотел выразить благодарность коллегам по соревнованиям (особенно Селиму и Виктору) за здравую конкуренцию и дельные советы, а также всем тем, кто помогал мне редактировать текст.
Спасибо всем, кто дочитал, и удачи в соревнованиях!
PS: организаторы spacenet выложили код.
