Привет, коллеги!

В последней публикации уходящего года мы хотели упомянуть о Reinforcement Learning — теме, книгу на которую мы уже переводим.
Посудите сами: нашлась элементарная статья с Medium, в которой изложен контекст проблемы, описан простейший алгоритм с реализацией на Python. В статье есть несколько гифок. А мотивация, вознаграждение и выбор правильной стратегии на пути к успеху — это вещи, которые исключительно пригодятся в наступающем году каждому из нас.
Приятного чтения!
Обучение с подкреплением – это разновидность машинного обучения, при котором агент учится действовать в окружающей среде, выполняя действия и тем самым нарабатывая интуицию, после чего наблюдает результаты своих действий. В этой статье я расскажу, как понять и сформулировать задачу на обучение с подкреплением, а затем решить ее на Python.
В последнее время мы уже привыкли к тому, что компьютеры играют в игры против человека – либо как боты в многопользовательских играх, либо как соперники в играх «один на один»: скажем, в Dota2, PUB-G, Mario. Исследовательская компания Deepmind наделала шороху в новостях, когда в 2016 году их программа AlphaGo в 2016 году одолела чемпиона Южной Кореи по го. Если вы – заядлый геймер, то могли слышать о пятерке матчей Dota 2 OpenAI Five, где машины сражались против людей и в нескольких матчах одолели лучших игроков в Dota2. (Если вас интересуют подробности, здесь подробно проанализирован алгоритм и рассмотрено, как играли машины).

Последняя версия OpenAI Five берет Roshan.
Итак, начнем с центрального вопроса. Зачем нам требуется обучение с подкреплением? Используется ли оно только в играх, либо применимо в реалистичных сценариях для решения прикладных задач? Если вы впервые читаете про обучение с подкреплением, то просто не можете вообразить себе ответ на эти вопросы. Ведь обучение с подкреплением — одна из самых широко используемых и бурно развивающихся технологий в сфере искусственного интеллекта.
Вот ряд предметных областей, в которых особенно востребованы системы по обучению с подкреплением:
Краткий обзор и происхождение обучения с подкреплением
Итак, как же сформировался сам феномен обучения с подкреплением, когда у нас в распоряжении такое множество методов машинного и глубокого обучения? «Его изобрели Рич Саттон и Эндрю Барто, научный руководитель Рича, помогавший ему готовить PhD». Парадигма впервые оформилась в 1980-е и тогда была архаична. Впоследствии Рич верил, что у нее большое будущее, и она в конце концов получит признание.
Обучение с подкреплением поддерживает автоматизацию в той среде, где оно внедрено. Примерно также действуют и машинное, и глубокое обучение – стратегически они устроены иначе, но обе парадигмы поддерживают автоматизацию. Итак, почему же возникло обучение с подкреплением?
Оно очень напоминает естественный процесс обучения, при котором процесс/модель действует и получает обратную связь о том, как ей удается справляться с задачей: хорошо и нет.
Машинное и глубокое обучение – также варианты обучения, однако, они в большей степени заточены под выявление закономерностей в имеющихся данных. В обучении с подкреплением, с другой стороны, такой опыт приобретается методом проб и ошибок; система постепенно находит правильные варианты действий или глобальный оптимум. Серьезное дополнительное преимущество обучения с подкреплением заключается в том, что в данном случае не требуется предоставлять обширного набора учебных данных, как при обучении с учителем. Достаточно будет нескольких мелких фрагментов.
Понятие об обучении с подкреплением
Представьте, что учите ваших кошек новым фокусам; но, к сожалению, кошки не понимают человеческого языка, поэтому вы не можете взять и рассказать им, во что собираетесь с ними играть. Поэтому вы будете действовать иначе: имитировать ситуацию, а кошка в ответ будет пытаться реагировать тем или иным способом. Если кошка отреагировала так, как вы хотели, то вы наливаете ей молока. Понимаете, что будет дальше? Вновь оказавшись в аналогичной ситуации, кошка вновь выполнит желаемое вами действие, и с еще большим энтузиазмом, рассчитывая, что ее покормят еще лучше. Так происходит обучение на положительном примере; но, если пытаться «воспитывать» кошку отрицательными стимулами, например, строго смотреть на нее и хмуриться, она обычно не обучается на таких ситуациях.
Схожим образом работает и обучение с подкреплением. Мы сообщаем машине некоторый ввод и действия, а затем вознаграждаем машину в зависимости от вывода. Наша конечная цель – максимизация вознаграждения. Теперь давайте рассмотрим, как переформулировать изложенную выше проблему в терминах обучения с подкреплением.
Теперь, разобравшись, что представляет из себя обучение с подкреплением, давайте подробно поговорим об истоках и эволюции обучения с подкреплением и глубокого обучения с подкреплением, обсудим, как эта парадигма позволяет решать задачи, неподъемные для обучения с учителем или без учителя, а также отметим следующий любопытный факт: в настоящее время поисковик Google оптимизирован как раз с применением алгоритмов обучения с подкреплением.
Знакомство с терминологией обучения с подкреплением
Агент и Среда играют ключевые роли в алгоритме обучения с подкреплением. Среда – это тот мир, в котором приходится выживать Агенту. Кроме того, Агент получает от Среды подкрепляющие сигналы (вознаграждение): это число, характеризующее, насколько хорошим или плохим можно считать текущее состояние мира. Цель Агента — максимизировать совокупное вознаграждение, так называемый «выигрыш». Прежде чем написать наши первые алгоритмы на обучение с подкреплением, необходимо разобраться с нижеизложенной терминологией.

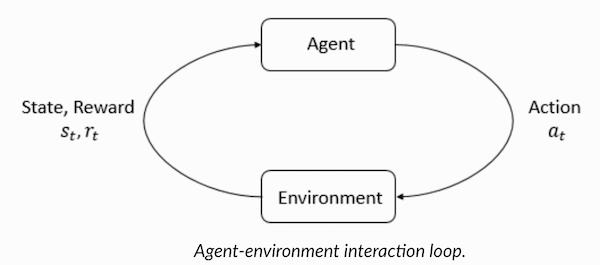
Теперь, познакомившись с терминологией обучения с подкреплением, давайте решим задачу, воспользовавшись соответствующими алгоритмами. Перед этим нужно понять, как сформулировать такую задачу, а при решении этой задачи опираться на терминологию обучения с подкреплением.
Решение задачи такси
Итак, переходим к решению задачи с применением подкрепляющих алгоритмов.
Допустим, у нас есть зона для обучения беспилотного такси, которое мы обучаем доставлять пассажиров на парковку в четыре различные точки (
Среду для решения задачи с такси можно настроить при помощи Gym от компании OpenAI – это одна из самых популярных библиотек для решения задач на обучение с подкреплением. Хорошо, прежде чем использовать gym, ее нужно установить на вашей машине, а для этого удобен менеджер пакетов Python под названием pip. Ниже приведена установочная команда.
Далее давайте посмотрим, как будет отображаться наша среда. Все модели и интерфейс для этой задачи уже сконфигурированы в gym и поименованы под
“Имеем 4 местоположения (обозначенных разными буквами); наша задача – подхватить пассажира в одной точке и высадить его в другой. Получаем +20 очков за успешную высадку пассажира и теряем 1 очко за каждый шаг, затраченный на это. Также предусмотрен штраф 10 очков за каждую непредусмотренную посадку и высадку пассажира.” (Источник: gym.openai.com/envs/Taxi-v2)
Вот какой вывод мы увидим в нашей консоли:

Taxi V2 ENV
Отлично,
Итак, рассмотрев среду, давайте постараемся глубже понять задачу. Такси – единственный автомобиль на данной парковке. Парковку можно разбить в виде сетки
В среде есть 4 точки, в которых допускается высадка пассажиров: это:
Итак, в нашей среде для такси насчитывается 5×5×5×4=500 возможных состояний. Агент имеет дело с одним из 500 состояний и предпринимает действие. В нашем случае варианты действий таковы: перемещение в том или ином направлении, либо решение подобрать/высадить пассажира. Иными словами, у нас в распоряжении шесть возможных действий:
pickup, drop, north, east, south, west (Четыре последних значения – это направления, в которых может двигаться такси.)
Это пространство
Как понятно из иллюстрации выше, такси не может совершать определенные действия в некоторых ситуациях (мешают стены). В коде, описывающем среду, мы просто назначим штраф -1 за каждое попадание в стену, и такси, столкнувшись со стеной. Таким образом, подобные штрафы будут накапливаться, поэтому такси попытается не врезаться в стены.
Таблица вознаграждений: При создании среды «такси» также создается первичная таблица вознаграждений под названием P. Можно считать ее матрицей, где количество состояний соответствует числу строк, а количество действий – числу столбцов. Т.е., речь идет о матрице
Поскольку в эту матрицу записаны абсолютно все состояния, можно просмотреть заданные по умолчанию значения вознаграждений, присвоенные тому состоянию, что мы выбрали для иллюстрации:
Структура этого словаря такова:
Для решения этой задачи без какого-либо обучения с подкреплением, можно задать целевое состояние, сделать выборку пространств, а затем, если удастся достичь целевого состояния за некоторое количество итераций – предположить, что этот момент соответствует максимальному вознаграждению. В других состояниях значение вознаграждения либо близится к максимуму, если программа действует правильно (приближается к цели), либо накапливает штрафы, если совершает ошибки. Причем, значение штрафа может дойти не ниже, чем до -10.
Давайте напишем код для решения этой задачи без обучения с подкреплением.
Поскольку у нас есть P-таблица с заданными по умолчанию значениями вознаграждения для каждого состояния, можем попытаться организовать навигацию нашего такси просто на основе этой таблицы.
Создаем бесконечный цикл, проматывающийся до тех пор, пока пассажир не попадет в место назначения (один эпизод), либо, иными словами, пока показатель вознаграждения не достигнет 20. Метод
Вывод:
credits: OpenAI
Задача решена, но не оптимизирована, либо этот алгоритм будет работать не во всех случаях. Нам нужен подходящий взаимодействующий агент, чтобы количество итераций, затрачиваемых машиной/алгоритмом на решение задачи оставалось минимальным. Здесь нам поможет алгоритм Q-обучения, реализацию которого мы рассмотрим в следующем разделе.
Знакомство с Q-обучением
Ниже представлен наиболее востребованный и один из самых простых алгоритмов на обучение с подкреплением. Среда вознаграждает агента за постепенное обучение и за то, что в конкретном состоянии он совершает наиболее оптимальный шаг. В реализации, рассмотренной выше, у нас была таблица вознаграждений «P», по которой будет учиться наш агент. Опираясь на таблицу вознаграждений, он выбирает следующее действие в зависимости от того, насколько оно полезно, а затем обновляет еще одну величину, именуемую Q-значением. В результате создается новая таблица, называемая Q-таблица, отображаемая на комбинацию (Состояние, Действие). Если Q-значения оказываются лучше, то мы получаем более оптимизированные вознаграждения.
Например, если такси оказывается в состоянии, где пассажир оказывается в той же точке, что и такси, исключительно вероятно, что Q-значение для действия «подобрать» выше, чем для других действий, например, «высадить пассажира» или «ехать на север».
Q-величины инициализируются со случайными значениями, и по мере того, как агент взаимодействует со средой и получает различные вознаграждения, совершая те или иные действия, Q-значения обновляются в соответствии со следующим уравнением:

Здесь возникает вопрос: как инициализировать Q-значения и как рассчитывать их. По мере выполнения действий Q-значения выполняются в данном уравнении.
Здесь Альфа и Гамма – параметры алгоритма на Q-обучение. Альфа – это темп обучения, а гамма – дисконтирующий множитель. Оба значения могут быть в диапазоне от 0 до 1 и иногда равны единице. Гамма может быть равна нулю, а альфа – не может, поскольку значение потерь при обновлении должно компенсироваться (темп обучения — положителен). Альфа-значение здесь такое же, как и при обучении с учителем. Гамма определяет, какую важность мы хотим придать вознаграждениям, ожидающим нас в перспективе.
Данный алгоритм кратко изложен ниже:
Q-обучение в Python
Отлично, теперь все ваши значения будут храниться в переменной
Итак, ваша модель обучена в условиях окружающей среды, и теперь умеет более точно подбирать пассажиров. А вы познакомились с феноменом обучения с подкреплением, и можете запрограммировать алгоритм для решения новой задачи.
Другие приемы обучения с подкреплением:
Код к этому упражнению находится по адресу:
vihar/python-reinforcement-learning

В последней публикации уходящего года мы хотели упомянуть о Reinforcement Learning — теме, книгу на которую мы уже переводим.
Посудите сами: нашлась элементарная статья с Medium, в которой изложен контекст проблемы, описан простейший алгоритм с реализацией на Python. В статье есть несколько гифок. А мотивация, вознаграждение и выбор правильной стратегии на пути к успеху — это вещи, которые исключительно пригодятся в наступающем году каждому из нас.
Приятного чтения!
Обучение с подкреплением – это разновидность машинного обучения, при котором агент учится действовать в окружающей среде, выполняя действия и тем самым нарабатывая интуицию, после чего наблюдает результаты своих действий. В этой статье я расскажу, как понять и сформулировать задачу на обучение с подкреплением, а затем решить ее на Python.
В последнее время мы уже привыкли к тому, что компьютеры играют в игры против человека – либо как боты в многопользовательских играх, либо как соперники в играх «один на один»: скажем, в Dota2, PUB-G, Mario. Исследовательская компания Deepmind наделала шороху в новостях, когда в 2016 году их программа AlphaGo в 2016 году одолела чемпиона Южной Кореи по го. Если вы – заядлый геймер, то могли слышать о пятерке матчей Dota 2 OpenAI Five, где машины сражались против людей и в нескольких матчах одолели лучших игроков в Dota2. (Если вас интересуют подробности, здесь подробно проанализирован алгоритм и рассмотрено, как играли машины).

Последняя версия OpenAI Five берет Roshan.
Итак, начнем с центрального вопроса. Зачем нам требуется обучение с подкреплением? Используется ли оно только в играх, либо применимо в реалистичных сценариях для решения прикладных задач? Если вы впервые читаете про обучение с подкреплением, то просто не можете вообразить себе ответ на эти вопросы. Ведь обучение с подкреплением — одна из самых широко используемых и бурно развивающихся технологий в сфере искусственного интеллекта.
Вот ряд предметных областей, в которых особенно востребованы системы по обучению с подкреплением:
- Беспилотные автомобили
- Игровая индустрия
- Робототехника
- Рекомендательные системы
- Реклама и маркетинг
Краткий обзор и происхождение обучения с подкреплением
Итак, как же сформировался сам феномен обучения с подкреплением, когда у нас в распоряжении такое множество методов машинного и глубокого обучения? «Его изобрели Рич Саттон и Эндрю Барто, научный руководитель Рича, помогавший ему готовить PhD». Парадигма впервые оформилась в 1980-е и тогда была архаична. Впоследствии Рич верил, что у нее большое будущее, и она в конце концов получит признание.
Обучение с подкреплением поддерживает автоматизацию в той среде, где оно внедрено. Примерно также действуют и машинное, и глубокое обучение – стратегически они устроены иначе, но обе парадигмы поддерживают автоматизацию. Итак, почему же возникло обучение с подкреплением?
Оно очень напоминает естественный процесс обучения, при котором процесс/модель действует и получает обратную связь о том, как ей удается справляться с задачей: хорошо и нет.
Машинное и глубокое обучение – также варианты обучения, однако, они в большей степени заточены под выявление закономерностей в имеющихся данных. В обучении с подкреплением, с другой стороны, такой опыт приобретается методом проб и ошибок; система постепенно находит правильные варианты действий или глобальный оптимум. Серьезное дополнительное преимущество обучения с подкреплением заключается в том, что в данном случае не требуется предоставлять обширного набора учебных данных, как при обучении с учителем. Достаточно будет нескольких мелких фрагментов.
Понятие об обучении с подкреплением
Представьте, что учите ваших кошек новым фокусам; но, к сожалению, кошки не понимают человеческого языка, поэтому вы не можете взять и рассказать им, во что собираетесь с ними играть. Поэтому вы будете действовать иначе: имитировать ситуацию, а кошка в ответ будет пытаться реагировать тем или иным способом. Если кошка отреагировала так, как вы хотели, то вы наливаете ей молока. Понимаете, что будет дальше? Вновь оказавшись в аналогичной ситуации, кошка вновь выполнит желаемое вами действие, и с еще большим энтузиазмом, рассчитывая, что ее покормят еще лучше. Так происходит обучение на положительном примере; но, если пытаться «воспитывать» кошку отрицательными стимулами, например, строго смотреть на нее и хмуриться, она обычно не обучается на таких ситуациях.
Схожим образом работает и обучение с подкреплением. Мы сообщаем машине некоторый ввод и действия, а затем вознаграждаем машину в зависимости от вывода. Наша конечная цель – максимизация вознаграждения. Теперь давайте рассмотрим, как переформулировать изложенную выше проблему в терминах обучения с подкреплением.
- Кошка выступает в роли «агента», подвергающегося воздействию «окружающей среды».
- Окружающая среда – это дом или игровая зона, в зависимости того, чему вы обучаете кошку.
- Ситуации, возникающие при обучении, называются «состояниями». В случае с кошкой примеры состояний – когда кошка «бежит» или «заползает под кровать».
- Агенты реагируют, совершая действия и переходя из одного «состояния» в другое.
- После изменения состояния агент получает «вознаграждение» или «штраф» в зависимости от совершенного им действия.
- «Стратегия» — это методика выбора действия для получения наилучших результатов.
Теперь, разобравшись, что представляет из себя обучение с подкреплением, давайте подробно поговорим об истоках и эволюции обучения с подкреплением и глубокого обучения с подкреплением, обсудим, как эта парадигма позволяет решать задачи, неподъемные для обучения с учителем или без учителя, а также отметим следующий любопытный факт: в настоящее время поисковик Google оптимизирован как раз с применением алгоритмов обучения с подкреплением.
Знакомство с терминологией обучения с подкреплением
Агент и Среда играют ключевые роли в алгоритме обучения с подкреплением. Среда – это тот мир, в котором приходится выживать Агенту. Кроме того, Агент получает от Среды подкрепляющие сигналы (вознаграждение): это число, характеризующее, насколько хорошим или плохим можно считать текущее состояние мира. Цель Агента — максимизировать совокупное вознаграждение, так называемый «выигрыш». Прежде чем написать наши первые алгоритмы на обучение с подкреплением, необходимо разобраться с нижеизложенной терминологией.
- Состояния: Состояние – это полное описание мира, в котором не упущено ни единого фрагмента информации, характеризующей этот мир. Это может быть позиция, фиксированная или динамическая. Как правило, такие состояния записываются в виде массивов, матриц или тензоров высшего порядка.
- Действие: Действие обычно зависит от условий окружающей среды, и в различных средах агент будет предпринимать разные действия. Множество допустимых действий агента записывается в пространстве, именуемом «пространство действий». Как правило, количество действий в пространстве конечно.
- Среда: Это место, в котором агент существует и с которым взаимодействует. Для различных сред используются различные типы вознаграждений, стратегий, т.д.
- Вознаграждение и выигрыш: Отслеживать функцию вознаграждения R при обучении с подкреплением нужно постоянно. Она критически важна при настройке алгоритма, его оптимизации, а также при прекращении обучения. Она зависит от текущего состояния мира, только что предпринятого действия и следующего состояния мира.
- Стратегии: стратегия — это правило, в соответствии с которым агент избирает следующее действие. Набор стратегий также именуется «мозгом» агента.
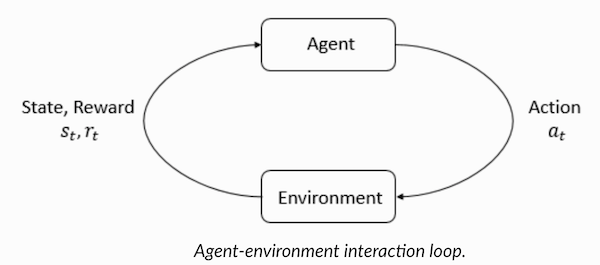
Теперь, познакомившись с терминологией обучения с подкреплением, давайте решим задачу, воспользовавшись соответствующими алгоритмами. Перед этим нужно понять, как сформулировать такую задачу, а при решении этой задачи опираться на терминологию обучения с подкреплением.
Решение задачи такси
Итак, переходим к решению задачи с применением подкрепляющих алгоритмов.
Допустим, у нас есть зона для обучения беспилотного такси, которое мы обучаем доставлять пассажиров на парковку в четыре различные точки (
R,G,Y,B). Перед этим нужно понять и задать среду, в которой начнем программировать на Python. Если вы только начинаете осваивать Python, рекомендую вам эту статью.Среду для решения задачи с такси можно настроить при помощи Gym от компании OpenAI – это одна из самых популярных библиотек для решения задач на обучение с подкреплением. Хорошо, прежде чем использовать gym, ее нужно установить на вашей машине, а для этого удобен менеджер пакетов Python под названием pip. Ниже приведена установочная команда.
pip install gymДалее давайте посмотрим, как будет отображаться наша среда. Все модели и интерфейс для этой задачи уже сконфигурированы в gym и поименованы под
Taxi-V2. Для отображения этой среды используется приведенный ниже фрагмент кода. “Имеем 4 местоположения (обозначенных разными буквами); наша задача – подхватить пассажира в одной точке и высадить его в другой. Получаем +20 очков за успешную высадку пассажира и теряем 1 очко за каждый шаг, затраченный на это. Также предусмотрен штраф 10 очков за каждую непредусмотренную посадку и высадку пассажира.” (Источник: gym.openai.com/envs/Taxi-v2)
Вот какой вывод мы увидим в нашей консоли:

Taxi V2 ENV
Отлично,
env – это сердце OpenAi Gym, представляет собой унифицированный интерфейс среды. Далее приведены методы env, которые нам весьма пригодятся: env.reset: сбрасывает окружающую среду и возвращает случайное исходное состояние.env.step(action): Продвигает развитие окружающей среды на один шаг во времени.env.step(action): возвращает следующие переменные observation: Наблюдение за окружающей средой.reward: Характеризует, было ли полезно ваше действиеdone: Указывает, удалось ли нам правильно подобрать и высадить пассажира, также именуется «один эпизод».info: Дополнительная информация, например, о производительности и задержках, нужная для отладочных целейenv.render: Отображает один кадр среды (полезна при визуализации)
Итак, рассмотрев среду, давайте постараемся глубже понять задачу. Такси – единственный автомобиль на данной парковке. Парковку можно разбить в виде сетки
5x5, где получаем 25 возможных расположений такси. Эти 25 значений – один из элементов нашего пространства состояний. Обратите внимание: в настоящий момент наше такси расположено в точке с координатами (3, 1).В среде есть 4 точки, в которых допускается высадка пассажиров: это:
R, G, Y, B или [(0,0), (0,4), (4,0), (4,3)] в координатах (по горизонтали; по вертикали), если бы можно было интерпретировать вышеуказанную среду в декартовых координатах. Если также учесть еще одно (1) состояние пассажира: внутри такси, то можно взять все комбинации локаций пассажиров и их мест назначения, чтобы подсчитать общее количество состояний в нашей среде для обучения такси: имеем четыре (4) места назначения и пять (4+1) локаций пассажиров. Итак, в нашей среде для такси насчитывается 5×5×5×4=500 возможных состояний. Агент имеет дело с одним из 500 состояний и предпринимает действие. В нашем случае варианты действий таковы: перемещение в том или ином направлении, либо решение подобрать/высадить пассажира. Иными словами, у нас в распоряжении шесть возможных действий:
pickup, drop, north, east, south, west (Четыре последних значения – это направления, в которых может двигаться такси.)
Это пространство
action space: совокупность всех действий, которые наш агент может предпринять в заданном состоянии. Как понятно из иллюстрации выше, такси не может совершать определенные действия в некоторых ситуациях (мешают стены). В коде, описывающем среду, мы просто назначим штраф -1 за каждое попадание в стену, и такси, столкнувшись со стеной. Таким образом, подобные штрафы будут накапливаться, поэтому такси попытается не врезаться в стены.
Таблица вознаграждений: При создании среды «такси» также создается первичная таблица вознаграждений под названием P. Можно считать ее матрицей, где количество состояний соответствует числу строк, а количество действий – числу столбцов. Т.е., речь идет о матрице
states × actions.Поскольку в эту матрицу записаны абсолютно все состояния, можно просмотреть заданные по умолчанию значения вознаграждений, присвоенные тому состоянию, что мы выбрали для иллюстрации:
>>> import gym
>>> env = gym.make("Taxi-v2").env
>>> env.P[328]
{0: [(1.0, 433, -1, False)],
1: [(1.0, 233, -1, False)],
2: [(1.0, 353, -1, False)],
3: [(1.0, 333, -1, False)],
4: [(1.0, 333, -10, False)],
5: [(1.0, 333, -10, False)]
}Структура этого словаря такова:
{action: [(probability, nextstate, reward, done)]}.- Значения 0–5 соответствуют действиям (south, north, east, west, pickup, dropoff), которые такси может совершать в актуальном состоянии, приведенном на иллюстрации.
- done позволяет судить, когда мы успешно высадили пассажира в нужной точке.
Для решения этой задачи без какого-либо обучения с подкреплением, можно задать целевое состояние, сделать выборку пространств, а затем, если удастся достичь целевого состояния за некоторое количество итераций – предположить, что этот момент соответствует максимальному вознаграждению. В других состояниях значение вознаграждения либо близится к максимуму, если программа действует правильно (приближается к цели), либо накапливает штрафы, если совершает ошибки. Причем, значение штрафа может дойти не ниже, чем до -10.
Давайте напишем код для решения этой задачи без обучения с подкреплением.
Поскольку у нас есть P-таблица с заданными по умолчанию значениями вознаграждения для каждого состояния, можем попытаться организовать навигацию нашего такси просто на основе этой таблицы.
Создаем бесконечный цикл, проматывающийся до тех пор, пока пассажир не попадет в место назначения (один эпизод), либо, иными словами, пока показатель вознаграждения не достигнет 20. Метод
env.action_space.sample() автоматически выбирает случайное действие из множества всех доступных действий. Рассмотрим, что происходит: import gym
from time import sleep
# Создаем thr env
env = gym.make("Taxi-v2").env
env.s = 328
# Устанавливаем в ноль количество итераций, штрафы и вознаграждение,
epochs = 0
penalties, reward = 0, 0
frames = []
done = False
while not done:
action = env.action_space.sample()
state, reward, done, info = env.step(action)
if reward == -10:
penalties += 1
# Каждый отображенный кадр помещаем в словарь для анимации
frames.append({
'frame': env.render(mode='ansi'),
'state': state,
'action': action,
'reward': reward
}
)
epochs += 1
print("Timesteps taken: {}".format(epochs))
print("Penalties incurred: {}".format(penalties))
# Выводим все возможные действия, состояния, вознаграждения
def frames(frames):
for i, frame in enumerate(frames):
clear_output(wait=True)
print(frame['frame'].getvalue())
print(f"Timestep: {i + 1}")
print(f"State: {frame['state']}")
print(f"Action: {frame['action']}")
print(f"Reward: {frame['reward']}")
sleep(.1)
frames(frames)
Вывод:
credits: OpenAI
Задача решена, но не оптимизирована, либо этот алгоритм будет работать не во всех случаях. Нам нужен подходящий взаимодействующий агент, чтобы количество итераций, затрачиваемых машиной/алгоритмом на решение задачи оставалось минимальным. Здесь нам поможет алгоритм Q-обучения, реализацию которого мы рассмотрим в следующем разделе.
Знакомство с Q-обучением
Ниже представлен наиболее востребованный и один из самых простых алгоритмов на обучение с подкреплением. Среда вознаграждает агента за постепенное обучение и за то, что в конкретном состоянии он совершает наиболее оптимальный шаг. В реализации, рассмотренной выше, у нас была таблица вознаграждений «P», по которой будет учиться наш агент. Опираясь на таблицу вознаграждений, он выбирает следующее действие в зависимости от того, насколько оно полезно, а затем обновляет еще одну величину, именуемую Q-значением. В результате создается новая таблица, называемая Q-таблица, отображаемая на комбинацию (Состояние, Действие). Если Q-значения оказываются лучше, то мы получаем более оптимизированные вознаграждения.
Например, если такси оказывается в состоянии, где пассажир оказывается в той же точке, что и такси, исключительно вероятно, что Q-значение для действия «подобрать» выше, чем для других действий, например, «высадить пассажира» или «ехать на север».
Q-величины инициализируются со случайными значениями, и по мере того, как агент взаимодействует со средой и получает различные вознаграждения, совершая те или иные действия, Q-значения обновляются в соответствии со следующим уравнением:

Здесь возникает вопрос: как инициализировать Q-значения и как рассчитывать их. По мере выполнения действий Q-значения выполняются в данном уравнении.
Здесь Альфа и Гамма – параметры алгоритма на Q-обучение. Альфа – это темп обучения, а гамма – дисконтирующий множитель. Оба значения могут быть в диапазоне от 0 до 1 и иногда равны единице. Гамма может быть равна нулю, а альфа – не может, поскольку значение потерь при обновлении должно компенсироваться (темп обучения — положителен). Альфа-значение здесь такое же, как и при обучении с учителем. Гамма определяет, какую важность мы хотим придать вознаграждениям, ожидающим нас в перспективе.
Данный алгоритм кратко изложен ниже:
- Шаг 1: инициализируем Q-таблицу, заполняя ее нулями, а для Q-значений задаем произвольные константы.
- Шаг 2: теперь пусть агент реагирует на окружающую среду и пробует разные действия. Для каждого изменения состояния выбираем одно из всех действий, возможных в данном состоянии (S).
- Шаг 3: Переходим к следующему состоянию (S’) по результатам предыдущего действия (a).
- Шаг 4: Для всех возможных действий из состояния (S’) выбираем одно с наивысшим Q-значением.
- Шаг 5: Обновляем значения Q-таблицы в соответствии с вышеприведенным уравнением.
- Шаг 6: Превращаем следующее состояние в текущее.
- Шаг 7: Если целевое состояние достигнуто – завершаем процесс, а затем повторяем.
Q-обучение в Python
import gym
import numpy as np
import random
from IPython.display import clear_output
# Инициализируем Taxi-V2 Env
env = gym.make("Taxi-v2").env
# Инициализируем произвольные значения
q_table = np.zeros([env.observation_space.n, env.action_space.n])
# Гиперпараметры
alpha = 0.1
gamma = 0.6
epsilon = 0.1
all_epochs = []
all_penalties = []
for i in range(1, 100001):
state = env.reset()
# Инициализируем переменные
epochs, penalties, reward, = 0, 0, 0
done = False
while not done:
if random.uniform(0, 1) < epsilon:
# Проверяем пространство действий
action = env.action_space.sample()
else:
# Проверяем изученные значения
action = np.argmax(q_table[state])
next_state, reward, done, info = env.step(action)
old_value = q_table[state, action]
next_max = np.max(q_table[next_state])
# Обновляем новое значение
new_value = (1 - alpha) * old_value + alpha * \
(reward + gamma * next_max)
q_table[state, action] = new_value
if reward == -10:
penalties += 1
state = next_state
epochs += 1
if i % 100 == 0:
clear_output(wait=True)
print("Episode: {i}")
print("Training finished.")
Отлично, теперь все ваши значения будут храниться в переменной
q_table.Итак, ваша модель обучена в условиях окружающей среды, и теперь умеет более точно подбирать пассажиров. А вы познакомились с феноменом обучения с подкреплением, и можете запрограммировать алгоритм для решения новой задачи.
Другие приемы обучения с подкреплением:
- Марковские процессы принятия решений (MDP) и уравнения Беллмана
- Динамическое программирование: RL на основе моделей, итерация по стратегиям и итерация по значениям
- Глубокое Q-обучение
- Методы градиентного спуска по стратегиям
- SARSA
Код к этому упражнению находится по адресу:
vihar/python-reinforcement-learning
