Комментарии 27
И ни один скриншот не масштабируется (как тут можно сравнить)


простите, не могу удержаться


Пересняли скриншоты, сейчас должно быть получше
но ссылки так и не вставили. хочется приблизить и повертеть
Теперь все есть!
Не всё.
Где оригинальное изображение-то?
P.S. А ещё хотелось бы сравнения в движении(gif?). Сами же обратили внимание
Лично для меня временное мерцание это самый раздражающий эффект с которым борется АА.(Лесенки конечно хуже, но их уже победили на достаточном для меня уровне)
В результате папоротники в случае DLSS 2.0 выглядят даже более детальными, чем на оригинальном изображении.
Где оригинальное изображение-то?
P.S. А ещё хотелось бы сравнения в движении(gif?). Сами же обратили внимание
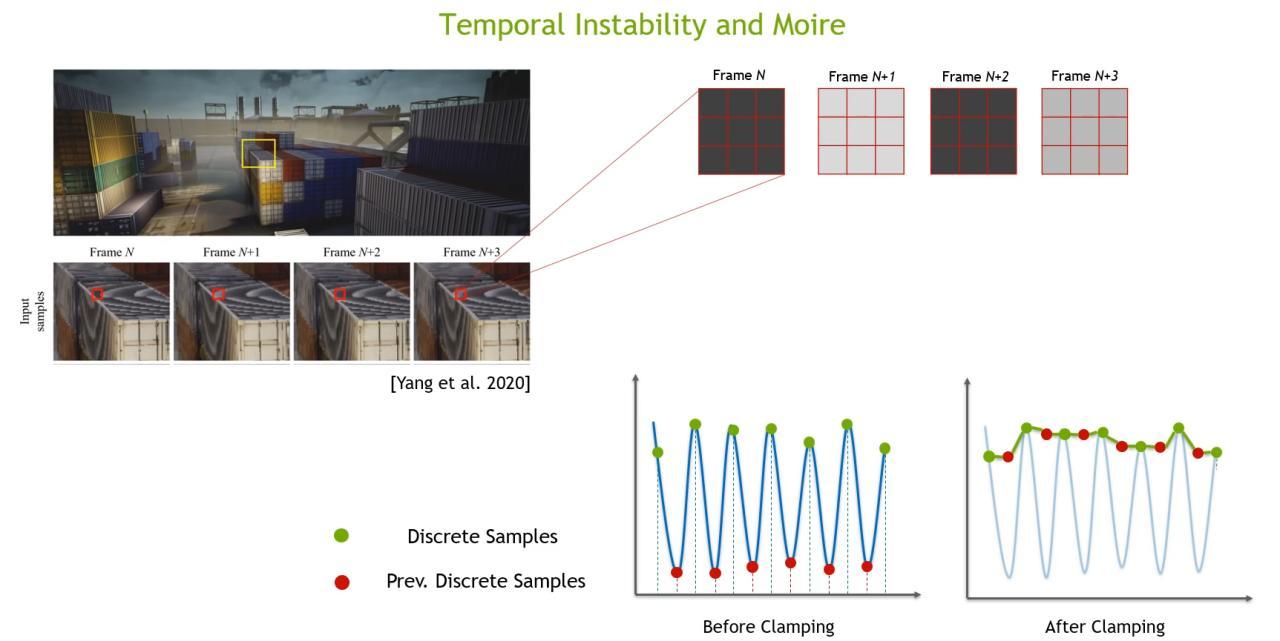
Временное мерцание и муар на изображениях с Neighbour Clamping
Лично для меня временное мерцание это самый раздражающий эффект с которым борется АА.(Лесенки конечно хуже, но их уже победили на достаточном для меня уровне)
Где оригинальное изображение-то?
В примерах по умолчанию включен TAA, так что считаем 1080 TAA
Временное мерцание и муар на изображениях с Neighbour Clamping
Этот эффект в динамике показывается здесь на моменте 32:49:
Видео
Ну и в статье эффект покадрово:
1)Т.е. вы попортили чёткость оригинала ТАА, а потом сравнивая DLSS с TAA говорите что DLSS чётче оригинала? TAA настолько жутко мажет картинку, что я использовал его буквально в одной игре.
2)Про мерцание «претензия» не к тому что не сравнили, а что не выложили сэмплы для сравнения в удобном виде. Ну это же классика-параллельно запустить 2 отрезка. Один с одними настройками, а другой с другими.
2)Про мерцание «претензия» не к тому что не сравнили, а что не выложили сэмплы для сравнения в удобном виде. Ну это же классика-параллельно запустить 2 отрезка. Один с одними настройками, а другой с другими.
НЛО прилетело и опубликовало эту надпись здесь
на канале «этот компьютер» автор рассказывал про это очень интересно. технологии, конечно… жаль живём мало, очень бы хотелось технологическое будущее пощупать
DLSS искажает картинку. При этом сравнение почему-то проводится с TAA без DLSS, который тоже может искажать картинку — на канале Digital Foundry в сравнении Death Stranding есть примеры. При том сравнений «обычная картинка — DLSS» на том же канале едва пара штук и на них видно, что при включённом DLSS пропадает «туман», дымка синего светофильтра, являющегося частью картинки.
Вообще, не спорю, алгоритм даёт двойную производительность при 90% картинке, если не тянет ПК — это спасение, но, во-первых, нельзя ли это включить для всех игр на уровне драйвера, если его больше не требуется обучать для каждой игры отдельно, а во-вторых, не окажется ли это типичным vaporware от Nvidia вроде PhysX, когда сначала благодаря рекламе пользователи покупают железо, потом технология оказывается заброшена, а на рынке появляется общая альтернатива? Для DLSS даже версии 2.0 всё ещё требуется драйвер под определённую игру.
Вообще, не спорю, алгоритм даёт двойную производительность при 90% картинке, если не тянет ПК — это спасение, но, во-первых, нельзя ли это включить для всех игр на уровне драйвера, если его больше не требуется обучать для каждой игры отдельно, а во-вторых, не окажется ли это типичным vaporware от Nvidia вроде PhysX, когда сначала благодаря рекламе пользователи покупают железо, потом технология оказывается заброшена, а на рынке появляется общая альтернатива? Для DLSS даже версии 2.0 всё ещё требуется драйвер под определённую игру.
Следующий шаг — улучшение качества фотографий, как в дурацких фильмах, где из пары пикселей собирают качественное фото?
Ты должен понимать что это физически не возможно. Из 2 пикселей нельзя получить картинку 320x240 пикселей, это возможно только в фильмах. Если получить фото то искажения будут очень сильными. Посмотри как сейчас увеличивают картинки используя нейросети, там очень много шумов и не естественных деталей.
Чтож, как кто-то писал "никто не удивится появлению искусственного разума больше, чем его разработчики".
А нормальную нейросетку поставить на кластер и натренировать, чтоб не задавать больше глупых вопросов, всё руки не доходят.
Повышение разрешения – вполне типичная обратная задача, при решении которой мы страдаем от слишком большого (бесконечного) числа допустимых решений, а не от их отсутствия.
Почти невозможно получить изображение, совпадающее с оригиналом высокого разрешения, имея только один снимок без дополнительной информации. Какое-то правдоподобное изображение 320x240 можно получить и из одного пикселя: например, если заранее понизить разрешение большого числа картинок до одного пикселя, среди этих значений найти ближайшее ко входу и взять в качестве результата соответствующее изображение исходного разрешения.
Если говорить о нейросетях, то существует не меньше двух фундаментально разных подходов для этой задачи: просто натренировать сеть повышать разрешение и натренировать сеть рисовать реалистичные изображения, после чего решать задачу оптимизации не в пространстве изображений, а в пространстве входа нейросети. Первый подход быстрый, но для него довольно сложно гарантировать, например, что понизив разрешение обратно, мы получим входное изображение. Второй же подход для каждого изображения будет работать долго, но и гарантий больше. Если посмотреть на работы последних лет по GAN, можно увидеть серьёзный прогресс как минимум в генерации реалистичных картинок, то есть поверить, что второй подход будет работать вполне можно. Причём с GAN можно пользоваться ещё и условием максимальности оценки дискриминатора.
Возвращаясь к обратной задаче, если есть дополнительная информация, например мы знаем что на снимке лицо, а снимков несколько, то условий в задаче становится сильно больше, а множество решений сужается, и тогда становится возможным уже достаточно точно восстановить исходное изображение, как в кино.
Почти невозможно получить изображение, совпадающее с оригиналом высокого разрешения, имея только один снимок без дополнительной информации. Какое-то правдоподобное изображение 320x240 можно получить и из одного пикселя: например, если заранее понизить разрешение большого числа картинок до одного пикселя, среди этих значений найти ближайшее ко входу и взять в качестве результата соответствующее изображение исходного разрешения.
Если говорить о нейросетях, то существует не меньше двух фундаментально разных подходов для этой задачи: просто натренировать сеть повышать разрешение и натренировать сеть рисовать реалистичные изображения, после чего решать задачу оптимизации не в пространстве изображений, а в пространстве входа нейросети. Первый подход быстрый, но для него довольно сложно гарантировать, например, что понизив разрешение обратно, мы получим входное изображение. Второй же подход для каждого изображения будет работать долго, но и гарантий больше. Если посмотреть на работы последних лет по GAN, можно увидеть серьёзный прогресс как минимум в генерации реалистичных картинок, то есть поверить, что второй подход будет работать вполне можно. Причём с GAN можно пользоваться ещё и условием максимальности оценки дискриминатора.
Возвращаясь к обратной задаче, если есть дополнительная информация, например мы знаем что на снимке лицо, а снимков несколько, то условий в задаче становится сильно больше, а множество решений сужается, и тогда становится возможным уже достаточно точно восстановить исходное изображение, как в кино.
Пример как поможет GAN
Пусть есть сеть G, которая по какому-то входному вектору x генерирует реалистичное лицо, сеть D оценивающая реалистичность изображения и дифференцируемая операция понижения разрешения F(y). Составим цепочку: x – G(x) – F(G(x)).
Если изображение одно, то ищем оптимальный x* (например, градиентным спуском), чтобы минимизировать различие между F(G(x)) и исходным изображением, а также максимизировать реалистичность, то есть оценку D(x). С различными начальными приближениями можно получать различные x, по ним генерировать реалистичные изображения G(x), соответствующие условиям.
Важно, что таким образом мы значительно сузили пространство поиска среди изображений до реалистичных (действительно ли максимизация D гарантирует реалистичность – отдельный для каждого метода вопрос), поэтому искажений скорей всего не будет.
Когда доступны несколько снимков объекта, можно искать набор близких друг к другу x_i, таких, чтобы каждый x_i минимизировал различие со своим снимком – это поможет ещё больше сузить пространство поиска и более точно восстановить каждое изображение.
Если изображение одно, то ищем оптимальный x* (например, градиентным спуском), чтобы минимизировать различие между F(G(x)) и исходным изображением, а также максимизировать реалистичность, то есть оценку D(x). С различными начальными приближениями можно получать различные x, по ним генерировать реалистичные изображения G(x), соответствующие условиям.
Важно, что таким образом мы значительно сузили пространство поиска среди изображений до реалистичных (действительно ли максимизация D гарантирует реалистичность – отдельный для каждого метода вопрос), поэтому искажений скорей всего не будет.
Когда доступны несколько снимков объекта, можно искать набор близких друг к другу x_i, таких, чтобы каждый x_i минимизировал различие со своим снимком – это поможет ещё больше сузить пространство поиска и более точно восстановить каждое изображение.
Мне кажется следующим (ну или скорее одним из следующих, в неопределённом будущем) шагом будет генерация картинки без исходного изображения — просто данные сцены перевариваем в удобоваримый для нейронки формат, а она генерирует изображение с практически любым разрешением и с учётом предыдущих кадров (чтобы изображение не «плыло»). От разработчиков требуется только скормить ей в начале частичный набор данных предобучения, аналог нынешних мешей и текстур, и, так сказать, тяп-ляп и в продакшн.
А как вообще такое будет редактироваться? Сейчас больше развивается генерация материалов из просты текстур, генерация моделек органики. В будущем скорее всего будет тот же PBR, но в профиль: материалы получат реальные физические свойства, смогут размазываться и крошиться, разваливаться и получаться повреждения. Нормальная система физики и их вида. Сейчас это тоже можно шейдерами добиться, но это надо нехилый скилл иметь, что-бы оно нормально выглядело.
Нормальную физику уж много лет как можно реализовать. Когда-то вышел Red Faction, где можно было крушить почти всё, и тогда многим казалось, что будущее игр — за полной разрушаемостью окружения. Но этого не наступило, и очевидно проблема тут вовсе не в технической сложности, а в сложности игровой разработки — если игрок может разрушить всё (а в условиях реальной физики он вполне может разрушить практически всё), то его ничем нельзя будет ограничить, нельзя будет предсказать, куда игрок попытается пролезть и это будет ломать игровые скрипты, либо делать их невероятно сложными.
Я всё-таки про другое говорил, исключительно про технику рендеринга. Опять же, глядя в прошлое, когда-то многие верили, что будущее за воксельной графикой, которая позволила бы полностью избавиться от ограничений на количество полигонов. Но этого так и не произошло. Сейчас смотрят на рейтресинг как технологию будущего (в смысле, полный и полноценный, а не как сейчас, когда он используется в первую очередь как дополнение к классическому рендерингу, которое подкрашивает картинку более реалистичными цветами, тенями и отражениями). Но ведь вполне несложно представить, как вместо классического пайплайна картинку генерирует нейросеть на базе данных о сцене и предобучения. И тут пожалуйста, теоретически, если нейронка достаточно большая и обучена на достаточном массиве данных, то если игрок захочет рассмотреть кожу вплотную, то он сможет увидеть каждую волосинку на ней, каждую дорожку папиллярного узора, и при этом нагрузка на вычислитель всегда будет практически одинаковой.
Но это так, измышлизмы, разумеется, до такой технологии пока ещё далеко (однако же, стоит ли мне напомнить, что шаги в этом направлении уже есть — нейронки, которые дорисовывают картинку по данным от пользователя, или же нейронки, которые рисуют картины с нуля со словесного описания).
Я всё-таки про другое говорил, исключительно про технику рендеринга. Опять же, глядя в прошлое, когда-то многие верили, что будущее за воксельной графикой, которая позволила бы полностью избавиться от ограничений на количество полигонов. Но этого так и не произошло. Сейчас смотрят на рейтресинг как технологию будущего (в смысле, полный и полноценный, а не как сейчас, когда он используется в первую очередь как дополнение к классическому рендерингу, которое подкрашивает картинку более реалистичными цветами, тенями и отражениями). Но ведь вполне несложно представить, как вместо классического пайплайна картинку генерирует нейросеть на базе данных о сцене и предобучения. И тут пожалуйста, теоретически, если нейронка достаточно большая и обучена на достаточном массиве данных, то если игрок захочет рассмотреть кожу вплотную, то он сможет увидеть каждую волосинку на ней, каждую дорожку папиллярного узора, и при этом нагрузка на вычислитель всегда будет практически одинаковой.
Но это так, измышлизмы, разумеется, до такой технологии пока ещё далеко (однако же, стоит ли мне напомнить, что шаги в этом направлении уже есть — нейронки, которые дорисовывают картинку по данным от пользователя, или же нейронки, которые рисуют картины с нуля со словесного описания).
По моему это будет очень дорогая технология, если можно будет увидеть каждую волосинку на коже при приближении. Даже если теоретически как-то ОЧЕНЬ ХИТРО это лодировать и отсекать, всё равно объем генерирующихся данных будет гигантский. Хотя, идея мне нравится)
Как сказать, и да, и нет. ДА — в том плане, что это будет в принципе очень дорогая технология, нужна огромная нейронка, обученная на огромной базе, да и к ней ещё и жирненький такой вектор инициализации под конкретную игру. Естественно, чтобы её обработать, потребуется недюжая вычислительная мощность (впрочем, вполне допустимая, с учётом темпов технологического развития и специализированных тензорных процессоров).
НЕТ — потому что нагрузка будет более-менее одинаковой всегда, куда ни посмотри, сколько бы деталей ни было в кадре, потому что нейронка одна и та же, ей без разницы, нужно ли сгенерировать лохматую шкуру, планету Земля и всё, что на ней или поле ржи, она сделает это за один проход.
НЕТ — потому что нагрузка будет более-менее одинаковой всегда, куда ни посмотри, сколько бы деталей ни было в кадре, потому что нейронка одна и та же, ей без разницы, нужно ли сгенерировать лохматую шкуру, планету Земля и всё, что на ней или поле ржи, она сделает это за один проход.
Понимаете, вы всё это представляете что всё это будет генерироваться каким-то совершенно волшебным способом. Если у меня, допустим есть текстура бетона, просто серое месиво, как оно поймёт что нужно сгенерировать? Как вообще такое хранить, или просто на лету генерировать? А «вектор инициализации под конкретную игру» как вообще будет настраиваться? Инструменты то откуда возьмуться? Я думаю что всё это будет очень долго развиваться, скорее к 10 годам, ибо и трудоёмко, и железо которое такие страшные заморочки потянет подтянется. И скорее всего оно прийдёт к какому-то намного более простому и менее ресурсоёмкому результату и скорее всего в реальном времени оно генерироваться не будет, а будет какой-то паттерт генерации материала в масштабе или что-то типа того. Судя по увеличению объёмов носителей, это просто будет хранится на компе.
Похоже, вы совсем не понимаете, как работают нейросети. У вас нет текстуры бетона. Текстуры всевозможных бетонов есть в самой нейросети, так же, как и модели, и они не отделены друг от друга, они все в обучающей выборке, и обучающая выборка в таком сценарии вообще должна состоять практически полностью из фотографий. Нейросеть структурирует, классифицирует данные из обучающей выборки «на свой вкус», выделяет в ней отдельные объекты, понимает их ракурсы по отношению к камере, их освещение по отношению к источникам света, и строит для всего этого свою внутреннюю модель, по которой она может сгенерировать то, чего в обучающей выборке не было. Какую модель — никто не знает, потому что нейросети состоят из миллиардов если не на порядки больше параметров. В этом есть своего рода магия — оно просто работает (но не всегда так, как надо).
Вот насчёт вектора инициализации уже чистые спекуляции, я не представляю как это возможно сделать, только что в нём примерно должно быть. А должна быть общая тема, чтобы нейросеть знала что примерно в игре находится, в каком стиле/тематике. Скажем, что дорожные знаки, например, в европейском или американском стиле.
Я и не утверждаю, что это будет завтра. Я и не утверждаю, что это вообще будет. Но чисто гипотетически это возможно. При этом
такой способ генерации ресурсоёмкий только до определённых пределов, после чего он становится менее ресурсоёмким, чем классический подход, причём это зависит от степени детализации. Чем большую детализацию и проработку сцены требуется изобразить, тем нейросеть выгоднее и проще. Потому что для неё не нужно много данных, ей нужно лишь указать, что вот здесь трава, здесь здание с такими-то размерами, в таком-то стиле, здесь вход в здание.
Короче, предлагаю вам высказать очередное «фе» и за сим закрывать дискуссию, потому что она начиналась со спекуляций и никуда дальше она не придёт. За объяснением принципов работы нейросетей — тут на хабре более чем достаточно и статей, и примеров.
Вот насчёт вектора инициализации уже чистые спекуляции, я не представляю как это возможно сделать, только что в нём примерно должно быть. А должна быть общая тема, чтобы нейросеть знала что примерно в игре находится, в каком стиле/тематике. Скажем, что дорожные знаки, например, в европейском или американском стиле.
Я думаю что всё это будет очень долго развиваться, скорее к 10 годам
Я и не утверждаю, что это будет завтра. Я и не утверждаю, что это вообще будет. Но чисто гипотетически это возможно. При этом
менее ресурсоёмкому результату
такой способ генерации ресурсоёмкий только до определённых пределов, после чего он становится менее ресурсоёмким, чем классический подход, причём это зависит от степени детализации. Чем большую детализацию и проработку сцены требуется изобразить, тем нейросеть выгоднее и проще. Потому что для неё не нужно много данных, ей нужно лишь указать, что вот здесь трава, здесь здание с такими-то размерами, в таком-то стиле, здесь вход в здание.
Короче, предлагаю вам высказать очередное «фе» и за сим закрывать дискуссию, потому что она начиналась со спекуляций и никуда дальше она не придёт. За объяснением принципов работы нейросетей — тут на хабре более чем достаточно и статей, и примеров.
В некоторых моментах статья напоминает скорее рекламную, чем техническую («в этом и заключается суть DLSS: преобразовать изображение с низким разрешением в более высокое» — «мы специально добавили в Gala компоненты из дорогого стирального порошка»).
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Бесплатные ФПС: как ИИ помогает сделать игровую графику лучше