Каждый, кто хоть раз играл в игры Playrix, замечал, что в них приходится много читать. Тексты окружают игрока повсюду: это разные элементы интерфейса, окна сезонов, баннеры, а также диалоговые окна, в которых разворачиваются целые сюжетные линии. Иногда нам кажется, что если собрать все наши игровые тексты, то можно выпустить ещё один том «Войны и мира».
Работать с таким большим количеством текстов сложно — у каждого из 7 проектов в релизе был свой способ подготовки шрифтов. В какой-то момент мы поняли, что нам нужно объединить усилия и создать общий для всех подход, который будет поддерживать специальная техническая команда.

В этой серии статей мы поделимся своими приемами в работе со шрифтами и расскажем, как мы используем TrueType и как сделать из нескольких ttf один и сжать 190 мегабайт исходных шрифтов в 12. А в конце ответим на вопрос, что делать, если нужно локализовать и на китайский, и на японский.
Всмотрись в бездну и… начнешь видеть разные засечки.

Немного истории
Мы видим текст с самого детства: буквари, титры фильмов, дорожные указатели. Чтение становится естественным процессом, а сами символы — чем-то побочным. Но при этом важно не только что написано, но и как: один и тот же текст, написанный разными шрифтами, восприниматься может по-разному.


Видите разницу? Представьте, что текста будет ещё больше.
Какой вариант шрифта вам нравится больше?

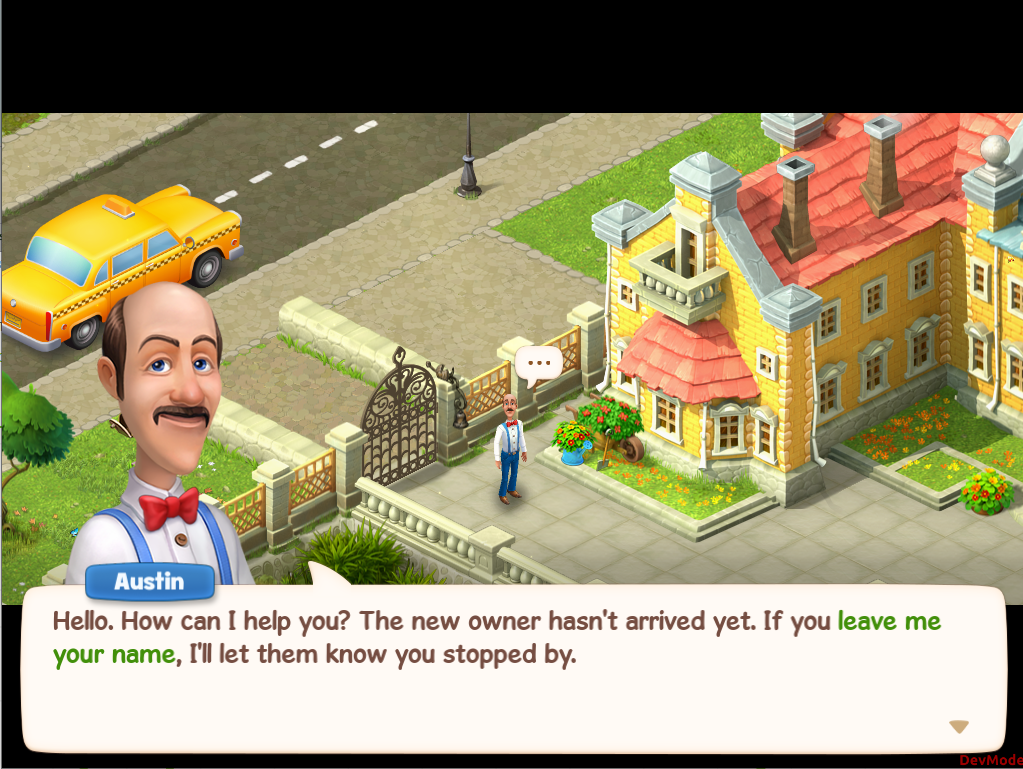
Кажется, что на первой картинке Остин не любезно предлагает представиться, а требует этого. С непременным подписанием многотомного контракта и мелким текстом под звездочкой. Такой шрифт был бы уместен в газете или в повестке в суд, но никак не в игре про уютный сад и вежливого дворецкого.
Типографика влияет на наше восприятие текста так же, как музыка влияет на атмосферу в фильмах. И это не просто так. Помните историю с фильмом «Аватар», бесплатным шрифтом «Папирус» на его логотипе и волну критики, обрушившуюся на его создателей? Чтобы разобраться, как типографика стала одним из сильнейших инструментов выражения смыслов, давайте немного погрузимся в историю письменности.
Сначала люди портили стены в пещерах, потом перешли на более мелкие площади и стали портить таблички. Все это — пиктографическое письмо.

Человечество накапливало знания, и рисунка уже не хватало — он стал распадаться на составные элементы, образные знаки. Так пиктографическое письмо переросло в логографическое. Его единицей была графема — минимальная единица письменности, обозначающая слово или морфему.
Один из примеров — египетские иероглифы. Изначально рисунок соответствовал отдельному понятию и имел внешнее сходство с тем, что на нем изображено.
 означает пчелу")

Но появились и логограммы — иероглифы, выражающие что-то абстрактное. Например, скипетр мог обозначать предмет, а мог символизировать власть и могущество. И потому читать иероглифы становилось все сложнее.
На фонетическое письмо, в котором уже появились буквы, правда, пока только согласные, первыми перешли финикийцы. Их ноу-хау подхватили греки, добавив от себя гласные, а римляне распространили радость чтения по всем регионам своей знаменитой империи.
Через много веков застоя родился Гутенберг и придумал печатный станок, потом Николя Жансон, начавший массово употреблять заглавные буквы, Баскервиль, школа Баухауса, Гельветика...
История типографики очень увлекательна, и если вам будет интересно углубиться, советуем начать с этих ссылок:
История типографики в разрезе печати математических символов;
Мастер класс по шрифтам — просто интересно и хорошо написано.
А что сегодня?
Несмотря на путь, который проделала письменность, наше восприятие текста в некотором смысле по-прежнему остается ассоциативным. Более строго оформленное сообщение — будь то приглашение на обед в виде пиктограммы грозного ножа или поздравление с праздником, набранное суровым шрифтом, — вряд ли откликнется как что-то приятное. И наоборот, предупреждение «Вы собираетесь удалить свой игровой прогресс без возможности восстановления», написанное в уютном мультяшном стиле, не транслирует пользователю реальную опасность, стоящую за этими словами.

В наших играх встречаются тексты разного содержания и направленности: интерфейсные, тексты комиксов и настроек игры. Для каждого из них дизайнеры подбирают наиболее информативные и легкие для восприятия шрифты. В результате шрифтов становится все больше, файл ttf раздувается до гигантских размеров, и это становится проблемой, которую программистам приходится как-то решать.
Способы приготовления шрифтов
Вот мы и добрались до подготовки шрифта — связующего звена между миром дизайна и картинкой на экране. Если взять все шрифты, нужные нам, например, для Gardenscapes, то они потянут где-то на 190 Мб. Многовато, учитывая ограничения на размер всего приложения в сторах (до 150 Мб в Google Play, до 200 Мб в App Store).
Первый вопрос, приходящий в голову — откуда столько? Для английских и русских текстов нужны все буквы алфавита, здесь все просто. А основной объем занимают иероглифы, которые исчисляются десятками тысяч. При этом из всего их многообразия мы используем 5-10 тысяч.
Второй вопрос — и что с этим всем делать? Файлов с исходными шрифтами у нас много, а для шрифтов с иероглифами может быть сразу несколько файлов с нужными символами. Поэтому надо их как-то сливать воедино, а лишнее отрезать.
Проекты в Playrix развивались параллельно, поэтому у каждого был свой способ подготовки. Но их было уже довольно сложно поддерживать и развивать из-за legacy-кода и некоторых наших требований, о которых мы поговорим ниже. Да и новым проектам затаскивать старый код тоже не хотелось. Чтобы сделать всем хорошо, мы собрали все шишки в одну корзину, и получилось два основных способа:
Из большого маленькое: собираем только нужные для конкретного шрифта символы и выкидываем лишние из исходного ttf.
Из множества одно: также собираем все нужные символы для шрифта и сливаем их из нескольких ttf в один.
Немного юридической информации
Мы скрупулезно подходим к лицензионным соглашениям, а тут нам нужно вносить изменения в файлы. Чтобы ничего не нарушить, идем по одному из этих путей:
Берем шрифты с Open Font Licence, которая разрешает без ограничений их использовать. Это наш идеальный вариант.
Связываемся с разработчиком, получаем у него согласие на внесение изменений в символы. Важный момент — дать разработчику понять, что мы встраиваем шрифт в приложение и не продаем как отдельный продукт. То есть шрифт никак не может в измененном состоянии использоваться вне приложения.
Ищем студию, которая занимается разработкой шрифтов, и получаем новый конечный продукт с независимой лицензией. Полностью наш.
Как у нас хранятся тексты и шрифты
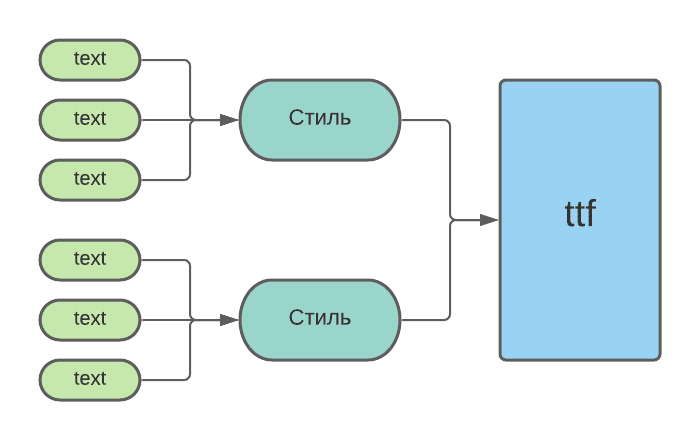
У нас очень много текстов, которые хранятся в xml со своим форматом. Они связаны с шрифтом через прослойку — стили. Именно стиль определяет, что будет в итоге на экране и какой ttf нужно загрузить.
Первый шаг подготовки — правильно найти символы и составить конфиг, в котором указать нужную информацию:
что собирать (symbols): все найденные символы записываются в txt-файл;
куда собирать (path): где мы хотим видеть конечный файл;
как собирать: merge_sources —будем сливать много в один; single_source — вырезать лишние символы.
Конфиг для сборщика шрифта:
[Fishdom.FDCustom.ttf]
path=%output_path%/FDCustom.ttf
symbols=%repo%/ci/intermediate/fonts/fd_custom.txt
merge_sources=%sources_path%/PoetsenOne.ttf;%sources_path%/FDCustomMajor.ttf;%sources_path%/SourceHanSans-Medium.ttf
[SourceHanSans.SourceHanSansSC-Bold.ttf]
path=%output_path%/SourceHanSansSC-Bold.ttf
symbols=%repo%/ci/intermediate/fonts/source_hansans.txt
single_source=%source_path%/SourceHanSansSC-Bold.ttfПогружение в ttf
Выше мы говорили о символах в контексте того, какие они бывают, как воспринимаются. Но в рамках TrueType символ — это абстрактная сущность, которая просто имеет какие-то характеристики. То, с чем мы имеем дело при подготовке шрифта, — глиф. Именно глиф представляет символ графически в том виде, в котором он отображается на экране.
Технически шрифт для TrueType — это набор таблиц, в одной из которых хранится глиф, а в остальных разнообразные свойства. Таблицы разделяются на:
Обязательные (cmap, glyf, head, hhea, htmx, loca, maxp, post). Без них у вас точно не взлетит.
Опциональные (cvt, fpgm, prep, и т. д. — полный список можно посмотреть здесь). То, что делает из обычного шрифта потрясающий.
Таблицы, которые нас тут больше всего интересуют, — glyf и cmap. В первой хранятся данные, которые определяют внешность глифа: спецификации точек и кривых, формирующих вид символа, а также набор инструкций для этого глифа. Вторая соединяет порядковый номер глифа в таблице glyf и юникод этого символа.
FontForge. Вырезаем лишнее
Писать низкоуровневый парсер мы не стали, и первое, к чему обратились — это FontForge. Он уже был на проектах несколько лет, все работало, и никто почти не жаловался, поэтому — копипаста. Утилита делает всю грязную работу за тебя: парсит, создает нужные таблицы, заполняет дефолтными значениями. Верхнеуровневый код для вырезания ненужных символов выглядит предельно просто.
import fontforge
def build_with_erasing(dst_font_path, source_font_path, chars):
font = fontforge.open(source_font_path)
exclude_unused_glyphs(font, chars)
font.generate(dst_font_path)
font.close()Утилита сама правильно загрузит шрифт и сохранит все таблицы при генерации. Нам остается написать логику вырезания символов.
def use_in_other_glyph(glyph, chars):
# altuni - Tuple of alternate encodings.
# Each alternate encoding is a tuple of
# (unicode-value, variation-selector, reserved-field)
# https://fontforge.org/docs/scripting/python/fontforge.html
if glyph.altuni is None:
return False
for alts in glyph.altuni:
if alts[0] in chars:
return True
return False
def exclude_unused_glyphs(font, chars):
for g in font.glyphs():
if g.unicode in chars:
continue
if use_in_other_glyph(g, chars):
# глиф используется в других глифах
continue
if g.glyphname != ".notdef":
g.unlinkThisGlyph()
g.clear()
Особенность при вырезании — сохранить все нужное. Как отмечали выше, для TrueType символ и глиф — не одно и то же. Последний может быть компонентным, то есть состоять из нескольких элементов. Например, Ć из шрифта GosmickSans сочетает в себе два глифа:
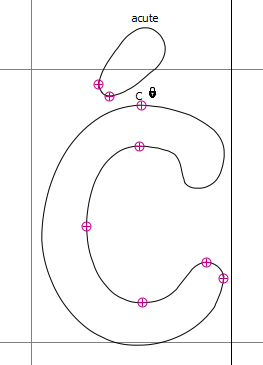
Если сохранить данные только одного глифа, то на экране символ будет отображаться некорректно. Нужно обязательно сохранять составляющие глифы: C (U+0043) и апостроф (U+0301).
Другой важный момент: нельзя удалять глиф с именем .notdef — он подставляется, когда искомый символ не найден в шрифте.
FontForge. Собираем один большой шрифт
Перед вставкой в билд сначала создаем пустой шрифт через функцию `fontforge.font() — в нем будет необходимый нам набор таблиц. А затем заполняем его: добавляем нужные символы из всех исходных шрифтов.
def copy_glyph_info(old, new):
points = old.anchorPoints
for point in points:
new.addAnchorPoint(point[0], point[1], point[2], point[3])
def append_fonts(dst_font_path, add_fonts, chars, family_name):
path = os.path.normpath(dst_font_path)
if not os.path.exists(path):
font_base = fontforge.font()
else:
font_base = fontforge.open(path)
for src_font_path in add_fonts:
font_add = fontforge.open(os.path.normpath(src_font_path))
for ch in chars:
glyphname = fontforge.nameFromUnicode(ord(ch))
font_base.createChar(ord(ch), glyphname)
font_add.selection.select(('more', 'unicode',), ord(ch))
font_base.selection.select(('more', 'unicode',), ord(ch))
font_add.copy()
font_base.paste()
font_add.selection.none()
font_base.selection.none()
for glyph in font_base.glyphs():
if glyph.glyphname in font_add:
oldGlyph = font_add[glyph.glyphname]
copy_glyph_info(oldGlyph, glyph)
font_base.familyname = family_name
font_base.fullname = family_name
font_base.fontname = family_name
font_base.generate(os.path.normpath(dst_font_path))И вот мы подошли к минусам FontForge.
Первый минус — его совершенно невозможно отлаживать. Ну, или мы не нашли способа. Запускать скрипт, использующий функционал FontForge можно только через его собственный собранный интерпретатор (документация). Все потому, что в python вынесены биндинги, а весь функционал в библиотеках. И, вероятно, это был самый удобный способ добавить поддержку python уже после релиза.
Другой минус — нельзя слить большие ttf одним махом. Эмпирическим путем мы выяснили, что FontForge падает при одновременном открытии ttf суммарным размером ~25-30 Mb, поэтому — здравствуйте, процессы. По факту все выполняется последовательно, ничего не ускорено. Но не падает из-за того, что запускается в другом процессе, и после его окончания память освобождается уже системой.
from multiprocessing import Process
def assemble_font(dst_font_path, name, chars, src_fonts):
count_in_chunk = 2 # по сколько шрифтов за раз можно сливать
fonts_chunks = [src_fonts[name][:4]] # Первые 4 шрифта лёгкие, можно пачкой обработать
fonts_chunks.extend([src_fonts[name][i:i + count_in_chunk] for i in range(4, len(src_fonts[name]), count_in_chunk)])
for add_fonts in fonts_chunks:
p = Process(target=append_fonts, args=(dst_font_path, add_fonts, chars, name))
p.start()
p.join()Ещё одна шишка, на которую мы наткнулись — при таком соединении нужно переносить информацию из других, опциональных, таблиц. Без них шрифт теряет красоту, которую в него заложил автор. Но это была эра проектных скриптов, когда завтра релиз, а шрифты нужны вчера. Тут не до таблиц и засечек! Скрипты даже затачивались под определенную последовательность шрифтов в массивах. И это работало — шрифты сокращались с 192 Мб до 12.
Однако в общем коде для всех проектов мы не можем позволить себе таких недочетов и хаков. Но — ура! — мы ведь в команде технологий, поэтому у нас есть время сделать хорошо. В следующей части мы расскажем, как погрузились в дебри формата, перешли на другой инструмент сборки и сделали шрифты красивее. Не переключайтесь!
