
Коронавирус типа 2019-nCoV, после вспышки заболевания в китайском городе Ухань, стремительно распространяется по миру. На момент написания оригинальной статьи (30 января 2020 года) сообщалось о более чем 9000 заражённых и о 213 умерших, на сегодня (10 февраля 2020 года) сообщается уже о 40570 зараженных, 910 человек умерло. Случаи заражения коронавирусом выявлены во Франции, в Австралии, в России, в Японии, в Сингапуре, в Малайзии, в Германии, в Италии, в Шри-Ланке, в Камбодже, в Непале и во многих других странах. Никто не знает о том, когда вирус будет остановлен. Пока же число подтверждённых случаев коронавируса лишь растёт.
Автор статьи, перевод которой мы сегодня публикуем, хочет рассказать о том, как, с использованием Python, создать простое приложение для отслеживания распространения коронавируса. После завершения работы над этим приложением в распоряжении читателя окажется HTML-страница, которая выводит карту распространения вируса и ползунок, который позволяет выбирать дату, по состоянию на которую данные выводятся на карту.
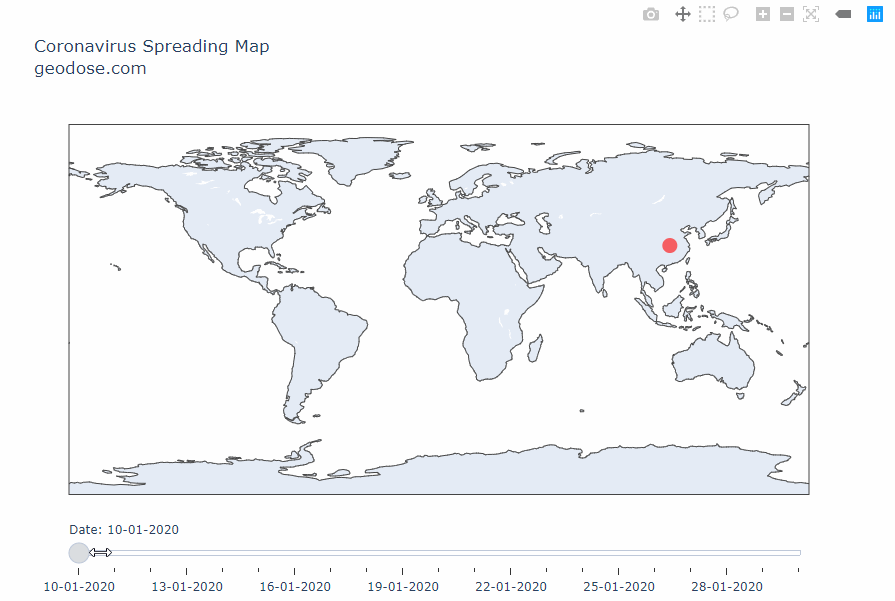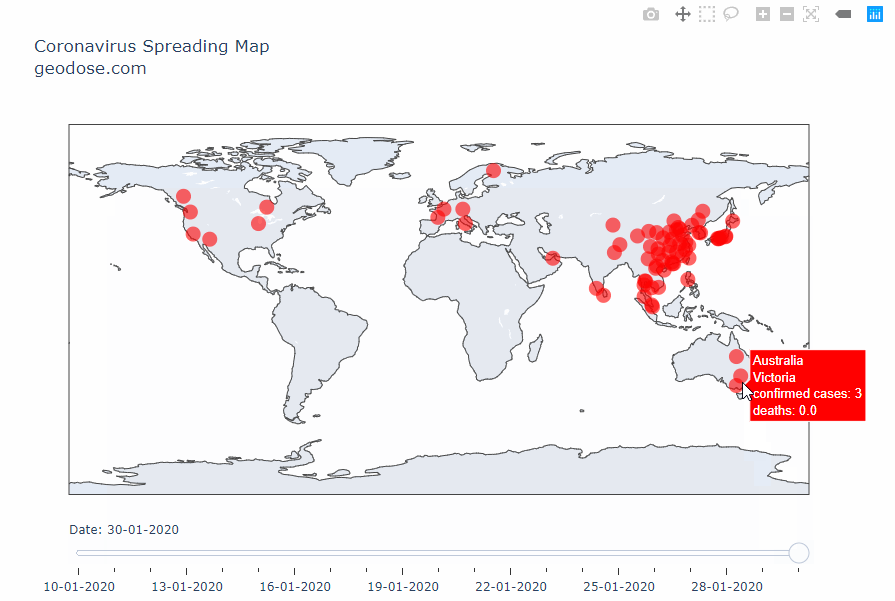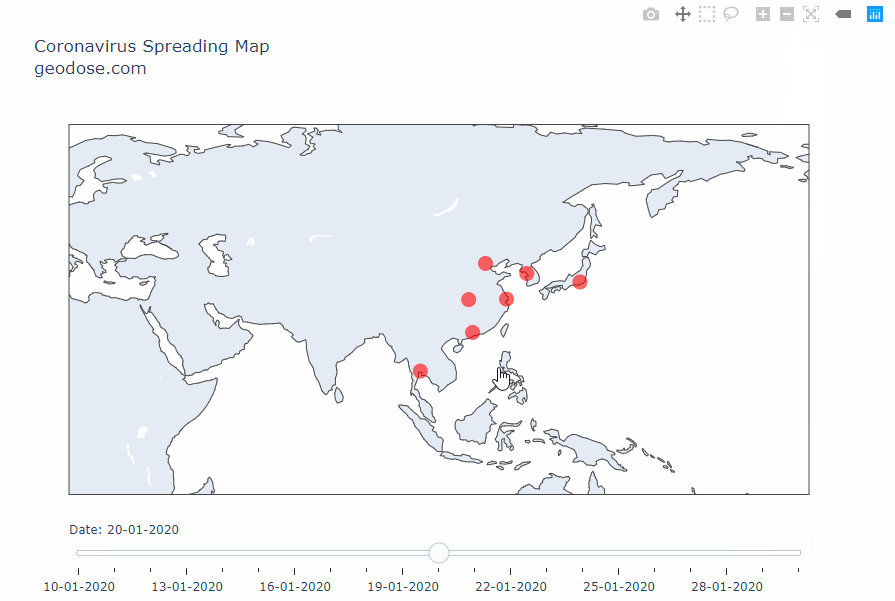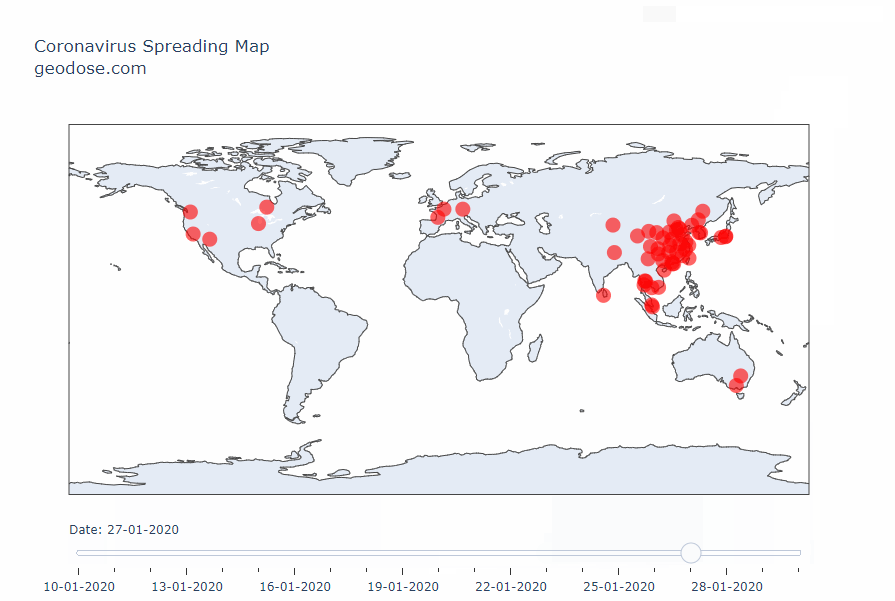
Интерактивная карта распространения коронавируса типа 2019-nCoV
Здесь будут использованы такие технологии, как Python 3.7, Pandas, Plotly 4.1.0 и Jupyter Notebook.
Начнём работу с импорта в проект, основанный на Jupyter Notebook, библиотек Plotly и Pandas.
Прежде чем двигаться дальше — попробуйте запустить код. Если вы не увидели сообщений об ошибках — значит все необходимые библиотеки у вас установлены и работают правильно. Если код запустить не удалось — загляните на официальные страницы Plotly и Pandas и почитайте справочные материалы и материалы по установке этих библиотек. Если у вас нет системы Jupyter Notebook, работающей на вашем аппаратном обеспечении — рекомендую воспользоваться Google Colab — облачной платформой, позволяющей работать с Jupyter Notebook.
Данные, которыми мы тут пользуемся, можно найти здесь. Это — расшаренная таблица из документов Google, которая ежедневно обновляется. Огромное спасибо всем тем, кто поддерживает её в актуальном состоянии! Вы делаете очень нужную работу.
Мы будем читать данные, используя метод Pandas
Нам нужно заменить выделенный фрагмент ссылки, приведя ссылку к такому виду:
В следующем коде мы инициализируем переменную
Понимание того, как устроены структуры данных, которые мы используем, чрезвычайно важно на данном шаге работы, так как это определяет то, какой подход к обработке данных мы применим. Просмотрим данные, воспользовавшись командой
Первые 5 строк данных по коронавирусу
В левом нижнем углу можно видеть сведения о том, что в таблице данных имеется 47 столбцов. Вот имена первых пяти столбцов:
Имена первых пяти столбцов таблицы не меняются, но с течением времени в таблицу будут добавляться колонки с новыми именами. То, что будет выводить наша интерактивная карта, представляет собой визуализацию распространения коронавируса с возможностью указания дня, по данным которого формируется карта. Поэтому нам нужно разделить весь набор данных, выбрав из него сведения по каждому дню и учитывая то, что первые 5 столбцов таблицы не меняются, и то, что каждый день описывается двумя столбцами. Затем, если внимательнее присмотреться к данным, например — к данным за 10.01.2020, то окажется, что этой дате соответствует множество строк. На самом деле, на эту дату обнаружение коронавируса было подтверждено лишь в одном месте, что отмечено соответствующим числом. Во всех других строках на эту дату содержатся лишь нули. Это означает, что нам нужно исключить эти строки из процесса построения карты.
Процесс подготовки данных к визуализации производится в цикле.
В процессе работы выходные данные каждого набора данных добавляются к Scattergeo-графику с использованием
Здесь мы создадим слайдер, с помощью которого организован выбор данных, визуализируемых на карте. Вот соответствующий код:
Код слайдера состоит из двух основных фрагментов. Первый — это цикл, в котором заполняется список
Сейчас мы подошли к финальной части материала. Тут мы поговорим о том, как выводить карту, и о том, как сохранять её в формате HTML. Вот код, реализующий эти операции:
Когда карта выводится на экран, видимым оказывается визуальное представление первого набора данных. Затем мы делаем так, чтобы содержимое карты обновлялось бы в соответствии с положением слайдера. Тут же мы задаём заголовок карты и настраиваем её высоту. На последнем шаге мы выводим карту, пользуясь методом
Вот полный код проекта, позволяющего создать карту распространения коронавируса типа 2019-nCoV. Обратите внимание на то, что последнюю строчку, ответственную за сохранение HTML-варианта карты, нужно отредактировать, заменив указанный там путь на тот, который актуален для вас.
Мы завершили разбор руководства, посвящённого созданию интерактивной карты визуализации распространения коронавируса типа 2019-nCoV. Проработав этот материал, вы узнали о том, как читать данные из общедоступных таблиц Google, как выполнять обработку данных с помощью Pandas, и как визуализировать эти данные на интерактивной карте с использованием слайдера и Plotly. Результат работы проекта в виде HTML-страницы можно загрузить отсюда. Информация, выводимая на карте, зависит от таблицы с данными. Каждый раз, когда выполняется код проекта, карта обновляется, на ней становятся доступными свежие данные из таблицы. Это — очень простая карта. Существует множество путей её улучшения. Например, её можно дополнить дополнительными графиками, некими сводными данными и так далее. Если вам это интересно — вы вполне можете сделать всё это и многое другое самостоятельно.
Уважаемые читатели! Для решения каких задач вы пользуетесь технологией Jupyter Notebook?

Автор статьи, перевод которой мы сегодня публикуем, хочет рассказать о том, как, с использованием Python, создать простое приложение для отслеживания распространения коронавируса. После завершения работы над этим приложением в распоряжении читателя окажется HTML-страница, которая выводит карту распространения вируса и ползунок, который позволяет выбирать дату, по состоянию на которую данные выводятся на карту.
Интерактивная карта распространения коронавируса типа 2019-nCoV
Здесь будут использованы такие технологии, как Python 3.7, Pandas, Plotly 4.1.0 и Jupyter Notebook.
Импорт библиотек
Начнём работу с импорта в проект, основанный на Jupyter Notebook, библиотек Plotly и Pandas.
import plotly.offline as go_offline
import plotly.graph_objects as go
import pandas as pdПрежде чем двигаться дальше — попробуйте запустить код. Если вы не увидели сообщений об ошибках — значит все необходимые библиотеки у вас установлены и работают правильно. Если код запустить не удалось — загляните на официальные страницы Plotly и Pandas и почитайте справочные материалы и материалы по установке этих библиотек. Если у вас нет системы Jupyter Notebook, работающей на вашем аппаратном обеспечении — рекомендую воспользоваться Google Colab — облачной платформой, позволяющей работать с Jupyter Notebook.
Обработка данных
Данные, которыми мы тут пользуемся, можно найти здесь. Это — расшаренная таблица из документов Google, которая ежедневно обновляется. Огромное спасибо всем тем, кто поддерживает её в актуальном состоянии! Вы делаете очень нужную работу.
Мы будем читать данные, используя метод Pandas
read_csv. Но прежде чем загружать данные из таблицы, воспользовавшись ссылкой на неё, нам нужно поработать с этой ссылкой. Сейчас она выглядит так:https://docs.google.com/spreadsheets/d/18X1VM1671d99V_yd-cnUI1j8oSG2ZgfU_q1HfOizErA/edit#gid=0Нам нужно заменить выделенный фрагмент ссылки, приведя ссылку к такому виду:
https://docs.google.com/spreadsheets/d/18X1VM1671d99V_yd-cnUI1j8oSG2ZgfU_q1HfOizErA/export?format=csv&idВ следующем коде мы инициализируем переменную
url, записывая в неё ссылку на данные, читаем данные с использованием метода read_csv и записываем в пустые ячейки, содержащие NaN, значения 0.url='https://docs.google.com/spreadsheets/d/18X1VM1671d99V_yd-cnUI1j8oSG2ZgfU_q1HfOizErA/export?format=csv&id'
data=pd.read_csv(url)
data=data.fillna(0)Понимание того, как устроены структуры данных, которые мы используем, чрезвычайно важно на данном шаге работы, так как это определяет то, какой подход к обработке данных мы применим. Просмотрим данные, воспользовавшись командой
data.head(). Это приведёт к выводу первых 5 строк таблицы.Первые 5 строк данных по коронавирусу
В левом нижнем углу можно видеть сведения о том, что в таблице данных имеется 47 столбцов. Вот имена первых пяти столбцов:
country, location_id, location, latitude и longitude. Другие столбцы представляют собой пары, имена которых построены по следующей схеме: confirmedcase_dd-mm-yyyy и deaths_dd-mm-yyyy. Общее число столбцов в таблице на момент написания этого материала было 47. Это означает, что в моём распоряжении были данные за 21 день ((47-5)/2=21). Если начальной датой сбора данных было 10.01.2020, то конечной датой было 30.01.2020.Имена первых пяти столбцов таблицы не меняются, но с течением времени в таблицу будут добавляться колонки с новыми именами. То, что будет выводить наша интерактивная карта, представляет собой визуализацию распространения коронавируса с возможностью указания дня, по данным которого формируется карта. Поэтому нам нужно разделить весь набор данных, выбрав из него сведения по каждому дню и учитывая то, что первые 5 столбцов таблицы не меняются, и то, что каждый день описывается двумя столбцами. Затем, если внимательнее присмотреться к данным, например — к данным за 10.01.2020, то окажется, что этой дате соответствует множество строк. На самом деле, на эту дату обнаружение коронавируса было подтверждено лишь в одном месте, что отмечено соответствующим числом. Во всех других строках на эту дату содержатся лишь нули. Это означает, что нам нужно исключить эти строки из процесса построения карты.
Процесс подготовки данных к визуализации производится в цикле.
#Инициализация некоторых переменных
fig=go.Figure()
col_name=data.columns
n_col=len(data.columns)
date_list=[]
init=4
n_range=int((n_col-5)/2)
#Цикл, в котором производится разбор данных и подготовка их к визуализации
for i in range(n_range):
col_case=init+1
col_dead=col_case+1
init=col_case+1
df_split=data[['latitude','longitude','country','location',col_name[col_case],col_name[col_dead]]]
df=df_split[(df_split[col_name[col_case]]!=0)]
lat=df['latitude']
lon=df['longitude']
case=df[df.columns[-2]].astype(int)
deaths=df[df.columns[-1]].astype(int)
df['text']=df['country']+'<br>'+df['location']+'<br>'+'confirmed cases: '+ case.astype(str)+'<br>'+'deaths: '+deaths.astype(str)
date_label=deaths.name[7:17]
date_list.append(date_label)
#Настройка графика Scattergeo
fig.add_trace(go.Scattergeo(
name='',
lon=lon,
lat=lat,
visible=False,
hovertemplate=df['text'],
text=df['text'],
mode='markers',
marker=dict(size=15,opacity=0.6,color='Red', symbol='circle'),
))В процессе работы выходные данные каждого набора данных добавляются к Scattergeo-графику с использованием
fig.add_trace. На момент написания материала данные, на основе которых будут строиться изображения, представлены 21 объектом. Проверить это можно, воспользовавшись командой fig.data.Создание слайдера
Здесь мы создадим слайдер, с помощью которого организован выбор данных, визуализируемых на карте. Вот соответствующий код:
#Код слайдера
steps = []
for i in range(len(fig.data)):
step = dict(
method="restyle",
args=["visible", [False] * len(fig.data)],
label=date_list[i],
)
step["args"][1][i] = True # Переключить i-й набор данных в состояние "visible"
steps.append(step)
sliders = [dict(
active=0,
currentvalue={"prefix": "Date: "},
pad={"t": 1},
steps=steps
)]Код слайдера состоит из двух основных фрагментов. Первый — это цикл, в котором заполняется список
steps, используемый при перемещении бегунка слайдера. При перемещении слайдера выполняется визуализация соответствующего набора данных и скрытие того, что было выведено до этого. Вторая часть кода — это включение сконструированного ранее списка steps в объект слайдера. Когда слайдер перемещается — осуществляется выбор соответствующего элемента из steps.Вывод карты и сохранение её в виде HTML-файла
Сейчас мы подошли к финальной части материала. Тут мы поговорим о том, как выводить карту, и о том, как сохранять её в формате HTML. Вот код, реализующий эти операции:
#Делаем видимым первый набор данных
fig.data[0].visible=True
#Выводим карту и сохраняем её в формате HTML
fig.update_layout(sliders=sliders,title='Coronavirus Spreading Map'+'<br>geodose.com',height=600)
fig.show()
go_offline.plot(fig,filename='F:/html/map_ncov.html',validate=True, auto_open=False)Когда карта выводится на экран, видимым оказывается визуальное представление первого набора данных. Затем мы делаем так, чтобы содержимое карты обновлялось бы в соответствии с положением слайдера. Тут же мы задаём заголовок карты и настраиваем её высоту. На последнем шаге мы выводим карту, пользуясь методом
fig.show, после чего сохраняем её в HTML с помощью метода go_offline.plot.Полный код проекта
Вот полный код проекта, позволяющего создать карту распространения коронавируса типа 2019-nCoV. Обратите внимание на то, что последнюю строчку, ответственную за сохранение HTML-варианта карты, нужно отредактировать, заменив указанный там путь на тот, который актуален для вас.
import plotly.offline as go_offline
import plotly.graph_objects as go
import pandas as pd
#Чтение данных
url='https://docs.google.com/spreadsheets/d/18X1VM1671d99V_yd-cnUI1j8oSG2ZgfU_q1HfOizErA/export?format=csv&id'
data=pd.read_csv(url)
data=data.fillna(0)
#Инициализация некоторых переменных
fig=go.Figure()
col_name=data.columns
n_col=len(data.columns)
date_list=[]
init=4
n_range=int((n_col-5)/2)
#Цикл, в котором производится разбор данных и подготовка их к визуализации
for i in range(n_range):
col_case=init+1
col_dead=col_case+1
init=col_case+1
df_split=data[['latitude','longitude','country','location',col_name[col_case],col_name[col_dead]]]
df=df_split[(df_split[col_name[col_case]]!=0)]
lat=df['latitude']
lon=df['longitude']
case=df[df.columns[-2]].astype(int)
deaths=df[df.columns[-1]].astype(int)
df['text']=df['country']+'<br>'+df['location']+'<br>'+'confirmed cases: '+ case.astype(str)+'<br>'+'deaths: '+deaths.astype(str)
date_label=deaths.name[7:17]
date_list.append(date_label)
#Настройка графика Scattergeo
fig.add_trace(go.Scattergeo(
name='',
lon=lon,
lat=lat,
visible=False,
hovertemplate=df['text'],
text=df['text'],
mode='markers',
marker=dict(size=15,opacity=0.6,color='Red', symbol='circle'),
))
#Код слайдера
steps = []
for i in range(len(fig.data)):
step = dict(
method="restyle",
args=["visible", [False] * len(fig.data)],
label=date_list[i],
)
step["args"][1][i] = True # Переключить i-й набор данных в состояние "visible"
steps.append(step)
sliders = [dict(
active=0,
currentvalue={"prefix": "Date: "},
pad={"t": 1},
steps=steps
)]
#Делаем видимым первый набор данных
fig.data[0].visible=True
#Выводим карту и сохраняем её в формате HTML
fig.update_layout(sliders=sliders,title='Coronavirus Spreading Map'+'<br>geodose.com',height=600)
fig.show()
go_offline.plot(fig,filename='F:/html/map_ncov_slider.html',validate=True, auto_open=False)Итоги
Мы завершили разбор руководства, посвящённого созданию интерактивной карты визуализации распространения коронавируса типа 2019-nCoV. Проработав этот материал, вы узнали о том, как читать данные из общедоступных таблиц Google, как выполнять обработку данных с помощью Pandas, и как визуализировать эти данные на интерактивной карте с использованием слайдера и Plotly. Результат работы проекта в виде HTML-страницы можно загрузить отсюда. Информация, выводимая на карте, зависит от таблицы с данными. Каждый раз, когда выполняется код проекта, карта обновляется, на ней становятся доступными свежие данные из таблицы. Это — очень простая карта. Существует множество путей её улучшения. Например, её можно дополнить дополнительными графиками, некими сводными данными и так далее. Если вам это интересно — вы вполне можете сделать всё это и многое другое самостоятельно.
Уважаемые читатели! Для решения каких задач вы пользуетесь технологией Jupyter Notebook?
