
Нет, конечно же, не убивает.
То, что мертво, умереть не может: доля линукса на десктопах колеблется около 2% уже много лет, и не имеет тенденций ни к росту, ни к падению, изменяясь на уровне статистической погрешности.
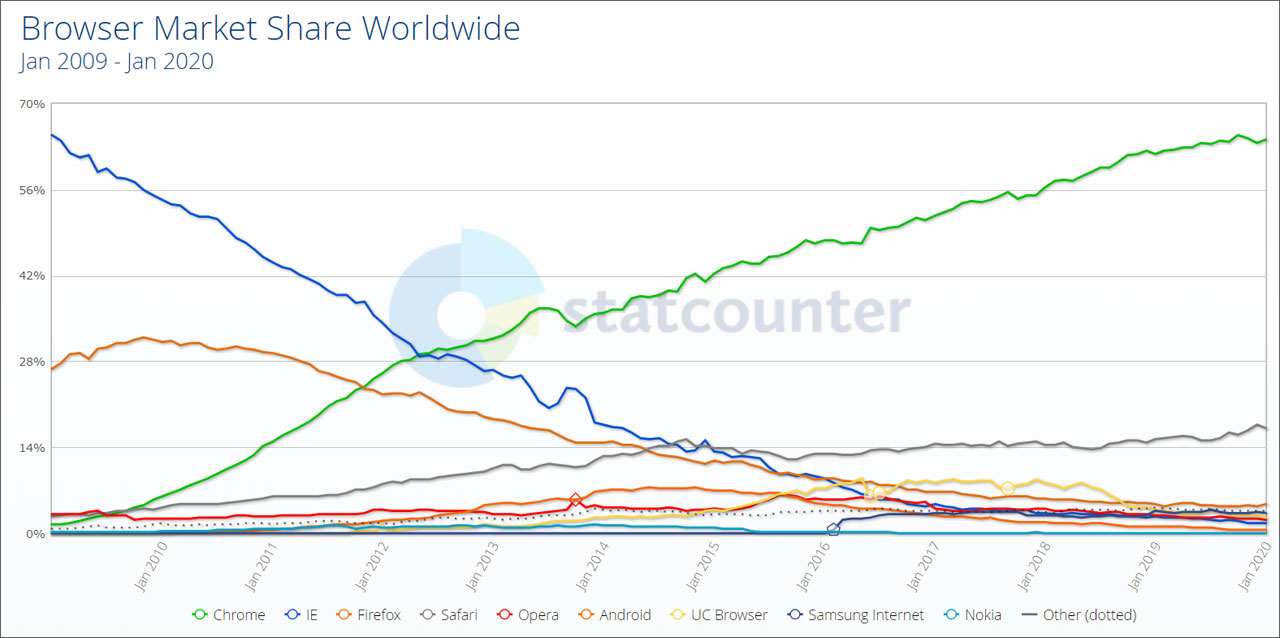
Как выглядит захват рынка конкурентоспособным продуктом, можно видеть на примере Chrome: за 10 лет рост на 70%. Или Android: за 5 лет рост на 75%. Отчасти за их успех ответственна поддержка своих продуктов гуглом, но поддержка и насаждение своей платформы это не основной двигатель: Windows Mobile (и второй, и первой) не помогла вся стоящая за спиной громада Microsoft.
А вот у Linux рост, от силы, пол-процента в год, несмотря на то, что он, например, лучший из существующих вариантов для использования в качестве национальных/государственных ОС.
Так что да, учитывая долю в 2%, которая не растет, но и не падает, все-таки "не дает вырасти", а не "убивает".
Дисклеймер
Автор не претендует на абсолютную правильность выводов и суждений, приведенная идея — скорее, затравка для дискуссии, а не всеобьясняющая концепция.
Автор предостерегает от спора с позиции "а у меня такая же нога и ничего не болит", и напоминает, что личный пример не служит доказательством. У вас нога не болит, у меня болит: мы тут в равных условиях. Но я потрудился подвести хоть сколько-нибудь логическую базу к моим тезисам, потрудитесь и вы спорить не с конкретными примерами (на каждый из них можно найти или придумать контрпример и рассказать, почему так), а с идеями. Примеры всего лишь иллюстрируют идеи.
Под "Десктопным Linux" автор имеет ввиду GNU/Linux-based дистрибутивы (Ubuntu, Debian, etc), установленные на обычном x86/x64 компьютере/ноутбуке, с GUI и используемые для бытовых или рабочих целей. Туда не входят такие системы как (даже если они используют ядро linux и его окружение):
1)Android и Chrome OS: несмотря на ядро, это не Linux в той мере, в какой мы его понимаем как продукт: там своя оболочка, свои настройки, свои интерфейсы, свои API для программных продуктов и так далее. Это не линукс, так же как и MacOS это не BSD.
2)Cпецифичные встраиваемые системы, тонкие клиенты, планшеты, умные телевизоры, умные приставки: хоть планшет и телевизор можно с натяжкой назвать десктопом, если подключить к нему клавиатуру, у всех этих систем, как правило, невозможно выбрать ОС по своему вкусу. Что производитель поставил, то и используется.
3)Специфичные рабочие станции для рендеринга, обсчета данных или проектирования микросхем, суперкомпьютеры и так далее. Часть из этого можно использовать как десктоп, но из-за требований к рабочему окружению, возможность выбора ОС на них так же ограничена.
Данные по процентному соотношению разных ОС взяты отсюда. Если у кого-то есть статистика по годам на протяжении десятка лет, покажите, будет интересно посмотреть на долговременные тенденции.
Так в чем же дело? Почему несмотря на все старания, Linux, который стал стандартом де-факто на встраиваемых устройствах, работает на подавляющем большинстве серверов, целиком захватил рынок суперкомпьютеров, Linux, над которым работают сотни компаний и десятки тысяч людей... практически не используется на обычных компьютерах и ноутбуках?
Причины этой ситуации, как ни странно, те же, что сыграли роль в популярности Linux на серверах: unix-way, "Философия Unix": "Пишите программы, которые делают что-то одно, и делают это хорошо, и имеют возможность получать и принимать данные через текстовый интерфейс (потому что он универсален)".
Это очень хорошее решение, когда у вас нет:
Быстрого постоянного интернета
Stackoverflow
Github
Высокоуровневых простых языков типа Python
Кучи фреймворков и библиотек для этих языков в легком доступе
Но есть желание делать свою работу, компьютер и ОС с базовыми инструментами (т.е. ситуация 90-х или 2000-х). Если вы специалист, который может понять некоторые абстрактные концепции, готов писать скрипты-связки, и не требует кнопочки "сделать все хорошо".
Базовое окружение хорошего качества, которое можно комбинировать как угодно, универсальное, бесплатное, переносимое и дописываемое (если уж совсем не хватает фичи или обнаружен баг) — это серьезный шаг по сравнению с поставкой первых ЭВМ, где зачастую-то компилятора нормального не было, или с другими ОС того времени, где приходилось пользоваться, чем дают, да еще и платить за это деньги.
В таких условиях проявляются все преимущества, так странно звучащие в наше время: "я могу просмотреть код любой программы, я могу исправить баг или дописать фичу и отправить в мейнстрим".
Звучат эти аргументы странно потому, что они наследие золотой эпохи опенсорса, когда отдельные утилиты были написаны на одном стандартном для всей кодовой базы языке, были маленькие, потому что делали одну функцию, и сопровождались одним человеком, которому можно было написать письмо. Весьма приятная ситуация, если вы тоже подобный специалист.
Сейчас, когда код программы — это десятки мегабайт текста (и далеко не все из него непосредственно код, там может быть 2мб XML-а) и огромное количество библиотек, когда сборка — отдельное приключение, когда кодовая база пишется десятком человек, ни один обычный пользователь не будет в здравом уме просматривать весь код или пытаться исправить ошибку в чем-нибудь, типа OpenOffice, GIMP-а, KDE или Chrome.
Все исходники прочитать очень сложно, а вероятность найти там ошибку или закладку, просто просматривая код, стремится к нулю: простые места проверили до вас, а в сложных способны разобраться только профессионалы и авторы статических анализаторов :).
Поиск места, в котором засел баг, который вам мешает (даже если вы можете его воспроизвести), если вы обычный пользователь — гиблое дело: отладка больших программ со зрелой кодовой базой (читай "легаси") это отдельное занятие, которому надо учиться, и даже в чем-то искусство.
Произошло это потому, что за 30-50 лет ситуация изменилась. Железо стало более доступным, возникло такое понятие как десктоп, он же "персональный компьютер", и за ними начали массово работать обычные люди, не являющиеся специалистами ни в IT, ни в программировании.
И в этой новой ситуации, достоинство Linux начинает превращаться в недостаток
Для того, чтобы понять, как именно оно становится недостатком, надо немного поговорить о том, как вообще происходит развитие продуктов на долговременном периоде.
В процессе развития IT-отрасли мы непрерывно размениваем ресурсы на пользовательский охват: именно этим объясняются страдания людей на тему "почему процессоры в 10 раз быстрее, а скорость работы текстового редактора такая же". Скорость работы такая же, потому что "выгоднее" увеличить покрытие людей инструментом, чем улучшать пользовательский опыт уже покрытых. Вы этого не видите, потому что для вас, как для уже существующего пользователя, долетают только отголоски этого процесса: новые фичи, переделанный интерфейс, и так далее. А при взгляде со стороны разработчиков — новый интерфейс это более удобная пользовательская навигация -> простое освоение инструмента -> меньший процент отказов -> бОльшая пользовательская база -> больше денег и ресурсов на разработку.
И это ситуация, от которой никуда не деться: если ваш сосед играет грязно, то без внешнего регуляционного механизма (которым может выступать государство, например), и вам придется играть грязно, иначе вы не сможете с ним конкурировать.
Если ваш конкурент меняет ресурсы на пользовательскую базу, то вам либо надо делать так же, либо смириться с тем, что ваш конкурент вырастет, а вы нет.
Но человеку, знакомому с современным десктопным линуксом ясно, что его разработчики, в принципе, не прочь поменять ресурсы на пользовательский охват: ни один из основных дистрибутивов не пытается остаться в состоянии голого терминала, все они предлагают графические оболочки, конфигураторы, инсталляторы, новые программы управления, и так далее.
Таким образом, не является проблемой ни отсутствие ресурсов (например, веб-приложения постоянно топчутся около самой этой черты, и их разработчики гарантируют нормальную работу своих приложений только на достаточно производительном железе и последних версиях браузеров), ни нежелание разработчиков идти по стандартному пути увеличения пользовательской базы. Как минимум, не основной проблемой.
Так в чем же дело?
Проблема лежит не в плоскости разработки, а в плоскости менеджмента
Процесс развития IT-отрасли не просто привлекает новых пользователей. Он привлекает неподготовленных пользователей. Те рассказы о том, как технарь слету разбирается в интерфейсе телевизора, и на вопрос "ой, у вас наверное дома такой же" отвечает "нет, я его впервые вижу" — это не демонстрация высокого интеллекта этого технаря, это демонстрация знания принципов, по которым строятся почти все интерфейсы. Когда за десяток последних лет вы используете интерфейсы iOS, Android, Symbian, Windows, Linux, двух фотоаппаратов, трех телевизоров, кассетного магнитофона с программируемой записью, факса, копировального аппарата, настенного пульта для кондиционера, MP3-плеера и vi, то у вас появляется насмотренность — вы знаете, как спроектированы большинство в мире интерфейсов, хоть и не можете формализовать это знание в виде четких инструкций, но можете использовать. Например, быстро найти нужный пункт в меню, которое видите впервые.
Но те пользователи, которые приходят в IT сейчас — у них всего этого нет.
У них нет необходимости придумывать пути решения задач — большая часть их работы превращается из творческой в алгоритмическую, когда специалиста учат цепочкам действий, необходимым для работы, а не умению создавать эти цепочки. Потому что дешевле, быстрее, и тоже вполне работает.
У них нет желания и необходимости сортировать файлы по папкам: для них уже сделано облако, отдельное для каждого приложения. И там зачастую не файлы, а абстрактные "проекты".
У них нет страха потери всего: их данные хранятся не на их жестком, и это не совсем их данные, будем честны.
У них нет необходимости разбираться с десятком интерфейсов, они могут вырасти до сознательного возраста, не видя интерфейса кроме айфона и десятка приложений на нем для настройки кондиционера, светильника и вибратора.
Именно для них создаются такие интерфейсы, как, например, Fluent (ribbon) в MS Office: он непривычный, и возможно, менее удобный для тех, кто привык к старому меню, и умеет им пользоваться, но он определенно снижает порог входа для тех, кто еще не умеет.
Время, когда отраслью безраздельно владели гики, закончилось
Это время было возможно потому, что только гики имели достаточную настойчивость, чтобы добраться до дефицитного железа и разобраться в текстовых интерфейсах, написанных такими же гиками. Сейчас борьба за пользователя происходит на другом уровне: компьютеры и телефоны доступны всем.
И если вы хотите, чтобы вашим приложением пользовалось максимальное количество людей, вам придется ориентироваться на всех: от ребенка во втором классе с андроидом за 5000, и 16-летней девушки с айфоном в розовом чехле, до 55-летней дамы, которой внук подарил ноутбук на юбилей. И общего у них будет только одно: они представляют собой просто квинтэссенцию не-гиковости.
Для того, чтобы они могли пользоваться вашим продуктом, вам необходимо понять, как мыслит ваш средний пользователь, придумать и протестировать интерфейс, функциональность, фичи и пользовательские пути так, чтобы пользователю было как можно более удобно (или, если переформулировать, чтобы покрыть максимальное количество пользователей: на достаточно больших числах это одно и то же).
Этот процесс начался не сейчас, и даже не десять лет назад: уже в 1992 году (почти 30 лет назад!) в Microsoft были специальные отделы, которые проектировали интерфейсы новой системы. И не просто проектировали, а проводили, как сейчас модно это называть, кастдев — интервью с живыми пользователями с проверкой гипотез на прототипах.
Сейчас фокус исследований сместился с того, как именно пользователь будет взаимодействовать с интерфейсом на то, каким путем он будет решать свои проблемы: базовые элементы интерфейса известны, нарисованы в дизайн-гайдах, SDK, фреймворках, и что гораздо более важно, уже запомнены пользователями, поэтому придумывать их не надо, а изменять следует только если у вас есть веская причина.
Сейчас исследования юзабилити концентрируются на другом: сложность логики и пользовательских путей, которые выводятся на уровень пользователя, увеличивается, и интерфейсы необходимо изменять так, чтобы эта сложность была доступной для пользователей.
Если десяток лет назад интерфейс выбора билетов представлял собой текстовые формы с сокращениями в окне терминала, для работы с которым существовали специальные люди в агентствах, к которым надо было прийти ногами, и они превращали ваши запросы в команды системе, то сейчас произошла серьезная трансформация — процесс подбора рейса не потерял в комбинаторной сложности (рейсов и параметров не стало меньше), но очень уменьшился в интерфейсной сложности: сайты вроде aviasales/tutu/skyscanner создали интерфейс настолько дружелюбный к пользователю, настолько заботливо обмазанный подсказками, предложениями, основанными на обычных запросах пользователей, что для их успешного использования гораздо важнее принципиальное знание "да, так можно купить билет, в этом нет ничего страшного" и согласие это так делать, чем умение пользоваться конкретным интерфейсом.
Именно поэтому главное достоинство Linux — комбинационность и расширяемость, столь любимая гиками, — становится главной проблемой. У нас есть миллионы комбинаций инструментов в системе, но это слишком сложно для обычного пользователя, он хочет десятки и сотни путей. Но для того, чтобы понять, какие именно из миллионов путей надо сделать доступными и простыми для пользователя, надо сфокусироваться на пользовательском опыте, надо работать с новыми пользователями и пытаться понять, как они будут использовать новый интерфейс. В этой части принципиально не могут участвовать разработчики и даже просто существующие пользователи — проклятье знания не дает им возможности непредвзято судить о качестве нового интерфейса: существующий всегда будет лучше и привычнее.
Из этого следует два вывода: во-первых, для ориентации на не-гиков нужны интервью с не-гиками, а не просто идеи разработчиков о том, как "сделать лучше", а во-вторых, интересы пользователей необходимо ставить выше интересов разработчиков: мало кому нравится выбрасывать существующие наработки и делать кучу скучной работы по упрощению пользовательского пути, который самому разработчику вовсе не кажется сложным, но это придется делать.
Именно интересы разработчиков, которые ставятся выше интересов пользователей — это и есть бич Linux
Происходит это потому, что линукс разрабатывается и поддерживается разработчиками, а прочие роли (продакты, аналитики, маркетологи, дизайнеры, UI/UX, редакторы) там присутствуют только по случайности, если они каким-то образом оказались в одном человеке с этим разработчиком (или партнером этого человека).
В традиционной разработке пользовательского ПО, где так или иначе присутствует бизнес, есть четкое понимание, что пользователь = деньги. Возможно не сейчас, возможно в будущем, возможно, он заплатит не напрямую через подписку или покупку, а через рекламу, или вообще деньги придут от инвестора (но будут рассчитаны из количества потенциально-платежных пользователей). В корпоративной (B2B, B2B2C, B2G) разработке может быть по-другому, и деньги могут формироваться даже из того, настолько хорошо ваш продажник дружит с ЛПР другой компании, но в коммерческой B2C разработке деньги приносит пользователь, и удовлетворенность ЦА пользователей это то, что конвертируется в размер аудитории, а значит и в деньги.
В OpenSource-разработке десктопного линукса не то, чтобы нет денег... Они есть: разнообразные гранты, пожертвования, платная поддержка, выделение свободного процента времени сотрудников компанией, оплата разработки кода через коммиты в опенсорс от компаний или просто выкладывание всего инструмента в опенсорс, программы господдержки национальных ОС, в конце-концов. Но там нет бизнеса: как правило, ни одна из этих форм оплаты не принимает в качестве метрики успеха количество удовлетворенных или даже просто пользующихся продуктом пользователей.
А без интересов бизнеса в отношении пользователей нет возможности продвигать решения, неинтересные для разработчиков: сама разработка (написание кода, тестирование, документация) и запиливание новых фич занимает едва ли 30-40% в разработке продукта. Остальное занимает: предварительная аналитика существующих продуктов и рынка, разработка унифицированных и документированных интерфейсов (в случае GUI это соглашения об одинаковых паттернах использования элементов, в случае API это единообразность и логичность методов и формата данных), высокоуровневая документация, которая описывает принципы, по которым строится работа с продуктом ("все есть файл" — это именно такой принцип, например), изучение пользовательских задач и путей (не доступная пользователю функциональность, а то, как и для чего он ее будет использовать: например, подход к tar с этой точки зрения заставил бы добавить ключи --archive и --unarchive), логика миграции между разными версиями, механики проброса низкоуровневых ошибок на уровень пользователя, и так далее.
Но для всего этого, как правило, необходимо подняться на уровень выше, начать рассматривать комбинацию инструментов как систему, которая представляет собой нечто большее, чем сумму входящих в нее частей.
Но это противоречит философии Unix: зона ответственности разработчика кончается на том, что он делает функциональную программу с унифицированным вводом-выводом.
О том, насколько интерфейсы этой программы совпадают с другими программами (насколько ключ -v одинаково работает у всех консольных утилит, например: --v/-vv/-v 1 и так далее), он уже не заботится: в данный момент ему удобнее принять решение о создании интерфейса по своему вкусу (никто не регламентирует создание нового интерфейса), а в дальнейшем не существует механизма вывода успешных решений на уровень составного продукта. Создав новое удачное интерфейсное решение в опенсорсе, вы оказываетесь меж двух зол: либо применить его у себя, и тем самым, нарушив хоть призрачный, но паттерн проектирования, либо забыть об этом удачном решении, и поддержать бездействием устаревшие концепции девяностых годов, созданные в других условиях и для другого поколения пользователей. Сделать так, что это удачное решение сможет попасть в другие продукты, которые разрабатываются рядом с вами, почти невозможно. Отчасти за это отвечает обратная совместимость, но это не единственный механизм: с болью и возмущениями python смог перейти на третью версию, значит, это вполне возможно.
Примеры? Да сколько угодно.
Проблема #1: отсутствие изоляции программ
Традиционный Windows-путь — это хранение данных в папке пользователя, а настроек программы в папке с программой. Нужные программе библиотеки, за исключением системных и всяких .Net Framework, хранятся в той же папке. То, что windows довольно долго была де-факто однопользовательской ОС, наложило свой отпечаток в виде того, что не было ничего страшного в том, чтобы хранить настройки вместе с кодом и библиотеками: все равно это настройки конкретного пользователя. А если ему очень нужны другие настройки, то он может сделать копию папки.
Был еще вариант хранить свои настройки в реестре, но это штука, которая убивает плюс миграции, не принося ничего взамен, кроме некоторого упрощения логики записи-чтения настроек.
Сейчас Windows приходит к модели разделения пользователей друг от друга и от системных данных, поэтому современные программы теряют права на запись в свою папку с исполняемыми файлами и библиотеками совсем, а настройки предлагается хранить в глубинах домашней директории пользователя (как в Linux, см. ниже).
Традиционный Linux-путь (ну, точнее, *nix-путь) — это хранение настроек и данных в домашней папке пользователя (отличный задел), а библиотек программы — размазанных тонким слоем по системе. Так сложилось исторически, потому что *nix системы представляли собой многопользовательские системы, запущенные на едином "сервере", к которым пользователи подключались с помощью "тонких клиентов" (очень тонких) — в минимальном варианте это был принтер и клавиатура, что и определило текстово-консольный интерфейс как основной, заложив основы того, что позволило Linux занять свое текущее положение на серверах. Со временем "очень тонкий клиент" превратился в монитор, к которому подключался либо знакогенератор, либо упрощенный компьютер. Это, в свою очередь, привело к тому, что графический интерфейс оказался разделен на серверную и клиентскую части, что доставило (и продолжает доставлять) немало проблем в условиях, когда в таком разделении нужда отпала. Из-за множества пользователей логичным решением было экономить место на жестком диске, жестко отделяя исполняемые файлы от данных, и как логичный следующий шаг — экономить место среди исполняемых файлов, разделяя выделенную логику конкретного приложения и библиотеки, которые могут использоваться не только этим приложением. Это почти не давало выигрыша в ранних однопользовательских системах (все равно приходилось хранить как минимум одну копию исполняемых файлов и библиотек к ним), но ощутимо экономило место для многопользовательских систем.
Но в современном мире ситуация изменилась.
Во-первых, резко возросло количество библиотек, пакетов, и их зависимостей, вырос темп разработки, а место на жестком диске очень сильно упало в цене.
Во-вторых, современные системы — однопользовательские. Ну, в худшем случае, двух- или трех-пользовательские: стоимость железа такова, что не проблема купить каждому пользователю по компьютеру или даже по высокопроизводительной рабочей станции (она все равно не будет стоить больше пары зарплат специалиста). А если ресурсов ее не хватит — с развитием интернета к вашим услугам огромное количество облачных серверов: стоимость и развитие аппаратных ресурсов, позволяет переносить многопользовательность в область виртуальных машин: накладные расходы на это небольшие, их с лихвой окупает изоляция и возможность кастомизации каждой виртуальной машины.
В тех применениях, где присутствует все-таки множество пользователей (например, в веб-сервисах), их количество настолько большое, а спектр запросов настолько мал (я имею ввиду функциональность одного сервиса по сравнению со всеми комбинациями инструментов в *nix), что нет никакого смысла отдавать им настоящую системную многопользовательность со всеми ее возможностями и недостатками, гораздо проще написать свою, маленькую и карманную, сделав это выше системного уровня, на пользовательском уровне ОС: когда база данных одна, логика приложения одна, веб-сервер один, все это работает от одного или от 2-3 пользователей ОС, но внутри они разделяют между собой тысячи аккаунтов клиентов.
Из всего этого можно сделать вывод, что современная многопользовательность на уровне ОС — это фишка на 50% для удобства разделения пользователей и их данных в рамках одного компьютера, и на 50% для безопасности. Разделение пользователей пригождается, если у вас все-таки один домашний компьютер, а для безопасности хорошо, когда процесс веб-сервера не может читать данные процесса базы данных, и оба они не могут переписать системные файлы.
По факту, современные системы — однопользовательские. Это не означает, что от многозадачности надо избавиться, но означает, что практически не встречается ситуации, когда у нас в одном пространстве ОС существуют множество пользователей, использующих одни и те же программы и библиотеки, чтобы их "схлопывание" серьезно экономило деньги, затрачиваемые на хранение их в памяти.
Однако, софт в Linux до сих пор использует концепцию разделяемых библиотек, отчасти "потому что так сложилось", отчасти по причине плюсов, связанных с безопасностью: ошибка, допущенная в ssl-библиотеке может создать уязвимость в десятке приложений, ее использующих. В случае разделяемых библиотек достаточно будет обновить пакет библиотеки, и при условии неизменности ABI библиотеки, все остальные приложения сразу же исправят уязвимость без каких-либо действий авторов и мейнтейнеров.
Альтернатива — это пакетирование программ в самодостаточные сборки, со всеми (или большинством) зависимостей. Вариантов много — Application Bundles / AppImage / Snappy (Ubuntu) / Flatpack (Gnome), но они тоже имеют недостатки и критику.
Однако и текущая реализация механизма разделяемых библиотек и установки пакетов с зависимостями — это далеко не совершенная конструкция, которая на задачах чуть сложнее стандартных легко скатывается в dependency hell, что тут же на порядок повышает сложность обслуживания системы: там где в Windows надо просто переустановить программу, в Linux приходится ковыряться в глубине пакетного менеджера. Причем получить ситуацию ада зависимостей можно достаточно легко — при попытке поставить новую версию ПО, которая требует новой версии библиотеки, которая несовместима с существующим ПО, погуглить, как установить вторую версию библиотеки, ввести пару команд с SO... Все, apt-get невнятно ругается, не предлагая никаких осмысленных действий. В связи с отсутствием механизма миграции (см. следующий пункт) альтернатива "снести все и поставить заново" превращается в долгий и нудный перенос данных и настроек — тоже плохой вариант.
У меня нет готовой идеи, как решить этот вопрос: у обоих подходов есть минусы, и есть плюсы, даже если не принимать во внимание призрачную экономию места. Однако проблема абсолютно точно есть, но без четкого понимания, кто будет за ее решение платить, двигаться ситуация никуда не будет. И кстати, мнения что динамическая линковка это не всегда хорошо, придерживаюсь не только я.
В качестве рабочего примера можно посмотреть на Docker. Так как он работает в сегменте серверного Linux, то там есть интересы бизнеса (в стоимости ресурсов, поддержки, обновлений, обслуживания, раскатки и т.д.), который видит решение проблемы и из-за этого голосуют за использование и разработку докера, даже несмотря на ощутимый оверхед по ресурсам.
Это происходит из-за того, что основной плюс докера вовсе не в быстрой раскатке и обновлении приложений — этого можно было бы добиться и с Ansible, например.
Сила докера — в самодостаточности образа (все нужное окружение он несет в себе, и при правильном проектировании образа есть хорошая гарантия, что он запустится где угодно) и принудительности хранения данных и настроек отдельно от кода (так как образы докера эфемерны и легко удаляются и создаются заново при обновлении или новом деплое, и для юзера, де-факто, неизменны, а значит, заставляют хранить данные в другом месте).
Всем этим докер сводит логический модуль к черному ящику: дай ему ресурсы (память, хранилище, процессор, сеть), укажи место хранения настроек и данных через унифицированный механизм ФС (хоть что-то у нас есть унифицированного), и дальше он будет работать сам. Сломался код? Надо мигрировать на новую версию? Образ убивается, собирается новый, запускается с теми же параметрами, и опа, все работает как и прежде.
Я говорю о логических модулях, потому что изолируются именно куски логики (бизнес-логики, если угодно), а не отдельные программы: контейнер может включать в себя, например, два сервиса на разных языках программирования (или на языках разных версий), сами языки программирования, их зависимости и библиотеки, логику обслуживания при падении, централизованный клиент сбора логов, мониторинг, локальную временную БД, и так далее. И у десяти разных контейнеров это не размазывается тонким слоем по системе, начиная интерферировать друг с другом, а работает изолированно и обособленно друг от друга, непринужденно убивается, сносится и ставится заново, никак не ломая хост-систему и друг друга.
И именно поэтому, несмотря на ситуацию, когда образ с единицей логики в 5мб весит 500мб, потому что тащит за собой копию потрохов системы, такая концепция настолько упрощает работу, что "на ура" принимается бизнесом.
И что интересно, этот подход вовсе не имеет таких глобальных проблем с безопасностью, как можно было бы ожидать от пакетирования программ: так как образы у нас состоят из слоев, их можно обновлять, по сути, независимо друг от друга (на самом деле, нет, они накатываются заново, но для конечного пользователя отличия только во времени обновления), поэтому исправление уязвимости в стандартной библиотеке в слое базовой системы автоматически применяется ко всем работающим приложениям, не требуя внимания создателей слоя конечного приложения. Нечто подобное можно было бы реализовать и для установки программ для десктопного линукса.
Проблема #2: сложность миграции с версии на версию
Во время многопользовательности линукса настройки были разделены на два места: настройки пользовательских программ и настройки общесистемных программ. Пользовательские настройки лежали в /home/user/.config, а системные, которые применяются к программам, запущенным не от пользователя или используемыми всеми пользователями — в /etc.
Но в процессе превращения в де-факто однопользовательскую систему эта стройная логика была разрушена.
Например, xorg/x11 — в текущей реальности это программа пользовательского уровня: настройки в ней настраивают конкретную видеокарту и конкретный монитор пользователя. Второй может пользоваться консолью, третий ходить исключительно по ssh. Но файл настроек лежит в /etc (и хорошо если не в /usr/share/X11), и он одинаков для всех.
apt-get — тоже программа пользовательского уровня. У каждого пользователя могут быть свои репозитории, и негоже пытаться установить python-4-alpha-dev всем пользователям только потому, что для одного из них это обычная среда. Но конфиги и репозитории лежат в /etc. apt-get, кстати, запускается тоже только от root.
Ладно, фиг с ними, с репозиториями. Но вот список установленного софта — уж точно пользовательская штука, правда? Я на каждый компьютер ставлю определенный список программ, и если уж у нас есть рабочая система с репозиториями, которая снимает необходимость качать и ставить софт вручную, давайте же упростим задачу установки любимых программ на новую систему. Как мне получить список установленных мной пакетов?.. Никак. Не существует нормального механизма, который бы показал, что именно вы устанавливали (есть вот такие неофициальные решения, которые могут сломаться в любой момент), и не предполагается никакого метода хранения этого списка вместе с пользовательскими настройками.
Ладно установленные программы, раз они шарятся между юзерами, то может и правда логичнее ставить их всем, не разбираясь. Но вот запускаемые программы-то — это собственность пользователя, правда же? Ну, я поставил мускуль, коллега постгри. Каждый из-под своего аккаунта. При старте запустятся оба, если не сделать сложных телодвижений по поводу запуска из скриптов оболочки. Какая там многопользовательность, о чем вы. Я понимаю, что на это есть причины, и даже знаю, какие. Но эти причины не отменяют то, что список программ, которые при запуске нужны мне, как конкретному юзеру, лежат в /etc.
Что у нас там еще из пользовательских программ? reboot. Пользователь же может перезагрузить компьютер, правда? Это же его компьютер? Нет, не может? Нужен root? Блин.
openvpn, ppp — тоже же пользовательские штуки. Зачем другому пользователю мой корпоративный vpn и зачем для его добавления себе нужен root? Но лежат в /etc.
Ладно. Как я уже говорил, я установил себе БД для работы. База запускается от своего пользователя, mysql:mysql какой-нибудь. Настройки лежат... Наверное в /home/mysql/.config/mysql? Нет не угадали. Тоже в /etc! Почему? А вот. Ладно. БД хранит данные где-то на диске. Где они хранятся, в /home/mysql/data? Нет. В /var/lib/mysql. Ну йооооханный.
Особенно весело, когда вам и вашему коллеге надо будет поставить две одинаковых БД с чуть разной версией. Опытный админ пошлет вас на х.. запускать виртуалку или ставить в докер, и будет прав.
В общем, тут надо или крестик снять, или трусы надеть: или перестать делать вид, что система многопользовательская и начать концентрировать конфиги в одном глобальном месте, либо сделать систему действительно разделяемой многопользовательской, в которой у каждого пользователя свое окружение и свои конфиги.
Ситуацию осложняет то, что программам предоставлена полная свобода: кто где хочет, тот там и хранит данные/бинарники/настройки, кто хочет, тот от такого юзера и запускается. Система, вместо того, чтобы ограничить программы и дать им выбранное системой место для хранения (она же тут главная, она организует место, она выделяет ресурсы, она изолирует программы, она следит за тем, чтобы все получили свою долю тиков), в этом месте расслабляется и "ну вы там как-нибудь разберитесь сами, сделайте как деды завещали". Пацифизм губит ухоженные сады, вот это все. Оно ведь не только про общение, а про любые разделяемые ресурсы в условиях множества независимых агентов.
Что в итоге? А в итоге, миграция на новую систему — адский геморрой: скопировать свою папку недостаточно, часть файлов надо вытащить из /etc, но все копировать нельзя, потому что это сломает новую инсталляцию, часть файлов собрать по системе, никогда не знаешь, на что наткнешься в следующий раз, список пакетов получаешь с трудом (о существовании возможности это сделать кроме как через history|grep install я узнал только при написании этой статьи, хотя опыта с линуксами с полтора десятка лет).
Несмотря на то, что официальный способ конфигурирования — через текстовые конфиги, никто не реализовал способ сравнения конфигов (неважно, через diff или через layers ФС), чтобы иметь хотя бы представление "а что я там в конфиге в прошлый раз правил", чтобы отделить свои правки от системного стока. Вот в гите такое есть, потому что это требование бизнеса в виде разработки, а в ОС.. И так норм, мы привыкли.
В винде таскается пользовательская папка, папка с инсталляторами программ. Системные настройки приходится настраивать заново (но можно выборочно экcпортировать в .reg, благо, от версии к версии их место не особо меняется). Не идеал, но жить можно.
В макоси творится магия: мало того, что программы пакетированы, и переносятся копированием файлов за некоторым исключением, так еще и все настройки таки хранятся в папке пользователя. Как будто этого недостаточно, еще и есть встроенный инструмент, который при переходе на новое железо с новой системой корректно все переносит по нажатию трех кнопок. Все файлы пользователя, все настройки, весь софт, и остается сделать пару мелочей: дать разрешение программам, установить console tools и тому подобное.
В серверном линуксе это решается с помощью ansible, который хранит все настройки и действия по приведению чистой системы в рабочее состояние, или с помощью докера, который хранит данные и конфиги в определенных на стадии запуска контейнеров местах, а процесс развертывания бинарников и сопутствующего — в докер-файлах. Но это требует некоторой культуры и необходимости разворачивать все заново при изменениях в конфиге.
Десктопный линукс... десктопный линукс сидит и ест клей.
Проблема #3: отсутствие единого конфигуратора
Эта проблема отчасти пересекается с прошлой, но она, тем не менее, отдельна: множество мест хранения настроек мешают не только миграции, но и настройке системы.
Например, настройка скринсейвера и вообще выключения экрана.
В макоси — один ползунок. В винде — два разных места, в одном ползунок, во втором, через интерфейс пятнадцатилетней давности можно настроить более точно.
В андроиде — не помню точно, везде ли можно отключить это совсем, но тоже обычная менюшка.
В iOS — в менюшке.
В линуксе... ну, в интерфейсе вы можете отключить скринсейвер. Но это не означает, что экран не будет выключаться. Функция "отключить скринсейвер" отключает скринсейвер, программу-делающую-красивые-картинки. Локскрин, отключение экрана для экономии энергии, и так далее, она не отключает.
Кроме того, настройки отключения экрана для консоли и иксов — в разных местах. В общем, если вы погуглите "как отключить скринсейвер и отключение экрана в линукс", то соберете вот такую библиотеку разных вариантов уже с первой страницы гугла:
"consoleblank=0" >> /sys/module/kernel/parameters/consoleblank
"setterm -blank 0" >> /etc/rc.local
"setterm -blank" >> /etc/init.d/boot.local
"sleep 10 && xset s 0 0 && xset s off && exit 0" > autostart.sh
"xset s off" >> .xsession
'setterm -blank 0 -powersave off -powerdown 0' >> ~/.xinitrc
DISPLAY=:0.0 xset s activate
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash consoleblank=0"
Option "DPMS" "false" > xorg.conf
TERM=linux setterm -blank 0 -powerdown 0 -powersave off >/dev/tty0 </dev/tty0
apt-get remove xscreensaver
echo -ne "\033[9;0]" >> /etc/issue
gconftool --type int -s /apps/gnome-power-manager/backlight/idle_dim_time ***time***
gconftool-2 --direct --config-source xml:readwrite:/etc/gconf/gconf.xml.defaults --set -t boolean /apps/gnome-screensaver/idle_activation_enabled false
gconftool-2 --set -t boolean /apps/gnome-screensaver/idle_activation_enabled false
gnome-screensaver-command -d
gsettings set org.gnome.desktop.lockdown disable-lock-screen 'true'
gsettings set org.gnome.desktop.session idle-delay 0
gsettings set org.gnome.settings-daemon.plugins.power active false
remove @xscreensaver -no-splash from ~/.config/lxsession/LXDE/autostart
setterm -blank 0 -powerdown 0
setterm -blank 0 -powersave off
systemd-inhibit sleep 2h
xset s 0 0 &
xset s noblank
xset s off && xset -dpmsГотовы сказать, какие из них будут работать, а какие нет? Какая-то команда меняет поведение сразу, другая команда записывает это в автозапуск, третья пытается что-то конфигурировать центрально...
Из-за отсутствия единого центра настроек, даже такой простой вопрос "а как мне выключить вообще любое отключение экрана" требует как минимум нескольких часов работы довольно дорогостоящего специалиста.
И такое — с почти всеми нетривиальными настройками системы. Разрешение монитора не определяется нормально? Добро пожаловать в волшебный мир конфигурационных файлов иксов (или wayland, если вам "повезло". Повезло в кавычках — потому что документов по конфигурированию wayland-а еще меньше). Хотите повернуть экран? Выбирайте:
gsettings set org.gnome.settings-daemon.plugins.orientation active false
xrandr -o normal
xrandr --output HDMI1 --rotate left
xrandr --output LVDS1 --rotate left
xrandr --output $(xrandr |grep eDP|cut -d" " -f1) --rotate left
xrandr --output LCD --auto
"[output] \n name=HDMI-A-1 \n transform=90" >> weston.ini
"display_rotate=1" >> /boot/config.txt
"video=DSI-1:800x480@60,rotate=0" >> /boot/cmdline.txt
snap set pi-config.display-rotate=2
snap set pi-config.lcd-rotate=2
"lcd_rotate=2" >> /boot/config.txt
"display_hdmi_rotate=2 " >> /boot/config.txt
"display_lcd_rotate=2" >> /boot/config.txtНу, вы поняли. В зависимости от того, хотите вы повернуть экран вообще, на уровне драйвера HDMI, или немножко, на уровне иксов, хотите вы его переворачивать в процессе работы или один раз, в зависимости от того, в какой из портов на видеокарте у вас подключен монитор, в зависимости от того, ноутбук у вас или десктоп, в зависимости от того, малина у вас или x86, в зависимости от того, NVIDIA/AMD/Intel у вас видеокарта, вам нужны разные команды.
Часть команд, которые вы найдете в интернете, безобразно устарела. Часть — от других операционных систем и других рабочих сред. Часть — настраивают не то.
И такая штука — со всеми нетривиальными настройкам. Я могу понять, когда мне надо искать тонкости настройки пересборки ядра для включения туда какого-то модуля: нет смысла выносить это в интерфейс, потому что эта функция нужна очень редко и не нужна обычным пользователям, нет смысла включать ее в юзерспейс.
Но уж команды отключения скринсейвера, настройка мониторов, разрешения, поворота — явно юзерспейс. И куча прочих таких штук, которые настраиваются в конфигах, и не просто в конфигах, а в непонятных местах, которые можно найти только методом перебора и тестов.
Когда вы берете консольный Debian, ставите туда хорг, потом ставите свое любимое окружение, это понятно. Вы собрали конструктор, это не поставляется вместе. Когда вы берете убунту, которая поставляется в виде продукта, там должен быть нормальный конфигуратор основных функций системы, или это какой-то так себе продукт. Как этот конфигуратор будет реализован — через переработку всех интерфейсов или через генерацию конфигов для разных программ из единого файла конфигурации, не суть важно.
Кстати, единый файл конфигурации в стабильном формате — это замечательная идея для решения предыдущего пункта про миграцию. Неважно, какие там конфиги лежат внизу, где они лежат, и как они изменились с прошлой версии системы. Важно то, что новая система способна распарсить файл конфигурации с прошлой системы и на базе него создать эти полтора десятка конфигов.
Проблема #4: рассинхронизация интерфейсов общения с пользователем
Вот например, довольно обычная ситуация для любой системы: запускаемая программа не запустилась, а упала, например, не найдя библиотеку или файл конфигурации. Для Windows базовым интерфейсом взаимодействия является графический, поэтому ошибка будет выдана в виде системного диалога.
Для Linux базовый интерфейс это текстово-терминальный, поэтому ошибка будет выдана текстом в терминале. ...если, конечно, вы запускаете программу из терминала. Если вы запускаете ее из GUI, то ошибку программы можно найти: а)в ее собственном логе, б)в системном логе в)нигде, потому что несохраненный в терминальной сессии вывод stdout/stderr нигде более не сохраняется. Для решения этой проблемы надо иметь договоренность о том, что при завершении программы с кодом ошибки надо показать пользователю сообщение об ошибке, и это сообщение не должно составлять собой содержимое stderr, а быть кратким, в одну строку, и действительно описывать место, где произошла ошибка.
У Windows это есть, хоть иногда и встречается невнятное "Память не может быть read" и "Error 0x000000F2DA563333".
У MacOS это реализовано хуже: ошибки в программе скорее всего выведутся, а вот некоторые программы могут падать при запуске, ничего не говоря
В Linux нормальна ситуация, когда ты нажимаешь кнопку в интерфейсе, она не нажимается, и ничего не говорит. И только в консольном выводе можно увидеть ошибку библиотеки фреймворка, которая говорит, что undefined какой-то аргумент объекта кнопки.
В итоге, даже просто желание погуглить ошибку при работе GUI программы зачастую превращается в увлекательный квест. С консольными программами тоже есть приколы — в целом, пользователь не знает, куда складывает лог конкретная программа: это может быть свой лог в соседнем файлике или текущей папке, это может быть /var/log/program_name, это может быть какой-то общесистемный журнал или журнал конкретного метода автозапуска программы.
Проблема #5: непроработанность функциональности ПО и неконсистентность инструментов
Это уже последствия отсутствия продуктового подхода: разработчики рассматривают программу как некий интерфейс, в котором есть объекты, которые вызывают функции. Нажимаем кнопочку — выполняется команда. Так же, как в консоли, набрали команду, нажали ввод, команда выполнилась, только вместо команды — кнопка в интерфейсе.
О том, как пользователь пользуется всей программой в целом — не задумываются. Условно, если мы сначала копируем один обьект, а потом в 99% его вставляем рядом, хорошо бы не закрывать меню с кнопками "копировать" и "вставить", это меньше движения курсора, меньше кликов. А еще хорошо бы сделать кнопку "дублировать". Это самый простой синтетический пример.
Реальные проблемы сложнее и включают в себя множество действий, которые часто выполнятся друг за другом в рамках одной пользовательской сессии, и которые хорошо бы сворачивать для упрощения работы. Или действия, которые выполняются наоборот, очень редко, и каждый раз вызывают недоумение у пользователя, потому что он успевает забыть, как именно это делается. Такие действия наоборот, можно разбивать на несколько более простых шагов, чтобы упростить пользовательский путь: логическую цепочку запомнить проще, чем магическую кнопку, спрятанную в недрах меню. А если она не спрятана в меню — все еще хуже, потому что ненужные и неиспользуемые функции загромождают меню, и не дают вынести в него то, что нужно на самом деле.
Но для этого надо понять, что именно делают пользователи, и как они это делают. У разработчика может не быть проблем — он, в конце-концов, сам проектировал этот интерфейс, и он точно сделан идеально под него. У опытных пользователей тоже может не быть проблем: они уже привыкли и ощущение "блин, ничерта непонятно" у них уже давно в прошлом (как пользователь Blender и Eagle заявляю, что привыкнуть можно к любому интерфейсу, если пользуешься им достаточно часто).
И вот тут опять же, провал: проблемами пользователя никто не занимается. Можно сравнить GIMP и Photoshop, Inkscape и Illustrator: базовый функционал у них действительно похож. Но покажите обе программы начинающему пользователю, и будет понятно, в чем разница.
И проблема не в ресурсах на разработку, они есть. Проблема в том, чтобы понять, куда разрабатывать.
Итоги
Все описанное выше — это не какие-то недоработки, которые можно взять и исправить, или страдания миллениалов, не могущих освоить не очень сложный интерфейс (а ваши деды в микрокодах писали!).
Это системные прое.. проблемы в архитектурной части, для исправления которых нужны значительные ресурсы не только в части времени и денег, но и запас проектной диктатуры, и смелости ломать уже существующие пользовательские привычки. Ведь, поправив все это — линукс уже не будет той системой, к которой привыкли эти миллионы людей, составляющие два процента. Лично для них миграция будет более болезненной и неприятной, чем освоение новой системы новичком.
К тому же проектной диктатуры в Opensource не хватает, потому что система построена на интересе. Уменьши интерес от запиливания новых фич, сказав "нам надо заниматься рефакторингом и слушать вот этого чувака-продакта безоговорочно" и разработчик пойдет коммитить в другой, более лояльный к интересам разработчика проект.
У меня нет плана, как это все исправить. Деньги — не настолько большая проблема, как кажется: они есть у государства, например. Правительство вполне понимает риски завязывания всей IT-структуры страны на чужое ПО и может выделить деньги в рамках программы импортозамещения, например. Гораздо важнее, как построить структуру так, чтобы эти деньги пошли именно на продуктовую разработку: как я уже говорил, для этого необходимо сделать метрикой успешности удовлетворенность пользователя.
Но, выделяя деньги на "российский линукс" абстрактно, это сделать невозможно: если государству нужен российский линукс, у него будет российский линукс, а про качество продукта там ничего не сказано.
Если выделить деньги госучреждениям с тезисом "закупайте сами", они закупят привычный Windows.
Если сказать "закупайте что угодно, кроме Windows", закупят ту систему, которая откатит больше бонусов: выбирать из десятка систем сложно, потому что они все одинаково кривые.
Если так и поставить задачу "сделайте линукс, которым удобно пользоваться", то сделают линукс, которым будет удобно пользоваться по мнению экспертной комиссии, а не по мнению пользователей: без свободного рынка оценить удобство можно только экспертно, а вот критерии экспертности уже формализуются настолько сложно, что никто этим заморачиваться не будет (или будет, что еще хуже).
Но если все пойдет, как идет сейчас, то Linux как Desktop-система продержится еще 5-10 лет, вряд ли больше: Microsoft осознает свою проблему в отсутствии POSIX-совместимости и невозможности работать со всеми теми наработками в OpenSource, созданными за 20 лет, и активно впиливает поддержку, используя ядро Linux внутри своей системы. Через некоторое время интеграция станет настолько хорошей, а инструменты вроде терминала разовьются достаточно, чтобы те, кто работал на Linux из-за удобства разработки, отладки и запуска серверных решений, перешли на винду: разницы нет, а интерфейс и удобство на порядок выше. И тогда десктопный линукс останется уделом полупроцента фриков и параноиков, из-за чего любая разработка заглохнет окончательно.
P.S. Что забавно, несмотря на многократное использование слова "Linux" в статье, к Linux-как-ядру описанные проблемы как раз имеют мало отношения: благодаря единому центру принятия решения о стратегии развития можно не опасаться проблемы абсолютной демократии, когда продвигаются решения, которые имеют меньше всего возражений. Там есть деньги, есть диктатор, который в любом случае фиксирует то или иное решение, и понимание того, что фиксировать решения необходимо. Ну и "пользователи" ядра Linux — это все еще категория разработчиков, а не конечных пользователей.



{kind=link}
{kind=link}