Комментарии 185

Немного ещё примеров генерации)

Немного ещё примеров генерации)

Немного ещё примеров генерации)
Картинки и тексты как будто взяты из сна. На первый взгляд выглядят реалистично, но если присмотреться к деталям - это жуткий майндфак. Сон на этом этапе обычно "ломается". А картинки - нет, их можно продолжать разглядывать. Любопытный феномен :)
Ага, причем, тексты во снах примерно так и выглядят.
И у вас так? Во сне иногда издалека ты вроде читаешь текст и даже вроде как понимаешь его смысл, но не всё тебе понятно и ты хочешь посмотреть поближе. И вот, приближаясь к нему, видишь.. вот именно то самое, что нагенерила эта сеть.
Удивительно.
Да и про картинки как из снов тоже согласен.
Еще одно подтверждение, что наш мозг в принципе не уникален, и когда-нибудь ИИ его догонит и, увы, перегонит.
У всех так. Так же фигня с музыкой, например. Когда слышишь типа во сне какую-то мелодию, помнишь что она была прекрасной, пытаешься ее вспомнить - и не можешь.
Потому что по факту там нет ни текста, ни мелодии, есть какие-то образы, которым мозг пытается подобрать чувственные ощущения. Ну действительно похоже на эти вот картинки, в сюжете сна сказано "ты слышишь музыку", и тебе кажется что ты что-то слышишь, хотя никакой музыки на самом деле нет, есть какие-то случайные обрывки и ощущение что ты ее слышишь, поэтому и вспомнить ее не можешь.
В принципе, тест на "дважды прочитать один и тот же текст и сравнить, вышло ли одно и то же" - хороший тест для проверки что ты во сне, для любителей практиковать осознанные сны.
Но это только во сне все кажется прекрасным
Однажды во сне я сочинил короткий стих и он был такой классный, что я очень захотел его запомнить и от того проснулся...
А текст в голове остался... Короче я разочаровался на яву :)
У всех так.
Похоже, не у всех. Удивлён, что кто-то видел во сне текст и слышал музыку.
Нормально во сне музыка придумывается, если иметь навык её запоминания и записи. Не редко встаю посреди ночи, чтоб наиграть приснившееся. А если навыка не иметь - то думаю всё очень сильно упрощается в памяти, если вспоминать под утро.
Занимаетесь музыкой что ли?
На любительском уровне, вроде сыграть опенинг к любимому мультфильму. И генераторы, вроде тех, что на shadertoy интересно пробовать делать. Я написал это к тому, что вникнув в некоторую область творчества, смотришь на вещи совсем другими глазами. Те же аудиофилы отлавливают характерные недостатки сжатия при mp3 192kbps, которые не тренированный человек не поймёт. Чуть научившись рисовать, смотришь, где и как свет идёт, как это изобразить удачнее. Ещё интересное наблюдение: если не учится писать рукой, то освоив основы языка после нескольких месяцев обучения и умея узнавать сотню иероглифов на вид, попытка нарисовать их по памяти полностью проваливается, выдавая результат как у сабжевых нейросетей.
//offtop on
За книги, тексты и вывески - да, есть такое.
Тоже самое кстати касается попыток посмотреть на часы во сне. Формально время там увидеть можно, но в большинстве случаев это будет или абсурд, или повторный взгляд через условную секунду, привет к абсолютно новому значению.
Феномен описан в книге "Практики Осознанных Сновидений" Стивена Лаберж. Это устойчивое явление, в числе прочего, используется как маячок понимания того, что Вы находитесь во сне в целях достижения осознанности.
По поводу того, что не у всех так - я об этом слышал и читал, но не уверен, что это не кажется таковым. Т.е Вы условно видели вывеску и проснувшись она кажется нормальной - но была всё таки абсурдной или нечитабельной.
Одно точно знаю на личной практике, что со временем, если практиковать ОС-ы например, то мозг словно тренируется периодически строить иллюзию того, что Вы не спите - т.е например вместо абсурда на часах Вы начинаете видеть вполне нормальное время, тексты на вывесках вроде бы тоже приходят в условную норму или начинаешь их так воспринимать, т.е условно маячки, которые раньше успешно работали и тренировались в состоянии бодрствования в целях развития критического мышления и проверки значения "сон-явь " начинают сбоить словно это делается мозгом специально. Насколько это так - большой вопрос, но например я неоднократно сталкивался с эффектом столь красиво показанном в известном фильме "Начало", а именно сон-во-сне и играешь с мозгом в игру проснулся ты или нет.
Вообще это тема отдельной статьи и сны штука интересная, но написать я её как-то не решаюсь из-за того, что многими тема изучения снов построенная вокруг ОС-ов воспринимается бредом и мистификацией из-за книг некоторых известных деятелей на К и клуба.. ммм.. мягко говоря странных людей, что возвели это в культ и чуть ли не религию.
Так меня что-то понесло.
//offtop off
К слову сказать, я использую руку (кисть) в качестве маркера сна - во сне у меня не бывает константного количества пальцев, их, во-первых, почти никогда не пять, а во вторых их вообще не посчитать, потому что их число меняется все время. Может, у Вас тоже так?
Рука, в отличае от часов и вывесок, как правило, есть всегда, вне зависимости от конекста)
С количеством пальцев не обращал внимания никогда специально - но вроде всегда было нормально, насколько я могу припомнить. Скорее всего такая техника ближе к индивидуальной и вопрос тренировки. Насколько я помню тот же мануал Лабержа - у каждого могут быть свои маркеры, общие приводятся как наиболее часто выделенное и совпадающее множество - те же часы или текст и тд и тп.
С другой стороны, во ОСе лично я постоянно специально смотрю на ладони, если требуется удержать осознанность и чувствую, что сейчас проснусь или теряю саму осознанность. Техника вроде оттуда же - работает прекрасно. По идее это же можно подвязать под маркер - посмотрел на ладони - потом на мир вокруг - если картинка изменилась или странная - сплю. С другой стороны специфично.
Вообще с пальцами надо попробовать - это мысль. Не то чтобы я их считал каждый раз, но вижу их так часто, что наверное мозг смоделирует довольно точно :)
Случайно прочитал ваш комментарий. Сегодня пытался прочитать надпись на упаковке с лекарством. Сначала оно показалось адекватным, но почему то я решил вчитаться и вдруг понял что только что надпись была другой, попытался вглядеться еще раз и опять что-то новое и тогда я точно понял, что во сне.
А тема с "сон во сне" раньше была вообще постоянно, когда сны были ярче. Думаешь что проснулся. Радуешься, ан нет - это опять сон.
Ну да, оно как-то так и работает. Нюанс в том, что по сути всё во сне кажется нормальным, хотя зачастую какие-то элементы переходят грань абсурдности (для меня это чаще всего люди, которых я не видел 100 лет и/или которые в принципе в моем кругу друг с другом никогда не пересекались, за умерших вообще молчу), а понимаешь это только, когда просыпаешься (если запомнилось).
Поэтому при практике ОСов как раз учишься всегда проводить критическую оценку реальности и искать условные странности или перепроверять. Без тренировки осознание, что спишь встречается настолько редко, что почти наверное никогда.
За сны во сне как у большинства сказать не могу - судя по Вашему комментарию бывают и может даже не редко. Но когда я практиковал ОСы попадал пару раз в цикл максимум в 6 (шесть) просыпаний внутри сна и каждый раз мне приходилось проверять сплю или нет и искать проснулся я или нет в собственной же комнате и каждый раз какой-то новый неочевидный момент не совпадал. Честно говоря, я не очень понимаю чем и зачем вызван такой феномен работы мозга, но игры в поиск реальности с одной стороны тогда вызывали интерес - с другой стороны несколько пугали.
А ведь некоторые из этих "мемов", если их удачно запостить, вполне могут составить конкуренцию реальным мемам! Это даже может стать темой для исследования - как нейросеть может хакнуть массовое сознание :)
Я проиграл с картинки «Пяп» (четвёртая в нижнем ряду).
Все картинки несуществующие, но картинка с Дауни младшим (второй ряд, четвертая картинка) неотличима от оригинала.

Немного ещё примеров генерации)

Немного ещё примеров генерации)


Немного ещё примеров генерации)

Ещё немного)
Это топ. Качество невероятное! Как тебе такое, Илон Маск?

Котики, куда же без них?

Собаченьки

ожидаемо

Типа фото

Пейзажи
А если запрашивать "некрасивое" всякое?)
Порно из датасетов постарались вычистить, но, конечно, совсем идеально это не получилось. Но вообще самый страшный крип это не порно, а то, что моделька генерирует на запросы типа «элитный педикюр». Потому что считать-то (что пальцы, что другие предметы) она особо не умеет, разве что до трёх...
Оу, я как-то и не подумал про порно - просто заметил, что во многих примерах есть эпитет "красивый/ое/ая"... Но я Вас понял :)
Порно для вас ассоциируется с "некрасивым"?
Или нейросеть его выдавала, и вам пришлось вычищать?
не получилось



Мне лысые кошки конечно тоже не очень нравятся, но что на первой картинке вообще? Наверное не стоило включать в датасет фото с ватермарками.
Судя по семплам из комментариев и моих экспериментов с этой сеткой, складывается ощущение, что сеть серьезно страдает проблемой меморизации...Есть ли какой-то анализ полученной модели? Какие значения FID оно показывает на валидационной выборке, как соотносится с DALL-E, CogView на COCO etc.?
Аналогичное ощущение. Словно сеть просто нашла способ упаковать все разнообразие данных, на которых обучалась и выплевывает с дорисовкой то, что сохранено под определленными словами или ембеддингами этих слов.
Выглядит как скорее неудача, чем успех. Сеть достаточно откровенно выдает картинки, на которых она обучалась. Это видно невооруженным глазом. И это плохо, ИМХО.
Я так понимаю, это общая проблема автоэнкодеров. Интересно, как с этим можно бороться, если можно вообще.
Проблема в том, что эту разработку подают как сеть, понимающей смыслы, а по смыслам понимающую изображения. По факту же, сеть просто занимается сжатием картинок, которые индексирует по словам. Выход этой сети -- просто распаковка значений, лежащих близко к примитивной упаковке предложения в вектор.
Грубо говоря, ее работа на данный момент хуже простого поиска в гугле, ибо выдает она тоже самое, что поиск, только отягощенное сжатием-расжатием.
В целом это проблема не только автоэнкодеров, а вообще всех нейронных сетей (да и других тренируемых моделей тоже). В первую очередь модель же пытается заучить все, что ей показывают (т.к. методы обучения от нее именно этого и хотят обычно в явном или не очень виде), а обобщать начинает уже от безысходности, когда емкости не хватает для заучивания.
Тут скорей вопрос в том, насколько конкретная модель заучила трейн и является ли это проблемой конкретного пайплайна, или другие large scale сети для text-to-image (в частности CogView, который публично доступен и с которым можно как-то сравниваться) тоже склонны к меморизаци в +/- той-же степени. Ну т.е. очень круто, что Сбер тратит ресурсы на тренировку гигантских сетей и выкладывает это в паблик под свободной лицензией, но хотелось бы, чтобы модели были действительно полезными, а не только "самыми большими") А без хоть каких-то метрик и анализа не понятно, насколько оно полезно.
обобщать начинает уже от безысходности, когда емкости не хватает для заучивания.

А есть какое-то внятное объяснение, как это может работать? Чет ничего в голову не приходит… Разве что за счет именно глубоких архитектур, когда сеть все-таки не может выделить внутри себя отдельные «подсети», и в любом случае что-то как-то обобщает на входных слоях, что бы уже дальше разобраться в нюансах…
Гипотеза подтверждается экспериментами по прореживанию таких избыточных сеток. Если ранжировать все их веса по вкладу в выходной сигнал и начать обнулять наименее значимые, то оказывается возможным занулить до 90% всех весов тренированной сетки, прежде чем начнётся заметное просаживание качества. Т.е. всю реальную работу выполняет «выигрышный лотерейный билет» — небольшой участок (или пара-тройка таких), победивший в жёсткой конкурентной борьбе на этапе тренировки.
Согласен, я умышленно загрубил свое высказывание, чтобы не вдаваться в подробности ;) На графике, на самом деле, можно предположить и корреляцию между трейн/тест как один из факторов, благодаря которому точность в ноль не падает на тесте и другие причины такого поведения.

P.S. На Tesla P100 в колабе оно конечно жесть как долго генерирует в сравнении с Clip+VQGAN.
Только они будут растровые по определению. ;)
А еще встречаются очень интересные экземпляры генерации, содержащие надписи, природу которых я не понимал, пока не прочитал вашу реплику про «свободные от лицензии фотостоков»:

Видимо в обучающих выборках были и не совсем свободные? ;)
Ну растровые ещё прогоним через трассировщик — и вот у нас уже куча всратых векторных иллюстраций :) В выборку картинки тянули краулеры, понятно, что попало в датасеты всё, что было не закрыто — из двух сотен миллионов картинок отсеять те, что без ватермарков, не совсем просто, но это постепенно поправим.
А вот когда в выборке картинки с одинаковым копирайтом составляют заметный процент, вот тогда нейронка этот копирайт успешно ухватит.
Почему так важно создавать изображения на основе именно русского языка? Сегодня уже довольно хорошо работают переводчики. Ведь можно перевести фразу на английский и пользоваться обычной DALL-E. Согласен, наверно будут проблемы с генерацией типа "лучшая картина Васи Ложкина", но тем не менее, зачем бороться за язык исходной фразы?
Любая дополнительная модель in the middle снижает качество всего пайплайна. Ну и, конечно, нам важно иметь модель, которая учитывает отечественные реалии — она всё-таки для русскоязычных сервисов, в первую очередь.

А вот зачем. Понятно, почему это "большие сиськи"? :) Если нет - переведите "tit" на английский.

Просто похлопаю. Я ещё не отошёл от вашего прошлого мегауспешного проекта https://habr.com/ru/company/sberbank/blog/584068/
Я так и не понял, зачем мне генератор воображаемых характеристик (указываю название реальных товаров и мне в тексте вписывают несуществующие характеристики).
Ждал этого 30 минут.

:( Не всегда получается хорошо, увы. А сейчас 5000 запросов в очереди на генерацию, и даже 150 карт Nvidia V100 не вывозят быстрее...
Хотел уже попробовать запустить локально, но увы — на windows у меня(и судя по issue на гитхабе — не только у меня) падает компиляция youtokentome :(
У меня под Linux успешно запустилось, но в самом конце упало по причине нехватки видеопамяти (GTX 1080 8 GB).
youtokentome, кажется, падает из-за cython.
В общем, я на винде запустил.
fix: первый issue не совсем то, имел ввиду этот
У меня нормально запустилось на win10, просто часть зависимостей, включая cython для youtokentome пришлось ставить вручную. Но проблем в этот раз значительно меньше чем обычно.
По недостатку видеопамяти вылетает апскейл, рекомендую для домашних эксперементов его убрать, также как и черипикинг, который можно и самостоятельно провести. Кроме того, если поэксперементировать с параметрами, качество генерации можно и подтянуть.
:( Не всегда получается хорошо, увы. А сейчас 5000 запросов в очереди на генерацию, и даже 150 карт Nvidia V100 не вывозят быстрее...
Хабраэффект в 2021 году



Слава богу, Хэмингуэй это не увидел.

Мда.





"Пурпурная пульсирующая сущность в пространстве". Что-то я не вкурил, что он хотел сказать этим..
Больше похоже на обложку альбома для пост-рока
Негры ночью уголь воровали

Пробую разные запросы, чаще всего вылезает что-то абстрактное, похожее на текст со сильно смазанными буквами.
Хотя иногда что-то похожее вылезает, но не совсем точно.
Певица с очень большой грудью

На певицу она похожа, вот только грудь у неё не очень-то и большая.
Я так понял, что на графике training loss. Видно, что loss меняется с 5.25 до 5.0 ооооочень долго. Интересно, как различаются качество картинок при loss=5.25 и при loss=5. Вообще, насколько в принципе (не)возможно, чтобы loss упал до нуля в этой модели?
Как когда-то заметил Денис Ширяев, добавление к тексту запроса слов unreal engine и/или rtx mode on делает результат немного качественнее
Простейший вопрос для ИИ "зеленый цилиндр стоит на двух серых кубиках" выдал 2 зеленых квадрата. Печаль...

Это другая статья была.
Здравствуйте! Удалить опубликованный комментарий могут только модераторы и только в случае выявления факта нарушения правил сайта.
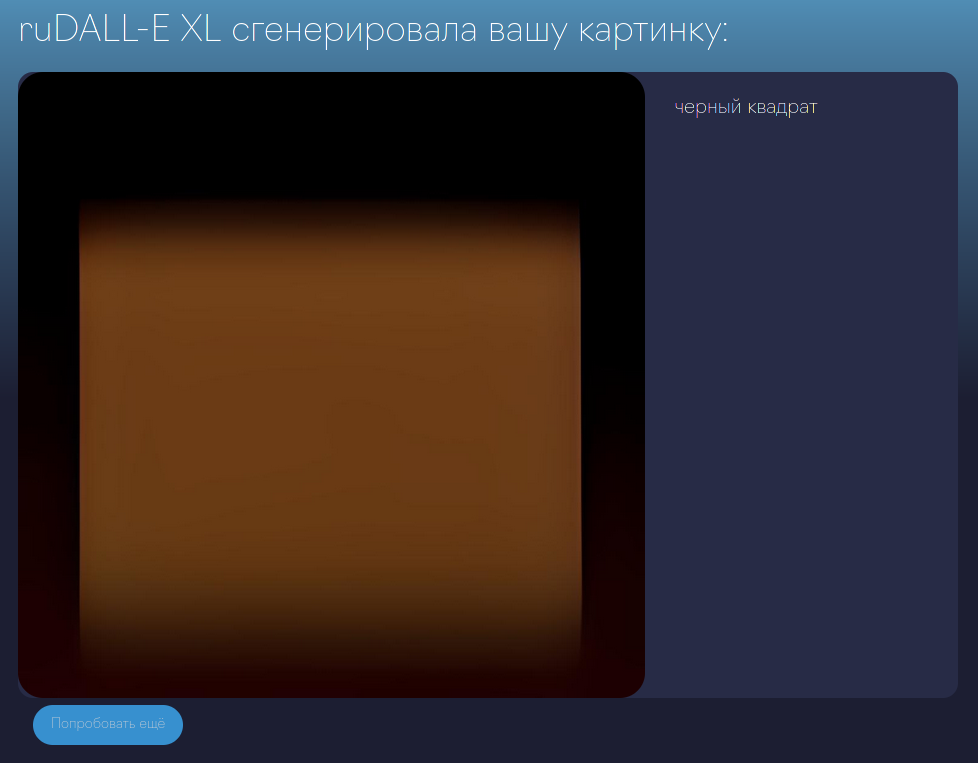
У вас Malevich не может чёрный квадрат нарисовать.

...переводчик поверх модели OpenAI...
Если я использую прилагательное "кошачий", тупо получаю кошку во всю картинку. Несолидно.
Опытным путем мы установили, что параметры top_p и top_k контролируют степень абстрактности изображения
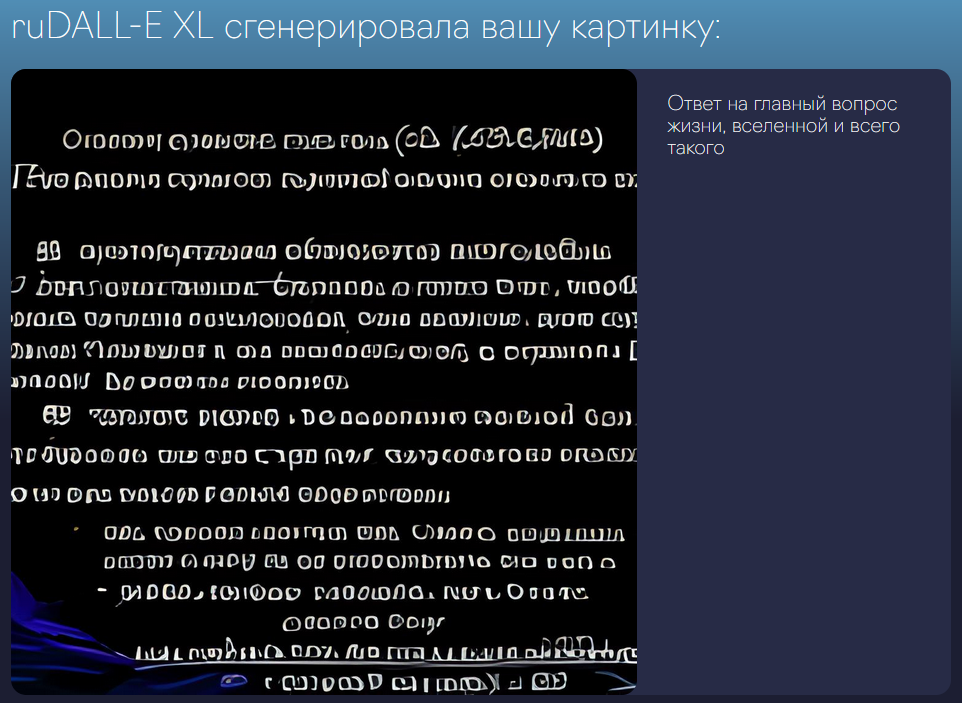
А вот это вообще меня убило. "...большая машина "воин-купол" пришла в движение от пальца в отверстии пятом и от пальца в отверстии сорок седьмом, и движение было неодолимое, быстрое и прямое."
Короче, общее впечатление - дети дорвались до мощной техники.

Как пет-проект сделанный по фану, чисто по приколу - было бы вполне неплохо.
Но когда проект с таким количеством треша в результатах так помпезно презентуется... мне не понять.
P.S. Сама идея интересная, и думаю лет через 10-20 появятся вполне хорошие генераторы изображений. Но пока - это больше похоже на генератор треша.
Т.е. вот у сбера есть команда, которая проводит некие изыскания в области основных проектов машинного обучения. Получается по-разному. Иногда прям вот круто. Иногда — не очень. Но они выкатывают результаты как есть — со всеми недостатками и что важно — исходниками!
Было бы гораздо хуже, если бы выкатывались только однозначно выверенные готовые пойти в прод модели. Да и где помпа-то? Ну да — по телеграм-каналам и разным лентам новостным разошлось, но так… Стиль подачи скорее именно как у пэт-проекта (правда с нефиговым техническим ресурсом!).
Я двумя руками за то, что в сбере есть такая команда, что они это делают, что выкладывают — пусть и дальше продолжают в том же духе! Я использую их GPT2/3 модель и скрипты для фантюнинга для своих изысканий — до них это было бы сильно сложнее.
Ещё немного треша с rsdn
У вас на сайте при нажатии на кнопку "Обновить" браузер переходит в полноэкранный режим...
Спасибо за отличную нейросеть и статью! Вы молодцы! Продолжайте в том же духе
попадание только в 2 слова, а по смыслу вообще попадания нет


«Зелёные бутылки на красном фоне»

«Мультфильм Крокодил гена и Черномырдин»

«Бог»

«Бутылка вина, бокал с вином, на зелёном фоне картина маслом»

«Айвазовский, мазки квадрата Малевича»
Очень круто.
В комментах пишут типа "проект с таким количеством треша в результатах".
Но в этом же и крутость! Конкретную картинку по тексту легко найти в любом поисковике. А тут такой полет фантазии! Столько материала для вдохновения собственных нейронных сетей (которые, как его там, мозг)!
Работало бы только побыстрее, но это, очевидно, дело наживное.
Ребята, понятно, что со временем вы научитесь генерить картинки без такого количества нелепицы и абсурда, но, пожалуйста, оставьте возможность синтеза таких вот странных изображений. Или сделайте "регулятор абсурдности", от 0 до 100%.
А Николай Иронов - родственник Далли? По такому же принципу работает?
Просто не понятно, как удалось Артемию Лебедеву, при всем уважении, создать собственного (?) ИИ-дизайнера, очевидно не обладая такими колоссальными технологическими и финансовыми ресурсами, как у Сбера.
Это как говорить, если цепи Маркова тоже синтезируют текст, то зачем нужны GPT2/3?
Так вот ты какой...





Ночевала тучка золотая
На груди утеса-великана;
Утром в путь она умчалась рано,
По лазури весело играя;
Азбука по версии нейронки

У кого-нибудь получилось запустить на 6gb vram карточке?
В этом и суть, что в Collab ОООчень долго. Хотел узнать смог ли кто-то оптимизировать потребление памяти в угоду скорости. У меня GTX 1660 SUPER, а тут вижу что ребята запускают на более слабых картах, но с большими VRAM.
Сами авторы на гитхабе обещают выпустить уменьшенную модель к новому году
Ага, видел. Но там кто-то уже пулл реквест создал на оптимизацию, пойду пробовать.
p.s.: Действительно, с этим форком стало генерировать в РАЗЫ(10x) быстрее, но проблема с памятью у меня все еще актуальна.
Таки смог сгенерить, ток на cpu :), форк парня на ускорение + fp16=False + device = 'cpu' + в generate_images(images_num=1) - итог:
8 минут генерации 1 картинки на intel core i5 10400f. Без форка ушел бы примерно час на cpu.
"Светлое будущее". Что-то как-то мрачновато...

Сплошное разочарование. Это вот разве "Много разных маленьких финтифлюшек, плавающих в тазике с синими чернилами"?


А вот "Имладрис" уже явно не понимает. Корпус богатый, но не на столько.
На каггле ругается на зависимости: "allennlp 2.7.0 requires transformers<4.10,>=4.1, but you have transformers 4.10.3 which is incompatible". Но работает.

Какой же интернет без этого персонажа…
Ей богу. Лучше бы Бетховенов намайнили и всем хабровчанам раздали )

"Мем про парня и двух девушек"
Я имел в виду этот:

и композиционно оно даже как-то похоже.
Осталось сделать нейросеть переводчик:

¯_(ツ)_/¯
Ваша программа выдаёт мне файл. Эта программа работает без моей власти, по вашей воле. Следовательно, результат её работы является вашим произведением. Эти иллюстрации закрыты вашим авторским правом. И отсюда вопрос.
Скажите пожалуйста, по какой лицензии вы разрешаете использовать произведения, созданные этим сайтом, этой нейросетью?
Спасибо.
Если следовать этой логике, то молоток работает по воле создавшего его мастера, MS Word по воле Microsoft. Нейронка это просто инструмент — сложный, но и только. Все лицензии указаны и в github'е и на сайте rudalle.ru
а то так можно брать чужие меди файлы, к примеру из компьютерных игр, делать программу, которая эти файлы будет слегка модифицировать (уменьшать размер на 1 пиксел например) с помощью опенсорс приложения и на их основе делать новую игру, и говорить результат лицензионно чист, вон открытая лицензия используется.
А то понаберут рефов, прокрутят в своей межушной нейросети и на их основе делают новый рисунок.
Ну, а если серьёзно, то нейронки — это потенциально огромный вызов всей системе авторских прав. Даже больший, чем распространение Интернета. Потому что при простом копировании контента хотя бы можно понять, что перед вами копия, а когда контент пропущен через нейронки, то в большинстве случаев совершенно невозможно доказать, что использовались закопирайченные данные, причём принадлежащие именно данному правообладателю.


{kind=link}
{kind=link}


И ещё

Его здесь все знают

Учись, Петров-Водкин

наиболее удачные из около 20 попыток



Сперва попытки получить что-то релевантное провалились. "Мику играет на пианино", "Рин и Лен седлают коня", "девочка на коте в осенних джунглях" - выдают мусор, грубую мазню. Очень не хватает ускоренного промежуточного результата, чтоб оценить примерно, что там оно наколдовало и продолжить или отвергнуть/переделать, ведь каждый раз оно генерирует по-разному. Ночью считает быстро 2-3 мин.
Подведём итоги темы:

Мне напомнило Гугл начало 00х. Когда нужно было правильный запрос писать, что бы найти нужный ответ. Так и тут, при правильном тексте может выдать просто жемчужину. Но все же это криповые, психоделические, фантазийные картинки. Неплохо кстати эмитирует работы Пикассо, Мунка, Малевича и др. Достаточно написать "картина пикассо" например.

Что-то в этом есть.
Не знаю почему, но это мне нравится СЛИШКОМ сильно...



Хочу спросить, а кто-нибудь пробовал подкрутить параметры в коде?
Например, в ячейке Generation, seed_everything(42) - на что-нибудь влияет это число?
Киберпанк девяностых

Очень неплохо работает с запросом "шарж".
Например по запросу "Весёлый "Иосиф Виссарионович Сталин шарж карандашный рисунок" - получился весьма обаятельный Виссарионыч.

Так-же сеть умеет работать с логотипами (разумеется при правильном запросе). Это уже прямая конкуренция Лебедевскому Н.Иронову за сто тысяч рублей. Причём нужно конечно посидеть, погенерить. Но результаты не хуже Лебедевских. А порой и интересней.



Я видимо где-то туплю но при попытке установить себе на винду (pip install -r ru-dalle/requirements.txt) выдает конфликт версий в исходниках:
ERROR: Cannot install -r ru-dalle/requirements.txt (line 1), -r ru-dalle/require ments.txt (line 3) and -r ru-dalle/requirements.txt (line 9) because these packa ge versions have conflicting dependencies.
The conflict is caused by:
taming-transformers 0.0.1 depends on tqdm
transformers 4.10.2 depends on tqdm>=4.27
torchvision 0.2.2 depends on tqdm==4.19.9
To fix this you could try to:
loosen the range of package versions you've specified
remove package versions to allow pip attempt to solve the dependency conflict
ERROR: ResolutionImpossible: for help visit https://pip.pypa.io/en/latest/user_g uide/#fixing-conflicting-dependencies
Подскажите как поправить.
Сделайте систему оценок изображения, мы бы могли помочь нейросети генерировать изображения более адекватные некоторым запросам.
Телеграмм бот перестал работать. Завис на этой фразе. "Одновременно можно обрабатывать только один запрос! Пожалуйста, дождись завершения обработки и попробуй еще раз." Перезагружал.
Очень залипательно)))
На сайте https://rudalle.ru/ на запрос "Анна Каренина" и "пес" выдает ошибку неправильного заполнения формы. При запросе "котопес" крутится колесико загрузки, затем останавливается, картинка не появляется. При нажатии на кнопку "Обновить" появляются результаты для запроса "курица".

При запросе "котопёс" появляются результат для запроса "все в порядке"

"Унесенные ветром" в стиле Картина маслом выглядит шикарно!)))

Люди в общем-то ничего получаются


Но не все, Анна Каренина ему не заходит совсем))))))

ruDALL-E: генерируем изображения по текстовому описанию, или Самый большой вычислительный проект в России