Привет!
С начала года мы провели около 10 хакатонов и воркшопов по всей стране. В мае мы вместе с AI-community организовывали хакатон по направлению «Цифровизация производства». До нас хакатон про data science на производстве ещё не делали, и сегодня мы решили подробно рассказать о том, как это было.

Цель была проста. Нужно было оцифровать наш бизнес на всех его этапах (от поставок сырья до производства и прямых продаж). Само собой, должны были решаться и задачи прикладного характера, например:
В чём главная ценность таких задач? Правильно, в максимальном приближении к настоящим бизнес-кейсам, а не к абстрактным проектам. Первая задача уже подробно описана на Хабре одним из участников (спасибо, cointegrated Давид!). А второй задачей, вынесенной на хакатон, стала необходимость оптимизировать процесс совмещения плановых ремонтов ж/д-вагонов логистического парка. Это взяли прямо из нашего текущего бэклога, немного адаптировав для участников, дабы сделать её понятнее.
Итак, описание задачи.
У специалистов по логистике есть специальный календарь, куда вносится информация об отправке вагонов на плановое техобслуживание. Так как вагонов больше двух (сильно больше двух), нужно решение, которое упростит работу сотрудника, сделав его работу проще, интуитивнее, а также поможет ему быстрее принимать те или иные решения на основе предварительного анализа данных.
Поэтому само решение должно включать в себя две составляющие:
Мы предоставили участникам датасет об отправке на ремонт 18 000 вагонов с данными о всех расстояниях, тайминге и прочим (информация за несколько лет). Плюс к этому у них была возможность вживую пообщаться с бизнес-оунером процесса и уточнить у него все необходимые подробности, а также собрать пожелания.
Казалось бы, ну составил календарь ремонта вагонов и всё, чего тут ещё можно оптимизировать? А главное — как и чем измерить эффективность решения?

Критерии оптимизации плановых ремонтов
Тут стоит начать с того, что ремонт вагона — это не просто ремонт вагона. У каждого нашего вагона может быть 4 типа ремонтов.
У каждого из этих четырёх видов ремонта есть своя стоимость непосредственно ремонта (материалы для починки + оплата работ по ремонту), а также стоимость подготовки к ремонту. Кроме этого, есть ещё и стоимость доставки вагона до депо. А так как вагон едет целенаправленно на ремонт, то едет он порожняком, значит, исключаем тут возможную прибыль за поездку.
Начали ребята, само собой, с гипотез.
Гипотеза №1. Если совместить несколько ремонтов в один день, можно сэкономить на подготовительных работах.
Гипотеза встретила предложение вида «Да давайте тогда просто при каждом ремонте делать ещё и все остальные, чтобы два раза не вставать, в тот же день».
Звучит круто. Местами даже логично. Но не всё так просто.
У ремонта (у любого из четырёх) есть не только стоимость, но и утилизация. В общем, как с машиной. Прошёл ты техосмотр в январе, и тянешь до следующего техосмотра как можно дольше, чтобы каждый потраченный рубль на первый техосмотр расходовался эффективно. Если делать ТО слишком часто, не вырабатывая ресурс, теряешь деньги.
Да, с авто пример не совсем совпадает с нашим, все же, ситуации бывают разные, и иногда стоит пройти ТО заранее (а то и 2-3 раза в год), скажем, перед важной долгой поездкой. Но в случае с огромным количеством вагонов такой фальстарт ремонтов может принести довольно серьёзные убытки.
Гипотеза №2. Тогда можно просто совмещать эти ремонты так, чтобы утилизация каждого из них была максимально полной.
Уже лучше. Возникают вопросы:
С какой именно станции вагон выгоднее отправить в ремонт?
Путь от каждой станции до депо мы знаем. А путь между самими станциями — нет. Может, вагон осилит перевезти чуть больше груза и отправиться в депо с более дальней станции, но зато заработав на поездке?
Гипотеза №3. Учитываем расстояния между станциями и прибыль от доставки продукции — оптимизируем логистические точки отправки в ремонт.
Чтобы гипотеза была не просто голословным заявлением, её лучше выражать в финансовых показателях.
То есть тут, чтобы решить задачу, в идеале надо построить такую модель, которая сможет максимально эти показатели между собой увязать. При этом дав возможность менять входные параметры (количество вагонов, отправляемых на ремонт, даты ремонтов, нахождение на станциях и прочее) и показывать реальную экономию средств.
И опять же, главное. Это программа, с которой будут работать люди. Поэтому надо сделать интерфейс для людей, а не адовое нагромождение формочек и табличек с фильтрами. Каждый из сотрудников, который будет работать с этим интерфейсом, должен быстро понимать, что вообще происходит, откуда едет этот вагон и за каким вот эти вагоны додумались совместить.
В качестве отправной точки мы показали участникам несколько наших черновиков. Это было не руководство к действию, а просто пример.

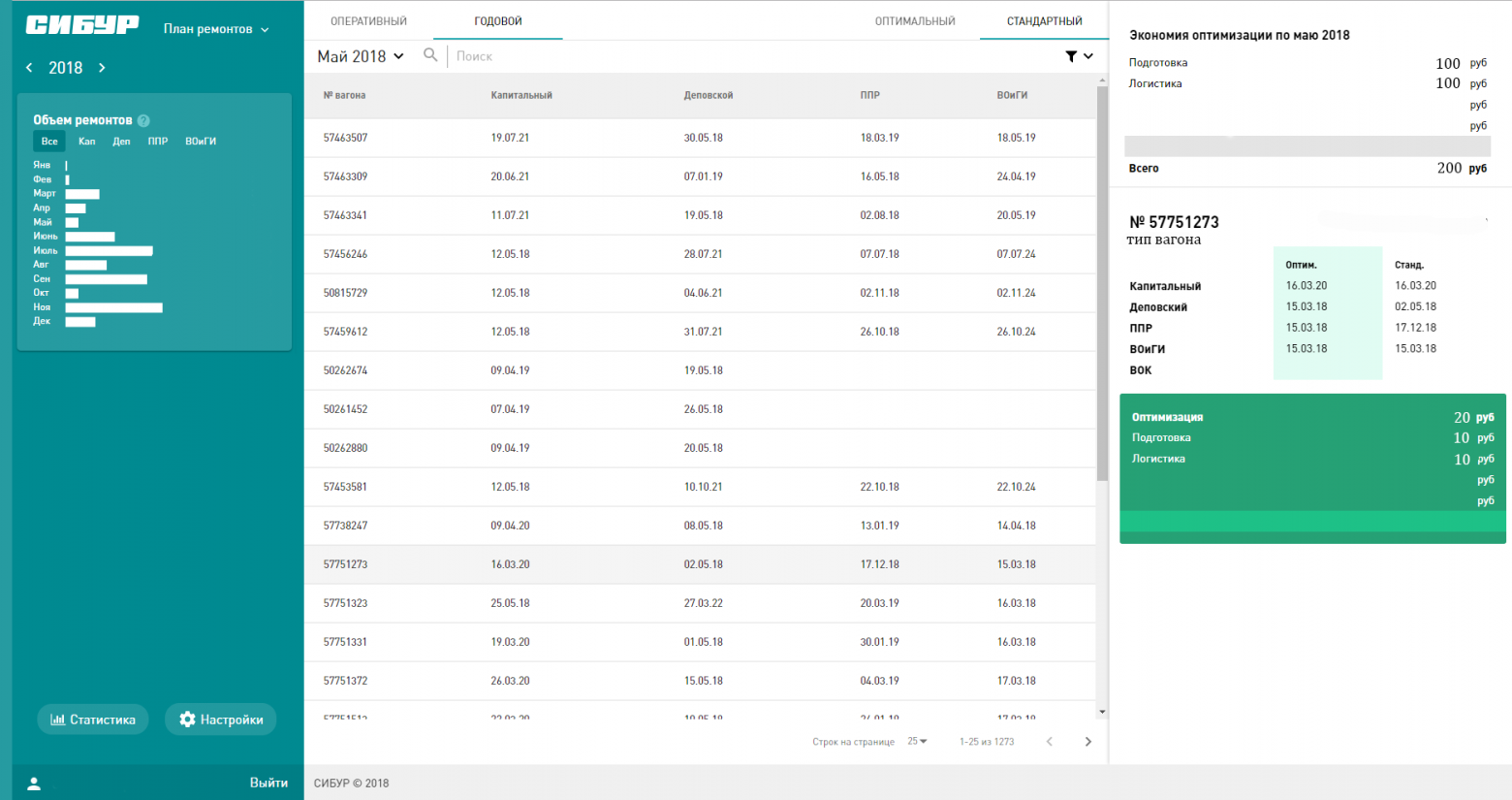
Черновые эскизы дизайнов
Участники приняли все эскизы и пожелания и ушли думать.
Пара дней прошла в формате постоянных уточнений — команды приходили к нам, показывали примерные наброски, что-то уточняли, получали ответы, уходили допиливать решение дальше.
На самом деле, со стороны организатора это выглядит очень круто — люди креативят на ходу, подстраиваясь под новые уточнённые вводные, за пару часов находя в собственном решении какие-то минусы и тут же их устраняя. Причём в формате полноценной командной работы — пока один рисует дизайн всего этого добра, дата-сайнтисты уже заканчивают писать первые скрипты.
Мы сейчас стараемся сделать так, чтобы наше цифровое подразделение работало над повседневными задачами компании в такой же атмосфере, потому что это очень захватывает.




Тут всё было просто и привычно. У каждой команды есть 5 минут на выступление, а у организаторов — 5 минут на вопросы. Само собой, рамки не были совсем уж жёсткими, и иногда мы выходили за это время.
На всё про всё в таком ритме мы провели часа 3.

Оценивали полученные решения комплексно — подходы к решению задачи в общем и целом, визуализацию, применимость предложений в реальности. Тут помог подход AI-community, по которому фиксировались ещё и промежуточные результаты процесса.

Главный приз (300 000 рублей) достался команде «Hack.zamAI».
Ребята создали комплексное решение, не только оптимизировав финансовые показатели, но и вписав туда кучу дополнительных плюшек, отобразив в продукте готовый бизнес-процесс.
При этом оно всё ещё и выглядит достойно и дружелюбно.




Вот тут можно посмотреть демонстрацию их решения.
(видео на GoogleDrive)
Само собой, это не последний наш хакатон.
Хотим сказать спасибо всем, кто участвовал в этом. И обязательно разместим анонс следующего.
Дмитрий Архипов, архитектор, «Цифровизация процессов», СИБУР
С начала года мы провели около 10 хакатонов и воркшопов по всей стране. В мае мы вместе с AI-community организовывали хакатон по направлению «Цифровизация производства». До нас хакатон про data science на производстве ещё не делали, и сегодня мы решили подробно рассказать о том, как это было.

Цель была проста. Нужно было оцифровать наш бизнес на всех его этапах (от поставок сырья до производства и прямых продаж). Само собой, должны были решаться и задачи прикладного характера, например:
- устранение простоев оборудования, технологических нарушений и сбоев;
- повышение производительности и вместе с этим — качества продукции;
- снижение затрат на логистику и закупки;
- ускорение запуска и вывода на рынок новых продуктов.
В чём главная ценность таких задач? Правильно, в максимальном приближении к настоящим бизнес-кейсам, а не к абстрактным проектам. Первая задача уже подробно описана на Хабре одним из участников (спасибо, cointegrated Давид!). А второй задачей, вынесенной на хакатон, стала необходимость оптимизировать процесс совмещения плановых ремонтов ж/д-вагонов логистического парка. Это взяли прямо из нашего текущего бэклога, немного адаптировав для участников, дабы сделать её понятнее.
Итак, описание задачи.
Что нужно было сделать
У специалистов по логистике есть специальный календарь, куда вносится информация об отправке вагонов на плановое техобслуживание. Так как вагонов больше двух (сильно больше двух), нужно решение, которое упростит работу сотрудника, сделав его работу проще, интуитивнее, а также поможет ему быстрее принимать те или иные решения на основе предварительного анализа данных.
Поэтому само решение должно включать в себя две составляющие:
- Специальный алгоритм на основе анализа данных.
- Удобный интерфейс, позволяющий подробно и понятно визуализировать полученные данные и результаты работы алгоритма. На чём именно реализовывать (веб, мобильное приложение, или вообще с помощью бота) — на усмотрение участников.
Вводные данные
Мы предоставили участникам датасет об отправке на ремонт 18 000 вагонов с данными о всех расстояниях, тайминге и прочим (информация за несколько лет). Плюс к этому у них была возможность вживую пообщаться с бизнес-оунером процесса и уточнить у него все необходимые подробности, а также собрать пожелания.
Казалось бы, ну составил календарь ремонта вагонов и всё, чего тут ещё можно оптимизировать? А главное — как и чем измерить эффективность решения?
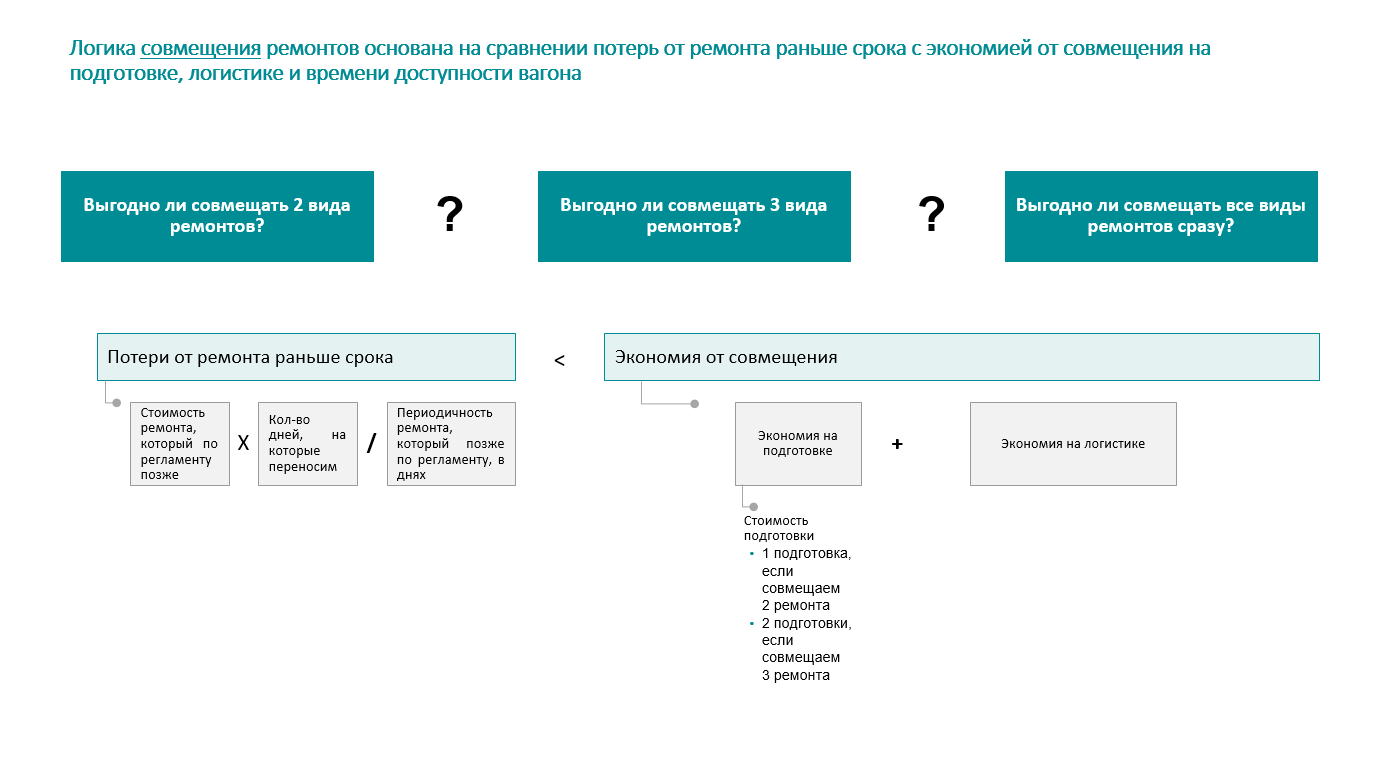
Критерии оптимизации плановых ремонтов
Тут стоит начать с того, что ремонт вагона — это не просто ремонт вагона. У каждого нашего вагона может быть 4 типа ремонтов.
- Капитальный.
- Деповской.
- Плановый предупредительный.
- Вакуумная очистка и гидроиспытания.
У каждого из этих четырёх видов ремонта есть своя стоимость непосредственно ремонта (материалы для починки + оплата работ по ремонту), а также стоимость подготовки к ремонту. Кроме этого, есть ещё и стоимость доставки вагона до депо. А так как вагон едет целенаправленно на ремонт, то едет он порожняком, значит, исключаем тут возможную прибыль за поездку.
Начали ребята, само собой, с гипотез.
Гипотезы
Гипотеза №1. Если совместить несколько ремонтов в один день, можно сэкономить на подготовительных работах.
Гипотеза встретила предложение вида «Да давайте тогда просто при каждом ремонте делать ещё и все остальные, чтобы два раза не вставать, в тот же день».
Звучит круто. Местами даже логично. Но не всё так просто.
У ремонта (у любого из четырёх) есть не только стоимость, но и утилизация. В общем, как с машиной. Прошёл ты техосмотр в январе, и тянешь до следующего техосмотра как можно дольше, чтобы каждый потраченный рубль на первый техосмотр расходовался эффективно. Если делать ТО слишком часто, не вырабатывая ресурс, теряешь деньги.
Да, с авто пример не совсем совпадает с нашим, все же, ситуации бывают разные, и иногда стоит пройти ТО заранее (а то и 2-3 раза в год), скажем, перед важной долгой поездкой. Но в случае с огромным количеством вагонов такой фальстарт ремонтов может принести довольно серьёзные убытки.
Гипотеза №2. Тогда можно просто совмещать эти ремонты так, чтобы утилизация каждого из них была максимально полной.
Уже лучше. Возникают вопросы:
С какой именно станции вагон выгоднее отправить в ремонт?
Путь от каждой станции до депо мы знаем. А путь между самими станциями — нет. Может, вагон осилит перевезти чуть больше груза и отправиться в депо с более дальней станции, но зато заработав на поездке?
Гипотеза №3. Учитываем расстояния между станциями и прибыль от доставки продукции — оптимизируем логистические точки отправки в ремонт.
Чтобы гипотеза была не просто голословным заявлением, её лучше выражать в финансовых показателях.
То есть тут, чтобы решить задачу, в идеале надо построить такую модель, которая сможет максимально эти показатели между собой увязать. При этом дав возможность менять входные параметры (количество вагонов, отправляемых на ремонт, даты ремонтов, нахождение на станциях и прочее) и показывать реальную экономию средств.
И опять же, главное. Это программа, с которой будут работать люди. Поэтому надо сделать интерфейс для людей, а не адовое нагромождение формочек и табличек с фильтрами. Каждый из сотрудников, который будет работать с этим интерфейсом, должен быстро понимать, что вообще происходит, откуда едет этот вагон и за каким вот эти вагоны додумались совместить.
В качестве отправной точки мы показали участникам несколько наших черновиков. Это было не руководство к действию, а просто пример.
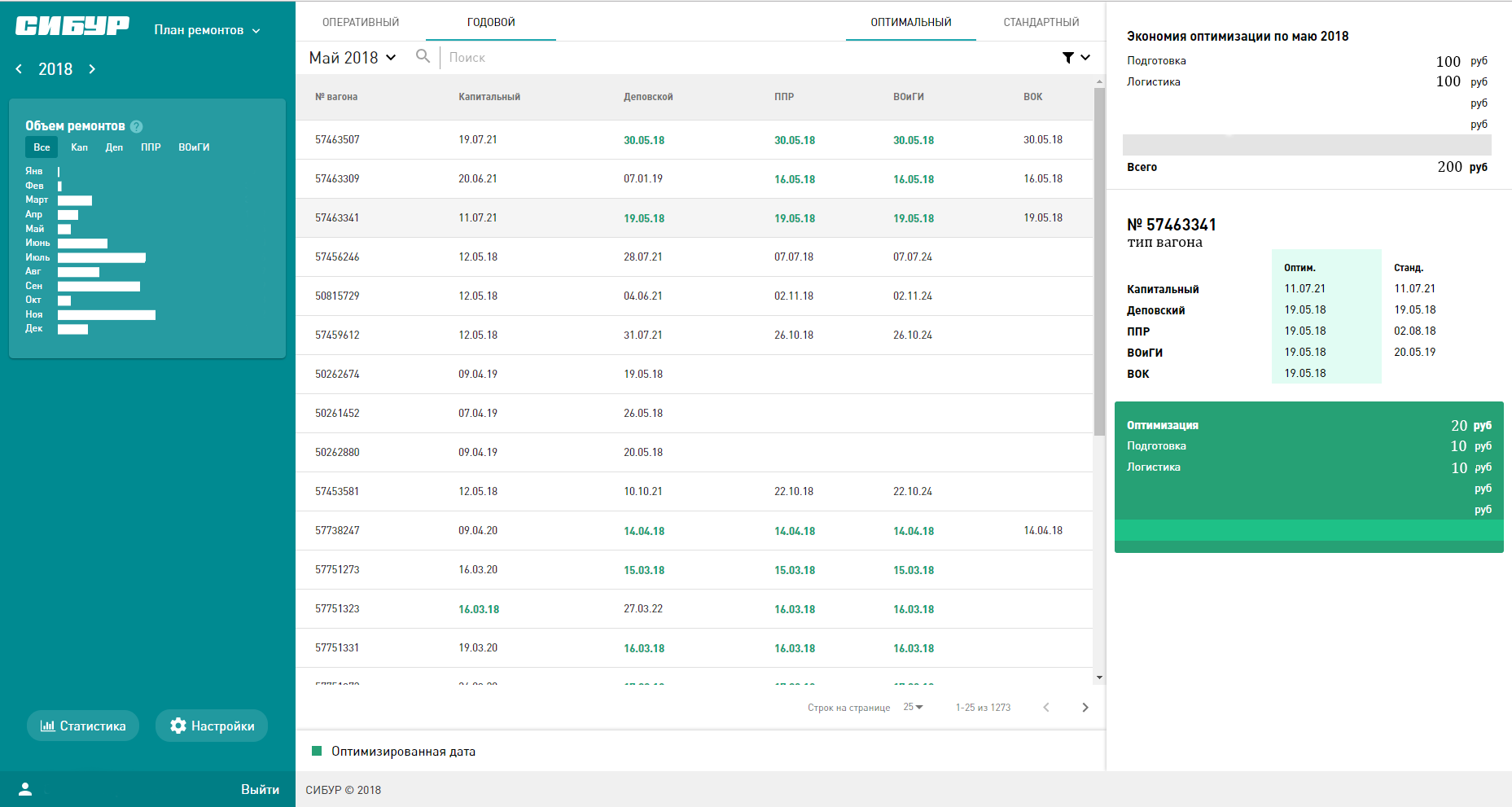
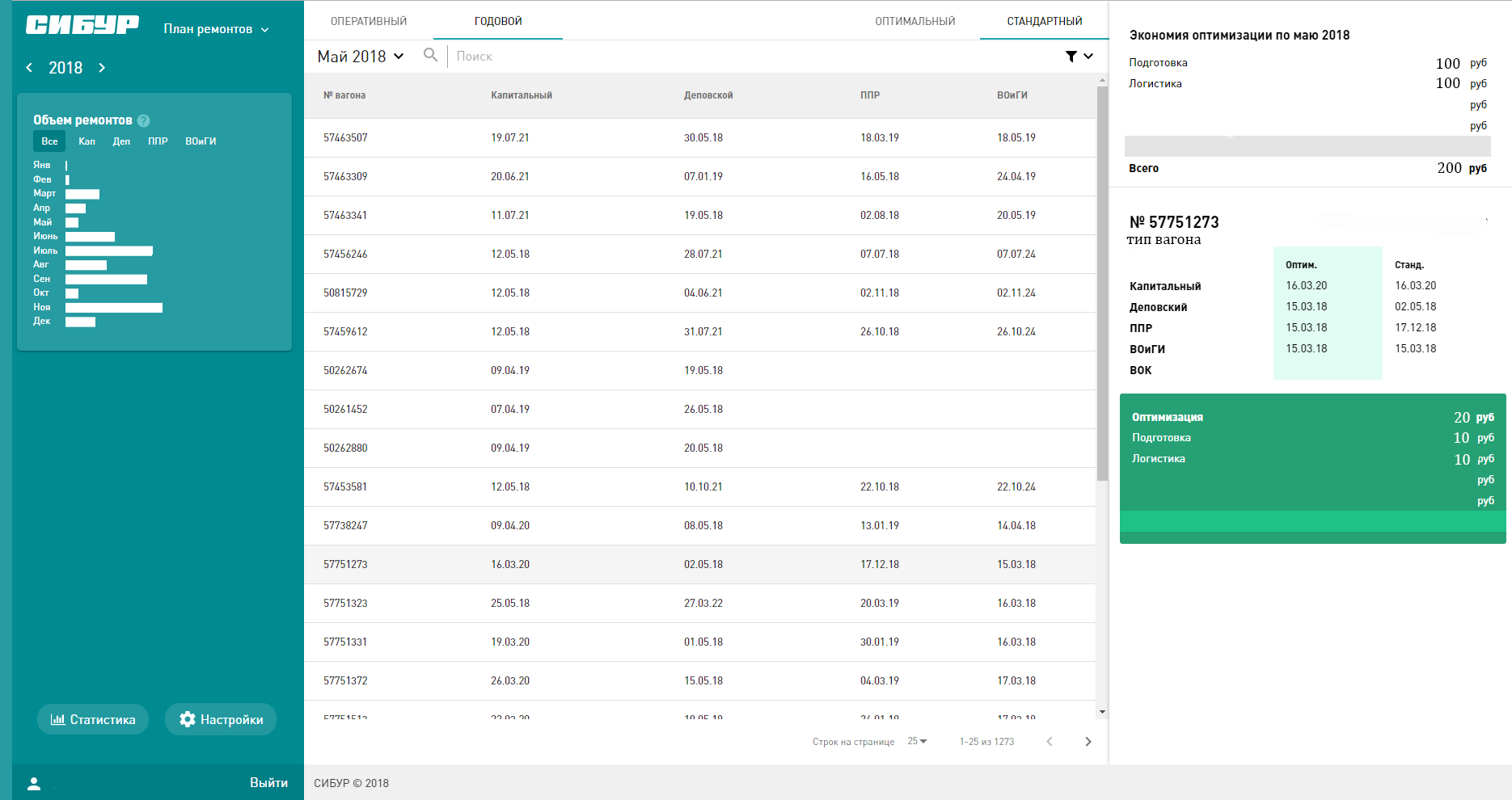
Черновые эскизы дизайнов
Участники приняли все эскизы и пожелания и ушли думать.
Пара дней прошла в формате постоянных уточнений — команды приходили к нам, показывали примерные наброски, что-то уточняли, получали ответы, уходили допиливать решение дальше.
На самом деле, со стороны организатора это выглядит очень круто — люди креативят на ходу, подстраиваясь под новые уточнённые вводные, за пару часов находя в собственном решении какие-то минусы и тут же их устраняя. Причём в формате полноценной командной работы — пока один рисует дизайн всего этого добра, дата-сайнтисты уже заканчивают писать первые скрипты.
Мы сейчас стараемся сделать так, чтобы наше цифровое подразделение работало над повседневными задачами компании в такой же атмосфере, потому что это очень захватывает.




Смотр демо и финал
Тут всё было просто и привычно. У каждой команды есть 5 минут на выступление, а у организаторов — 5 минут на вопросы. Само собой, рамки не были совсем уж жёсткими, и иногда мы выходили за это время.
На всё про всё в таком ритме мы провели часа 3.

Оценивали полученные решения комплексно — подходы к решению задачи в общем и целом, визуализацию, применимость предложений в реальности. Тут помог подход AI-community, по которому фиксировались ещё и промежуточные результаты процесса.

Победители
Главный приз (300 000 рублей) достался команде «Hack.zamAI».
Ребята создали комплексное решение, не только оптимизировав финансовые показатели, но и вписав туда кучу дополнительных плюшек, отобразив в продукте готовый бизнес-процесс.
При этом оно всё ещё и выглядит достойно и дружелюбно.
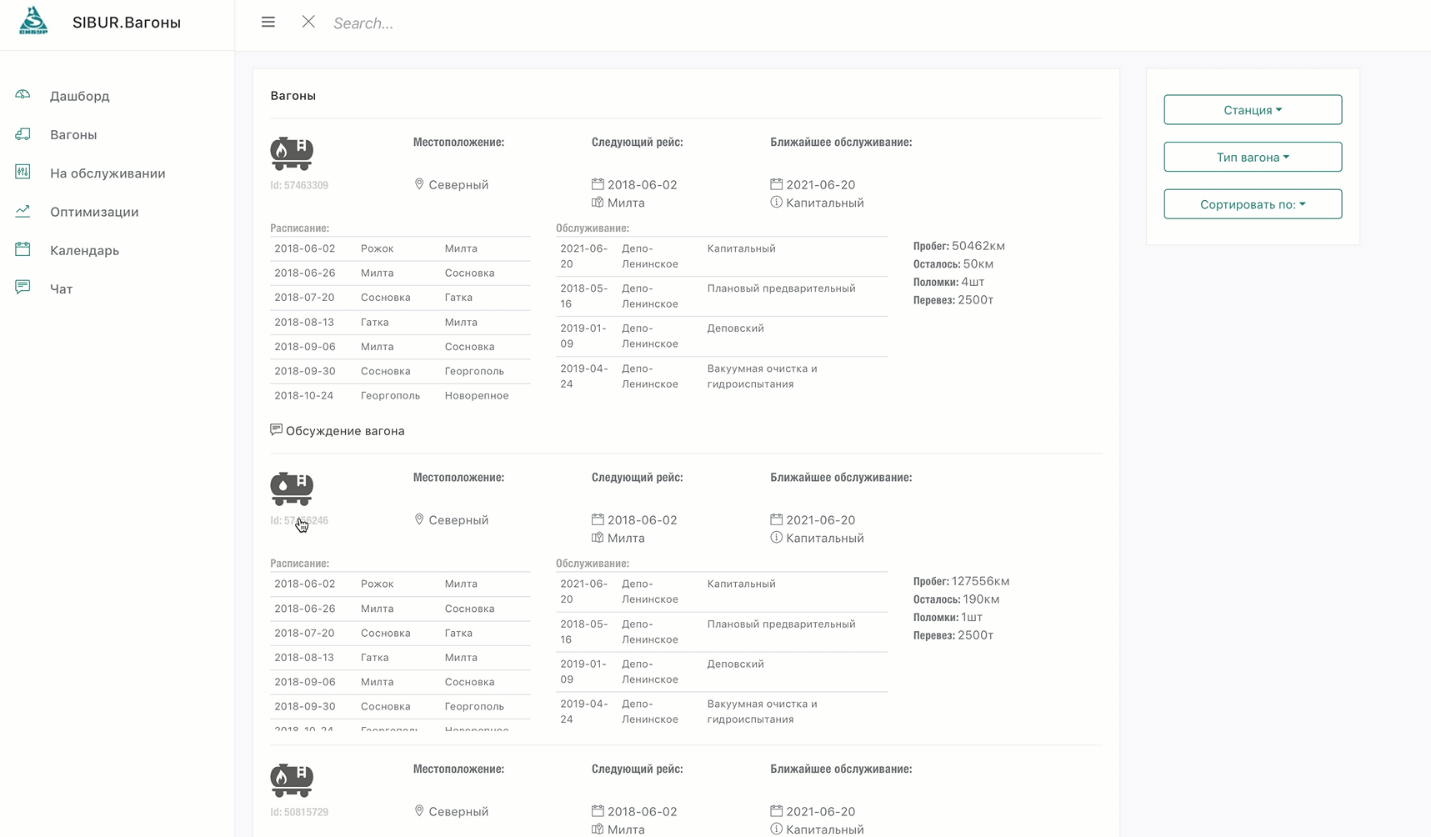
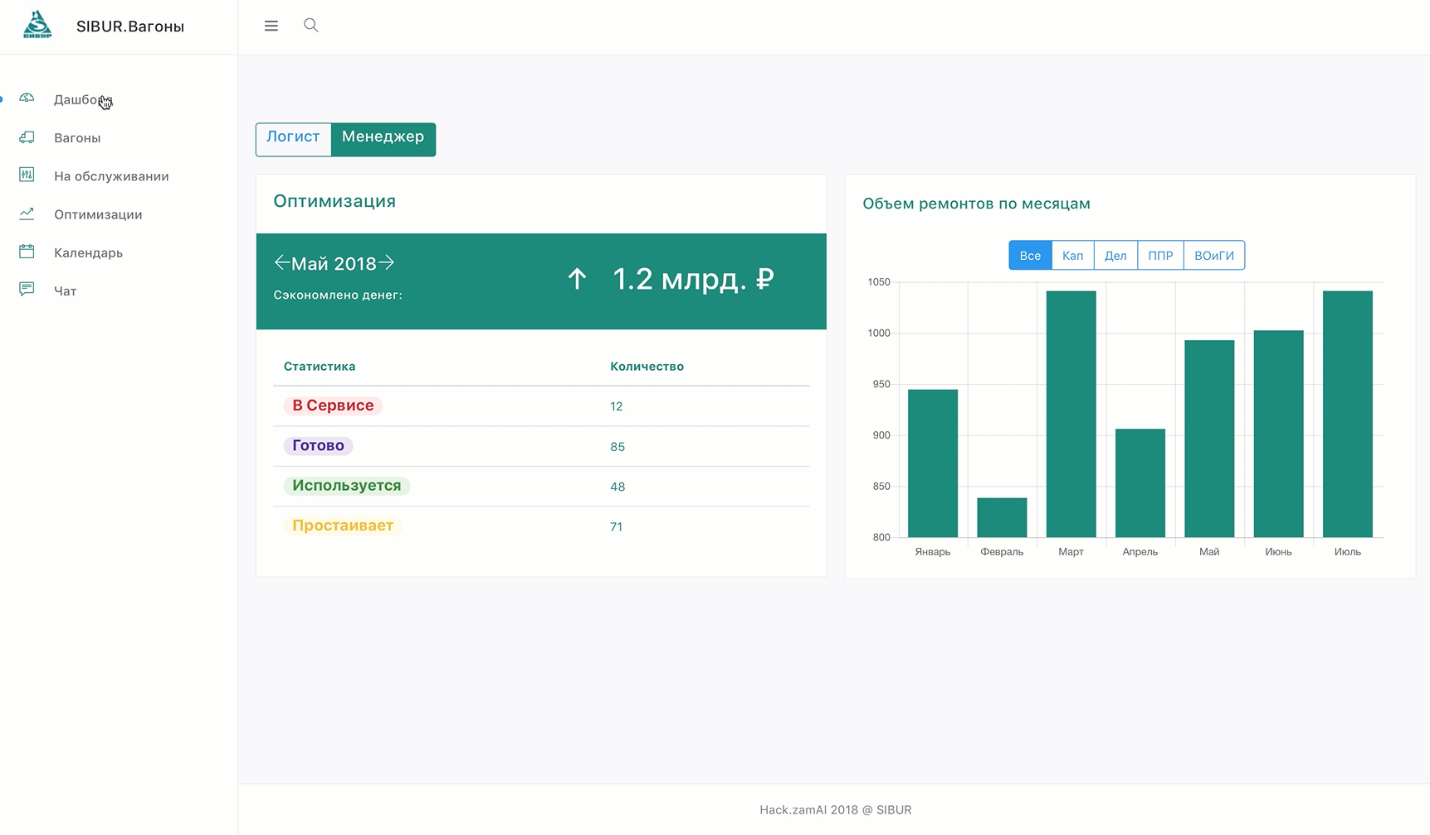

Вот тут можно посмотреть демонстрацию их решения.
(видео на GoogleDrive)
Само собой, это не последний наш хакатон.
Хотим сказать спасибо всем, кто участвовал в этом. И обязательно разместим анонс следующего.
Дмитрий Архипов, архитектор, «Цифровизация процессов», СИБУР
