Решим классическую задачу Data Science на C99 и C++11.
В то время как такие языки как Python и R становятся все более популярными для науки о данных, C и C++ могут быть сильным выбором для эффективного решения задач в Data Science. В этой статье мы будем использовать C99 и C++11 для написания программы, работающей с квартетом Энскомба, о котором я расскажу далее.
О своей мотивации к постоянному изучению языков я написал в статье, посвященной Python и GNU Octave, которую стоит прочитать. Все программы предназначены для командной строки, а не для графического интерфейса пользователя (GUI). Полные примеры доступны в репозитории polyglot_fit.
Программа, которую вы напишете в этой серии:
Это обычная задача, с которой сталкиваются многие специалисты по данным. Примером данных является первый набор квартета Энскомба, представленный в таблице ниже. Это набор искусственно сконструированных данных, которые дают одинаковые результаты при подгонке под прямую, но их графики сильно отличаются. Файл данных — это текстовый файл с табами для разделения столбцов и несколькими строками, формирующими заголовок. В этой задаче будет использоваться только первый набор (т.е. первые две колонки).
Квартет Энскомба

C — язык программирования общего назначения, который является одним из наиболее популярных языков, используемых сегодня (по данным Индекса TIOBE, рейтинга RedMonk Programming Language Rankings, Индекса популярности языков программирования, и исследованию GitHub). Это достаточно старый язык (он был создан примерно в 1973 году), и на нем было написано много успешных программ (например, ядро Linux и Git). Этот язык также максимально приближен к внутренней работе компьютера, так как используется для непосредственного управления памятью. Это компилируемый язык, поэтому исходный код должен быть транслирован компилятором в машинный код. Его стандартная библиотека небольшая и легкая по размерам, поэтому были разработаны другие библиотеки, обеспечивающие недостающие функциональные возможности.
Это язык, который я использую больше всего для числодробилки, в основном из-за его производительности. Я нахожу его довольно утомительным в использовании, так как он требует написания большого объема шаблонного кода, но он хорошо поддерживается в различных средах. Стандарт C99 — это недавняя ревизия, которая добавляет некоторые изящные возможности и хорошо поддерживается компиляторами.
Я расскажу о необходимых предпосылках программирования на С и С++, чтобы и новички, и опытные пользователи могли воспользоваться этими языками.
Для разработки на C99 нужен компилятор. Обычно я использую Clang, но подойдет и GCC – еще один полноценный компилятор с открытым исходным кодом. Для подгонки данных я решил использовать научную библиотеку GNU. Для построения графиков я не смог найти никакой разумной библиотеки, и поэтому эта программа полагается на внешнюю программу: Gnuplot. В примере также используется динамическая структура данных для хранения данных, которая определена в Дистрибутиве программ Беркли (Berkeley Software Distribution, BSD).
Установка в Fedora очень проста:
В C99 комментарии форматируются путем добавления // в начало строки, а остальная часть строки будет отброшена интерпретатором. Все, что находится между /* и */, также отбрасывается.
Библиотеки состоят из двух частей:
Заголовочные файлы включаются в исходный код, а исходный код библиотек привязываются к исполняемому файлу. Следовательно, заголовочные файлы необходимы для данного примера:
В языке Си программа должна находиться внутри специальной функции, называемой main():
Здесь можно заметить отличие от Python, о котором говорилось в последнем руководстве, потому что в случае с Python, будет выполняться любой код, который он найдет в исходных файлах.
В C переменные должны быть объявлены до их использования, и они должны быть ассоциированы с типом. Всякий раз, когда вы хотите использовать переменную, вы должны решить, какие данные в ней хранить. Вы также можете указать, собираетесь ли вы использовать переменную в качестве константного значения, что не обязательно, но компилятор может извлечь выгоду из этой информации. Пример из программы fitting_C99.c, находящейся в репозитории:
Массивы в языке С не являются динамическими в том смысле, что их длина должна быть определена заранее (т.е. до компиляции):
Так как вы обычно не знаете, сколько точек данных находится в файле, используйте односвязный список. Это динамическая структура данных, которая может расти бесконечно. К счастью, BSD предоставляет односвязные списки. Вот пример определения:
Этот пример определяет список data_point, состоящий из структурированных значений, которые содержат как значения x, так и значения y. Синтаксис довольно сложный, но интуитивно понятный, и его подробное описание было бы слишком многословным.
Для печати в терминале можно использовать функцию printf(), которая работает как функция printf() в Octave (описанная в первой статье):
Функция printf() не добавляет новую строку в конце распечатываемой строки автоматически, поэтому ее нужно добавлять собственноручно. Первый аргумент — это строка, которая может содержать информацию о формате других аргументов, которые могут быть переданы в функцию, например:
Сейчас наступает сложная часть… Есть несколько библиотек для разбора CSV-файлов на C, но ни одна из них не оказалась достаточно стабильной или популярной, чтобы находиться в репозитории пакетов Fedora. Вместо того, чтобы добавлять зависимость для этого руководства, я решил написать эту часть самостоятельно. Опять же, вдаваться в подробности было бы слишком многословно, поэтому я буду объяснять только общую идею. Некоторые строки в исходном коде будут проигнорированы для краткости, но вы можете найти полный пример в репозитории.
Сначала откройте входной файл:
Затем читайте файл построчно до тех пор, пока не произойдет ошибка или пока файл не закончится:
Функция getline() является приятным недавним дополнением из стандарта POSIX.1-2008. Она может читать целую строку в файле и заботиться о выделении необходимой памяти. Каждая строка затем разбивается на токены с помощью функции strtok(). Просматривая токен, выберите нужные вам столбцы:
Наконец, когда выбраны значения x и y, добавьте новую точку в список:
Функция malloc() динамически выделяет (резервирует) некоторый объем постоянной памяти для новой точки.
Функция линейной интерполяции из GSL gsl_fit_linear() принимает на вход обычные массивы. Поэтому, так как вы не можете заранее знать размер создаваемых массивов, необходимо вручную выделить на них память:
Затем пройдите по списку, чтобы сохранить соответствующие данные в массивах:
Теперь, когда вы закончили со списком, наведите порядок. Всегда освобождайте память, которая была выделена вручную, чтобы предотвратить утечку памяти. Утечка памяти — это плохо, плохо, и еще раз плохо. Каждый раз, когда память не освобождается, садовый гном лишается головы:
Наконец, наконец-то(!), вы можете подогнать свои данные:
Для построения графика необходимо использовать внешнюю программу. Поэтому сохраните функцию подгонки во внешнем файле:
Команда Gnuplot для построения графиков выглядит следующим образом:
Перед запуском программы необходимо ее скомпилировать:
Эта команда говорит компилятору использовать стандарт C99, прочитать файл fitting_C99.c, загрузить библиотеки gsl и gslcblas и сохранить результат в fitting_C99. Полученный результат в командной строке:
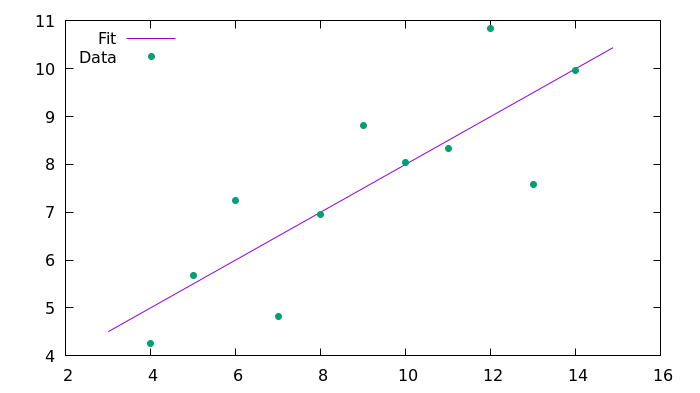
Вот результирующее изображение, сгенерированное с помощью Gnuplot.
С++ — язык программирования общего назначения, который также является одним из самых популярных языков, используемых сегодня. Он был создан как преемник языка С (в 1983 году) с акцентом на объектно-ориентированное программирование (ООП). С++ обычно считается надмножеством С, поэтому программа на С должна быть скомпилирована компилятором Си++. Это получается не всегда, так как есть некоторые краевые случаи, когда они ведут себя по-разному. По моему опыту, С++ требует меньше шаблонного кода, чем С, но его синтаксис сложнее, если вы хотите разрабатывать объекты. Стандарт C++11 — это недавняя ревизия, которая добавляет некоторые изящные возможности, которые более или менее поддерживается компиляторами.
Так как C++ в значительной степени совместим с C, я просто остановлюсь на различиях между ними. Если я не опишу какой-то раздел в этой части, это означает, что он такой же, как и в C.
Зависимости для C++ такие же, как и для примера C. На Fedora необходимо выполнить следующую команду:
Библиотеки работают так же, как и на C, но директивы include немного отличаются:
Поскольку библиотеки GSL написаны на С, компилятору необходимо сообщить об этой особенности.
C++ поддерживает больше типов (классов) данных, чем C, например, строковый тип, который имеет гораздо больше возможностей, чем его C-аналог. Обновите определение переменных соответствующим образом:
Для структурированных объектов, таких как строки, можно определить переменную без использования знака =.
Вы можете использовать функцию printf(), но более принято использовать cout. Используйте оператор << для указания строки (или объектов), которые вы хотите распечатать с помощью cout:
Схема такая же, как и раньше. Файл открывается и читается построчно, но с другим синтаксисом:
Токены строк извлекаются той же функцией, что и в примере C99. Вместо стандартных массивов из C используйте два вектора. Векторы являются расширением массивов C в стандартной библиотеке C++, позволяющим динамически управлять памятью без вызова malloc():
Для подгонки данных на С++ не нужно мучиться со списками, так как векторы гарантированно имеют последовательную память. Вы можете напрямую передать функции подгонки указатели на буферы векторов:
Построение графика делается так же, как и раньше. Запишите в файл:
А потом используйте Gnuplot для построения графика.
Перед запуском программы она должна быть скомпилирована аналогичной командой:
Результирующий вывод в командной строке:
И вот полученное изображение, сгенерированное с помощью Gnuplot.
В статье приведены примеры подгонки данных и построения графиков на C99 и C++11. Так как C++ в значительной степени совместим с C, в данной статье использовано их сходство для написания второго примера. В некоторых аспектах Си++ проще использовать, так как он частично снимает нагрузку по явному управлению памятью, но его синтаксис сложнее, так как он вводит возможность написания классов для ООП. Тем не менее, вы можете писать и на C с использованием методов ООП, так как ООП — это стиль программирования, его можно использовать на любом языке. Есть несколько замечательных примеров ООП на Си, таких как библиотеки GObject и Jansson.
Для работы с числами я предпочитаю использовать C99 из-за его более простого синтаксиса и широкой поддержки. До недавнего времени С++11 не так широко поддерживался, и я старался избегать шероховатостей в предыдущих версиях. Для более сложного программного обеспечения, C++ может быть хорошим выбором.
Вы используете С или С++ для Data Science? Поделитесь своим опытом в комментариях.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
В то время как такие языки как Python и R становятся все более популярными для науки о данных, C и C++ могут быть сильным выбором для эффективного решения задач в Data Science. В этой статье мы будем использовать C99 и C++11 для написания программы, работающей с квартетом Энскомба, о котором я расскажу далее.
О своей мотивации к постоянному изучению языков я написал в статье, посвященной Python и GNU Octave, которую стоит прочитать. Все программы предназначены для командной строки, а не для графического интерфейса пользователя (GUI). Полные примеры доступны в репозитории polyglot_fit.
Задача по программированию
Программа, которую вы напишете в этой серии:
- Считывает данные из CSV-файла
- Интерполирует данные прямой линией (т.е., f(x)=m ⋅ x + q).
- Записывает результат в файл изображения
Это обычная задача, с которой сталкиваются многие специалисты по данным. Примером данных является первый набор квартета Энскомба, представленный в таблице ниже. Это набор искусственно сконструированных данных, которые дают одинаковые результаты при подгонке под прямую, но их графики сильно отличаются. Файл данных — это текстовый файл с табами для разделения столбцов и несколькими строками, формирующими заголовок. В этой задаче будет использоваться только первый набор (т.е. первые две колонки).
Квартет Энскомба
Способ решения на С
C — язык программирования общего назначения, который является одним из наиболее популярных языков, используемых сегодня (по данным Индекса TIOBE, рейтинга RedMonk Programming Language Rankings, Индекса популярности языков программирования, и исследованию GitHub). Это достаточно старый язык (он был создан примерно в 1973 году), и на нем было написано много успешных программ (например, ядро Linux и Git). Этот язык также максимально приближен к внутренней работе компьютера, так как используется для непосредственного управления памятью. Это компилируемый язык, поэтому исходный код должен быть транслирован компилятором в машинный код. Его стандартная библиотека небольшая и легкая по размерам, поэтому были разработаны другие библиотеки, обеспечивающие недостающие функциональные возможности.
Это язык, который я использую больше всего для числодробилки, в основном из-за его производительности. Я нахожу его довольно утомительным в использовании, так как он требует написания большого объема шаблонного кода, но он хорошо поддерживается в различных средах. Стандарт C99 — это недавняя ревизия, которая добавляет некоторые изящные возможности и хорошо поддерживается компиляторами.
Я расскажу о необходимых предпосылках программирования на С и С++, чтобы и новички, и опытные пользователи могли воспользоваться этими языками.
Установка
Для разработки на C99 нужен компилятор. Обычно я использую Clang, но подойдет и GCC – еще один полноценный компилятор с открытым исходным кодом. Для подгонки данных я решил использовать научную библиотеку GNU. Для построения графиков я не смог найти никакой разумной библиотеки, и поэтому эта программа полагается на внешнюю программу: Gnuplot. В примере также используется динамическая структура данных для хранения данных, которая определена в Дистрибутиве программ Беркли (Berkeley Software Distribution, BSD).
Установка в Fedora очень проста:
sudo dnf install clang gnuplot gsl gsl-develКомментарии к коду
В C99 комментарии форматируются путем добавления // в начало строки, а остальная часть строки будет отброшена интерпретатором. Все, что находится между /* и */, также отбрасывается.
// Компилятор проигнорирует этот комментарий.
/* И этот тоже проигнорирует */Необходимые библиотеки
Библиотеки состоят из двух частей:
- Заголовочный файл, содержащий описание функций
- Исходный файл, содержащий определения функций
Заголовочные файлы включаются в исходный код, а исходный код библиотек привязываются к исполняемому файлу. Следовательно, заголовочные файлы необходимы для данного примера:
// Инструменты ввода-вывода
#include <stdio.h>
// Стандартная библиотека
#include <stdlib.h>
// Инструменты для работы с строками
#include <string.h>
// Структура данных "очередь" от BSD
#include <sys/queue.h>
// Научные инструменты GSL
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>Функция Main
В языке Си программа должна находиться внутри специальной функции, называемой main():
int main(void) {
...
}Здесь можно заметить отличие от Python, о котором говорилось в последнем руководстве, потому что в случае с Python, будет выполняться любой код, который он найдет в исходных файлах.
Определение переменных
В C переменные должны быть объявлены до их использования, и они должны быть ассоциированы с типом. Всякий раз, когда вы хотите использовать переменную, вы должны решить, какие данные в ней хранить. Вы также можете указать, собираетесь ли вы использовать переменную в качестве константного значения, что не обязательно, но компилятор может извлечь выгоду из этой информации. Пример из программы fitting_C99.c, находящейся в репозитории:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;Массивы в языке С не являются динамическими в том смысле, что их длина должна быть определена заранее (т.е. до компиляции):
int data_array[1024];Так как вы обычно не знаете, сколько точек данных находится в файле, используйте односвязный список. Это динамическая структура данных, которая может расти бесконечно. К счастью, BSD предоставляет односвязные списки. Вот пример определения:
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);Этот пример определяет список data_point, состоящий из структурированных значений, которые содержат как значения x, так и значения y. Синтаксис довольно сложный, но интуитивно понятный, и его подробное описание было бы слишком многословным.
Вывод на печать
Для печати в терминале можно использовать функцию printf(), которая работает как функция printf() в Octave (описанная в первой статье):
printf("#### Первый набор квартета Энскомба на C99 ####\n");Функция printf() не добавляет новую строку в конце распечатываемой строки автоматически, поэтому ее нужно добавлять собственноручно. Первый аргумент — это строка, которая может содержать информацию о формате других аргументов, которые могут быть переданы в функцию, например:
printf("Slope: %f\n", slope);Чтение данных
Сейчас наступает сложная часть… Есть несколько библиотек для разбора CSV-файлов на C, но ни одна из них не оказалась достаточно стабильной или популярной, чтобы находиться в репозитории пакетов Fedora. Вместо того, чтобы добавлять зависимость для этого руководства, я решил написать эту часть самостоятельно. Опять же, вдаваться в подробности было бы слишком многословно, поэтому я буду объяснять только общую идею. Некоторые строки в исходном коде будут проигнорированы для краткости, но вы можете найти полный пример в репозитории.
Сначала откройте входной файл:
FILE* input_file = fopen(input_file_name, "r");Затем читайте файл построчно до тех пор, пока не произойдет ошибка или пока файл не закончится:
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}Функция getline() является приятным недавним дополнением из стандарта POSIX.1-2008. Она может читать целую строку в файле и заботиться о выделении необходимой памяти. Каждая строка затем разбивается на токены с помощью функции strtok(). Просматривая токен, выберите нужные вам столбцы:
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}Наконец, когда выбраны значения x и y, добавьте новую точку в список:
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);Функция malloc() динамически выделяет (резервирует) некоторый объем постоянной памяти для новой точки.
Подгонка данных
Функция линейной интерполяции из GSL gsl_fit_linear() принимает на вход обычные массивы. Поэтому, так как вы не можете заранее знать размер создаваемых массивов, необходимо вручную выделить на них память:
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);Затем пройдите по списку, чтобы сохранить соответствующие данные в массивах:
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}Теперь, когда вы закончили со списком, наведите порядок. Всегда освобождайте память, которая была выделена вручную, чтобы предотвратить утечку памяти. Утечка памяти — это плохо, плохо, и еще раз плохо. Каждый раз, когда память не освобождается, садовый гном лишается головы:
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}Наконец, наконец-то(!), вы можете подогнать свои данные:
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);Построение графика
Для построения графика необходимо использовать внешнюю программу. Поэтому сохраните функцию подгонки во внешнем файле:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}Команда Gnuplot для построения графиков выглядит следующим образом:
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'Результаты
Перед запуском программы необходимо ее скомпилировать:
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99Эта команда говорит компилятору использовать стандарт C99, прочитать файл fitting_C99.c, загрузить библиотеки gsl и gslcblas и сохранить результат в fitting_C99. Полученный результат в командной строке:
#### Первый набор квартета Энскомба на C99 ####
Угловой коэффициент: 0.500091
Пересечение: 3.000091
Коэффициент корреляции: 0.816421Вот результирующее изображение, сгенерированное с помощью Gnuplot.
Способ решения на С++11
С++ — язык программирования общего назначения, который также является одним из самых популярных языков, используемых сегодня. Он был создан как преемник языка С (в 1983 году) с акцентом на объектно-ориентированное программирование (ООП). С++ обычно считается надмножеством С, поэтому программа на С должна быть скомпилирована компилятором Си++. Это получается не всегда, так как есть некоторые краевые случаи, когда они ведут себя по-разному. По моему опыту, С++ требует меньше шаблонного кода, чем С, но его синтаксис сложнее, если вы хотите разрабатывать объекты. Стандарт C++11 — это недавняя ревизия, которая добавляет некоторые изящные возможности, которые более или менее поддерживается компиляторами.
Так как C++ в значительной степени совместим с C, я просто остановлюсь на различиях между ними. Если я не опишу какой-то раздел в этой части, это означает, что он такой же, как и в C.
Установка
Зависимости для C++ такие же, как и для примера C. На Fedora необходимо выполнить следующую команду:
sudo dnf install clang gnuplot gsl gsl-develНеобходимые библиотеки
Библиотеки работают так же, как и на C, но директивы include немного отличаются:
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}Поскольку библиотеки GSL написаны на С, компилятору необходимо сообщить об этой особенности.
Определение переменных
C++ поддерживает больше типов (классов) данных, чем C, например, строковый тип, который имеет гораздо больше возможностей, чем его C-аналог. Обновите определение переменных соответствующим образом:
const std::string input_file_name("anscombe.csv");Для структурированных объектов, таких как строки, можно определить переменную без использования знака =.
Вывод на печать
Вы можете использовать функцию printf(), но более принято использовать cout. Используйте оператор << для указания строки (или объектов), которые вы хотите распечатать с помощью cout:
std::cout << "#### Первый набор квартета Энскомба на C++11 ####" << std::endl;
...
std::cout << "Угловой коэффициент: " << slope << std::endl;
std::cout << "Пересечение: " << intercept << std::endl;
std::cout << "Коэффициент корреляции: " << r_value << std::endl;Чтение данных
Схема такая же, как и раньше. Файл открывается и читается построчно, но с другим синтаксисом:
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}Токены строк извлекаются той же функцией, что и в примере C99. Вместо стандартных массивов из C используйте два вектора. Векторы являются расширением массивов C в стандартной библиотеке C++, позволяющим динамически управлять памятью без вызова malloc():
std::vector<double> x;
std::vector<double> y;
// Добавляем элементы в x и y
x.emplace_back(value);
y.emplace_back(value);Подгонка данных
Для подгонки данных на С++ не нужно мучиться со списками, так как векторы гарантированно имеют последовательную память. Вы можете напрямую передать функции подгонки указатели на буферы векторов:
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << "Угловой коэффициент: " << slope << std::endl;
std::cout << "Пересечение: " << intercept << std::endl;
std::cout << "Коэффициент корреляции: " << r_value << std::endl;Построение графика
Построение графика делается так же, как и раньше. Запишите в файл:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();А потом используйте Gnuplot для построения графика.
Результаты
Перед запуском программы она должна быть скомпилирована аналогичной командой:
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11Результирующий вывод в командной строке:
#### Первый набор квартета Энскомба на C++11 ####
Угловой Коэффициент: 0.500091
Пересечение: 3.00009
Коэффициент корреляции: 0.816421И вот полученное изображение, сгенерированное с помощью Gnuplot.
Заключение
В статье приведены примеры подгонки данных и построения графиков на C99 и C++11. Так как C++ в значительной степени совместим с C, в данной статье использовано их сходство для написания второго примера. В некоторых аспектах Си++ проще использовать, так как он частично снимает нагрузку по явному управлению памятью, но его синтаксис сложнее, так как он вводит возможность написания классов для ООП. Тем не менее, вы можете писать и на C с использованием методов ООП, так как ООП — это стиль программирования, его можно использовать на любом языке. Есть несколько замечательных примеров ООП на Си, таких как библиотеки GObject и Jansson.
Для работы с числами я предпочитаю использовать C99 из-за его более простого синтаксиса и широкой поддержки. До недавнего времени С++11 не так широко поддерживался, и я старался избегать шероховатостей в предыдущих версиях. Для более сложного программного обеспечения, C++ может быть хорошим выбором.
Вы используете С или С++ для Data Science? Поделитесь своим опытом в комментариях.
Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
- Курс по Machine Learning (12 недель)
- Обучение профессии Data Science с нуля (12 месяцев)
- Профессия аналитика с любым стартовым уровнем (9 месяцев)
- Курс «Python для веб-разработки» (9 месяцев)
Читать еще
- Тренды в Data Scienсe 2020
- Data Science умерла. Да здравствует Business Science
- Крутые Data Scientist не тратят время на статистику
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Data Science для гуманитариев: что такое «data»
- Data Scienсe на стероидах: знакомство с Decision Intelligence
