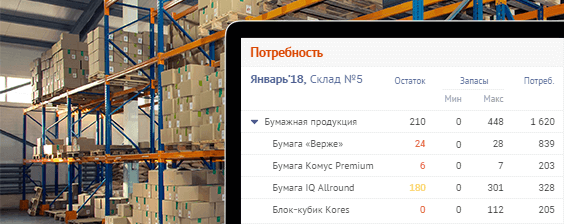
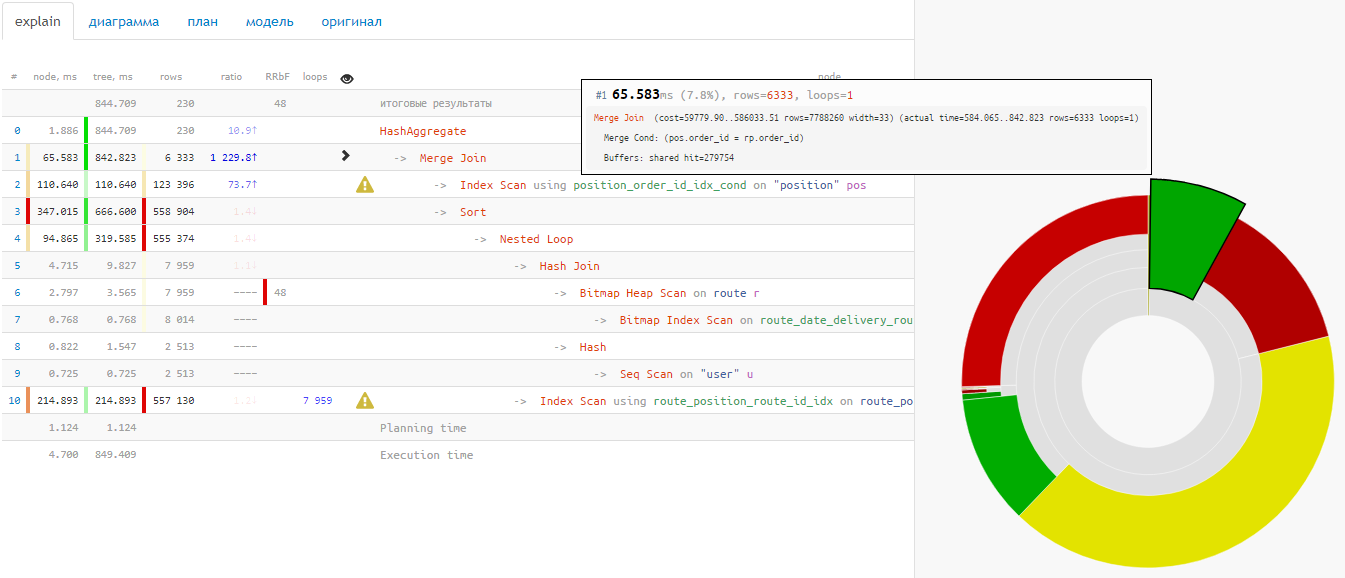
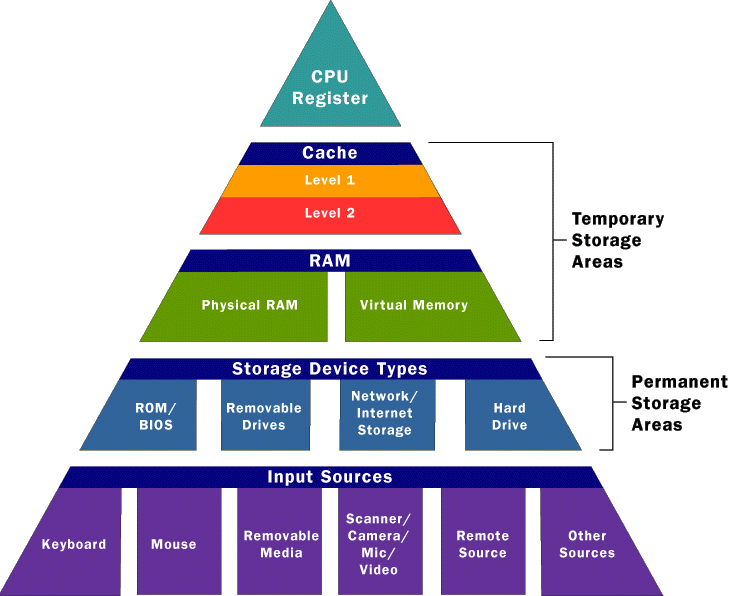
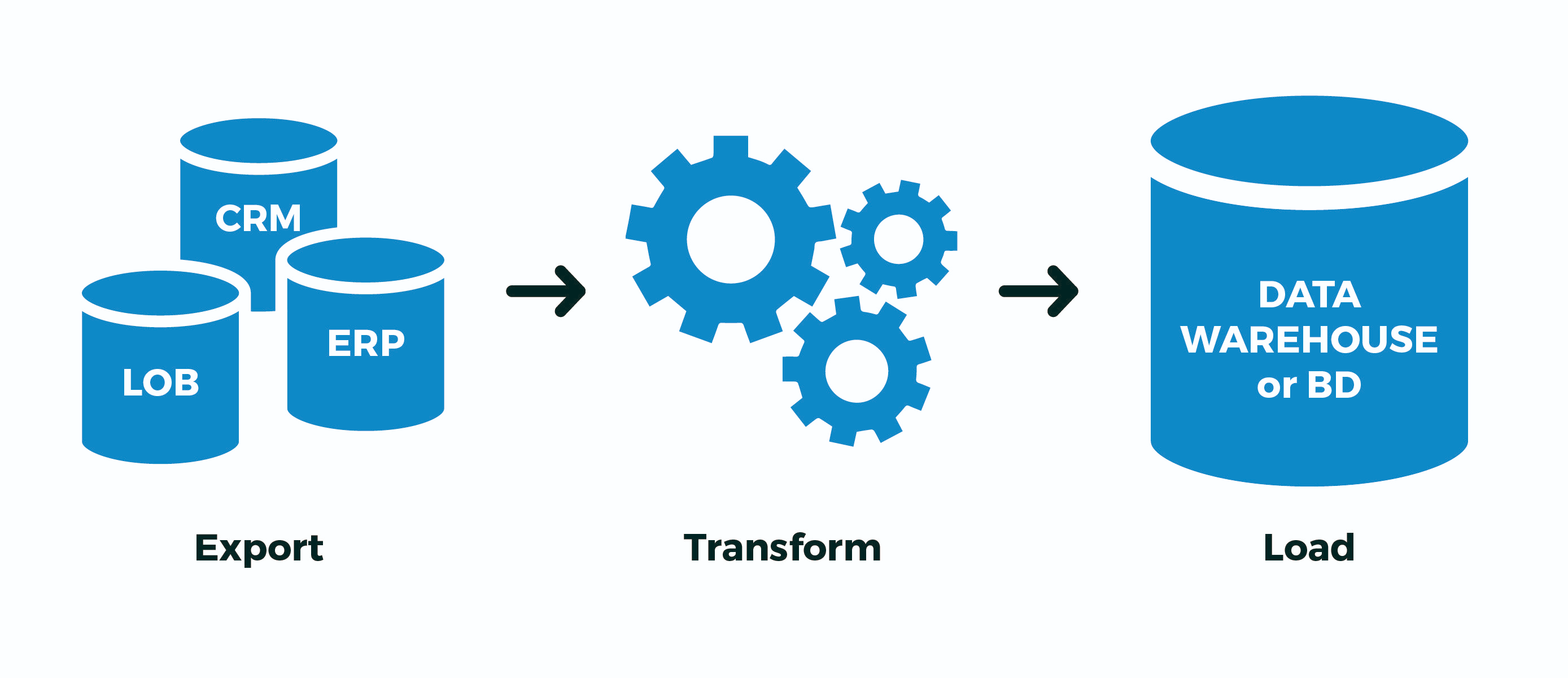
Некоторые ситуации в работе PostgreSQL кажутся неочевидными, пока не попытаешься детально понять, «почему это работает так». Из-за незнания таких особенностей иногда разработчик сам провоцирует проблемы для нормальной работы своего приложения в будущем.
Сегодня разберем пару примеров, как неудачная организация БД и кода могут превратить наше приложение в клубок проблем:

Сегодня разберем пару примеров, как неудачная организация БД и кода могут превратить наше приложение в клубок проблем:
- накрутка
serialприON CONFLICT - накрутка счетчика транзакций