

Привет, я Тони Альбрехт (Tony Albrecht), инженер в Riot. Мне нравится профилировать и оптимизировать. В этой статье я расскажу об основах профилирования, а также проанализирую пример С++-кода в ходе его профилирования на Windows-машине. Мы начнём с самого простого и будем постепенно углубляться в потроха центрального процессора. Когда нам встретятся возможности оптимизировать — мы внедрим изменения, а в следующей статье разберём реальные примеры из кодовой базы игры League of Legends. Поехали!
Обзор кода
Сначала взглянем на код, который собираемся профилировать. Наша программа — это простой маленький OpenGL-рендерер, объектно ориентированное, иерархические дерево сцены (scene tree). Я находчиво назвал основной объект Object’ом — всё в сцене наследуется от одного из этих базовых классов. В нашем коде от Object’а наследуются лишь Node, Cube и Modifier.
Cube — это Object, который рендерит себя на экране в виде куба. Modifier — это Object, который «живёт» в дереве сцены и, будучи Updated, преобразует добавленные нему Object’ы. Node — это Object, который может содержать другие Object’ы.
Система спроектирована так, что вы можете создавать иерархию объектов, добавляя кубики в ноды, а также одни ноды к другим нодам. Если вы преобразуете ноду (посредством модификатора), то будут преобразованы и все содержащиеся в ноде объекты. С помощью этой простой системы я создал дерево из кубов, вращающихся друг вокруг друга.

Согласен, предложенный код — не лучшая реализация дерева сцены, но ничего страшного: этот код нужен именно для последующей оптимизации. По сути, это прямое портирование примера для PlayStation3®, который я написал в 2009-м для анализа производительности в работе Pitfalls of Object Oriented Programming. Можно отчасти сравнить нашу сегодняшнюю статью со статьёй 9-летней давности и посмотреть, применимы ли к современным аппаратным платформам те уроки, что мы извлекли когда-то для PS3.
Но вернёмся к нашим кубикам. На приведённой выше гифке показаны около 55 тысяч вращающихся кубиков. Обратите внимание, что я профилирую не рендеринг сцены, а только анимацию и отбрасывание (culling) при передаче на рендеринг. Библиотеки, задействованные для создания примера: Dear Imgui и Vectormath от Bullet, обе бесплатны. Для профилирования я использовал AMD Code XL и простой контрольно-измерительный (instrumented) профилировщик, на скорую руку сооружённый для этой статьи.
Прежде чем переходить к делу
Единицы измерения
Сначала я хочу обсудить измерение производительности. Зачастую в играх в качестве метрики используются кадры в секунду (FPS). Это неплохой индикатор производительности, однако он бесполезен при анализе частей кадра или сравнении улучшений от разных оптимизаций. Допустим, «игра теперь работает на 20 кадров в секунду быстрее!» — это вообще насколько быстрее?
Зависит от ситуации. Если у нас было 60 FPS (или 1000/60 = 16,666 миллисекунд на кадр), а теперь стало 80 FPS (1000/80 = 12,5 мс на кадр), то наше улучшение равно 16,666 мс – 12,5 мс = 4,166 мс на кадр. Это хороший прирост.
Но если у нас было 20 FPS, а теперь стало 40 FPS, то улучшение уже равно (1000/20 – 1000/40) = 50 мс – 25 мс = 25 мс на кадр! Это мощный прирост производительности, который может превратить игру из «неиграбельной» в «приемлемую». Проблема метрики FPS в том, что она относительна, так что мы будем всегда использовать миллисекунды. Всегда.
Проведение замеров
Существует несколько типов профилировщиков, каждый со своими достоинствами и недостатками.
Контрольно-измерительные профилировщики
Для контрольно-измерительных (instrumented) профилировщиков программист должен вручную пометить фрагмент кода, производительность которого нужно измерить. Эти профилировщики засекают и сохраняют время начала и окончания работы профилируемого фрагмента, ориентируясь на уникальные маркеры. Например:
void Node::Update()
{
FT_PROFILE_FN
for(Object* obj : mObjects)
{
obj->Update();
}
}В данном случае FT_PROFILE_FN создаёт объект, фиксирующий время своего создания, а затем и уничтожения при выпадении из области видимости. Эти моменты времени вместе с именем функции хранятся в каком-нибудь массиве для последующего анализа и визуализации. Если постараться, то можно реализовать визуализацию в коде или — чуть проще — в инструменте вроде Chrome tracing.
Контрольно-измерительное профилирование великолепно подходит для визуального отображения производительности кода и выявления её всплесков. Если характеристики производительности приложения представить в виде иерархии, то можно сразу увидеть, какие функции в целом работают медленнее всего, какие вызывают больше всего других функций, у каких больше всего варьируется длительность исполнения и т. д.
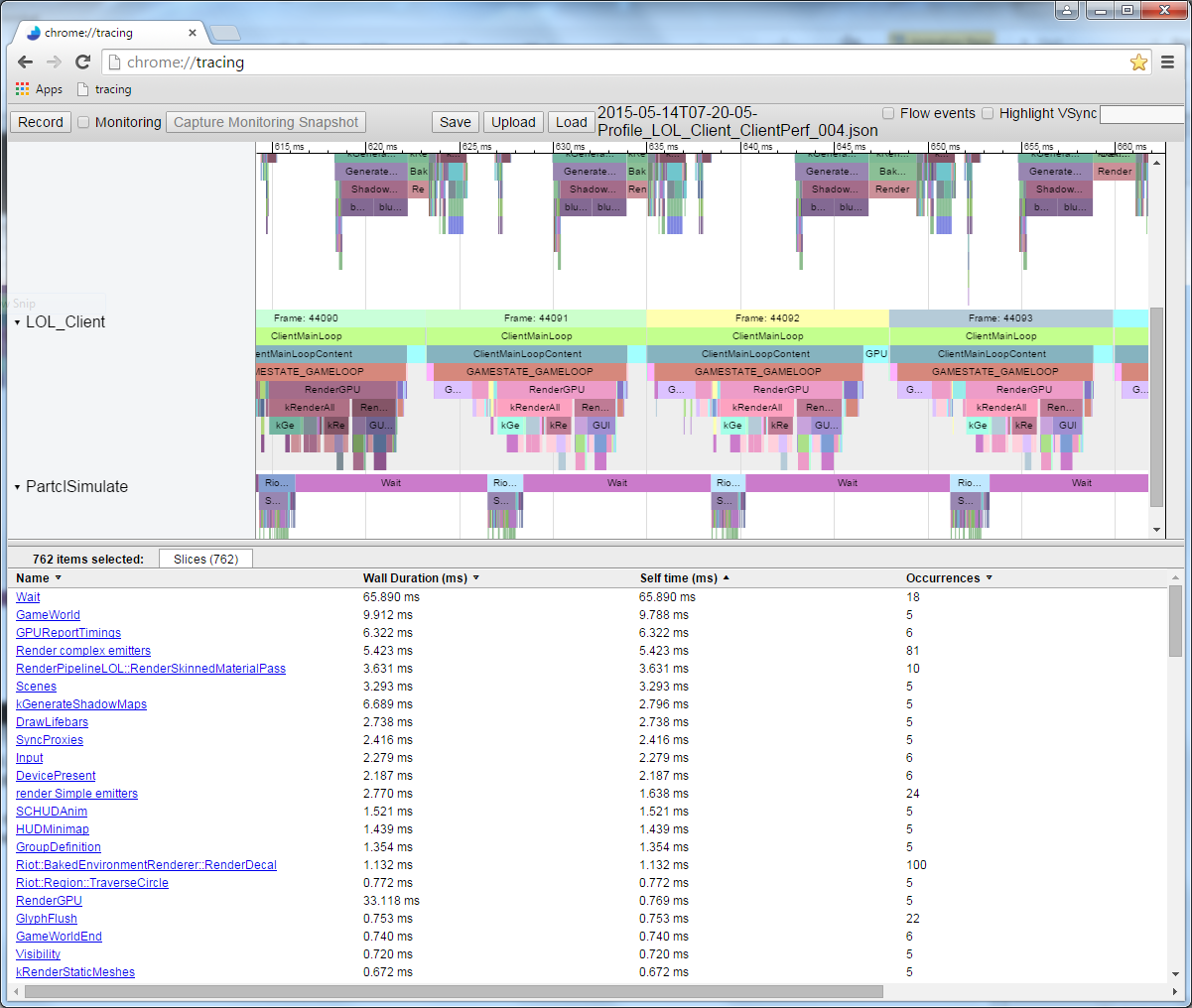
На этой иллюстрации каждая цветная плашка соответствует какой-то функции. Плашки, расположенные непосредственно под другими плашками, обозначают функции, которые вызываются «вышерасположенными» функциями. Длина плашки пропорциональна длительности исполнения функции.
Хотя контрольно-измерительное профилирование даёт ценную визуальную информацию, у него всё же есть недостатки. Оно замедляет исполнение программы: чем больше вы измеряете, тем медленнее становится программа. Поэтому при написании контрольно-измерительного профилировщика постарайтесь минимизировать его влияние на производительность приложения. Если пропустите медленную функцию, то появится большой разрыв в профиле. Также вы не получите информацию о скорости работы каждой строки кода: достаточно легко можно помечать лишь области видимости, но накладные расходы контрольно-измерительного профилирования обычно сводят на нет вклад отдельных строк, так что измерять их просто бесполезно.
Семплирующие профилировщики
Семплирующие (sampling) профилировщики запрашивают состояние исполнения того процесса, который вы хотите профилировать. Они периодически сохраняют счётчик программы (Program Counter, PC), показывающий, какая инструкция сейчас исполняется, а также сохраняют стек, благодаря чему можно узнать, какие функции вызвала та функция, что содержит текущую инструкцию. Вся эта информация полезна, поскольку функция или строки с наибольшим количеством семплов окажутся самой медленной функцией или строками. Чем дольше работает семплирующий профилировщик, тем больше собирается семплов инструкций и стеков, что улучшает результаты.
Семплирующие профилировщики позволяют собирать очень низкоуровневые характеристики производительности программы и не требуют ручного вмешательства, как в случае с контрольно-измерительными профилировщиками. Кроме того, они автоматически покрывают всё состояние исполнения вашей программы. У этих профилировщиков есть два основных недостатка: они не слишком полезны для определения всплесков по каждому кадру, а также не позволяют узнать, когда была вызвана определённая функция относительно других функций. То есть мы получаем меньше информации об иерархических вызовах по сравнению с хорошим контрольно-измерительным профилировщиком.
Специализированные профилировщики
Эти профилировщики предоставляют специфическую информацию о процессах. Обычно они связаны с аппаратными элементами вроде центрального процессора или видеокарты, которые способны генерировать конкретные события, если происходит что-то вас интересующее, к примеру промах кеша или ошибочное предсказание ветвления. Производители оборудования встраивают возможность измерения этих событий, чтобы нам легче было выяснять причины низкой производительности; следовательно, для понимания этих профилей нужны знания об используемой аппаратной части.
Профилировщики, предназначенные для конкретных игр
На гораздо более общем уровне профилировщики, предназначенные для конкретных игр, могут подсчитывать, скажем, количество миньонов на экране или количество видимых частиц в поле зрения персонажа. Такие профилировщики тоже очень полезны, они помогут выявить высокоуровневые ошибки в игровой логике.
Профилирование
Профилирование приложения без сравнительного эталона не имеет смысла, поэтому при оптимизации необходимо иметь под рукой надёжный тестовый сценарий. Это не так просто, как кажется. Современные компьютеры выполняют не одно лишь ваше приложение, а одновременно десятки, если не сотни других процессов, постоянно переключаясь между ними. То есть другие процессы могут замедлить профилируемый вами процесс в результате конкуренции за обращение к устройствам (например, несколько процессов пытаются считать с диска) или за ресурсы процессора/видеокарты. Так что для получения хорошей отправной точки вам нужно прогнать код через несколько операций профилирования, прежде чем вы хотя бы приступите к задаче. Если результаты прогонов будут сильно различаться, то придётся разобраться в причинах и избавиться от вариативности или хотя бы снизить её.
Добившись наименьшего возможного разброса результатов, не забывайте, что небольшие улучшения (меньше имеющейся вариативности) будет трудно измерить, потому что они могут затеряться в «шуме» системы. Допустим, конкретная сцена в игре отображается в диапазоне 14—18 мс на кадр, в среднем это 16 мс. Вы потратили две недели на оптимизацию какой-нибудь функции, перепрофилировали и получили 15,5 мс на кадр. Стало ли быстрее? Чтобы выяснить точно, вам придётся прогнать игру много раз, профилируя эту сцену и вычисляя среднеарифметическое значение и строя график тренда. В описанном здесь приложении мы измеряем сотни кадров и усредняем результаты, чтобы получить достаточно надёжное значение.
Кроме того, многие игры выполняются в несколько потоков, порядок которых определяется вашим оборудованием и ОС, что может привести к недетерминированному поведению или как минимум к разной длительности исполнения. Не забывайте о влиянии этих факторов.
В связи со сказанным я собрал небольшой тестовый сценарий для профилирования и оптимизации. Он прост для понимания, но достаточно сложен, чтобы иметь ресурс значительного улучшения производительности. Обратите внимание, что ради упрощения я при профилировании отключил рендеринг, так что мы видим только те вычислительные расходы, что связаны с центральным процессором.
Профилируем код
Ниже приведён код, который мы будем оптимизировать. Помните, что один пример лишь научит нас профилированию. Вы обязательно столкнётесь с неожиданными трудностями при профилировании собственного кода, и я надеюсь, что эта статья поможет вам создать собственный диагностический фреймворк.
{
FT_PROFILE("Update");
mRootNode->Update();
}
{
FT_PROFILE("GetWBS");
BoundingSphere totalVolume = mRootNode->GetWorldBoundingSphere(Matrix4::identity());
}
{
FT_PROFILE("cull");
uint8_t clipFlags = 63;
mRootNode->Cull(clipFlags);
}
{
FT_PROFILE("Node Render");
mRootNode->Render(mvp);
}Я добавил в разные области видимости контрольный макрос FT_PROFILE(), чтобы измерять длительность исполнения разных частей кода. Ниже мы подробнее поговорим о назначении каждого фрагмента.
Когда я выполнил код и записал данные из измеренного профиля, то получил в Chrome://tracing такую картину:

Это профиль одного кадра. Здесь мы видим относительную длительность работы каждого вызова функции. Обратите внимание, что можно посмотреть и порядок выполнения. Если бы я измерил функции, которые вызываются этими вызовами функций, то они отобразились бы под плашками родительских функций. К примеру, я измерил Node::Update() и получил такую рекурсивную структуру вызовов:
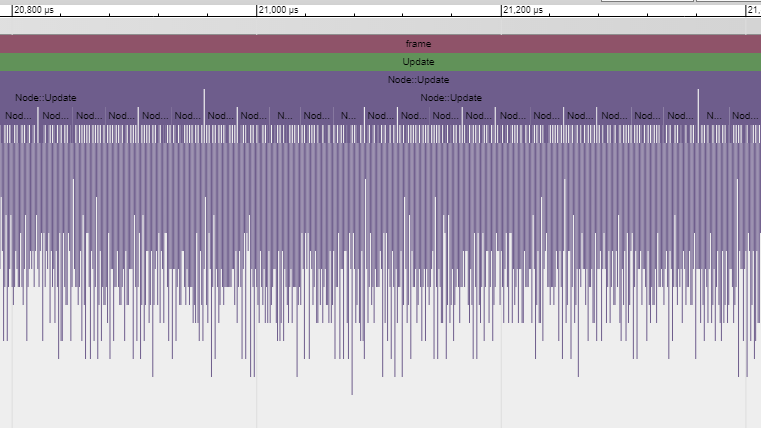
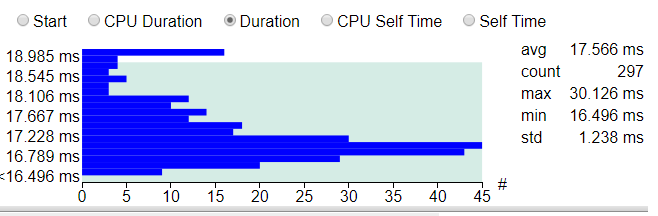
Длительность исполнения одного кадра этого кода при измерении различается на пару миллисекунд, так что мы берём среднеарифметическое как минимум по нескольким сотням кадров и сравниваем с исходным эталоном. В данном случае измерено 297 кадров, среднее значение — 17,5 мс, одни кадры выполнялись до 19 мс, а другие — чуть меньше 16,5 мс, хотя в каждом из них выполняется практически одно и то же. Такова неявная вариативность кадров. Многократный прогон и сравнение результатов устойчиво дают нам около 17,5 мс, так что это значение можно считать надёжной исходной точкой.
Если отключить в коде контрольные метки и прогнать его через семплирующий профилировщик AMD CodeXL, то получим такую картину:
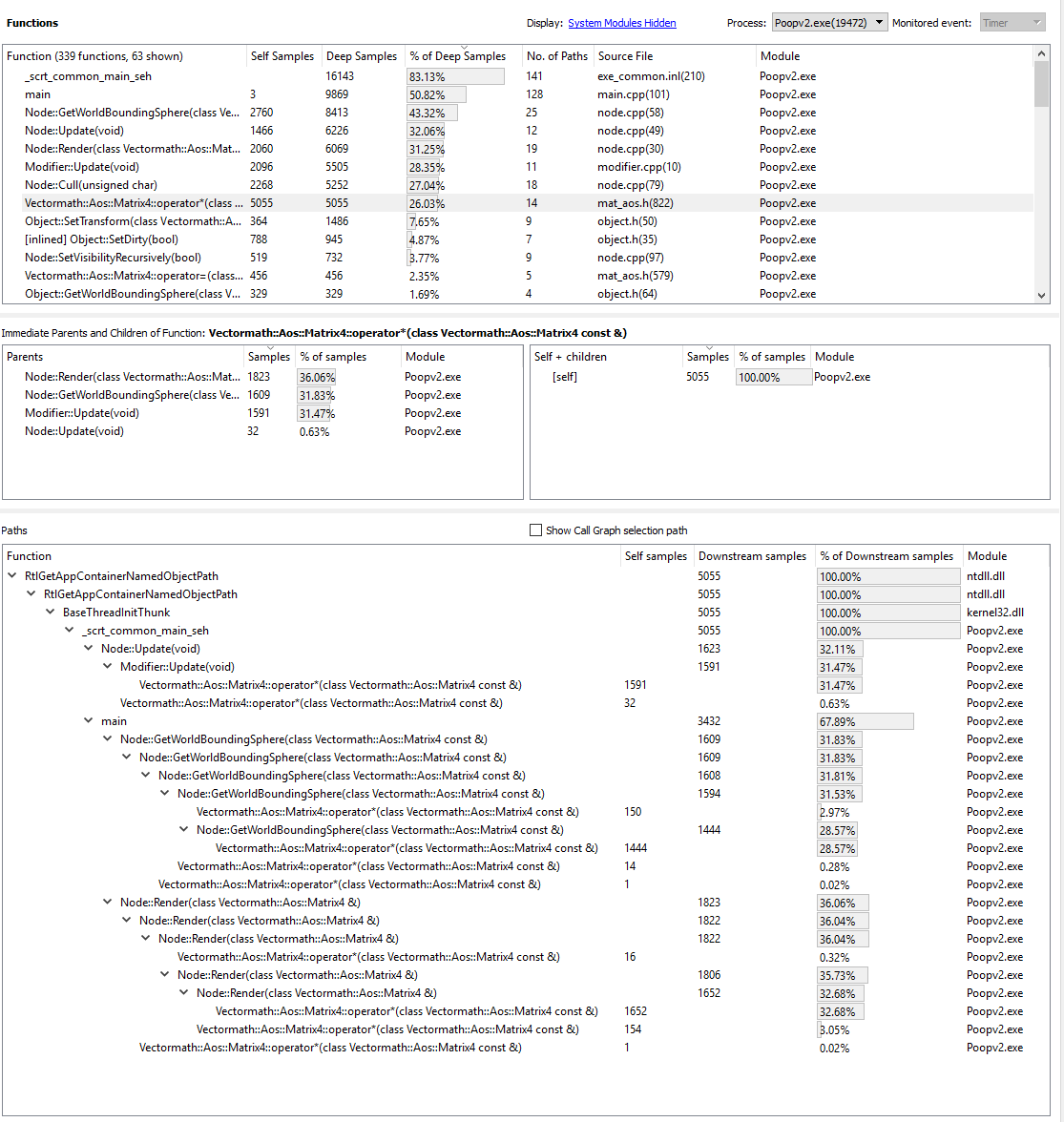
Если мы проанализируем пять самых «востребованных» функций, то получим:

Похоже, самая медленная функция — матричное умножение. Звучит логично, поскольку для всех этих вращений функции приходится выполнять кучу вычислений. Если внимательно присмотреться к иерархии стека парой иллюстраций выше, то можно заметить, что оператор матричного умножения вызывается посредством Modifier::Update(), Node::Update(), GetWorldBoundingSphere() и Node::Render(). Он вызывается так часто и из такого количества мест — так что этот оператор можно считать хорошим кандидатом на оптимизацию.
Matrix::operator*
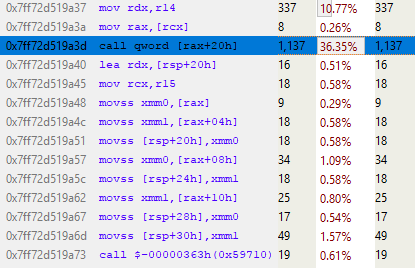
Если с помощью семплирующего профилировщика проанализировать код, отвечающий за умножение, то можно выяснить «стоимость» выполнения каждой строки.

К сожалению, длина кода матричного умножения — всего одна строка (ради эффективности), так что нам этот результат мало что даёт. Или всё-таки не так уж мало?
Если взглянуть на ассемблер, можно выявить пролог и эпилог функции.
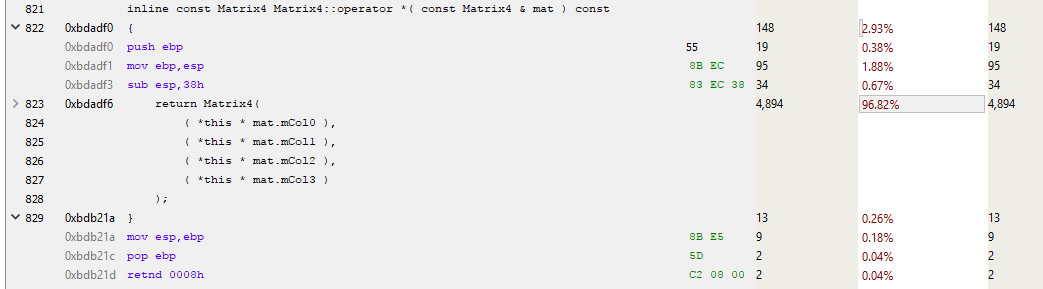
Это стоимость внутренней инструкции вызова функции. В прологе задаётся новое пространство стека (ESP — текущий указатель стека, EBP — базовый указатель для текущего фрейма стека), а в эпилоге выполняется очистка и возврат. При каждом вызове функции, которая не инлайнена и использует какое-либо пространство стека (т. е. имеет локальную переменную), все эти инструкции могут быть вставлены и вызваны.
Давайте развернём остальную часть функции и посмотрим, что на самом деле выполняет матричное умножение.
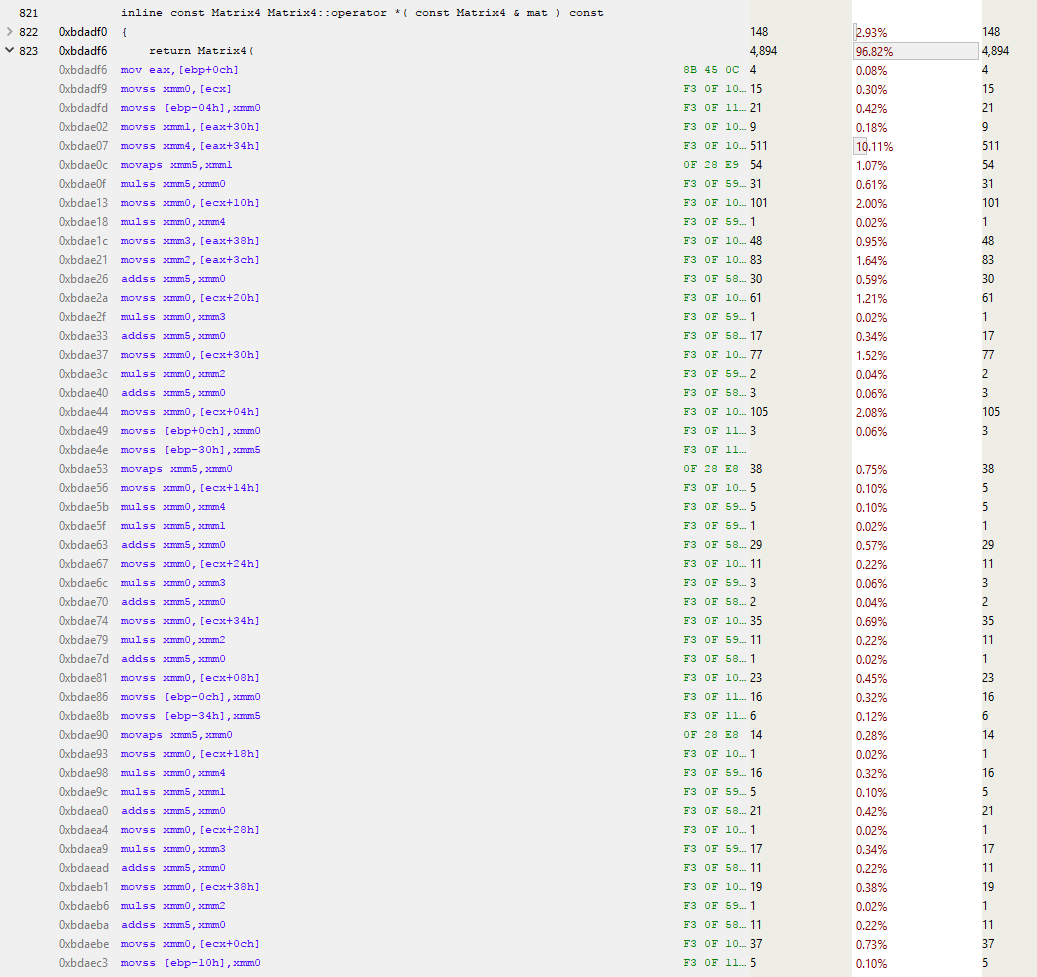
Ого, куча кода! И это лишь первая страница. Полная функция занимает больше килобайта кода с 250—300 инструкциями! Проанализируем начало функции.

Строка над выделенной синим цветом занимает около 10 % общего времени выполнения. Почему она выполняется гораздо медленнее соседних? Эта MOVSS-инструкция берёт из памяти по адресу eax+34h значение с плавающей запятой и кладёт в регистр xmm4. Строкой выше то же самое делается с регистром xmm1, но гораздо быстрее. Почему?
Всё дело в промахе кеша.
Разберёмся подробнее. Семплирование отдельных инструкций применимо в самых разных ситуациях. Современные процессоры в любой момент выполняют несколько инструкций, и в течение одного тактового цикла немало инструкций может быть пересортировано (retire). Даже семплирование на основе событий может приписывать события не той инструкции. Так что при анализе семплирования ассемблера необходимо руководствоваться какой-то логикой. В нашем примере наиболее семплированная инструкция может не быть самой медленной. Мы лишь можем с определённой долей уверенности говорить о медленной работе чего-то, относящегося к этой строке. А поскольку процессор выполняет ряд MOV’ов в память и из неё, то предположим, что как раз эти MOV’ы и виноваты в низкой производительности. Чтобы удостовериться в этом, можно прогнать профиль с включённым семплированием на основе событий для промахов кеша и посмотреть на результат. Но пока что доверимся инстинктам и прогоним профиль исходя из гипотезы о промахе кеша.
Пропуск кеша L3 занимает более 100 циклов (в некоторых случаях — несколько сотен циклов), а промах кеша L2 — около 40 циклов, хотя всё это сильно зависит от процессора. К примеру, x86-инструкции занимают от 1 примерно до 100 циклов, при этом большинство — менее 20 циклов (некоторые инструкции деления на некотором железе работают довольно медленно). На моём Core i7 инструкции умножения, сложения и даже деления занимали по несколько циклов. Инструкции попадают в конвейер, так что одновременно обрабатывается несколько инструкций. Это значит, что один промах кеша L3 — загрузка напрямую из памяти — по времени может занимать исполнение сотен инструкций. Проще говоря, чтение из памяти — очень медленный процесс.
Modifier::Update()
Итак, мы видим, что обращение к памяти замедляет исполнение нашего кода. Давайте вернёмся назад и посмотрим, что в коде приводит к этому обращению. Контрольно-измерительный профилировщик показывает, что Node::Update() выполняется медленно, а из отчёта семплирующего профилировщика о стеке очевидно, что функция Modifier::Update() особенно нетороплива. С этого и начнём оптимизацию.
void Modifier::Update()
{
for(Object* obj : mObjects)
{
Matrix4 mat = obj->GetTransform();
mat = mTransform*mat;
obj->SetTransform(mat);
}
}Modifier::Update() проходит через вектор указателей к Object’ам, берёт их матрицу преобразования (transform matrix), умножает её на матрицу mTransform Modifier’а, а затем применяет это преобразование к Object’ам. В приведённом выше коде преобразование копируется из объекта в стек, умножается, а затем копируется обратно.
GetTransform() просто возвращает копию mTransform, при этом SetTransform() копирует в mTransform новую матрицу и задаёт состояние mDirty этого объекта:
void SetDirty(bool dirty)
{
if (dirty && (dirty != mDirty))
{
if (mParent)
mParent->SetDirty(dirty);
}
mDirty = dirty;
}
void SetTransform(Matrix4& transform)
{
mTransform = transform;
SetDirty(true);
}
inline const Matrix4 GetTransform() const { return mTransform; } Внутренний слой данных этого Object’а выглядит так:
protected:
Matrix4 mTransform;
Matrix4 mWorldTransform;
BoundingSphere mBoundingSphere;
BoundingSphere mWorldBoundingSphere;
bool m_IsVisible = true;
const char* mName;
bool mDirty = true;
Object* mParent;
};Для ясности я раскрасил записи в памяти объекта Node:
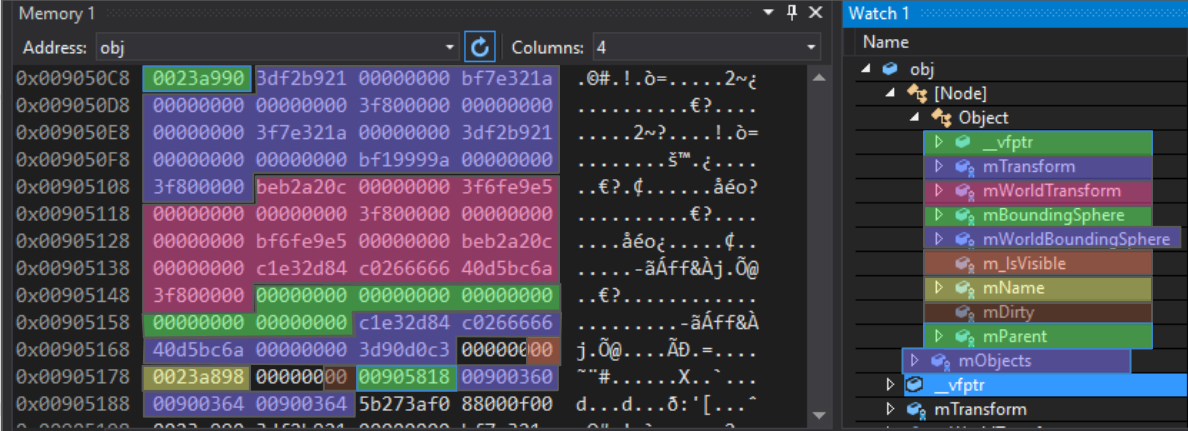
Первая запись — указатель виртуальной таблицы (virtual table pointer). Это часть реализации наследования в С++: указатель на массив указателей функций, которые выступают в роли виртуальных функций для этого конкретного полиморфного объекта. Для Object, Node, Modifier и любого класса, унаследованного от базового, существуют разные виртуальные таблицы.
После этого 4-байтного указателя идёт 64-байтный массив чисел с плавающей запятой. За матрицей mTransform идёт матрица mWorldTransform, а затем две ограничивающие сферы (bounding spheres). Обратите внимание, что следующая запись, m_IsVisible, однобайтная, она занимает 4 полных байта. Это нормально, поскольку следующая запись — указатель, который должен иметь как минимум 4-байтное выравнивание. Если после m_IsVisible положить другое булево значение, то оно было бы упаковано в доступные 3 байта. Далее идёт указатель mName (с 4-байтным выравниванием), затем булево mDirty (также неплотно упакованное), потом указатель на родительский Object. Всё это — характерные для Object данные. Последующий вектор mObjects относится уже к Node-вектору и занимает на этой платформе 12 байтов, хотя на иных платформах может быть другого размера.
Если мы рассмотрим код Modifier::Update(), то увидим, что может быть причиной промаха кеша.
void Modifier::Update()
{
for(Object* obj : mObjects)
{Для начала отметим: вектор mObjects — это массив указателей на Object’ы, которые размещаются в памяти динамически. Итерирование по этому вектору хорошо работает с кешем (красные стрелки на иллюстрации ниже), поскольку указатели следуют один за другим. Там есть несколько промахов, но они указывают на что-то, вероятно, не адаптированное для работы с кешем. А поскольку каждый Object размещается в памяти с новым указателем, то можно сказать лишь, что наша помеха находится где-то в памяти.
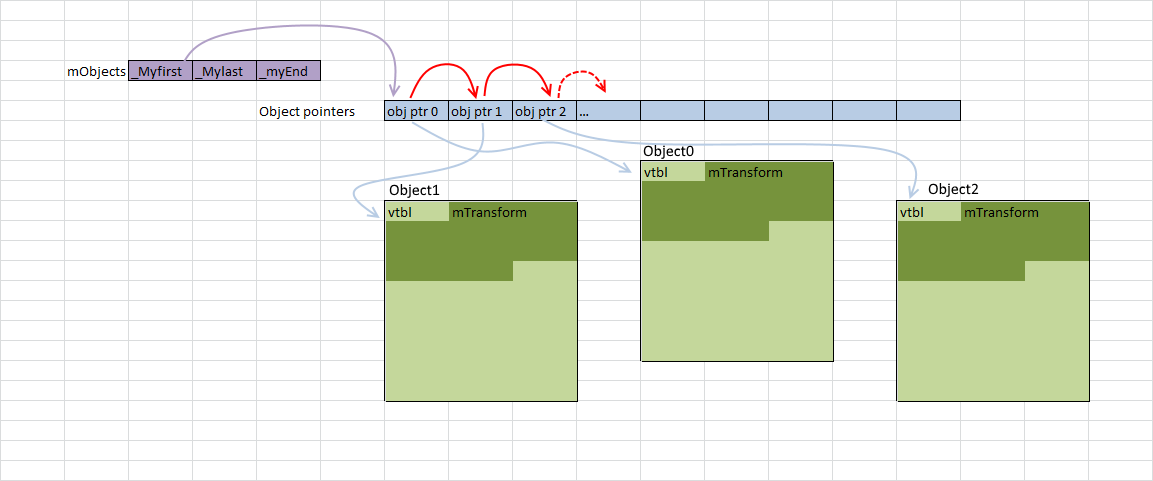
Когда мы получаем указатель на Object, вызываем GetTransform():
Matrix4 mat = obj->GetTransform();Эта инлайновая функция просто возвращает копию mTransform Object’а, так что предыдущая строка эквивалентна этой:
Matrix4 mat = obj->mTransform;Как вы можете видеть на диаграмме, Object’ы, на которые ссылаются указатели в массиве mObjects, разбросаны по памяти. Каждый раз, когда мы добавляем новый Object и вызываем GetTransform(), это наверняка приводит к промаху кеша при загрузке в mTransform и помещению в стек. На используемом мной оборудовании кеш-строка занимает 64 байта, так что если повезёт и объект начнётся за 4 байта до 64-байтной границы, то mTransform будет загружен в кеш целиком за раз. Но более вероятна ситуация, когда загрузка mTransform приведёт к двум промахам кеша. Из семплирующего профиля Modifier::Update() очевидно, что выравнивание матрицы выполняется произвольно.
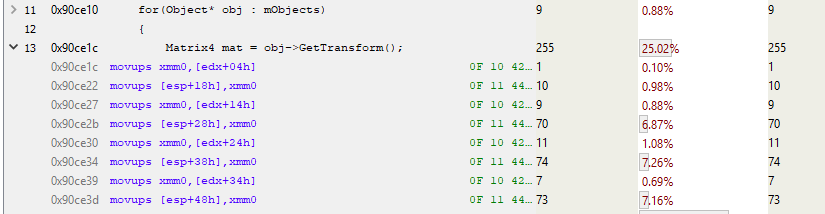
В этом фрагменте edx является расположением Object’а. А как мы знаем, mTransform начинается за 4 байта до начала объекта. Так что этот код копирует mTransform в стек (MOVUPS копирует в регистр 4 невыравненных значения с плавающей запятой). Обратите на 7 % обращений к трём MOVUPS-инструкциям. Это говорит о том, то промахи кеша также встречаются и в случае с MOV’ами. Не знаю, почему первый MOVUPS в стек занимает не столько же времени, сколько остальные. Мне кажется, «затраты» просто переносятся на последующие MOVUPS из-за особенностей конвейеризации инструкций. Но в любом случае мы получили доказательство высокой стоимости обращения к памяти, так что будем с этим работать.
void Modifier::Update()
{
for(Object* obj : mObjects)
{
Matrix4 mat = obj->GetTransform();
mat = mTransform*mat;
obj->SetTransform(mat);
}
}После умножения матрицы вызываем Object::SetTransform(), которая берёт результат умножения (свежепомещённый в стек) и копирует его в экземпляр Object’а. Копирование проходит быстро, потому что преобразование уже закешировано, но SetDirty() работает медленно, потому что считывает флаг mDirty, его, вероятно, нет в кеше. Так что для тестирования и, возможно, определения этого одного байта процессору приходится считывать окружающие 63 байта.
Заключение
Если дочитали до конца — молодцы! Знаю, поначалу это бывает сложно, особенно если вы не знакомы с ассемблером. Но очень рекомендую найти время и посмотреть, что компиляторы делают с кодом, который они пишут. Для этого можно воспользоваться Compiler Explorer.
Мы собрали ряд доказательств, что главная причина проблем с производительностью в нашем примере кода — это указатели доступа к памяти. Дальше минимизируем затраты на доступ к памяти, а затем снова измерим производительность, чтобы понять, удалось ли добиться улучшения. Этим мы и займёмся в следующий раз.
