Я учусь в CS центре в Новосибирске уже второй год. До поступления у меня уже была работа в IT — я работал аналитиком в Яндексе, но мне хотелось развиваться дальше, узнать что-то за пределами текущих задач и, по совету коллеги, я поступил в CS центр. В этой статье я хочу рассказать о практике, которую проходил во время учебы.
В начале первого семестра нам предложили несколько проектов. Мое внимание сразу зацепилось за проект под названием «Метод оценки цвета зерна по фотографии». Эту тему предложили специалисты из Института цитологии и генетики СО РАН, но сам проект был больше связан с анализом и обработкой изображений, чем с биологией. Я выбрал его, потому что интересовался машинным обучением и распознаванием образов и мне хотелось попрактиковаться в этих областях.
Есть приложение SeedCounter, предназначенное для подсчета и измерения размеров зерен пшеницы по фотографии, чтобы освободить агрономов от скучной и рутинной работы по подсчету и анализу зерен. Мне нужно было изучить возможность определения цвета зерен по фотографии и реализовать это в приложении так, чтобы зерна можно было разделить на осмысленные классы. Полученные классы могут соответствовать, например, содержанию полезных для человека веществ.
Пример фотографии до и после калибровки:

Казалось бы, взять и понять цвет зерен по фотографии — простая задача, тем более, если алгоритм нахождения самих зерен уже есть. Однако полученный цвет очень сильно зависит от освещения и камера вносит свои искажения. В итоге полученный цвет имеет слабое отношение к свойствам самого зерна. Поэтому основная цель была — получить откалиброванные цвета зерен, т.е. такие, какими они были бы при идеальных условиях съемки.
Для корректировки цветов мы использовали эталонную палитру, называемую ColorChecker. ColorChecker располагается на том же кадре, что и зерна, его цвета заранее известны. Приложение должно подобрать такое преобразование изображения, чтобы цвета на ColorChecker были как можно ближе к известным эталонным цветам.
То есть задача разделилась на три подзадачи:
В первую очередь мы поискали уже реализованный алгоритм поиска ColorChecker – он нашелся в свободном пакете macduff. Я опробовал его на тестовых изображениях, получилось плохо: даже при небольшом повороте ColorChecker распознавалось слишком мало квадратов палитры.После этого я стал искать другие методы поиска, где ориентация не важна. Выяснилось, что есть метод, используемый для более общей задачи поиска произвольного объекта — он основан на выделении характерных точек на изображении и сравнении их с шаблоном. Все необходимые компоненты уже есть в OpenCV, поэтому реализовать его оказалось несложно.
Для выделения характерных точек в OpenCV мы использовали несколько алгоритмов: как запатентованные (SIFT/SURF), так и свободные (ORB/FAST). Изначально метод работал вполне сносно с запатентованными вариантами, но при этом был очень медленным, что критично при использовании на мобильном устройстве. Также они отсутствовали в стандартной версии библиотеки, что могло вызвать сложности при портировании на Android. При использовании более быстрых вариантов качество распознавания падала.
Чтобы поднять качество распознавания, я разобрал примеры, где алгоритм ошибался. В большинстве случаев алгоритм находил примерное расположение ColorChecker, но при этом не точно определял его область. Из-за неточного определения области точки, из которых брались цвета для калибровки, не попадали в правильные квадраты палитры, соответственно цвета восстанавливались неправильно. Для исправления этого я попробовал делать повторный прогон алгоритма, получив неточное начальное приближение, а также эмпирически сдвигать точки, используемые для калибровки, в сторону нужных квадратов. После этого качество метода возросло и стало приемлемым, даже для изначально слабых, но быстрых алгоритмов:
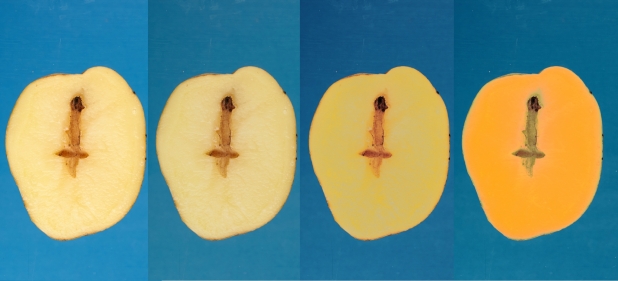
Для калибровки я использую простую регрессию методом наименьших квадратов: как линейную по цветам, так и более высоких порядков. Соответственно, встал вопрос: как из нескольких моделей выбрать лучшую. Метрики, основанные на близости цвета к эталону, давали неоднозначные результаты: хорошо откалиброванное по формальным критериям изображение могло выглядеть неестественным с точки зрения человека. На изображении ниже приведен пример такого эффекта. Для иллюстрации вместо зерен взял срез клубня картофеля, так как он больше, и нам нем искажения цвета лучше видно. Мы пробовали менять метрики, но в конце концов решили, что лучше оценивать модель для калибровки по ее влиянию на результат итоговой задачи — разделение зерен.
Срез клубня картофеля, слева направо: до калибровки, после калибровки регрессией первого, второго и третьего порядков.
Дальше нужно было собрать датасет, на котором можно было бы проверить качество поиска ColorChecker и калибровки, а также решить задачу разделения зерен по цвету. Для этого мы взяли пробы зерен разных сортов и сфотографировали на различные устройства, при разных источниках освещения: как искусственных, так и при дневном свете. После этого я прогнал все изображения через алгоритм калибровки и собрал цвета зерен, алгоритм для распознавания зерен мне дали готовый. Пришлось сделать не одну итерацию этого процесса: на изображениях плохого качества распознавание не всегда хорошо работало, приходилось подбирать дополнительные эвристики для отсеивания мусора.
В конце концов получилось собрать датасет, качеством которого я был доволен. Задачу разделения зерен я формализовал так: девять сортов зерен были разбиты на три класса (белые, красные и фиолетовые), каждое отдельное зерно нужно было классифицировать по цвету в один из трех классов. Я опробовал простые методы классификации, такие как KNN и линейные классификаторы, но получить хорошую точность так и не удалось. Впрочем, даже при отсмотре глазом было видно, что классы сильно пересекаются между собой и явной разделяющей поверхности между ними не наблюдается.
Основной итог работы — алгоритм поиска ColorChecker, работающий быстро и с хорошим качеством, и калибровка цвета по нему. Он может быть полезен не только для зерен. Например, его удалось применить в задаче по анализу колосьев пшеницы.
Также я проверил возможность классификации зерен по цвету — высокой точности здесь получить не удалось, даже с помощью калибровки.
Но самый важный результат — это то, что я получил опыт решения задачи, для которой нет готового, разложенного по полочкам алгоритма, и открыл для себя захватывающую область компьютерного зрения, с которой, надеюсь, мне предстоит столкнуться и в будущем.
В начале первого семестра нам предложили несколько проектов. Мое внимание сразу зацепилось за проект под названием «Метод оценки цвета зерна по фотографии». Эту тему предложили специалисты из Института цитологии и генетики СО РАН, но сам проект был больше связан с анализом и обработкой изображений, чем с биологией. Я выбрал его, потому что интересовался машинным обучением и распознаванием образов и мне хотелось попрактиковаться в этих областях.
Суть проекта
Есть приложение SeedCounter, предназначенное для подсчета и измерения размеров зерен пшеницы по фотографии, чтобы освободить агрономов от скучной и рутинной работы по подсчету и анализу зерен. Мне нужно было изучить возможность определения цвета зерен по фотографии и реализовать это в приложении так, чтобы зерна можно было разделить на осмысленные классы. Полученные классы могут соответствовать, например, содержанию полезных для человека веществ.
Пример фотографии до и после калибровки:

Казалось бы, взять и понять цвет зерен по фотографии — простая задача, тем более, если алгоритм нахождения самих зерен уже есть. Однако полученный цвет очень сильно зависит от освещения и камера вносит свои искажения. В итоге полученный цвет имеет слабое отношение к свойствам самого зерна. Поэтому основная цель была — получить откалиброванные цвета зерен, т.е. такие, какими они были бы при идеальных условиях съемки.
Для корректировки цветов мы использовали эталонную палитру, называемую ColorChecker. ColorChecker располагается на том же кадре, что и зерна, его цвета заранее известны. Приложение должно подобрать такое преобразование изображения, чтобы цвета на ColorChecker были как можно ближе к известным эталонным цветам.
То есть задача разделилась на три подзадачи:
- нахождение ColorChecker на изображении,
- вычисление цветового преобразования и применение его к изображению,
- разделение зерен по полученным цветам.
Ход работы
В первую очередь мы поискали уже реализованный алгоритм поиска ColorChecker – он нашелся в свободном пакете macduff. Я опробовал его на тестовых изображениях, получилось плохо: даже при небольшом повороте ColorChecker распознавалось слишком мало квадратов палитры.После этого я стал искать другие методы поиска, где ориентация не важна. Выяснилось, что есть метод, используемый для более общей задачи поиска произвольного объекта — он основан на выделении характерных точек на изображении и сравнении их с шаблоном. Все необходимые компоненты уже есть в OpenCV, поэтому реализовать его оказалось несложно.
Для выделения характерных точек в OpenCV мы использовали несколько алгоритмов: как запатентованные (SIFT/SURF), так и свободные (ORB/FAST). Изначально метод работал вполне сносно с запатентованными вариантами, но при этом был очень медленным, что критично при использовании на мобильном устройстве. Также они отсутствовали в стандартной версии библиотеки, что могло вызвать сложности при портировании на Android. При использовании более быстрых вариантов качество распознавания падала.
Чтобы поднять качество распознавания, я разобрал примеры, где алгоритм ошибался. В большинстве случаев алгоритм находил примерное расположение ColorChecker, но при этом не точно определял его область. Из-за неточного определения области точки, из которых брались цвета для калибровки, не попадали в правильные квадраты палитры, соответственно цвета восстанавливались неправильно. Для исправления этого я попробовал делать повторный прогон алгоритма, получив неточное начальное приближение, а также эмпирически сдвигать точки, используемые для калибровки, в сторону нужных квадратов. После этого качество метода возросло и стало приемлемым, даже для изначально слабых, но быстрых алгоритмов:
| Алгоритм | Точность | Время работы |
| SURF | 75% | 2.8s |
| 83% (+8%) | 14s | |
| SIFT | 88% | 3.4s |
| 96% (+8%) | 15s | |
| BRISK | 65% | 0.5s |
| 93% (+28%) | 1.5s | |
| ORB | 56% | 0.4s |
| 79% (+23%) | 1s |
Для калибровки я использую простую регрессию методом наименьших квадратов: как линейную по цветам, так и более высоких порядков. Соответственно, встал вопрос: как из нескольких моделей выбрать лучшую. Метрики, основанные на близости цвета к эталону, давали неоднозначные результаты: хорошо откалиброванное по формальным критериям изображение могло выглядеть неестественным с точки зрения человека. На изображении ниже приведен пример такого эффекта. Для иллюстрации вместо зерен взял срез клубня картофеля, так как он больше, и нам нем искажения цвета лучше видно. Мы пробовали менять метрики, но в конце концов решили, что лучше оценивать модель для калибровки по ее влиянию на результат итоговой задачи — разделение зерен.
Срез клубня картофеля, слева направо: до калибровки, после калибровки регрессией первого, второго и третьего порядков.

Дальше нужно было собрать датасет, на котором можно было бы проверить качество поиска ColorChecker и калибровки, а также решить задачу разделения зерен по цвету. Для этого мы взяли пробы зерен разных сортов и сфотографировали на различные устройства, при разных источниках освещения: как искусственных, так и при дневном свете. После этого я прогнал все изображения через алгоритм калибровки и собрал цвета зерен, алгоритм для распознавания зерен мне дали готовый. Пришлось сделать не одну итерацию этого процесса: на изображениях плохого качества распознавание не всегда хорошо работало, приходилось подбирать дополнительные эвристики для отсеивания мусора.
В конце концов получилось собрать датасет, качеством которого я был доволен. Задачу разделения зерен я формализовал так: девять сортов зерен были разбиты на три класса (белые, красные и фиолетовые), каждое отдельное зерно нужно было классифицировать по цвету в один из трех классов. Я опробовал простые методы классификации, такие как KNN и линейные классификаторы, но получить хорошую точность так и не удалось. Впрочем, даже при отсмотре глазом было видно, что классы сильно пересекаются между собой и явной разделяющей поверхности между ними не наблюдается.
Итог
Основной итог работы — алгоритм поиска ColorChecker, работающий быстро и с хорошим качеством, и калибровка цвета по нему. Он может быть полезен не только для зерен. Например, его удалось применить в задаче по анализу колосьев пшеницы.
Также я проверил возможность классификации зерен по цвету — высокой точности здесь получить не удалось, даже с помощью калибровки.
Но самый важный результат — это то, что я получил опыт решения задачи, для которой нет готового, разложенного по полочкам алгоритма, и открыл для себя захватывающую область компьютерного зрения, с которой, надеюсь, мне предстоит столкнуться и в будущем.
