Всем привет! Меня зовут Никита Василюк, я инженер по работе с данными в департаменте данных и аналитики компании Lamoda. В нашем департаменте Airflow играет роль оркестратора процессов обработки больших данных, с его помощью мы загружаем в Hadoop данные из внешних систем, обучаем ML модели, а также запускаем проверки качества данных, расчеты рекомендательных систем, различных метрик, А/Б-тестов и многое другое.

В этой статье я расскажу:
Airflow – это платформа для создания, мониторинга и оркестрации пайплайнов. Этот open source проект, написанный на Python, был создан в 2014 году в компании Airbnb. В 2016 году Airflow ушел под крылышко Apache Software Foundation, прошел через инкубатор и в начале 2019 года перешел в статус top-level проекта Apache.
В мире обработки данных некоторые называют его ETL-инструментом, но это не совсем ETL в классическом его понимании, как, например, Pentaho, Informatica PowerCenter, Talend и иже с ними. Airflow – это оркестратор, “cron на батарейках”: он сам не выполняет тяжелую работу по перекладке и обработке данных, а говорит другим системам и фреймворкам, что надо делать, и следит за статусом выполнения. Мы в основном используем его для запуска запросов в Hive или Spark джобы.
Спектр решаемых с помощью Airflow задач не ограничивается запуском чего-то в Hadoop кластере. Он может запускать Python-код, выполнять Bash команды, поднимать Docker контейнеры и поды в Kubernetes, выполнять запросы в вашей любимой базе данных и многое другое.

Примерно так выглядит наш текущий сетап Airflow, только в Lamoda используются два воркера. На отдельной машине крутятся веб-сервер и scheduler, на соседних пыхтят воркеры. Один создан для регулярных задач, второй мы адаптировали для запуска обучения ML моделей с помощью Vowpal Wabbit. Все компоненты общаются между собой через очередь задач и базу метаданных.
На заре развития Airflow в компании все компоненты (кроме БД) работали на одной машине, однако в какой-то момент это привело к нехватке ресурсов на сервере и задержкам в работе шедулера. Поэтому мы решили разнести сервисы по разным серверам и пришли к архитектуре, показанной на картинке выше.
Webserver
Webserver – это веб-интерфейс, показывающий, что сейчас происходит с пайплайном. Эту страницу видит пользователь:

Веб-сервер дает возможность просматривать список имеющихся пайплайнов. Возле каждого пайплайна отображается краткая статистика запусков. Также имеется несколько кнопок, которые принудительно запускают пайплайн или показывают детальную информацию: статистику запусков, исходный код пайплайна, его визуализацию в виде графа или таблицы, список задач и историю их запусков.
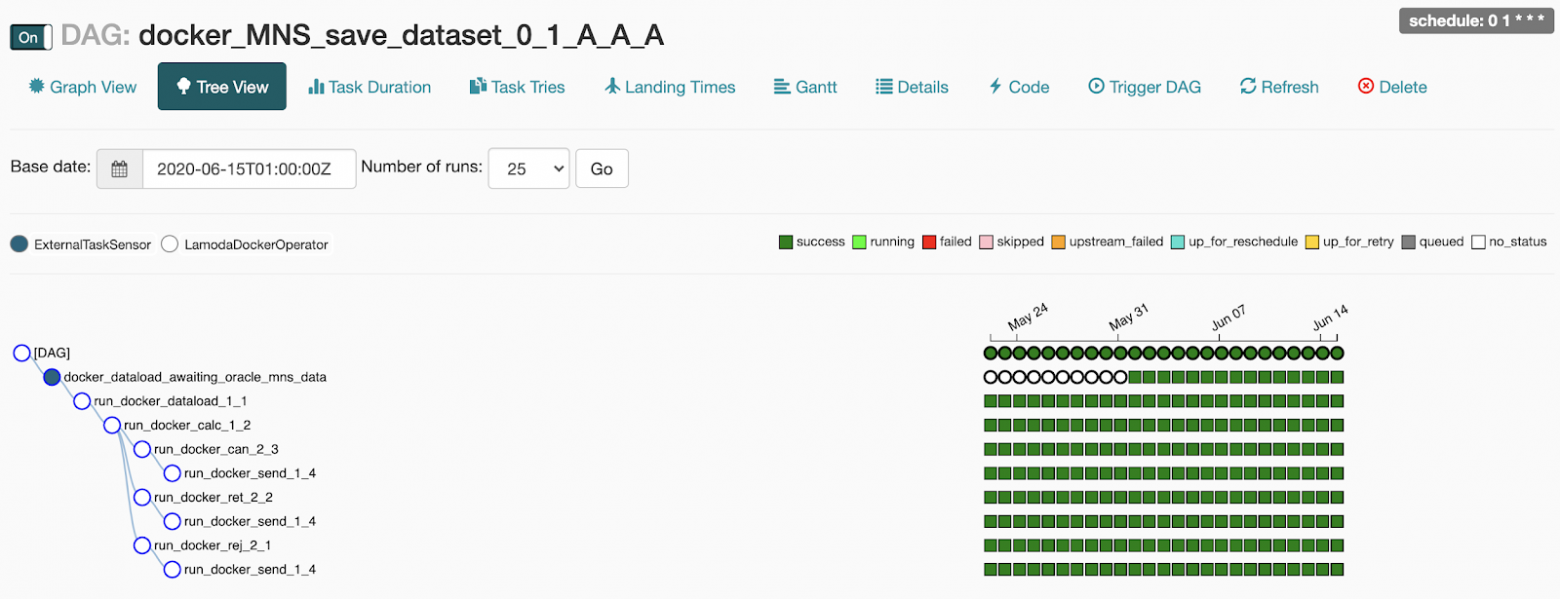
Если нажать на пайплайн, мы провалимся в меню Graph View. Тут отображаются задачи и связи между ними.

Рядом с Graph View есть меню Tree View. Оно создано для перезапуска задач, просмотра статистики и логов. В левой части отображается древовидное представление графа, напротив него – таблица с историей запуска задач.
Каждая строчка этой страшной таблицы – одна задача, каждый столбец – один запуск пайплайна. На их пересечении – квадратик с запуском определенной задачи за определенную дату. Если на него нажать, появляется меню, где можно посмотреть детальную информацию и логи этой задачи, запустить или перезапустить ее, а также пометить её как успешную или неудачную.
Scheduler – как понятно из названия, запускает пайплайны, когда настает их время. Он представляет собой Python-процесс, который периодически ходит в директорию с пайплайнами, подтягивает оттуда их актуальное состояние, проверяет статус и запускает. Вообще, Scheduler – это самое интересное и одновременно самое узкое место в архитектуре Airflow.
До некоторых пор запаздывание тюнится параметрами конфиг-файла Airflow, но лаг на запуск все равно остается. Из этого следует, что Airflow – это не про real-time обработку данных. Если поступить неосторожно и указать слишком частый интервал запуска (раз в пару минут), можно добиться запаздывания вашего пайплайна. Опыт показывает, что раз в 5 минут – уже достаточно часто, а некоторые не советуют запускать пайплайн раз в 10 минут. У нас есть пара пайплайнов, стартующих раз в 10 минут, они довольно простые и до сих пор проблем с ними не было.
Worker
Worker – это место, где запускается наш код и выполняются задачи. Airflow поддерживает несколько экзекьюторов:
Пайплайн, или DAG
Самая важная сущность Airflow – это DAG, он же пайплайн, он же направленный ациклический граф. Чтобы стало понятнее, как его готовить и зачем он нужен, я разберу небольшой пример.
Допустим, к нам пришел аналитик и попросил раз в день наливать данные в определенную таблицу. Он подготовил всю информацию: что откуда нужно брать, когда нужно запускаться, с каким SLA. Вот пример того, как мы могли бы описывать наш пайплайн.
В dag_id передается уникальное название пайплайна. Дальше мы с помощью schedule_interval указываем, как часто он должен запускаться.
Параметр default_args – это словарь, в котором описываются аргументы по умолчанию для всех задач в рамках этого пайплайна. Название большинства параметров хорошо себя описывает, я не буду на них останавливаться.
Оператор – это Python класс, который описывает, какие действия надо совершить в рамках нашей ежедневной задачи, чтобы порадовать аналитика.
Мы можем использовать HiveOperator, который, как ни странно, создан для того, чтобы отправлять запросы на выполнение в Hive. Для запуска оператора нужно указать название задачи, пайплайн, идентификатор соединения к Hive и выполняемый запрос.
В запросе, который мы передаем в конструктор оператора, есть кусочек Jinja-шаблона. Jinja – это библиотека Python для шаблонизации.
Каждый запуск пайплайна хранит информацию о дате запуска. Она лежит в переменной под названием execution_date. {{ ds }} – это макрос, который возьмет в execution_date только дату в формате %Y-%m-%d. В определенный момент перед запуском оператора Airflow отрендерит строку запроса, подставит туда нужную дату и отправит запрос на выполнение.
ds – это не единственный макрос, их порядка 20 (список всех доступных макросов). Они включают в себя разные форматы дат и парочку функций для работы с датами – прибавить или отнять сколько-то дней.
Когда я познакомился с Airflow, то не понимал, зачем нужны всякие макросы, когда можно просто вставить туда вызов datetime.now() и радоваться жизни. Но в некоторых кейсах это может сильно портить жизнь как нам, так и аналитику. Например, если мы захотим пересчитать что-то за какую-то дату в прошлом, Airflow подставит туда не дату запуска пайплайна, а фактическое время выполнения. И в некоторых случаях мы можем получить не то, что ожидаем.
Например, если захотим перезапустить пайплайн за прошлый вторник, то при использовании datetime.now() мы на самом деле пересчитаем пайплайн за сегодняшний день, а не за нужную дату. Плюс ко всему, сегодняшние данные к этому моменту могут быть даже не готовы.
После успешного выполнения запроса мы можем отправить уведомление в slack о загрузке данных. Дальше командуем Airflow, в каком порядке запускать задачи. Благодаря перегрузке операторов в Airflow, я легко с помощью оператора >> указываю порядок шагов в пайплайне. В моём примере мы говорим, что сначала запустим выполнение запроса, потом отправку нотификации в slack.
Невозможно рассказать про Airflow, не упомянув про идемпотентность. На всякий случай напомню: идемпотентность – это свойство объекта при повторном применении операции к объекту всегда возвращать один и тот же результат.
В контексте Airflow это значит, что если сегодня пятница, а мы перезапускаем задачу за прошлый вторник, то задача запустится так, как будто для нее сейчас прошлый вторник, и никак иначе. То есть запуск или перезапуск задачи за какую-то дату в прошлом никак не должен зависеть от того, когда эта задача фактически запускается. Идемпотентность реализуется с помощью вышеупомянутой переменной execution_date.
Airflow разрабатывался как инструмент для решения задач, связанных с обработкой данных. В этом мире мы обычно обрабатываем крупную порцию данных только тогда, когда она готова, то есть на следующий день. И создатели Airflow изначально изложили такую концепцию в своих продуктах.

Когда мы запускаем ежедневный пайплайн, то с большой вероятностью захотим обрабатывать данные за вчера. Именно поэтому execution_date будет равен левой границе интервала, за которой мы обрабатываем данные. Например, сегодняшний запуск, который стартовал в час ночи по UTC, получит в качестве execution_date вчерашнюю дату. В случае ежечасного пайплайна ситуация такая же: для запуска пайплайна в 6 утра время в execution_date будет равно 5 часам утра. Это мысль поначалу не очень очевидна, но тем не менее, она очень осмысленная и важная.
В Airflow есть не только операторы, которые ходят в Hive и отправляют что-то в slack. На самом деле, есть огромное множество операторов. В статью я вынес самые популярные и полезные.
Далее видно, как в течение дня менялась длительность выполнения задач. В нашем случае это процесс перекладки данных из Kafka в Hive с проверкой качества данных. Плюс можно проследить, когда задача почему-то выполнялась дольше обычного.

Ниже я привел несколько советов, которые помогут не выстрелить себе в ногу при использовании Airflow:
С начала использования Airflow мы держали конфиги пайплайнов отдельно от кода. Изначально это было связано с особенностями схемы деплоя, но постепенно этот подход прижился. И сейчас мы используем конфиги везде, где есть намек на шаблонность. Особенно у нас это касается Spark джобов, которые мы запускаем из Docker. Из этого получилась история с декларативным написанием пайплайнов.
Подход заключается в том, что у нас есть директория с конфигами. В каждом конфиг-файле лежит один или несколько пайплайнов с их описанием: как они должны работать, когда запускаться, какие в нем задачи и в каком порядке их нужно выполнить.
Я покажу, как выглядит код вызова нашего генератора пайплайна. На вход он получает директорию с конфигами, prefix и класс, который будет отвечать за наполнение пайплайна задачами. Под капотом генератор сходит в указанную директорию, найдет там конфиг-файлы, и для каждого пайплайна в этих файлах создаст задачи и свяжет их.
Примерно так выглядит типичный конфиг-файл. Для описания конфигов мы используем формат HOCON, который является надмножеством JSON. Он поддержкивает импорты других HOCON файлов и может ссылаться на значения других переменных.
В конфиге на уровне пайплайна (блок attribution) можно указать много параметров, но самым важным являются name, start_date и schedule_interval.
Тут можно указать concurrency – сколько задач будет одновременно бежать в одном запуске. С недавних пор мы добавляем сюда блок с кратким markdown-описанием пайплайна. Потом оно вместе с остальной информацией о пайплайне отправится в Confluence (отправку мы реализовали с помощью Foliant). Получилось супер-удобно: так мы экономим время разработчиков дагов на создание страниц в Confluence.
Далее идет часть, которая отвечает за формирование задач. Сначала мы в блоке connections указываем, из какого connection в Airflow нужно брать параметры для подключения к внешнему источнику – в примере это наш DWH.
Вся необходимая информация типа пользователя, пароля, URL и так далее пробросится в docker-контейнер в качестве переменных окружений. В блоке Containers указываем, какие задачи мы будем запускать. Внутри есть название образа, список используемых connection и список переменных окружений.
Можно заметить, что в значениях некоторых переменных окружения фигурируют Jinja-шаблоны. Для указания очереди в YARN мы используем стандартный синтаксис Airflow для получения значений переменных. Для указания даты запуска используем макрос {{ ds_nodash }}, который представляет собой дату их execution_date без дефисов. В конфиге перечислены еще 3 похожие задачи, они скрыты для наглядности.
Дальше с помощью tasks мы указываем, как эти задачи будут запускаться. Можно заметить, что они перечислены как список в списке. Это значит, что все 4 эти задачи будут запускаться параллельно друг с другом.
И последнее: мы указываем, от каких базовых пайплайнов зависит наш текущий DAG. Странные циферки и буковки в конце названий базовых дагов – это расписание, которое мы встраиваем в название пайплайна. Таким образом, наш пайплайн начнет заполняться только после того, как завершатся базовые даги и указанные в них задачи.
Вот что мы получаем после генерации:
Во-первых, построить полноценный Feature environment. Сейчас у нас есть один девелоперский стенд для тестирования всех наших пайплайнов. И перед тестированием нужно убедиться, что dev-ландшафт сейчас свободен.
Недавно наша команда расширилась, и желающих прибавилось. Мы нашли временное решение проблемы и теперь сообщаем в Slaсk, когда занимаем dev. Это работает, но все-таки это узкое место в процессе разработки и тестирования.
Один из вариантов – переезд в Kubernetes. Например, при создании pull-request в master можно поднимать в Kubernetes отдельный namespace, куда разворачивать Airflow, деплоить код, потом раскидывать переменные, коннекшены. Разработчик после развертывания придет в свежесозданный инстанс Airflow и будет тестировать свои пайплайны. У нас есть наработки на эту тему, но руки не добрались до боевого Kubernetes-кластера, где мы могли бы это все запускать.
Второй вариант реализации Feature environment – организация репозитория с общей веткой develop, куда вливается код разработчиков и автоматически выкатывается на dev-ландшафт. Сейчас активно смотрим в сторону этой схемы.
Также мы хотим попробовать внедрить у себя плагины – штуки для расширения функциональности веб-интерфейса. Основная цель внедрения плагинов – построить диаграмму Ганта на уровне всего Airflow, то есть на уровне всех пайплайнов, а также построить граф зависимостей между разными пайплайнами.

В этой статье я расскажу:
- что за зверь этот Airflow, из каких компонентов состоит и как они между собой взаимодействуют
- про основные сущности Airflow: пайплайны, которые называются DAG, Operator и еще про несколько вещей
- как преуспеть в разработке на Airflow
- как мы внедрили генерацию пайплайнов и так называемое «декларативное писание пайплайнов»
- про плюсы и минусы использования Airflow
Что такое Airflow
Airflow – это платформа для создания, мониторинга и оркестрации пайплайнов. Этот open source проект, написанный на Python, был создан в 2014 году в компании Airbnb. В 2016 году Airflow ушел под крылышко Apache Software Foundation, прошел через инкубатор и в начале 2019 года перешел в статус top-level проекта Apache.
В мире обработки данных некоторые называют его ETL-инструментом, но это не совсем ETL в классическом его понимании, как, например, Pentaho, Informatica PowerCenter, Talend и иже с ними. Airflow – это оркестратор, “cron на батарейках”: он сам не выполняет тяжелую работу по перекладке и обработке данных, а говорит другим системам и фреймворкам, что надо делать, и следит за статусом выполнения. Мы в основном используем его для запуска запросов в Hive или Spark джобы.
Спойлер
Ничто не мешает обрабатывать данные на самом Airflow, выкачивая их через worker (об этом ниже), и в некоторых случаях этого достаточно. Однако, когда нам нужно перекладывать десятки и сотни миллионов строк данных, такая обработка занимает непростительно много времени.
Спектр решаемых с помощью Airflow задач не ограничивается запуском чего-то в Hadoop кластере. Он может запускать Python-код, выполнять Bash команды, поднимать Docker контейнеры и поды в Kubernetes, выполнять запросы в вашей любимой базе данных и многое другое.
Архитектура Airflow
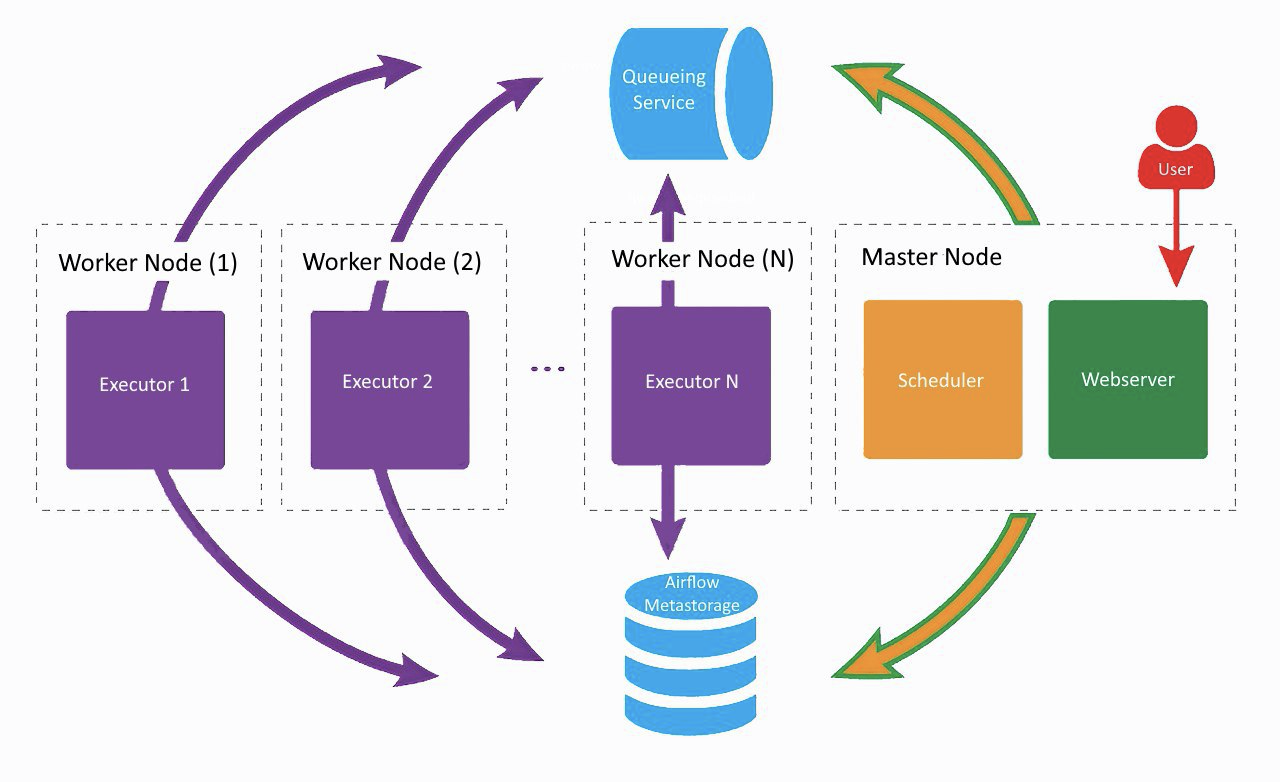
Примерно так выглядит наш текущий сетап Airflow, только в Lamoda используются два воркера. На отдельной машине крутятся веб-сервер и scheduler, на соседних пыхтят воркеры. Один создан для регулярных задач, второй мы адаптировали для запуска обучения ML моделей с помощью Vowpal Wabbit. Все компоненты общаются между собой через очередь задач и базу метаданных.
На заре развития Airflow в компании все компоненты (кроме БД) работали на одной машине, однако в какой-то момент это привело к нехватке ресурсов на сервере и задержкам в работе шедулера. Поэтому мы решили разнести сервисы по разным серверам и пришли к архитектуре, показанной на картинке выше.
Компоненты Airflow
Webserver
Webserver – это веб-интерфейс, показывающий, что сейчас происходит с пайплайном. Эту страницу видит пользователь:
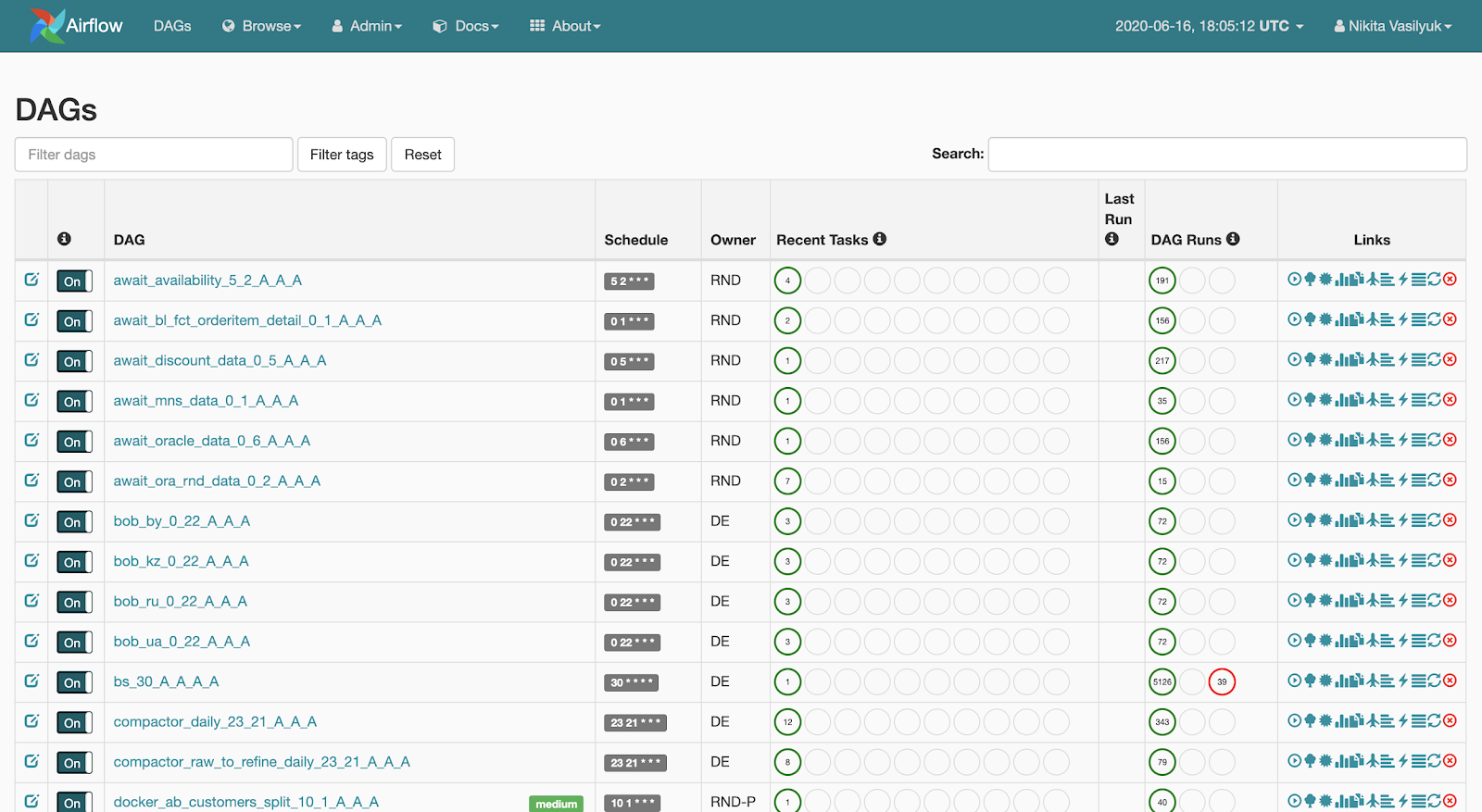
Веб-сервер дает возможность просматривать список имеющихся пайплайнов. Возле каждого пайплайна отображается краткая статистика запусков. Также имеется несколько кнопок, которые принудительно запускают пайплайн или показывают детальную информацию: статистику запусков, исходный код пайплайна, его визуализацию в виде графа или таблицы, список задач и историю их запусков.
Если нажать на пайплайн, мы провалимся в меню Graph View. Тут отображаются задачи и связи между ними.
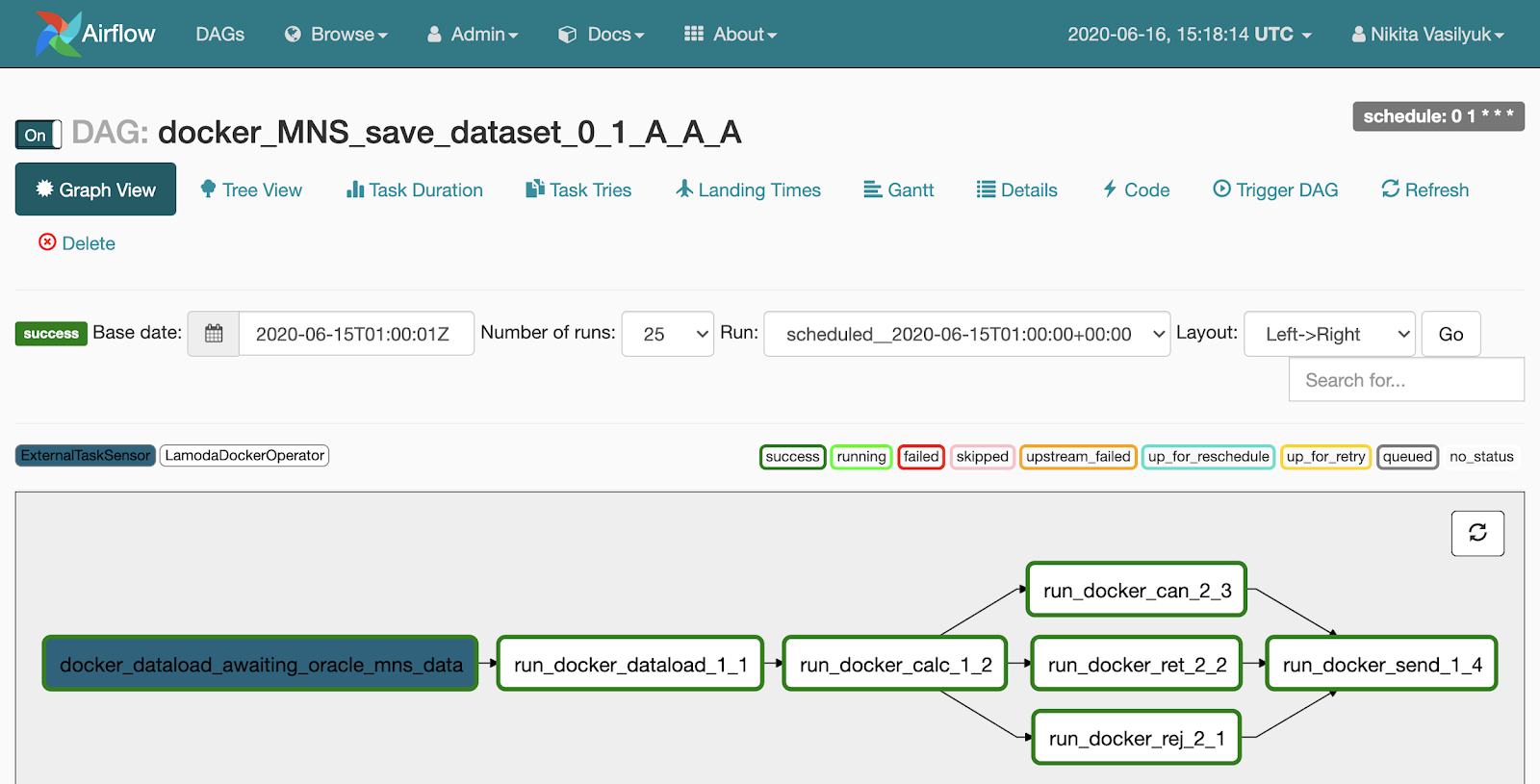
Рядом с Graph View есть меню Tree View. Оно создано для перезапуска задач, просмотра статистики и логов. В левой части отображается древовидное представление графа, напротив него – таблица с историей запуска задач.
Каждая строчка этой страшной таблицы – одна задача, каждый столбец – один запуск пайплайна. На их пересечении – квадратик с запуском определенной задачи за определенную дату. Если на него нажать, появляется меню, где можно посмотреть детальную информацию и логи этой задачи, запустить или перезапустить ее, а также пометить её как успешную или неудачную.

Scheduler – как понятно из названия, запускает пайплайны, когда настает их время. Он представляет собой Python-процесс, который периодически ходит в директорию с пайплайнами, подтягивает оттуда их актуальное состояние, проверяет статус и запускает. Вообще, Scheduler – это самое интересное и одновременно самое узкое место в архитектуре Airflow.
- Первый нюанс заключается в том, что в один момент времени может работать только один инстанс Scheduler’a. Это значит, что на текущий момент невозможен режим работы в High Availability (разработчики планируют добавить Scheduler HA в Airflow версии 2.0).
- Второй нюанс: в определённый момент на запуск могут отправиться несколько пайплайнов, из-за чего фактический старт задач может откладываться на несколько минут. Бывалые дяденьки рассказывают, что запаздывания могут затягиваться на полчаса-час или больше, но лично я с таким не сталкивался.
До некоторых пор запаздывание тюнится параметрами конфиг-файла Airflow, но лаг на запуск все равно остается. Из этого следует, что Airflow – это не про real-time обработку данных. Если поступить неосторожно и указать слишком частый интервал запуска (раз в пару минут), можно добиться запаздывания вашего пайплайна. Опыт показывает, что раз в 5 минут – уже достаточно часто, а некоторые не советуют запускать пайплайн раз в 10 минут. У нас есть пара пайплайнов, стартующих раз в 10 минут, они довольно простые и до сих пор проблем с ними не было.
Worker
Worker – это место, где запускается наш код и выполняются задачи. Airflow поддерживает несколько экзекьюторов:
- Первый, самый простенький – это SequentialExecutor. Он последовательно запускает прилетающие задачи, а на время их выполнения приостанавливает шедулер.
- LocalExecutor на каждую прилетающую задачу стартует новый процесс, с ним появляется возможность запускать несколько задач в параллель, поэтому LocalExecutor чуточку лучше предыдущего экзекьютора. Есть один нюанс: если в качестве базы метаданных используется что-то типа однопоточного SQLite, ваш LocalExecutor превращается в SequentialExecutor.
- CeleryExecutor позволяет иметь несколько воркеров, работающих на разных машинах. Celery – это распределенная очередь задач, которая под капотом использует RabbitMQ или Redis. При запуске воркера ему можно указать названия очередей, из которых он будет принимать задачи от шедулера.
- DaskExecutor запускает задачу с помощью Dask – библиотеки для параллельных вычислений.
- KubernetesExecutor на каждую задачу запускает новый pod в Kubernetes.
- DebugExecutor создан для запуска и отладки пайплайнов из IDE.
Сущности Apache Airflow
Пайплайн, или DAG
Самая важная сущность Airflow – это DAG, он же пайплайн, он же направленный ациклический граф. Чтобы стало понятнее, как его готовить и зачем он нужен, я разберу небольшой пример.
Допустим, к нам пришел аналитик и попросил раз в день наливать данные в определенную таблицу. Он подготовил всю информацию: что откуда нужно брать, когда нужно запускаться, с каким SLA. Вот пример того, как мы могли бы описывать наш пайплайн.
dag = DAG(
dag_id="load_some_data",
schedule_interval="0 1 * * *",
default_args={
"start_date": datetime(2020, 4, 20),
"owner": "DE",
"depends_on_past": False,
"sla": timedelta(minutes=45),
"email": "<your_email_here>",
"email_on_failure": True,
"retries": 2,
"retry_delay": timedelta(minutes=5)
}
)
В dag_id передается уникальное название пайплайна. Дальше мы с помощью schedule_interval указываем, как часто он должен запускаться.
Очень важный момент: поскольку Airflow разрабатывался международной компанией, он работает только по UTC. На текущий момент нет вменяемого способа заставить Airflow работать в другом часовом поясе, поэтому нужно постоянно помнить про разницу нашего часового пояса с UTC. В версии 1.10.10 появилась возможность менять таймзону в UI, однако это касается только веб-интерфейса, пайплайны все равно будут запускаться по UTC.
Параметр default_args – это словарь, в котором описываются аргументы по умолчанию для всех задач в рамках этого пайплайна. Название большинства параметров хорошо себя описывает, я не буду на них останавливаться.
Оператор
Оператор – это Python класс, который описывает, какие действия надо совершить в рамках нашей ежедневной задачи, чтобы порадовать аналитика.
Мы можем использовать HiveOperator, который, как ни странно, создан для того, чтобы отправлять запросы на выполнение в Hive. Для запуска оператора нужно указать название задачи, пайплайн, идентификатор соединения к Hive и выполняемый запрос.
run_sql = HiveOperator(
dag=dag,
task_id="run_sql",
hive_cli_conn_id="hive",
hql="""
INSERT OVERWRITE TABLE some_table
SELECT * FROM other_table t1
JOIN another_table t2 on ...
WHERE other_table.dt = '{{ ds }}'
"""
)
notify = SlackAPIPostOperator(
dag=dag,
task_id="notify_slack",
slack_conn_id="slack",
token=token,
channel="airflow_alerts",
text="Guys, I'm done for {{ ds }}"
)
run_sql >> notify
В запросе, который мы передаем в конструктор оператора, есть кусочек Jinja-шаблона. Jinja – это библиотека Python для шаблонизации.
Каждый запуск пайплайна хранит информацию о дате запуска. Она лежит в переменной под названием execution_date. {{ ds }} – это макрос, который возьмет в execution_date только дату в формате %Y-%m-%d. В определенный момент перед запуском оператора Airflow отрендерит строку запроса, подставит туда нужную дату и отправит запрос на выполнение.
ds – это не единственный макрос, их порядка 20 (список всех доступных макросов). Они включают в себя разные форматы дат и парочку функций для работы с датами – прибавить или отнять сколько-то дней.
Когда я познакомился с Airflow, то не понимал, зачем нужны всякие макросы, когда можно просто вставить туда вызов datetime.now() и радоваться жизни. Но в некоторых кейсах это может сильно портить жизнь как нам, так и аналитику. Например, если мы захотим пересчитать что-то за какую-то дату в прошлом, Airflow подставит туда не дату запуска пайплайна, а фактическое время выполнения. И в некоторых случаях мы можем получить не то, что ожидаем.
Например, если захотим перезапустить пайплайн за прошлый вторник, то при использовании datetime.now() мы на самом деле пересчитаем пайплайн за сегодняшний день, а не за нужную дату. Плюс ко всему, сегодняшние данные к этому моменту могут быть даже не готовы.
После успешного выполнения запроса мы можем отправить уведомление в slack о загрузке данных. Дальше командуем Airflow, в каком порядке запускать задачи. Благодаря перегрузке операторов в Airflow, я легко с помощью оператора >> указываю порядок шагов в пайплайне. В моём примере мы говорим, что сначала запустим выполнение запроса, потом отправку нотификации в slack.
Идемпотентность
Невозможно рассказать про Airflow, не упомянув про идемпотентность. На всякий случай напомню: идемпотентность – это свойство объекта при повторном применении операции к объекту всегда возвращать один и тот же результат.
В контексте Airflow это значит, что если сегодня пятница, а мы перезапускаем задачу за прошлый вторник, то задача запустится так, как будто для нее сейчас прошлый вторник, и никак иначе. То есть запуск или перезапуск задачи за какую-то дату в прошлом никак не должен зависеть от того, когда эта задача фактически запускается. Идемпотентность реализуется с помощью вышеупомянутой переменной execution_date.
Airflow разрабатывался как инструмент для решения задач, связанных с обработкой данных. В этом мире мы обычно обрабатываем крупную порцию данных только тогда, когда она готова, то есть на следующий день. И создатели Airflow изначально изложили такую концепцию в своих продуктах.
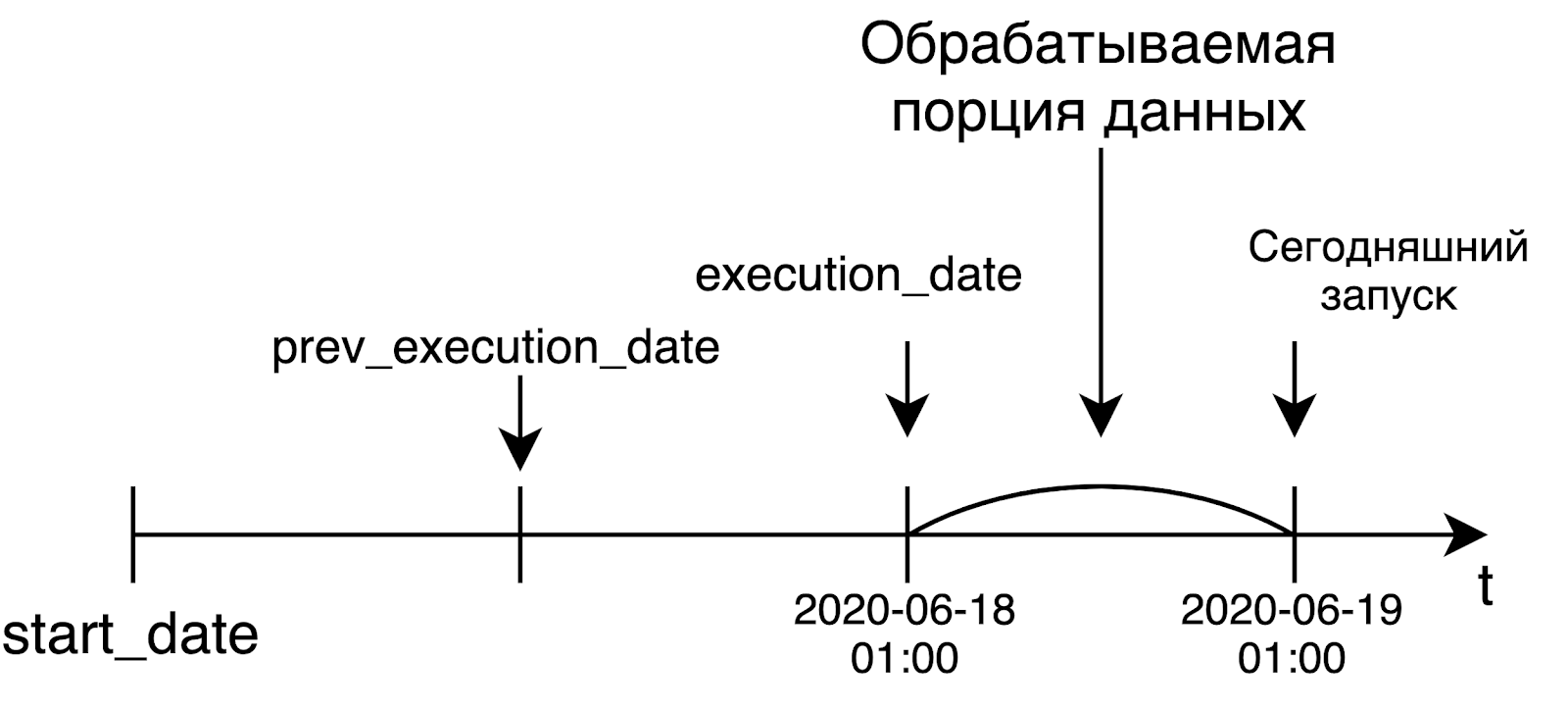
Когда мы запускаем ежедневный пайплайн, то с большой вероятностью захотим обрабатывать данные за вчера. Именно поэтому execution_date будет равен левой границе интервала, за которой мы обрабатываем данные. Например, сегодняшний запуск, который стартовал в час ночи по UTC, получит в качестве execution_date вчерашнюю дату. В случае ежечасного пайплайна ситуация такая же: для запуска пайплайна в 6 утра время в execution_date будет равно 5 часам утра. Это мысль поначалу не очень очевидна, но тем не менее, она очень осмысленная и важная.
Самые распространенные операторы Airflow
В Airflow есть не только операторы, которые ходят в Hive и отправляют что-то в slack. На самом деле, есть огромное множество операторов. В статью я вынес самые популярные и полезные.
- BashOpetator и PythonOperator. С ними все понятно: они отправляют на выполнение bash команду и python функцию соответственно.
- Есть огромное множество операторов для отправки запросов в различные базы данных. Поддерживаются стандартные Postgres, MySQL, Oracle, Hive, Presto. Если оператора для вашей любимой базы данных почему-то нет, можно использовать более общий JdbcOperator или написать свой, Airflow это позволяет.
- Sensor – это оператор, который при запуске проверяет выполнение определенного условия. И если оно не выполняется, оператор на какое-то время засыпает. Например, оператор может проверять количество строк в таблице, наличие файлов в файловой системе. Есть сенсор, которому можно сказать: подожди до 3 часов ночи, после этого передай эстафету следующей задаче. Сенсоры легко кастомизируются под задачи. Например, мы используем их для проверки готовности данных во внешних системах, чтобы не запускать тяжелый отчет на неполных данных.
- BranchPythonOperator – это оператор ветвления, который на основании определенного условия, заданного python кодом, решает, какую задачу надо запустить следующей.
- DockerOpetator запускает Docker-контейнер на воркере. Тут нужно понимать, что внутри Docker-контейнера может запуститься все, что угодно. Поэтому очень важно при этом мониторить ресурсы воркера, чтобы они внезапно не закончились.
- KubernetesPodOperator запускает новый pod в Kubernetes.
- DummyOperator выполняет роль пустышки и создан для того, чтобы склеивать различные участки пайплайна между собой.
Какие операторы мы используем в Lamoda
- Наша основная рабочая лошадка – это LamodaDockerOperator. Как понятно из названия, мы немножко подпилили напильником стандартный оператор: добавили монтирование актуальных конфиг-файлов Hadoop, прокидывание некоторых переменных окружения по умолчанию и еще парочку мелочей. В основном мы запускаем с помощью LamodaDockerOperator Spark-джобы в кластере, либо код на python.
- LamodaHiveОperator – тоже оператор, который мы изменили. Он отправляет запросы в Hive. Мы заметили, что у стандартного оператора в некоторых случаях запрос почему-то завершается ошибкой, при этом оператор говорит нам, что запрос завершился успешно. Мы заменили тип хука, который использовался под капотом у этого оператора, с HiveCliHook на HiveServer2Hook, и все стало замечательно.
- Следующий интересный оператор – это ExternalTaskSensor. С помощью него мы связываем пайплайны между собой. У нас есть набор базовых пайплайнов, которые загружают в Hadoop данные из внешних источников. Другие пайплайны, которые используют эти данные, могут подписаться на завершение либо всего базового пайплайна, либо какой-то конкретной его задачи, и начать выполняться только после того, как завершатся базовые. Раньше у нас был самописный механизм, который работал через файлы-флаги на HDFS, но буквально несколько недель назад мы переехали на встроенный механизм Airflow.
- BashOperator, PythonOperator – очевидно, запускают bash-команду и python код соответственно.
- И есть несколько небольших сенсоров и операторов, которые мы написали под свои нужды. Они очень-очень маленькие, я решил их сюда не выносить.
Другие полезности Airflow
- Variables – это переменные, смысл которых, думаю, очевиден. Здесь мы храним вещи, которые нужны для запуска пайплайнов. Например, там лежат названия популярных схем в Hive, пути к часто используемым директориям в HDFS, идентификатор окружения и прочее. У нас различаются значение для некоторых переменных в dev-среде и prod-среде, таким образом мы изолируем ландшафты друг от друга.
- Connections – это сущность, в которой хранится информация о подключении к внешним источникам. В Airflow поддерживается множество источников: от банальных http и ftp, заканчивая популярными базами данных и облачными провайдерами.
- Hooks – это интерфейсы для внешних источников и баз данных, часто выступающие ключевым звеном для работы операторов и сенсоров.
- SLA и тайм-ауты. При создании задачи можно указать, сколько у нее есть времени на выполнение. Если указать SLA и задача не успеет выполниться, то на почту придет письмо, что такой-то негодяй почему-то не успел вовремя. Про тайм-аут понятно: если этот негодяй совсем-совсем не успел, то Airflow его безжалостно прикончит.
- Следующая интересная штука – это XCom, что расшифровывается как cross-communication. Он создан для передачи данных между задачами: это могут быть название файла, строчка из базы данных или json-объект. Максимальный вес – до 48 килобайт.
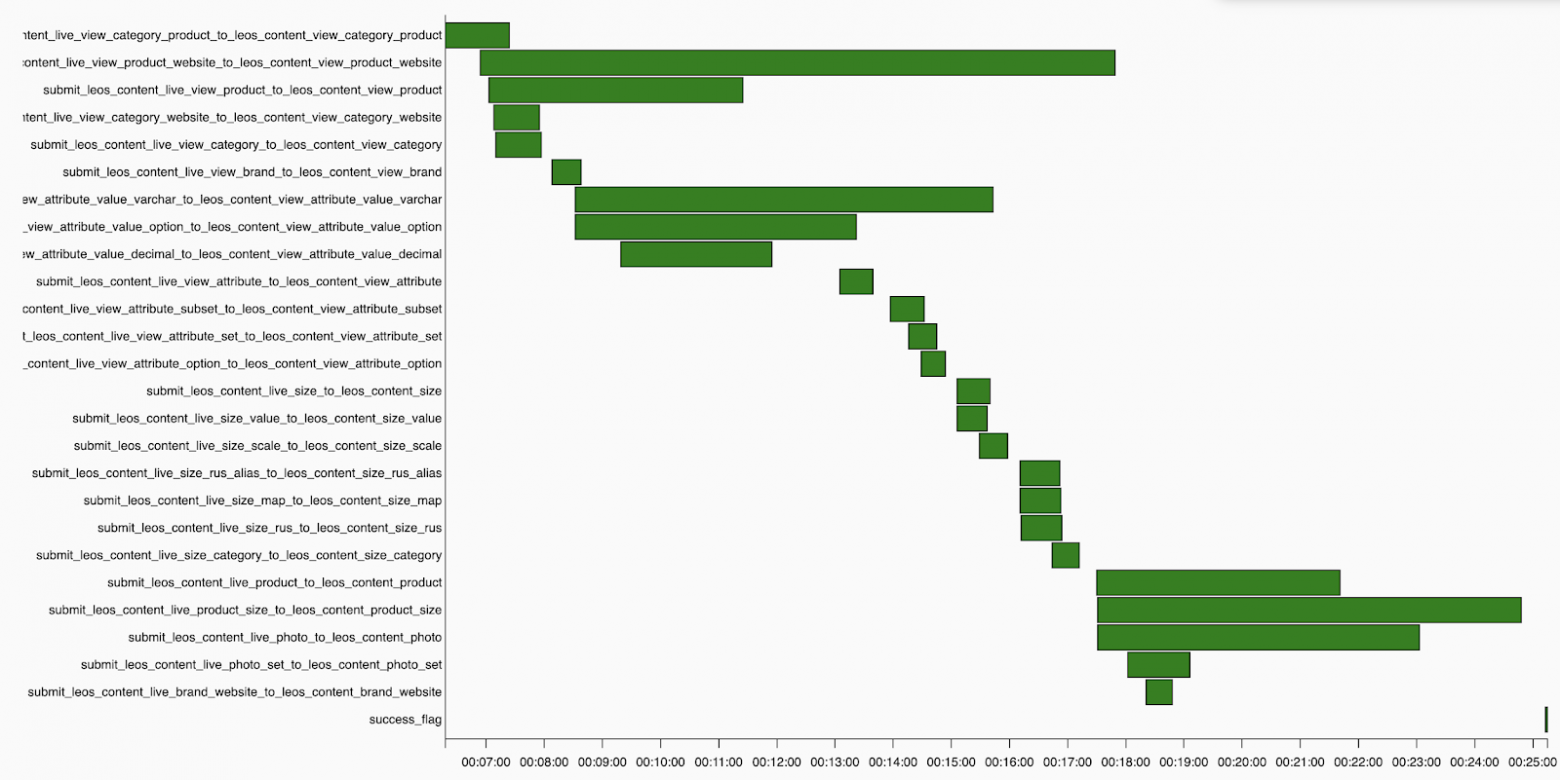
- Есть некоторое количество графиков – например, диаграмма Ганта. Здесь интересно проследить ту самую задержку перед запуском, которую я упоминал выше. Даже несмотря на то, что здесь выставлен параллелизм 5, мы ожидаем, что задачи стартанут одновременно, но нет, лаг на запуск присутствует.

Далее видно, как в течение дня менялась длительность выполнения задач. В нашем случае это процесс перекладки данных из Kafka в Hive с проверкой качества данных. Плюс можно проследить, когда задача почему-то выполнялась дольше обычного.

Как преуспеть в разработке на Airflow
Ниже я привел несколько советов, которые помогут не выстрелить себе в ногу при использовании Airflow:
- Полезно держать каждый пайплайн (или генератор пайплайнов, об этом ниже) в отдельном файле. Я сразу знаю, в какой файл нужно залезть, чтобы посмотреть на нужный пайплайн или генератор.
- Хорошей практикой является подход, когда пайплайн состоит из задач, которые максимально атомарны и идемпотентны. Конечно, можно создать одну задачу со здоровенным баш-скриптом, делающим все на свете. Но при разделенных задачах мы быстрее поймем, когда что-то пошло не так, и сможем быстро локализовать проблему. Про идемпотентность я уже говорил: в случае перезапуска можно быть уверенным, что мы обрабатываем ровно ту порцию данных, которую хотим обработать.
- Следующий неочевидный совет – при изменении schedule_interval или start_date нужно менять dag_id. Это связано с тем, что в базе метаданных Airflow уже есть запись о том, что такой-то пайплайн запускается тогда-то. При изменении расписания в таблицу DAGS добавляется еще одна строчка, что сводит с ума Scheduler, потому что он видит два пайплайна с разным расписанием. Для решения этой проблемы мы раньше указывали версию в названии пайплайнов, но сейчас мы перешли на подход, при котором вшиваем расписание прямо в dag_id. Таким образом пайплайн автоматически получает новое имя, и этим не нужно заниматься вручную.
- При создании пайплайна можно передать ему параметр catchup. Если его значение True, то Airflow начнет создавать запуски пайплайна для каждого интервала, начиная от start_date до текущей даты. Иногда это совсем не то, что вам нужно. При значении False Airflow создаст только один запуск за последний доступный интервал. Самое интересное, что по умолчанию в Airflow этот параметр равен True (значение по умолчанию задается в конфиг-файле).
- И последнее – стоит делать инициализацию пайплайнов максимально легкой. Шедулер раз в определенный промежуток времени приходит в директорию с пайплайнами, ищет все python файлы, в которых присутствуют слова airflow и DAG, и запускает код в этих файлах, после чего ищет все созданные объекты класса DAG. Тяжелая логика в файлах с пайплайнами может сильно повлиять на производительность. Например, если для инициализации пайплайна мы сначала ходим в базу данных, а она вдруг начинает висеть или таймаутить. Или сначала ходим в REST API, но вызов requests.get() без указания таймаута вдруг начинает бесконечно висеть.
Генерация дагов: генератор
С начала использования Airflow мы держали конфиги пайплайнов отдельно от кода. Изначально это было связано с особенностями схемы деплоя, но постепенно этот подход прижился. И сейчас мы используем конфиги везде, где есть намек на шаблонность. Особенно у нас это касается Spark джобов, которые мы запускаем из Docker. Из этого получилась история с декларативным написанием пайплайнов.
Подход заключается в том, что у нас есть директория с конфигами. В каждом конфиг-файле лежит один или несколько пайплайнов с их описанием: как они должны работать, когда запускаться, какие в нем задачи и в каком порядке их нужно выполнить.
Я покажу, как выглядит код вызова нашего генератора пайплайна. На вход он получает директорию с конфигами, prefix и класс, который будет отвечать за наполнение пайплайна задачами. Под капотом генератор сходит в указанную директорию, найдет там конфиг-файлы, и для каждого пайплайна в этих файлах создаст задачи и свяжет их.
from libs.dag_from_config.dag_generator import DagGenerator
from libs.runners.docker_runner import DockerRunner
generator = DagGenerator(config_dir='dag_configs/docker_runner', prefix='docker')
dags = generator.generate(task_runner=DockerRunner)
for dag in dags:
globals()[dag.dag_id] = dag # хак для динамической генерации дагов
Примерно так выглядит типичный конфиг-файл. Для описания конфигов мы используем формат HOCON, который является надмножеством JSON. Он поддержкивает импорты других HOCON файлов и может ссылаться на значения других переменных.
В конфиге на уровне пайплайна (блок attribution) можно указать много параметров, но самым важным являются name, start_date и schedule_interval.
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- Считывает события из z_log
- Атрибуцирует их друг к другу по определённой логике
- Проставляет параметры, необходимые для хранения данных
- Записывает новую партицию за вчера
"""
tags = ["critical"]
Тут можно указать concurrency – сколько задач будет одновременно бежать в одном запуске. С недавних пор мы добавляем сюда блок с кратким markdown-описанием пайплайна. Потом оно вместе с остальной информацией о пайплайне отправится в Confluence (отправку мы реализовали с помощью Foliant). Получилось супер-удобно: так мы экономим время разработчиков дагов на создание страниц в Confluence.
Далее идет часть, которая отвечает за формирование задач. Сначала мы в блоке connections указываем, из какого connection в Airflow нужно брать параметры для подключения к внешнему источнику – в примере это наш DWH.
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
Вся необходимая информация типа пользователя, пароля, URL и так далее пробросится в docker-контейнер в качестве переменных окружений. В блоке Containers указываем, какие задачи мы будем запускать. Внутри есть название образа, список используемых connection и список переменных окружений.
Можно заметить, что в значениях некоторых переменных окружения фигурируют Jinja-шаблоны. Для указания очереди в YARN мы используем стандартный синтаксис Airflow для получения значений переменных. Для указания даты запуска используем макрос {{ ds_nodash }}, который представляет собой дату их execution_date без дефисов. В конфиге перечислены еще 3 похожие задачи, они скрыты для наглядности.
Дальше с помощью tasks мы указываем, как эти задачи будут запускаться. Можно заметить, что они перечислены как список в списке. Это значит, что все 4 эти задачи будут запускаться параллельно друг с другом.
И последнее: мы указываем, от каких базовых пайплайнов зависит наш текущий DAG. Странные циферки и буковки в конце названий базовых дагов – это расписание, которое мы встраиваем в название пайплайна. Таким образом, наш пайплайн начнет заполняться только после того, как завершатся базовые даги и указанные в них задачи.
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
Полный текст конфиг-файла
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- Считывает события из z_log
- Атрибуцирует их друг к другу по определённой логике
- Проставляет параметры, необходимые для хранения данных
- Записывает новую партицию за вчера
"""
tags = ["critical"]
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
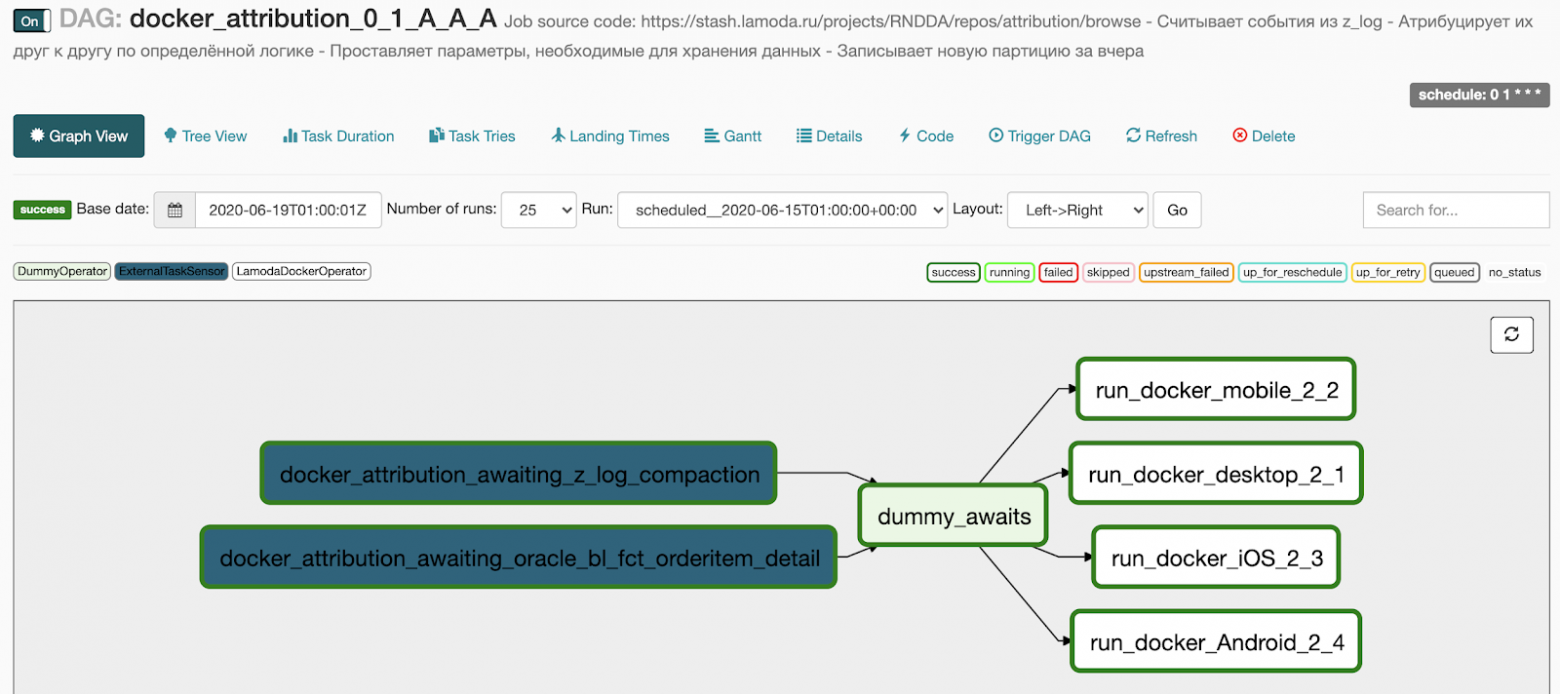
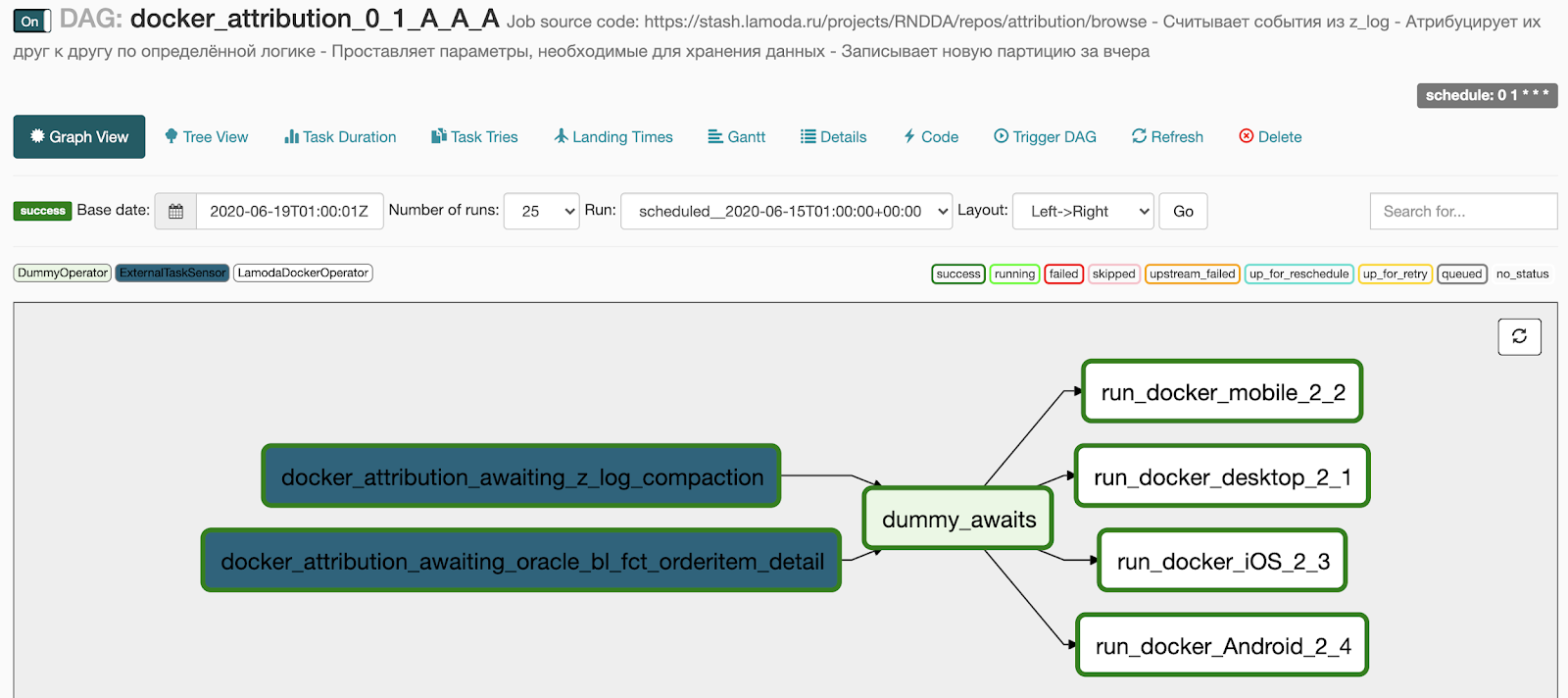
Вот что мы получаем после генерации:
- 2 пункта в блоке awaits превратились в два сенсора, которые дожидаются выполнения базового пайплайна,
- 4 задачи, которые мы указали в блоке docker, превратились в 4 параллельно бегущие задачи,
- между двумя блоками операторов мы добавили DummyOperator, чтобы не было паутины из связей между задачами.
Что мы хотим делать дальше
Во-первых, построить полноценный Feature environment. Сейчас у нас есть один девелоперский стенд для тестирования всех наших пайплайнов. И перед тестированием нужно убедиться, что dev-ландшафт сейчас свободен.
Недавно наша команда расширилась, и желающих прибавилось. Мы нашли временное решение проблемы и теперь сообщаем в Slaсk, когда занимаем dev. Это работает, но все-таки это узкое место в процессе разработки и тестирования.
Один из вариантов – переезд в Kubernetes. Например, при создании pull-request в master можно поднимать в Kubernetes отдельный namespace, куда разворачивать Airflow, деплоить код, потом раскидывать переменные, коннекшены. Разработчик после развертывания придет в свежесозданный инстанс Airflow и будет тестировать свои пайплайны. У нас есть наработки на эту тему, но руки не добрались до боевого Kubernetes-кластера, где мы могли бы это все запускать.
Второй вариант реализации Feature environment – организация репозитория с общей веткой develop, куда вливается код разработчиков и автоматически выкатывается на dev-ландшафт. Сейчас активно смотрим в сторону этой схемы.
Также мы хотим попробовать внедрить у себя плагины – штуки для расширения функциональности веб-интерфейса. Основная цель внедрения плагинов – построить диаграмму Ганта на уровне всего Airflow, то есть на уровне всех пайплайнов, а также построить граф зависимостей между разными пайплайнами.
Почему мы выбрали Airflow
- Во-первых, это Python, где с помощью двух циклов и пары условий можно сделать элегантный, правильно работающий пайплайн. И его не нужно будет описывать огромным куском XML. Плюс из коробки доступна практически вся экосистема Python и весь его зоопарк библиотек, который можно использовать как угодно.
- Отсутствие XML сильно упрощает code review. Мы написали код пайплайна и конфиги к нему, и всё замечательно, всё работает. На самом деле, можно затащить XML или любой другой формат конфигов, но это уже дело вкуса.
- Можно прикрутить базовые unit-тесты, которые будут проверять как отдельный пайплайн, так и конкретные операторы.
- Есть куча кастомизаций, и когда я говорю «куча», я немножко преуменьшаю. В Airflow можно кастомизировать стандартные операторы под ваши нужды. Он также не будет против, если мы вдруг захотим реализовать свой оператор, сенсор или хук.
- Airflow может ходить в огромное число внешних источников (и некоторые даже считают это минусом).
- Возможна интеграция с Active Directory и гибкая настройка доступов с помощью RBAC (role-based access control, подробнее об этом в минусах)
- Worker могут масштабироваться за счёт использования Celery или Kubernetes.
- Поскольку это open source-штука, можно в любой момент залезть в исходник любого оператора или в исходники шедулера и посмотреть, что там на самом деле происходит.
- У Airflow прекрасная документация, где описаны все подводные камни. Также о нём написано большое количество гайдов и есть активное сообщество.
- Доступен мониторинг и алертинг: из коробки есть интеграция со statsd для отправки метрик, интеграция с Sentry – мы попробовали ее прикрутить, но Airflow слал нам алерты на каждый чих, и мы решили пока отложить это дело. Также есть Airflow-exporter для интеграции с Prometheus.
Минусы Airflow, которые мы обнаружили
- Самый большой минус – это порог вхождения: необходимо настроить окружение, понять работу компонентов, как работает идемпотентность и почему execution_date в ежедневном даге – это на самом деле вчера, а не сегодня.
- Для кого-то может быть минусом невозможность накидывания пайплайна через веб-интерфейс, как это сделано, например, в Apache NiFi. Но мы считаем это плюсом – code-review с подсветкой diff-а организовать проще, чем ревью графических схем.
- Также Scheduler иногда причиняет некоторое количество боли из-за задержки между запусками задач.
- У кастомизации есть обратная сторона медали – некоторые операторы могут работать не так, как мы ожидаем. Или у них не будет достаточной функциональности для наших задач – в этих случаях придется переписать или расширить стандартные операторы.
- По умолчанию у Airflow довольно скромная ролевая модель: доступны роли пользователя и админа. При этом авторизованный пользователь имеет полный доступ к пайплайнам, включая те, которыми он не владеет. RBAC позволяет гибко настраивать роли пользователей (список доступных ролей) и их доступы, а также открывает бонусные плюшки в UI (например, указывать для пайплайнов теги, по которым можно фильтроваться). Однако подключение RBAC – отдельная веселая история с security настройками Flask, почитать об этом можно тут.
- Для полноценной локальной разработки и тестирования нужно поднять у себя все эти компоненты: шедулер, воркер, веб-сервер, очередь задач, базу метаданных. Когда я запускаю весь этот зоопарк у себя в докере, мой ноутбук превращается во взлетающий вертолет.
В каких случаях можно подружиться с Airflow
- Когда crontab’a уже не хватает и нужен cron на батарейках.
- Если человек уже дружит с Python.
- Если уже что-то крутится в Docker, но не хватает дополнительных свистелок типа интерфейса, просмотра статистики и зависимостей между задачами.
- Если не критична задержка между запусками задач, которую я упоминал, и если не критичен real time.
- Также Airflow подойдет, если потребности описываются словами “окей, нужно раз в день запустить штуку Х, также нужно два раза в день запускать штуку У, после чего запускать штуку Z – только если выполнится это условие”.
Что можно почитать про Airflow
- В документации описан процесс настройки и часто задаваемые вопросы – ссылка
- Также есть компания Astronomer, которая занимается hosted-установкой Airflow в облаке или в Kubernetes. Также она делает прикольные гайды – ссылка
- Плюс внезапно Astronomer делает подкаст про Airflow – ссылка
- Русскоязычный чатик Airflow (ссылка) и англоязычный Slack (ссылка).