
Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- Layer rotation: a surprisingly powerful indicator of generalization in deep networks? (Université catholique de Louvain, Belgium, 2018)
- Parameter-Efficient Transfer Learning for NLP (Google Research, Jagiellonian University, 2019)
- RoBERTa: A Robustly Optimized BERT Pretraining Approach (University of Washington, Facebook AI, 2019)
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (Google Research, 2019)
- How the Brain Transitions from Conscious to Subliminal Perception (USA, Argentina, Spain, 2019)
- Large Memory Layers with Product Keys (Facebook AI Research, 2019)
- Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches (Politecnico di Milano, University of Klagenfurt, 2019)
- Omni-Scale Feature Learning for Person Re-Identification (University of Surrey, Queen Mary University, Samsung AI, 2019)
- Neural reparameterization improves structural optimization (Google Research, 2019)
1. Layer rotation: a surprisingly powerful indicator of generalization in deep networks?
Авторы статьи: Simon Carbonnelle, Christophe De Vleeschouwer (Université catholique de Louvain, Belgium, 2018)
→ Оригинал статьи
Автор обзора: Святослав Скоблов (в слэке error_derivative)
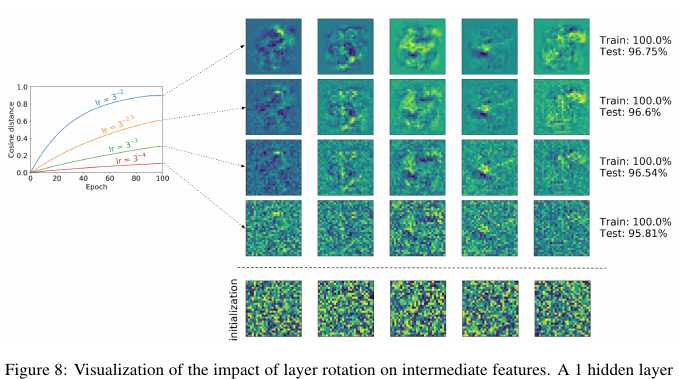
В данной статье авторы обратили внимание на достаточно простое наблюдение: cosine distance между весами слоя при инициализации и после обучения (процесс увеличения расстояния во время тренировки называют layer rotation). Господа заявляют, что в большинстве экспериментов сети, достигшие дистанции в 1 во всех слоях, стабильно превосходят в точности остальные конфигурации. Также в работе представлен алгоритм Layca (Layer-level Controlled Amount of weight rotation), позволяющий с помощью layer-wise learning rate контролировать этот самый layer rotation. По сути, от всем привычного алгоритма SGD он отличается наличием ортогональной проекции и нормализации. Подробный листинг алгоритма вместе со схемой обучения можно посмотреть в статье.
Основная идея, которую выводят авторы: the larger the layer rotations, the better the generalization performance. Большая часть статьи представляет из себя записи экспериментов, где исследовались различные сценарии обучения: использовались MNIST, CIFAR-10/CIFAR-100, tiny ImageNet с разными архитектурами, от однослойной сети до семейства ResNet.
Серия экспериментов была побита на несколько этапов:
- Vanilla SGD Выяснилось, что в целом поведение весов совпадает с гипотезой (большие изменения в расстоянии соответствовали лучшим значениям метрики), однако, были замечены и проблемы: layer rotation останавливался задолго до желаемых значений; также была замечена нестабильность в изменении дистанции.
- SGD + weight decay Уменьшение нормы весов сильно улучшило картинку обучения: большинство слоев достигали максимальной дистанции, а тестовая производительность схожа с предложенной Layca. Безусловным плюсом авторского метода является отсутствие дополнительного гиперпараметра.
- LR warmups Оказалось, что warmup помогает SGD побороть проблему нестабильного layer rotation, однако, не оказывает никакого эффекта на Layca.
- Adaptive Gradient Methods Помимо известной истины (что с помощью указанных методов тяжелее достичь того уровня генерализации, что может дать SGD + weight decay) выяснилось, что эффекты layer rotation весьма отличаются: первые увеличивают вращение в последних слоях, в то время как SGD — в начальных. Авторы намекают, что именно в этом может заключаться подлость адаптивных методов. И предлагают использовать Layca в связке с ними (улучшая способность к генерализации у адаптивных методов и ускоряя обучение у SGD).
Завершается статья попыткой интерпретации феномена. Для этого авторы натренировали сеть с 1 скрытым слоем на урезанной версии MNIST, после чего визуализировали случайные нейроны, придя к вполне логичному выводу: большая степень layer rotation соответствует меньшему влиянию инициализации и лучшему изучению фич, что и способствует улучшенной генерализации.
Выложен код реализованного алгоритма (tf/keras) и код для воспроизведения экспериментов.
2. Parameter-Efficient Transfer Learning for NLP
Авторы статьи: Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly (Google Research, Jagiellonian University, 2019)
→ Оригинал статьи
Автор обзора: Алексей Карначёв (в слэке zhirzemli)
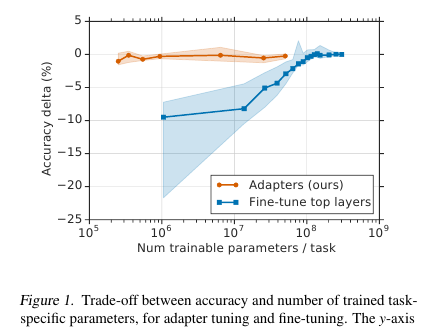
Тут господа предлагают простую, но эффективную технику fine-tuning’а NLP-моделей (в данном случае BERT). Идея в том, чтобы встроить обучаемые слои (адаптеры) прямо в сеть. Каждый такой слой — это сеть с bottleneck’ом, которая адаптирует скрытые состояния оригинальной модели к конкретной down-stream задаче. Веса исходной модели в свою очередь остаются замороженными.
Мотивация
В условиях streaming-обучения (или около-онлайн обучения), где down-stream задач много — не очень хочется файнтюнить всю модель целиком. Во-первых, долго, во-вторых, сложно, в-третьих, даже если зафайнтюним, то модель нужно как-то хранить: дампить или держать в памяти. И эту модель мы уже не сможем переиспользовать для следующей задачи: каждый раз придётся тюниться по новой. В итоге, можем попробовать адаптировать скрытые состояния сети под текущую проблему. Причем, исходная модель остается нетронутой, а сами адаптеры намного более ёмкие, чем основная модель (~4% от общего числа параметров)
Имплементация
Проблема решается невероятно простым образом: в каждый слой модели добавляем по 2 адаптера. Перед layer-нормализацией в transformer-based моделях происходит skip-connection: трансформированный input (текущее скрытое состояние) складывается с исходных input’ом.
Таких участков в каждом transformer слое — 2. Один — после multi-head attention’а, второй — после feed forward’а. Таким образом, скрытые состояния этих участков дополнительно пропускаются через Adapter: неглубокая сеть с 1-bottleneck скрытым слоем и с output’ом такой же размерности как и input. К bottleneck состоянию применяется нелинейность, а к output’у добавляется Input (skip-connection). Получается, что общее число обучаемых параметров равно: 2md + m + d, где d — это размерность скрытого состояния исходной модели, m — это размер bottleneck’а адаптер-слоя. Получается, что для BERT-base модели (12 слоёв, 110М параметров) и для размера адаптер-bottlneck’а 128, у нас получится 4.3% от общего числа параметров
Результаты
Сравнение делалось с полным файнтюнингом модели. На всех задачах такой подход показал минорный проигрыш по метрикам (в среднем меньше 1 пункта), при количестве тренируемых весов — 3% от общего числа. Сами задачи перечислять не буду, там их много, в статье есть табличка.
Fine-Tuning
В такой модели тюнится исключительно Аdapter часть (+ сам классификатор на выходе). Для весов адаптера предлагают делать near-identity инициализацию. Таким образом, необученная модель не будет никак изменять скрытые состояния сети, и это даст возможность уже в процессе тренировки модели самой решить какие состояния адаптировать под задачу, а какие оставить без изменения.
Learning rate рекомендуют брать больше, чем при стандартном finetuning’е BERT. Лично на моей задаче хорошо отработал 1e-04 lr. Кроме того, (уже лично моё наблюдение) в процессе тюнинга у модели почти всегда взрываются градиенты, поэтому нужно не забыть сделать clipping. Оптимизатор — Adam с warmup 10%
Код
Код у них в статье приложен. Имплементация на Tensorflow.
Для Torch автор обзора форкнул pytorch-transformers и добавил Adapter-слой (в начале README.md файла небольшой мануал по запуску)
3. RoBERTa: A Robustly Optimized BERT Pretraining Approach
Авторы статьи: Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov (University of Washington, Facebook AI, 2019)
→ Оригинал статьи
Автор обзора: Артем Родичев (в слэке fuckai)
Драматически подняли качество BERT модели, первое место на GLUE лидерборде и SOTA на многих NLP тасках. Предложили ряд способов как можно лучше тренировать BERT модель без какого-либо изменения самой архитектуры модели.
Основные различия с оригинальным BERT’ом:
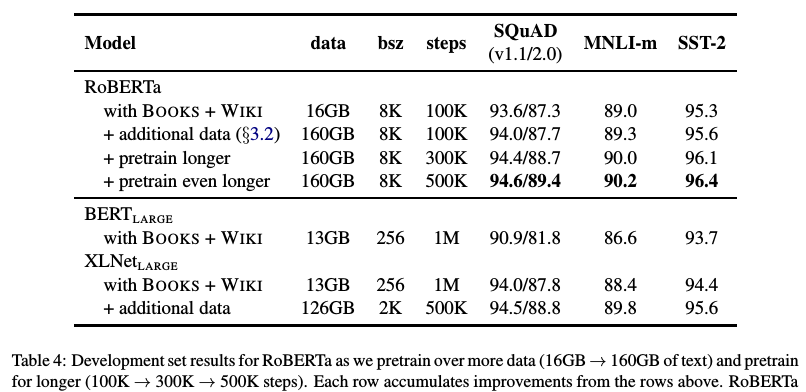
- Увеличили трейн корпус в 10 раз, с 16 GB сырого текста до 160 GB
- Сделали динамический маскинг для каждого сэмпла
- Убрали использование next sentence prediction лосса
- Увеличили размер мини-батча с 256 сэмплов до 8к
- Улучшили BPE енкодинг переведя базу с юникода на байты.
Лучшую финальную модель тренировали на 1024 картах Nvidia V100 (128 DGX-1 серверов) в течении 5 дней.
Суть подхода:
Данные. Помимо Wiki корпуса и BookCorpus (16GB в сумме), на которых учили оригинальный BERT, добавили еще 3 больший корпуса, все на английском:
- СС-News 63 миллиона новостей за 2.5 года на 76GB
- OpenWebText — корпус, на котором OpenAI учили GPT2 модель. Это скрауленные статьи на которые были приведены ссылки в постах на реддите минимум с тремя апвоутами. 38GB данных
- Stories — корпус историй из CommonCrawl на 31GB
Динамический маскинг. В оригинальном BERT’e в каждом сэмпле маскируется 15% токенов и предсказываются эти токены используя незамаскированную часть последовательности. Маска генерируется для каждого сэмпла один раз при препроцессинге и не меняется. При этом один и тот же сэмпл в трейне может встретиться несколько раз, в зависимости от кол-ва эпох по корпусу. Идея динамического маскинга — формировать каждый раз новую маску для последовательности, а не использовать фиксированную в препроцессинге.
Next Sentence Prediction objective. Давайте просто выпилим этот обджектив и посмотрим стало ли хуже? Стало лучше или осталось также — на SQuAD, MNLI, SST и RACE тасках.
Увеличение размера мини-батча. Много где, в частности в Machine Translation, было показано, что чем больше мини-батч, тем лучше финальные результаты трейна. Показали что если увеличить минибатч с 256 сэмплов, как в оринальном BERT’e, до 2k, а затем и до 8k, то perplexity на валидации падает, а метрики на MNLI и SST-2 растут.
BPE. BPE из оригинальной реализации BERT’a использует в качестве базы для subword units юникод символы. Это приводит к тому, что на больших и разнообразных корпусах значимую часть словаря будут занимать отдельные юникод символы. OpenAI еще в GPT2 предложили использовать не юникод символы, а байты в качестве базы для subwords. Если использовать BPE словарь размером 50k, то у нас не будет unknown токенов. Размер модели по сравнению с оригинальным BERT’ом вырос на 15М параметров для base модели и на 20М для large, то есть больше на 5-10%.
Результаты:
В качестве моделей для сравнения используют BERT-large и XLNet-large. Сама RoBERTa такая-же по параметрам, как и BERT-large.В итоге получили первое место на GLUE бенчмарке. Использовали single-task файнтюнинг, в отличии от многих других подходов из топа GLUE бенчмарка которые делают multi-task файнтюнинг. На дев-сете в GLUE сравниваются single model результаты, получили SOTA на всех 9 тасках. На тест-сете сравнивают ансамбль моделей, SOTA на 4 из 9 тасков и по финальному glue скору. На двух версиях SQuAD на дев-сете SOTA, на тест-сете на уровне XLNet. Причем в отличии от XLNet они не файнтюнятся на дополнительных QA корпусах прежде чем решать SQuAD.
SOTA на RACE таске, в котором дается кусок текста, вопрос по этому тексту и 4 варианта ответа, где нужно выбрать правильный. Чтобы зарешать этот таск они конкатенируют текст, вопрос и ответ, прогоняют через BERT, получают репрезентацию из CLF токена, подают на один полносвязанный слой и предсказывают является ли ответ правильным. Так делают 4 раза — для каждого из вариантов ответа.
Выложили код и претрейн модели RoBERTa в fairseq репе. Можно пользоваться, все выглядит аккуратно и просто.
4. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Авторы статьи: Mingxing Tan, Quoc V. Le (Google Research, 2019)
→ Оригинал статьи
Автор обзора: Александр Денисенко (в слэке Alexander Denisenko)
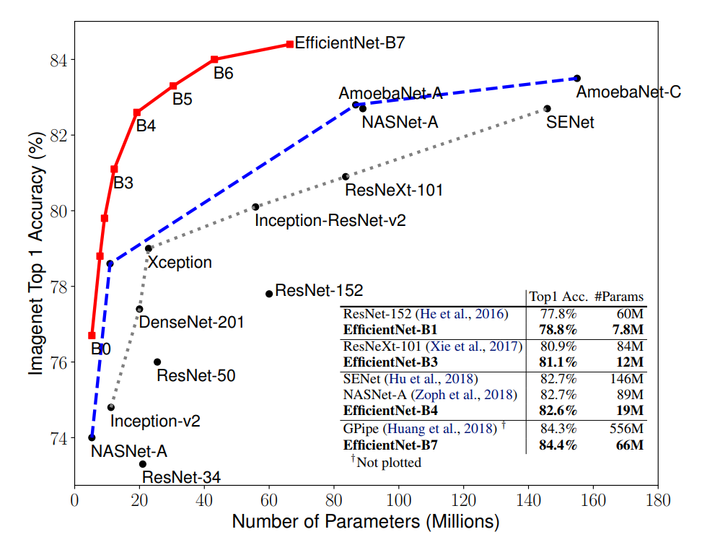
Изучают скейлинг (масштабирование) моделей и балансирование между собой глубины и ширины (количества каналов) сети, а также разрешение изображений в сетке. Предлагают новый метод скейлинга, который равномерно скейлит глубину/ширину/разрешение. Показывают его эффективность на MobileNet и ResNet.
Также используют Neural Architecture Search для создания новой сетки и скейлят её, тем самым получая класс новых моделей – EfficientNets. Они лучше и намного экономнее предыдущих сеток. На ImageNet EfficientNet-B7 достигает state-of-the-art 84.4% top-1 и 97.1% top-5 accuracy, будучи при этом в 8.4 раза меньше и в 6.1 раз быстрее на инференсе, чем текущая лучшая по точности ConvNet. Хорошо трансферится на другие датасеты – получили SOTA на 5 из 8 наиболее популярных датасетов.
Compound model scaling
Скейлинг – это когда фиксируются производимые внутри сетки операции и меняются лишь глубина (количество повторений одних и тех же модулей) d, ширина (количество каналов в свёртках) w и разрешение r. В пэйпере скейлинг формулируется как проблема оптимизации – хотим максимальную Accuracy(Net(d, w, r)) при том, что не вылезаем за границу по памяти и по FLOPS.
Провели эксперименты и убедились в том, что действительно помогает также скейлить по глубине и разрешению, когда скейлим по ширине. При тех же FLOPS достигаем существенно лучшего результата на ImageNet (см картинку выше). Вообще это разумно, потому что кажется, что при увеличении разрешения изображения сети необходимо больше слоёв в глубину для увеличения рецептивного поля и больше каналов для того, чтобы ухватить все паттерны в изображении с более высоким разрешением.
Суть compound scaling'а: берём compound coefficient phi, который с этим коэффициентом равномерно скейлит d, w и r:  где
где  – константы, полученные из небольшого грид сёрча по исходной сетке.
– константы, полученные из небольшого грид сёрча по исходной сетке.  – коэффициент, характеризующий количество имеющихся вычислительных ресурсов.
– коэффициент, характеризующий количество имеющихся вычислительных ресурсов.
Efficient-Net
Для создания сетки использовали Multi-objective neural architecture search, оптимизировали Accuracy и FLOPS с параметром, отвечающий за трейд-офф между ними. Такой поиск и дал EfficientNet-B0. Вкратце – Conv, за которой идут несколько MBConv, в конце Conv1х1, Pool, FC.
Затем делаем скейлинг из двух шагов:
- Для начала фиксируем
 , делаем грид сёрч для поиска .
, делаем грид сёрч для поиска . - Скейлим сетку, используя формулы для d, w и r. Получили EffiientNet-B1. Аналогично, увеличивая , получаются EfficientNet-B2, … B7.
Проводили скейлинг для разных ResNet и MobileNet, везде получили существенные улучшения на ImageNet, compound scaling давал значительный прирост по сравнению со скейлингом лишь по одному измерению. Также провели эксперименты с EfficientNet ещё на восьми популярных датасетах, везде получили SOTA или близкий к нему результат при существенно меньшем количестве параметров.
5. How the Brain Transitions from Conscious to Subliminal Perception
Авторы статьи: Francesca Arese Lucini, Gino Del Ferraro, Mariano Sigman, Hernan A. Makse (USA, Argentina, Spain, 2019)
→ Оригинал статьи
Автор обзора: Святослав Скоблов (в слэке error_derivative)
Данная статья является продолжением и переосмыслением работы Dehaene, S, Naccache, L, Cohen, L, Le Bihan, D, Mangin, JF, Poline, JB, & Rivie`re, D. Cerebral mechanisms of word masking and unconscious repetition priming, в которой авторы попытались рассмотреть режимы сознательной и бессознательной работы мозга.
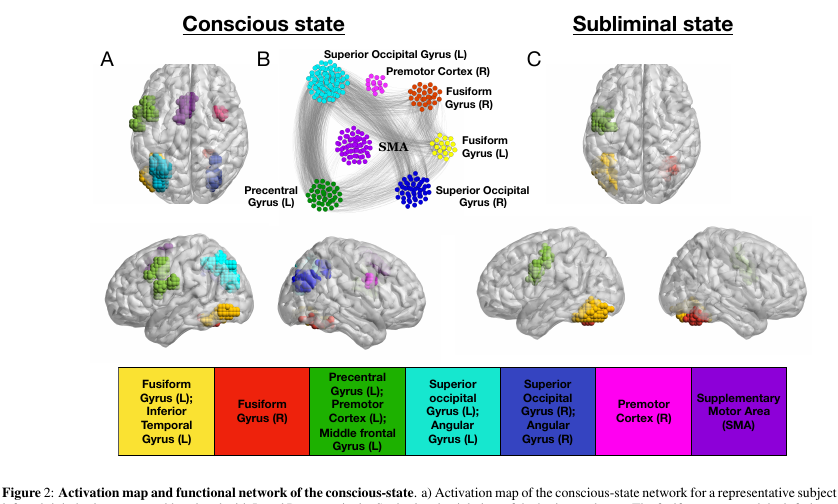
Эксперимент:
Добровольцам показывают картинки (слова из 4 букв, либо пустой экран, либо каракули). Каждую из них показывают 30 ms, в общем все действие длится 5 минут.
- В «сознательном» режиме эксперимента пустой экран чередуется со словами, что позволяет человеку осознанно воспринять текст.
- В «бессознательном» режиме слова чередуются с каракулями, что вполне эффективно мешало воспринимать текст на сознательном уровне.
Данные:
Во время сего представления мозги наших приматов сканировались с помощью fMRI. Всего у исследователей было 15 добровольцев, каждый повторил эксперимент 5 раз, итого 75 fMRI стримов. Стоит отметить, что voxel скана получился достаточно большой (сильно упрощенно: voxel — это 3D куб, содержащий достаточно большое количество клеток) — 4x4x4mm.
Магия:
Назовем нодой активный voxel с нашего стрима. Так как мозг — мочалка модульная, то введем в нем два типа связей: внешние и внутренние (соответствуют пространственному расположению нод). Связи собираются интересным образом: строим cross-correlation matrix между нодами и соединяем связью ноды, если корреляция больше некоего адаптивного параметра лямбда. Этот параметр влияет на разряженность нашей сети.
Настройка параметра осуществляется с помощью процедуры «фильтрации». Если немного пошатать нашу лямбду, то становятся заметными резкие переходы между конечными размерами сети (т.е. достаточно малому изменению параметра соответствует большое приращение в размере).
Так вот: внутренние связи активируются значением лямбда-1, которое соответствует значению лямбда прямо перед резким переходом. Внешние — значением лямбда-2, соответствующим значению лямбда сразу после резкого перехода.
Магия-2:
k-Core фильтрация. Концепт k-core описывает связность сети и формулируется довольно просто: максимальная подсеть, все ноды которой имеют как минимум k соседей. Такую подсеть можно получить итеративным удалением нод, имеющих меньше k соседей. Поскольку оставшиеся ноды будут терять соседей, то процесс продолжается, пока удалять будет нечего. То, что осталось, и есть k-core сети.
Результаты:
Применив данную артиллерию к нашим мозгам, можно увидеть ряд очень интересных особенностей.
- Число нод в k-core с маленьким/очень большим k крайне велико. А вот для средних k наоборот, мало. На картинке это выглядит как U shape, а именно такая конфигурация сети дает наибольшую стабильность системы (устойчивость как к локальным, так и к глобальным ошибкам).
- и самое важное Ноды, принадлежащие k-core с маленьким k мы можем увидеть практически в любом состоянии сети. А вот k-core с очень большим k характерны только для тех частей мозга, что активны в бессознательном состоянии fusiform gyrus & left precentral gyrus. Эти же части кортекса наиболее активны и в сознательном состоянии.
Для проверки результата авторы создали миллион случайных сетей на основе настоящих, делая случайный rewiring, при этом сохраняя оригинальную степень нод (то же самое, что и степень вершины в графе). Настоящие сети отличались от случайных куда большими значениями максимального k. При этом, U shape числа нод в кластерах оставался заметен и в случайных сетях, что натолкнуло авторов на мысль о том, что именно степень нод ответственна за данный феномен.
Выводы:
Авторы, почесав голову, размышляют о том, что транзит от сознательного к бессознательному в мозге происходит путем ослабления интеракций в сетях. Почесав голову с другой стороны, они делают предположение о том, что все внешние стимулы обрабатываются бессознательно, а сознанию отводится всего-лишь роль некоего регулятора информации (далее исследователи ссылаются на другие работы, которые, впрочем, не проясняют конкретную роль сознания).
Более того, исходя из того, что активация сетей в сознательном режиме происходит довольно разнообразно, то самим собой напрашивается вывод о том, что сознание не реализуется внутри определенной структуры мозга, а является адаптивной реакцией контроля на бессознательные стимулы и, следовательно, каждое сознательное впечатление по-своему уникально. Что, впрочем, не является новостью и было известно еще древним грекам как проблема qualia.
6. Large Memory Layers with Product Keys
Авторы статьи: Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou (Facebook AI Research, 2019)
→ Оригинал статьи
Автор обзора: Максим Лашкевич (в слэке belerafon)
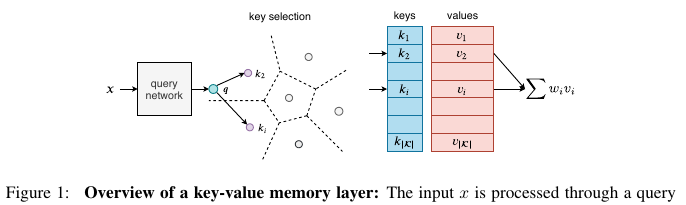
Рассказывают, как сделать быструю и дифференцируемую память key-value и куда её пихать в уже известных архитектурах, чтобы получить профит.
Память представляет из себя по-сути помесь эмбеддинга и attention. Есть вектор запроса q, у памяти есть ключи k и значения v. Берем q, перемножаем на все k, берем от этого софтмакс, и по нему взвешиваем все value и суммируем. Это то, что можно назвать уже известной архитектурой памяти. Далее в статье говорится, что есть два узких места при большом объеме памяти. Если брать софтмакс от всей памяти, то потом по ней обратно придется бекпропить при обучении, что очень больно. Предлагается брать только несколько максимально-близких ключей к запросу q и только от них считать софтмакс (например, топ-10). Тогда бекпропить придется только по самым релевантным ключам. Это как бы известная техника тоже.
Второе узкое место — это вычисление произведения запроса q на ключи k для всей памяти. Это тоже долго, поэтому предлагается трюк "Product Keys". Нюансы лучше всего смотреть в статье, но в двух словах они делят вектор запроса q на две части, и все ключи тоже напополам. Производя те же самые операции по выбору топ-10 с этими половинками, получается, что поиск идет вместо O(N) операций как в "обычной" реализации памяти, а всего О(sqrt(N)).
В итоге получается большая и быстрая и дифференцируемая key-value память. Пихать они её предлагают в задачах, где модели андерфитятся (где датасет такой, что модель не может заоверфититься). Например, они берут BERT и тренируют на датасете в 28 миллиардов слов. Показывают, что лучше и быстрее получается взять меньшую ёмкость самой модели, но расширить её такой памятью. А именно: 12-ти слойный трансформер с памятью работает в 2 раза быстрее, чем 24-слойный без памяти, да еще и perplexity с памятью на пункт ниже.
Ставить память они предлагают конкретно в этой архитектуре вместо полносвязной сети (в трансформере она стоит после слоёв self-attention). Говорят, что математически такая память по-сути представляет собой полносвязную сеть с невероятно большим скрытым слоем. Еще говорят, что делать запросы к памяти лучше в стиле multy-head attention. Т.е. вместо одного запроса query формировать несколько, по ним выбирать несколько ответов value, всё это суммировать и выплёвывать. Так память используется более интенсивно и более ёмко что-ли.
Ну и в статье много картинок и табличек, показывающих, на сколько процентов при каких конфигурациях память используется, на сколько повышает скор, куда её в BERT лучше вставлять. Про другие архитектуры ничего не пишут.
7. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
Авторы статьи: Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach (Politecnico di Milano, University of Klagenfurt, 2019)
→ Оригинал статьи
Автор обзора: Андрей Кузнецов (в слэке netcitizen)

Вопрос воспроизводимости результатов исследований в области DL поднимается с завидной регулярностью, однако, помимо воспроизводимости даже на крупных конференциях часто встречаются статьи с упущениями по методологии.
Задачи
В этой статье авторы попытались разобраться насколько все хорошо с последними исследованиями DL в области решения прикладных задач рекомендаций top-n. Для этого взяли DL алгоритмы рекомендаций последних лет с KDD, SIGIR, TheWebConf (WWW) и RecSys и попытались сделать следующие вещи:
- Воспроизвести результаты оригинальных статей
- Взять бейзлайны классических реко-алгоритмов и потюнить их для соответствующих датасетов
- Сравнить новый алгоритм с адекватными бейзлайнами
Результаты
- Воспроизвести удалось только 7/18 (39%)
- Почти во всех статьях из воспроизведенных нашлись “тонкости” вроде неслучайности разбиения train/test, странного расчета метрик и др., которые и позволяют, зачастую, добиться заявленных результатов.
- Все кроме одного алгоритма (Variational Autoencoders for Collaborative Filtering (Mult-VAE) показал ± такие же результаты) с отрывом проиграли дотюненным KNN, SVD, PR.
Выводы
Популярность DL, как инструмента для решения задач в CV, NLP покоя не дает исследователям рекомендательных систем, но пока результаты получаются не столь обнадеживающими.
8. Omni-Scale Feature Learning for Person Re-Identification
Авторы статьи: Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, Tao Xiang (University of Surrey, Queen Mary University, Samsung AI, 2019)
→ Оригинал статьи
Автор обзора: Вадим Петров (в слэке graviton)
Задача Person Re-Identification, в отличие от Face Recognition, не является хорошо решенной, поэтому в литературе наблюдается большой поток работ в данной области. Автор (Kaiyang Zhou) одного из лучших репозиториев по данной задаче deep-person-reid с группой коллег опубликовал работу, где предложил достаточно легкую модель (OSNet), которая достигает относительно высоких значений точности на базовых тестах Person Re-Identification. Модель доступна в указанном репозитории.
Демонстрация сложности задачи Person Re-Identification:

Основные идеи:
- Использование последовательности conv1x1 и deepwise conv3x3 вместо обычной conv3x3 в блоках (figure 3).
- Использование блоков, включающих потоки с различными полями восприятия. Для сравнения в ResNeXt потоки в блоках используют фичи на одинаковых полях восприятия, а в отличие от Inception потоки имеют более простую структуру (figure 4).
- Для объединения потоков используется разработанный “aggregation gate” с разделяемыми в рамках одного блока параметрами. При этом, в отличие от Inception веса аггрегации зависят от фич.
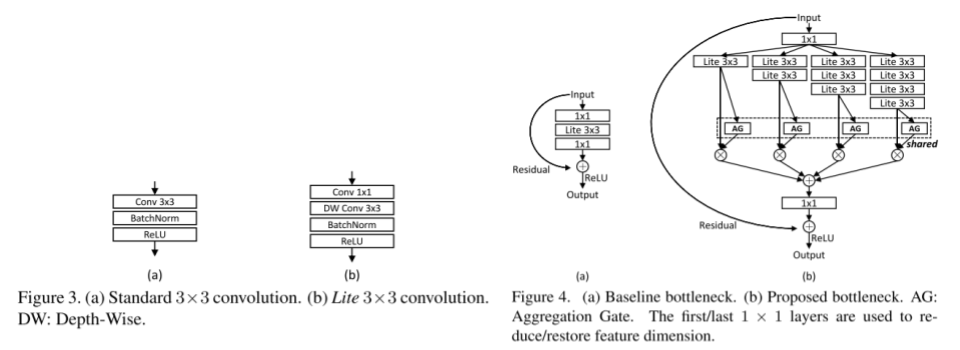
В OSNet основной упор сделан на использовние разных масштабов, т.к. это очень важно для решения проблем, которые составляют сложность задачи: очень часто отдельные мелкие детали (рисунок на майке, тип обуви) играют существенную роль.
Результаты по ReID тестам для OSNet (около 2 млн параметров) указывают преимущество данной архитектуры перед дргими легкими моделями (Market: R1 93.6%, mAP 81.0% для OSNet и R1 87.0%, mAP 69.5% для MobileNetV2) и отсутствие существенной разницы в точности с тяжелыми моделями ResNet и DenseNet (Market: R1 94.8%, mAP 84.9% для OSNet и R1 94.8%, mAP 86.0% для ResNet).
Еще одной сложностью задачи является доменная адаптация: модели обученные на одном датасете имеют плохое качество на другом. OSNet демонстрирует хорошие результаты и в данном сегменте без применения “unsupervised domain adaptation” (использование данных из теста в неразмеченном виде для выравнивания распределения данных).
Архитектура также проверена на ImageNet, где она достигла схожих точностей с MobileNetV2 при меньшем количестве параметров, но большем количестве операций.
9. Neural reparameterization improves structural optimization
Авторы статьи: Stephan Hoyer, Jascha Sohl-Dickstein, Sam Greydanus (Google Research, 2019)
→ Оригинал статьи
Автор обзора: Алексей (в слэке Arech)
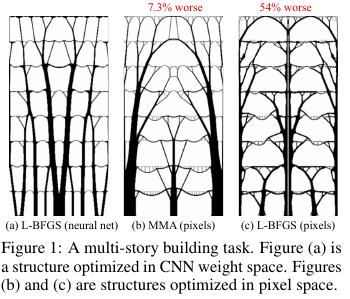
В строительстве и прочих технологиях есть задачи оптимизации структуры/топологии какого-то решения. Грубо говоря, это компьютерный ответ на вопрос типа, например, как задизайнить мост/здание/крыло самолёта/лопатку турбины/блаблабла, чтобы выполнялись определённые ограничения и конструкция была бы достаточно прочной. Есть набор "стандартных" методов решения, — работает, но там не всегда всё гладко.
Что придумали эти ребята из Гугла? Они сказали: а давайте мы будем генерить решение нейросетью (апсемплинговая часть UNet), а потом с помощью дифференцируемой физической модели, которая будет обсчитывать поведение решения под воздействием всяких сил и гравитации, высчитывать целевую функцию — прочность (точнее, обратную к ней, — податливость) конструкции. Затем, поскольку всё автоматически дифференцируемо, получаем градиент целевой функции, который проталкиваем через всю конструкцию обратно вплоть до весов и входа нейросети. Меняем веса и вход и продолжаем цикл до схождения к стабильному решению.
Результаты оказались на маленьких (в терминах размера пространства возможных решений) проблемах сравнимы с традиционными методами оптимизации топологий, а для больших проблем — заметно лучше традиционных (перевес в 99 против 66 из 116 задач). Причём получаемые решения часто бывают существенно более технологичны и оптимальны, чем решения бейслайнов.
Т.е. по сути они использовали НС как хитрый способ параметризовать физическую модель конструкции, который неявно (благодаря архитектуре НС) умеет налагать некоторые полезные ограничения на значения параметров (контролировали через убирание НС из метода и прямую оптимизацию значений пикселов).
